
10.1: Mutations - Causes and Significance
- Page ID
- 4896

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In the living cell, DNA undergoes frequent chemical change, especially when it is being replicated (in S phase of the eukaryotic cell cycle). Most of these changes are quickly repaired. Those that are not result in a mutation. Thus, mutation is a failure of DNA repair.
Single-base substitutions
A single base, say an A, becomes replaced by another. Single base substitutions are also called point mutations. (If one purine [A or G] or pyrimidine [C or T] is replaced by the other, the substitution is called a transition. If a purine is replaced by a pyrimidine or vice-versa, the substitution is called a transversion.)
Missense mutations
With a missense mutation, the new nucleotide alters the codon so as to produce an altered amino acid in the protein product.
The replacement of A by T at the 17th nucleotide of the gene for the beta chain of hemoglobin changes the codon GAG (for glutamic acid) to GTG (which encodes valine). Thus the 6th amino acid in the chain becomes valine instead of glutamic acid.

Nonsense mutations
With a nonsense mutation, the new nucleotide changes a codon that specified an amino acid to one of the STOP codons (TAA, TAG, or TGA). Therefore, translation of the messenger RNA transcribed from this mutant gene will stop prematurely. The earlier in the gene that this occurs, the more truncated the protein product and the more likely that it will be unable to function.
Here is a sampling of mutations that have been found in patients with cystic fibrosis. Each of these mutations occurs in a huge gene that encodes a protein (of 1480 amino acids) called the cystic fibrosis transmembrane conductance regulator (CFTR). The protein is responsible for transporting chloride and bicarbonate ions through the plasma membrane. The gene encompasses over 188,000 base pairs on chromosome 7 embedded in which are 27 exons encoding the protein. The numbers in the mutation column represent the number of the nucleotides affected. Defects in the protein cause the various symptoms of the disease. Unlike sickle-cell disease, then, no single mutation is responsible for all cases of cystic fibrosis. People with cystic fibrosis inherit two mutant genes, but the mutations need not be the same.
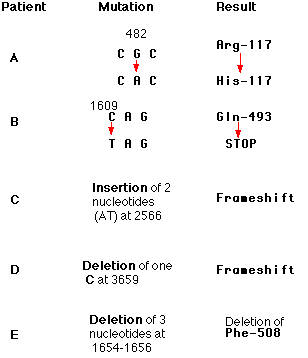
In one patient with cystic fibrosis (Patient B), the substitution of a T for a C at nucleotide 1609 converted a glutamine codon (CAG) to a STOP codon (TAG). The protein produced by this patient had only the first 493 amino acids of the normal chain of 1480 and could not function.
Silent mutations
Most amino acids are encoded by several different codons. For example, if the third base in the TCT codon for serine is changed to any one of the other three bases, serine will still be encoded. Such mutations are said to be silent because they cause no change in their product and cannot be detected without sequencing the gene (or its mRNA).
Splice-site mutations
The removal of intron sequences, as pre-mRNA is being processed to form mRNA, must be done with great precision. Nucleotide signals at the splice sites guide the enzymatic machinery. If a mutation alters one of these signals, then the intron is not removed and remains as part of the final RNA molecule. The translation of its sequence alters the sequence of the protein product.
Insertions and Deletions (Indels)
Extra base pairs may be added (insertions) or removed (deletions) from the DNA of a gene. The number can range from one to thousands. Collectively, these mutations are called indels.
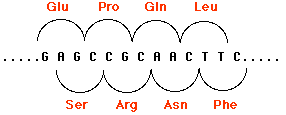
Indels involving one or two base pairs (or multiples of two) can have devastating consequences to the gene because translation of the gene is "frameshifted". This figure shows how by shifting the reading frame one nucleotide to the right, the same sequence of nucleotides encodes a different sequence of amino acids. The mRNA is translated in new groups of three nucleotides and the protein specified by these new codons will be worthless. Scroll up to see two other examples (Patients C and D).
Frameshifts often create new STOP codons and thus generate nonsense mutations. Perhaps that is just as well as the protein would probably be too garbled anyway to be useful to the cell.
Indels of three nucleotides or multiples of three may be less serious because they preserve the reading frame (see the above figure).
However, a number of inherited human disorders are caused by the insertion of many copies of the same triplet of nucleotides. Huntington's disease and the fragile X syndrome are examples of such trinucleotide repeat diseases.
Several disorders in humans are caused by the inheritance of genes that have undergone insertions of a string of 3 or 4 nucleotides repeated over and over. A locus on the human X chromosome contains such a stretch of nucleotides in which the triplet CGG is repeated (CGGCGGCGGCGG, etc.). The number of CGGs may be as few as 5 or as many as 50 without causing a harmful phenotype (these repeated nucleotides are in a noncoding region of the gene). Even 100 repeats usually cause no harm. However, these longer repeats have a tendency to grow longer still from one generation to the next (to as many as 4000 repeats).
