
4.8: Protein Folding and Unfolding (Denaturation) - Dynamics
- Page ID
- 14937


\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)-
Free Energy Landscapes and Protein Folding Dynamics
- Explain the concept of free energy landscapes in protein folding, including the "funnel" model versus rugged landscapes with local minima and a global minimum.
- Analyze how thermodynamic principles and activation energy barriers govern the transitions between unfolded, intermediate, and native protein states.
-
Molecular Dynamics and the Levinthal Paradox
- Describe how molecular dynamics (MD) simulations provide insight into the 3D, time-dependent process of protein folding.
- Discuss the Levinthal paradox and explain why proteins can fold rapidly despite the astronomical number of possible conformations.
-
Experimental Approaches to Studying Protein Folding
- Outline the key experimental techniques (e.g., fluorescence, circular dichroism, NMR D/H exchange) used to monitor folding transitions and measure protein stability.
- Interpret how kinetic methods (like stop-flow kinetics) and thermodynamic measurements are used to detect folding intermediates.
-
Anfinsen’s Experiment and the Role of Disulfide Bonds
- Summarize Anfinsen’s classic experiments on RNase folding, including how disulfide bonds are reformed during refolding and the impact of catalytic amounts of reducing agents.
- Relate the "socks and disulfides" exercise to the probability of achieving the correct native disulfide pairing during protein folding.
-
In Vitro vs. In Vivo Protein Folding and Aggregation
- Compare the conditions and challenges of protein folding in vitro versus in vivo, including the effects of concentration, aggregation, and cellular crowding.
- Explain the formation of inclusion bodies in recombinant protein expression and the role of the cellular environment in promoting correct folding.
-
Molecular Chaperones and Proteostasis
- Describe the function and mechanisms of molecular chaperones (e.g., Hsp70/Hsp40, chaperonins like GroEL/GroES and CCT/TRiC) in assisting protein folding and preventing aggregation.
- Analyze the ATP-dependent catalytic cycles of chaperones, including how nucleotide binding and hydrolysis regulate substrate affinity and folding kinetics.
-
Unfolded Protein Response (UPR) and ER Homeostasis
- Explain the unfolded protein response (UPR) and its role in managing ER stress by modulating chaperone levels, lipid synthesis, and protein degradation pathways.
- Discuss how the UPR helps maintain proteostasis in the context of protein folding and secretion.
-
Redox Chemistry in Protein Folding
- Understand the role of redox reactions in forming disulfide bonds, including the importance of oxidizing environments (e.g., ER, mitochondrial IMS) and reducing agents (e.g., glutathione).
- Compare the enzymatic systems (e.g., PDI/Ero1 in the ER versus Mia40/Erv1 in mitochondria) that catalyze disulfide bond formation and how these processes impact protein stability.
-
Protein Translocation Across Membranes
- Describe the mechanisms by which proteins are targeted and translocated across cellular membranes, including the role of signal peptides, the signal recognition particle (SRP), and the Sec translocon.
- Analyze how hydrophobicity and amino acid partitioning (using scales such as the Wimley-White hydrophobicity scale) determine whether a peptide inserts into a membrane or translocates across it.
-
Integration of Folding, Translocation, and Quality Control
- Synthesize how protein folding is coupled with membrane translocation and how cellular quality control systems (e.g., molecular chaperones, proteasomes) prevent aggregation and misfolding in vivo.
- Evaluate how both intrinsic protein properties and cellular factors contribute to the efficiency and fidelity of protein folding under physiological conditions.
These learning goals will help you integrate concepts from thermodynamics, kinetics, and cell biology to understand the complex, dynamic process of protein folding and its regulation in living systems.
Introduction
We've seen many static and rotating models of lipid aggregates (the micelle) and proteins. We have learned some rules about the disposition of amino acid side chains in folded proteins. However, we must think dynamically and thermodynamically when considering protein folding. Figure \(\PageIndex{1}\) shows a fun but clearly unrealistic animation of how a protein might fold from an unfolded state with exposed hydrophobic side chains (orange) to a folded state when they are mostly, but not fully, buried.
Luckily, we have the tools of molecular dynamics (MD) at our fingertips, which help us imagine how these processes take place and, concomitantly, how to probe protein folding experimentally.
As protein folding occurs in 3D, let's explore a free energy (G) landscape for folding from an extraordinarily large number of unfolded states of higher free energy to a single low-energy folded state. Two landscapes, created by Ken Dill's group, are shown in Figure \(\PageIndex{2}\).

The right image B shows a simplified ("much-reduced frustration") funnel view with a one-step path for any unfolded protein to reach a single global free-energy minimum state. This process occurs without any intermediates. A more realistic view is shown in A, which depicts a series of local minima and a single global minimum. Like in any activation energy curve you have encountered in chemistry courses, traversing from a local minimum to other local minimums or the global minimum is possible if enough energy is provided to overcome the activation energy for that step. Panel A implies that many intermediates lie along the path to the final global free energy minimum native state. Local minima could be populated and either stable or metastable depending on their activation energies. Intermediates might be "trapped" in these local minima. The view also conforms to our view that proteins are conformationally flexible and can adopt a variety of conformations. This is especially true for intrinsically disordered proteins.
Here are several 3D topology graphs that mimic (to some extent) the actual folding topology diagrams of proteins. Rotate them to view their shapes. Identify local and global minima, and the activation energies between them, for various paths. Use the mouse scroll wheel to resize the graphs and display the axis labels.
|
|
|
|
Now let's add some additional complexity. A protein on the path to a folded state has more hydrophobic exposure than the native state, so you would expect that it could aggregate with other self-proteins and form intermediates and end products off the normal folding pathway. These are illustrated in Figure \(\PageIndex{3}\), which shows the "normal" protein folding (blue) and a misfolding (orange) landscape. The misfolded landscape is populated with amorphous aggregates, oligomers, protofibrils, and fibrils.

We will discuss protein folding in vitro (in the lab) and in vivo (in the cell). In vitro folding is performed under very defined conditions, typically using low concentrations of small proteins to minimize the likelihood of misfolding. Folding in vivo occurs when a protein is made on a ribosome. It also occurs when a fully folded protein misfolds (such as during fevers in disease states) and is prevented from folding by association with other molecules. Folding in vivo is often assisted by other proteins called folding chaperones.
In either case, given the number of possibly nonnative states, it is amazing that proteins fold to the native state at all, let alone in a reasonable time frame. Consider this greatly simplified view of protein folding for a protein containing 100 amino acids. If each amino acid can adopt only three possible conformations, the total number of conformations could be 3100 = 5 x 1047. Assuming it would take 10-13 s to change each conformation, the time required to "test" all conformations would be 5 x 1034 s or 1027 years, longer than the universe's age (13.8 x 109 yr). Yet the protein can fold within seconds. This paradox is called the Levinthal paradox, after Cyrus Levinthal.
Lubert Stryer, (in his classic Biochemistry text), shows a way out of this dilemma by using an analogy of a monkey sitting at a typewriter, and typing this line out of Hamlet: "Me thinks it is like a weasel." Random typing would produce that line after 1040 keystrokes on average, but if the correct letters were maintained, the number of keystrokes would be a few thousand. Proteins could fold more quickly if they retain native-like intermediates along the way. Also, remember that much of conformational space is already restricted by allowed phi/psi angles (remember the empty areas in the Ramachandran plots).
We will explore the classic study of RNase folding by Anfinsen, for which he won the Nobel Prize. RNase is a small protein with four disulfide bonds and can refold from denaturing and reducing conditions in vitro. If he had chosen a larger protein, he might not have succeeded, as they are more prone to aggregation. We'll discuss mostly small proteins in this section.
Before we start, let's anticipate what might happen to fully reduced and denatured RNase with eight free Cys side chains. If the denatured protein is suddenly placed in a refolding solution lacking a denaturant and in an oxidizing environment (such as oxidized glutathione), reduced cysteine side chains could begin forming disulfide pairs. Still, only one such pair would be native. What would be the probability that a random process of forming disulfides would produce four correct ones and a fully native state? The following exercise will lead you to an answer.
You have four pairs of socks, each with a different color, as shown in Figure \(\PageIndex{4}\). You threw them into a drawer unpaired after washing. Now, without looking, take one sock out, then a second, and tie them together to form a pair. Continue doing this without looking until all four are paired. What is the probability that all the socks will be correctly matched when you are done? Once you have the answer, you're ready to understand Anfinsen's classic experiment.