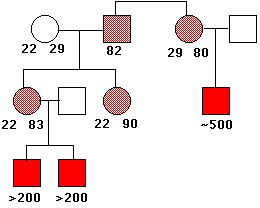
This causes a constriction in the X chromosome, which makes it quite fragile. Males who inherit such a chromosome (only from their mothers, of course) show a number of harmful phenotypic effects including mental retardation. Females who inherit a fragile X (also from their mothers; males with the syndrome seldom become fathers) are only mildly affected.
The above image shows the pattern of inheritance of the fragile X syndrome in one family. The number of times that the trinucleotide CGG is repeated is given under the symbols. The gene is on the X chromosome, so women (circles) have two copies of it; men (squares) have only one. People with a gene containing 80–90 repeats are normal (light red), but this gene is unstable, and the number of repeats can increase into the hundreds in their offspring. Males who inherit such an enlarged gene suffer from the syndrome (solid red squares). (Data from C. T. Caskey, et al.).
Polyglutamine Diseases
In these disorders, the repeated trinucleotide is CAG, which adds a string of glutamines (Gln) to the encoded protein. These have been implicated in a number of central nervous system disorders including
- Huntington's disease (where the protein called huntingtin carries the extra glutamines). The abnormal protein increases the level of the p53 protein in brain cells causing their death by apoptosis.
- some cases of Parkinson's disease where the extra glutamines are in the protein ataxin-2.
Muscular Dystrophy
Some forms of muscular dystrophy that appear in adults are caused by tri- or tetranucleotide, e.g. (CTG)n and (CCTG)n, repeats where n may run into the thousands. The huge RNA transcripts that result interfere with the alternative splicing of other transcripts in the nucleus.
Amyotrophic Lateral Sclerosis (ALS)
ALS is a neurodegenerative disorder leading to dementia and muscle weakness. (ALS is often called "Lou Gehrig's disease" after the baseball player who died from it.)
The most common mutation in ALS is an expansion of the number of repeats of the hexanucleotide GGGGCC in a gene on chromosome 9 from the normal two, or at least fewer than three dozen, to hundreds or even several thousand. Translation of both the sense and the antisense strands containing these repeats (and in all 3 reading frames; there is no ATG start codon) produces polymers with long strings of gly-ala, gly-pro, gly-arg (from the sense strand) as well as pro-ala, another pro-gly, and pro-arg from the antisense strand. These proteins, especially those containing arginine (arg) form aggregates that damage brain cells.
Duplications
Duplications are a doubling of a section of the genome. During meiosis, crossing over between sister chromatids that are out of alignment can produce one chromatid with a duplicated gene and the other (not shown) with the two genes with deletions. In the case shown here, unequal crossing over created a second copy of a gene needed for the synthesis of the steroid hormone aldosterone.
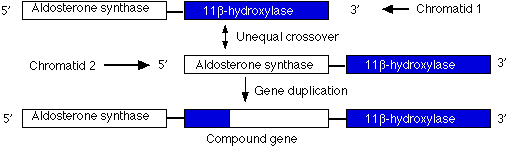
However, this new gene carries inappropriate promoters at its 5' end (acquired from the 11-beta hydroxylase gene) that cause it to be expressed more strongly than the normal gene. The mutant gene is dominant: all members of one family (through four generations) who inherited at least one chromosome carrying this duplication suffered from high blood pressure and were prone to early death from stroke.
Gene duplication has also been implicated in several human neurological disorders.
Gene duplication has occurred repeatedly during the evolution of eukaryotes. Genome analysis reveals many genes with similar sequences in a single organism. Presumably these paralogous genes have arisen by repeated duplication of an ancestral gene.
Such gene duplication can be beneficial.
- Over time, the duplicates can acquire different functions.
- The proteins they encode can take on different functions; for example, if the original gene product carried out two different functions (see "pleiotropy"), each duplicated gene can now specialize at one function and do a better job at it than the parental gene.
- But even if they do not, changes in the regulatory sequences of the genes (promoters and enhancers) may cause the same protein to be expressed at different times, at different levels, and/or in different tissues.
- But even while two paralogous genes are still similar in sequence and function, their existence provides redundancy ("belt and suspenders"). This may be a major reason why knocking out genes in yeast, "knockout mice", etc. so often has such a mild effect on the phenotype. The function of the knocked out gene can be taken over by a paralog.
- After gene duplication, random loss — or inactivation — of one of these genes at a later time in
- one group of descendants
- different from the loss in another group
Translocations
Translocations are the transfer of a piece of one chromosome to a nonhomologous chromosome. Translocations are often reciprocal; that is, the two nonhomologues swap segments.
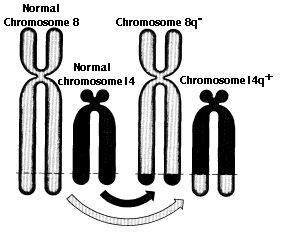
Translocations can alter the phenotype is several ways:
- the break may occur within a gene destroying its function
- translocated genes may come under the influence of different promoters and enhancers so that their expression is altered. The t(8;14) translocation in Burkitt's lymphoma (figure) is an example.
- the breakpoint may occur within a gene creating a hybrid gene. This may be transcribed and translated into a protein with an N-terminal of one normal cell protein coupled to the C-terminal of another. The Philadelphia chromosome found so often in the leukemic cells of patients with chronic myelogenous leukemia (CML) is the result of a translocation which produces a compound gene (bcr-abl).
Frequency of Mutations
Mutations are rare events. This is surprising. Humans inherit 3 x 109 base pairs of DNA from each parent. Just considering single-base substitutions, this means that each cell has 6 billion (6 x 109) different base pairs that can be the target of a substitution. Single-base substitutions are most apt to occur when DNA is being copied; for eukaryotes that means during S phase of the cell cycle.
No process is 100% accurate. Even the most highly skilled typist will introduce errors when copying a manuscript. So it is with DNA replication. Like a conscientious typist, the cell does proofread the accuracy of its copy. But, even so, errors slip through. It has been estimated that in humans and other mammals, uncorrected errors (= mutations) occur at the rate of about 1 in every 50 million (5 x 107) nucleotides added to the chain. (Not bad — I wish that I could type so accurately.) But with 6 x 109 base pairs in a human cell, that means that each new cell contains some 120 new mutations.
Should we be worried? The evidence is not clear. Only 1.2% of our DNA encodes the exons of our proteome, and for a long time it was thought that much of the rest was "junk" DNA. Mutations in it would most likely be harmless. And even in coding regions, the existence of synonymous codons could result in the altered (mutated) gene still encoding the same amino acid in the protein. But it now appears that as much as 80% of our DNA seems to participate in regulating which genes are expressed, and how strongly, in each of the multitude of differentiated cell types in our body as each responds to the signals (nutrients, hormones, etc.) it receives. So mutations in these regions might well have harmful, if subtle, effects.
As more vertebrate genomes are sequenced, it turns out that some of these stretches of DNA that do not encode proteins none-the-less have been remarkably conserved during vertebrate evolution. Some of these regions have accumulated even fewer mutations than protein-encoding genes have. This suggests that these sequences are extremely important to the welfare of the organism. However, other regions of the genome seem able to sustain point mutations with no detectible harm.
Recent advances have enabled the coding portions of the genome of single cells to be sequenced. Preliminary results indicate that each normal cell in an adult has accumulated ~20 somatic mutations, and that its collection of mutations differs from cell to cell. Cancer cells accumulate many more mutations (often in the hundreds).
How can we measure the frequency at which phenotype-altering mutations occur? In humans, it is not easy.
- First we must be sure that the mutation is newly-arisen. (Some populations have high frequencies of a particular mutation, not because the gene is especially susceptible, but because it has been passed down through the generations from a early "founder".
- Recessive mutations (most of them are) will not be seen except on the rare occasions that both parents contribute a mutation at the same locus to their child.
- This leaves us with estimating mutation frequencies for genes that are inherited as
- autosomal dominants
- X-linked recessives; that is, recessives on the X chromosome which will be expressed in males because they inherit only one X chromosome.
Examples
Frequency is expressed as the frequency of mutations occurring at that locus in the gametes
- Autosomal dominants
- Retinoblastoma
in the RB gene: about 8 per million (8 x 10-6) - Osteogenesis imperfecta
in one or the other of the two genes that encode Type I collagen: about 1 per 100,000 (10-5) - Inherited tendency to polyps (and later cancer) in the colon.
in a tumor suppressor gene (APC): ~10-5
- Retinoblastoma
- X-linked recessives
- Hemophilia A
~3 x 10-5 (the Factor VIII gene) - Duchenne Muscular Dystrophy (DMD)
>8 x 10-5 (the dystrophin gene)
Why should the mutation frequency in the dystrophin gene be so much larger than most of the others? It's probably a matter of size. The dystrophin gene stretches over 2.4 x 106 base pairs of DNA. This is almost 0.1% of the entire human genome! Such a huge gene offers many possibilities for damage.
- Hemophilia A
Measuring Mutation Rate
The frequency with which a given mutation is seen in a population (e.g., the mutation that causes cystic fibrosis) provides only a rough approximation of mutation rate — the rate at which fresh mutations occur — because of historical factors at work such as natural selection (positive or negative), drift, and founder effect. In addition, most methods for counting mutations require that the mutation have a visible effect on the phenotype. Thus
- many (but not all) mutations in noncoding DNA
- mutations that produce
- synonymous codons (encode the same amino acid)
- or, sometimes, new codons that encode a chemically-similar amino acid
- mutations which disrupt a gene whose functions are redundant; that is, can be compensated for by other genes
will not be seen. But now these problems have been largely solved. The story is told in a report by D. R. Denver, et al. in the 5 August 2004 issue of Nature.