- Answer
-
We'll calculate the probability of getting four perfect matches. You pick one sock initially. You have a 1/7 chance of getting the match from the remaining seven unpaired socks. You have six socks left. Pick one again. From the remaining 5, you have a 1/5 chance of getting a match. Now, pick another. From the remaining 3, you have a 1/3 chance of getting a match. Now, pick another. You have a 1/1 chance of getting the match. Each is independent, so the total probability of getting four matched pairs of socks is given by the product of the probabilities at each step, or
(1/7) x (1/5) x (1/3) x (1/1) = 1/105 or about 1%
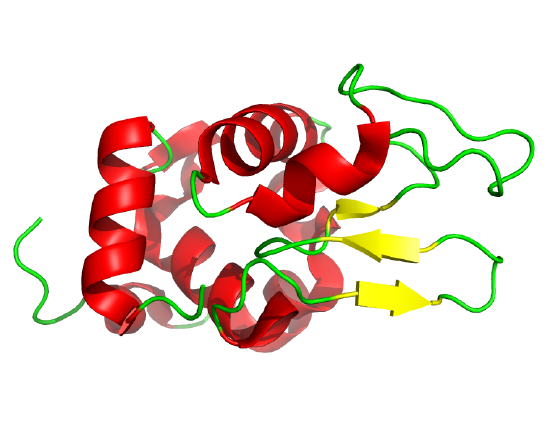
The classic experiment of Anfinsen showed that, at least for some proteins, all the necessary and sufficient information required to direct the folding of a protein into the native state is present in the primary sequence of a protein. Anfinsen studied the in vitro folding of a single-chain protein, RNase, which has four intrachain disulfide bonds, as shown in the interactive iCn3D model in Figure \(\PageIndex{5}\).
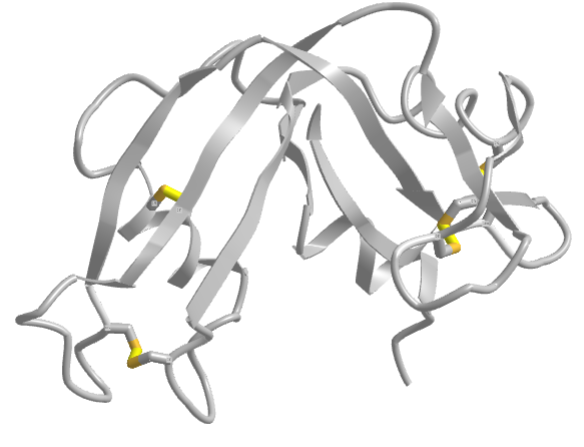
 Figure \(\PageIndex{5}\): RNase with four intrachain disulfide bonds (yellow sticks) (1KF5). (Copyright; author via source).
Figure \(\PageIndex{5}\): RNase with four intrachain disulfide bonds (yellow sticks) (1KF5). (Copyright; author via source).
Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...Risnvb1SfNrww6
We previously discussed how chemical agents (such as beta-mercaptoethanol, a disulfide-reducing agent) can covalently modify specific protein functional groups. Some can bind via complementary intermolecular forces to the active site or other surface cavities. Other reagents, such as urea, can alter protein folding through generalized solvent effects or nonspecific interactions with the protein. Anfinsen combined two reagents, 8 M urea and beta-mercaptoethanol (βME), to unfold RNase into a nonnative state. He then removed the βME using dialysis, allowing the disulfides to reform. Next, he removed the denaturing reagent, urea. To monitor whether the protein was correctly refolded or renatured, he measured its activity relative to that of the native protein. He found that the "refolded" protein retained only 1% of its initial activity (compare this to the matching socks activity). If, however, he added catalytic amounts of βME, the protein soon retained 100% of its initial activity. He was awarded the Nobel Prize in Chemistry in 1972 for his work. A general outline of his experiment is shown in Figure \(\PageIndex{6}\).