The Procedure
- Their organism = C. elegans
- Its advantages
- compact genome
- hermaphroditic — it fertilizes its own eggs and any new germline mutation will soon be either lost or appear on both homologous chromosomes.
- rapid generation time (4 days)
- They created 198 different experimental lines of worms.
- They grew them under optimum conditions to minimize any effects of natural selection.
- Only one offspring was kept at each new generation.
- Each line was maintained for several hundred generations.
- At the end of this time, random stretches of DNA
- derived from multiple locations on each of the six C. elegans chromosomes and
- totalling an average of ~21 thousand base pairs for each line
Results
Examining the DNA sequences from their experimental animals (a total of over 4 million base pairs!), and comparing them with the controls, turned up a total of 30 mutations.
- 17 of these were insertions or deletions ("indels')
- 7 in exons — all but 2 of which produced frameshifts and a premature STOP codon.
- 10 in introns or between genes
- 13 of these were single base substitutions ("point" mutations)
- 3 in exons : one "silent" producing a synonymous codon; two that changed the encoded amino acid.
- 10 in introns or between genes
Calculating Mutation Rate
From these results I have pooled their data to calculate an approximate rate at which spontaneous mutations occur throughout the genome.
Mutation Rate = # of mutations observed [30] ÷ (# of experimental lines [198]) x (average # of generations [339]) x (average # of base pairs sequenced [~21,000])
yielding a rate of 2.1 x 10-8 mutations per base pair per generation.
The total C. elegans genome contains some 108 base pairs so this tells us that two new germline mutations occur somewhere in each of C. elegans's two haploid genomes in each generation.
A similar analysis for Drosophila (whose genome is about the same size as that of C. elegans) showed a similar mutation rate: ~10-8 mutations per base pair per generation. As for the green plant Arabidopsis thaliana, its spontaneous mutation rate is slightly lower: ~7 x 10-9 mutations per base pair per generation.
In the 30 April 2010 issue of Science, Roach, J. C., et al., reported that the rate for humans is in the same range: ~1.1 x 10-8 mutations per base pair in the haploid genome. With a diploid genome of 6 x 109 base pairs, that works out to some 70 new mutations in each child. They derived these numbers from comparing the complete genome sequence of two children and their parents.
In the 20 July 2012 issue of Cell, Wang, J., et al. reported the results of sequencing 8 individual sperm cells from a 40-year-old man. They found a mutation rate ranging from 2.0 x 10-8 to 3.8 x 10-8.
Should we be worried about such spontaneous mutation rates? Probably not too much. With our high proportion of noncoding DNA, many mutations will occur in regions that will have no effect on our phenotype. Evidence: out of a total of 251 mutations found in the 8 sperm cells, only 3 were missense mutations altering a gene product. However, even in noncoding DNA, point mutations may affect the expression of genes, so perhaps as many as 10% of the point mutations a child inherits may have harmful, if subtle, effects.
Males Contribute More Mutations Than Females
If most mutations occur during S phase of cell division, then males should be more at risk. This is because only two dozen (24) or so mitotic divisions occur from the fertilized egg that starts a little girl's embryonic development and the setting aside of her future eggs (which is done long before she is even born). Furthermore, the sperm of a 30-year old man, in contrast, are the descendants of at least 400 mitotic divisions since the fertilized egg that formed him.
So, fathers are more likely than mothers to transmit newly-formed mutations to their children. The sperm of a 25-year-old man might carry some 45 new mutations. This number rises at a rate of about 1 per year, so the sperm of a 40-year-old man may transmit some 60 new mutations to his children (about 20 of these in coding regions). No matter what the age of the mother, she transmits only about 15 new mutations to her offspring. (But chromosomal aberrations, like aneuploidy, are more apt to arise in eggs than in sperm, and the incidence of these increases with maternal age.) These data explain why the children of aged fathers suffer more genetic disorders than those of young fathers.
Somatic vs. Germline Mutations
The significance of mutations is profoundly influenced by the distinction between germline and soma. Mutations that occur in a somatic cell, in the bone marrow or liver for example, may
- damage the cell
- make the cell cancerous
- kill the cell
Whatever the effect, the ultimate fate of that somatic mutation is to disappear when the cell in which it occurred, or its owner, dies.
Germline mutations, in contrast, will be found in every cell descended from the zygote to which that mutant gamete contributed. If an adult is successfully produced, every one of its cells will contain the mutation. Included among these will be the next generation of gametes, so if the owner is able to become a parent, that mutation will pass down to yet another generation.