Figure \(\PageIndex{7}\) presents a chemical mechanism to show how catalytic (non-stoichiometric) amounts of beta-mercaptoethanol can lead to full recovery of the most stable set of a protein with two disulfide bonds (right-hand side).

Scientists have investigated protein folding both in vitro and in vivo. In vitro experiments use urea, guanidine hydrochloride, or heat to denature the protein. Refolding is started by removing the perturbing agent (denaturing agent), using spectral techniques to follow the process. In vivo experiments involve studying intracellular proteins that assist in protein folding. An understanding of protein folding can not be separated from an understanding of protein stability and an understanding of the nature of the native and denatured state, as illustrated in the protein folding landscapes shown in Figure \(\PageIndex{1}\) and Figure \(\PageIndex{2}\).
In studying protein folding and stability/structure of the native and denatured states, equilibrium (thermodynamic) and time-dependent (kinetic) measurements are made. Folding occurs over the millisecond-to-second time scale, limiting the ability to detect intermediates. Some clever methods have been developed to study intermediates in protein folding by trapping specific intermediate structures and investigating their structure and stability in a "leisurely" fashion. Alternatively, intermediates can be studied as they occur using stop-flow kinetics. In this technique, a protein under denaturing conditions is rapidly mixed with a solution containing no denaturant or protein by injecting both solutions into a mixer/cuvette using syringes. The denaturant in the protein solution has been diluted to allow renaturation. Spectral measurements can begin at once.
Figure \(\PageIndex{8}\) shows a diagram summarizing these methods. Study it in conjunction with the text that follows.

Folding appears to proceed not by an obligatory pathway but by a probabilistic or stochastic search of possible conformations. Evolution has surely selected sequences that can reach the folded state. Localized secondary structure motifs (like short alpha helices and beta turns) can form quickly (about 1 ms). The folding of small proteins, depending on their structure, occurs over a wide time frame (milliseconds to minutes). Most likely, a small number of amino acids coalesce into a core, which serves as a nucleus for folding into structures similar to the native state. Finally, packing interactions collapse the structure into the native state.
Generally, the more complex the backbone fold, the longer it takes the protein to fold. As complexity increases—i.e., the more interactions among distal regions of the polypeptide chain —the less likely it is that random interactions will lead to rapid protein folding. The folding mechanisms for larger proteins (greater than 100 amino acids) appear to proceed through intermediates, suggesting that different domains of the protein can fold independently.
Protein Folding In Vitro
Early protein folding studies involved small proteins that could be reversibly denatured and refolded. A two-state model, D ↔ N, was assumed. The denaturants were heat, urea, or guanidine HCl. Since denatured states are less compact than the native state, the solution viscosity can be used as a measure of denaturation/renaturation. Likewise, the amino acid side chains in different states would be in different environments. The aromatic amino acids Trp, Phe, and Tyr absorb UV light. After excitation, the electrons decay to the ground state through several processes. Some vibrational relaxation occurs, bringing the electrons to lower vibrational energy levels. Through radiative processes, some electrons can then fall to various vibrational levels at lower principal energy levels. The photons emitted are lower in energy and, hence, longer in wavelength. The emitted light is termed fluorescence. The wavelength of maximum fluorescent intensity and the lifetime of the fluorescence decay are very sensitive to the environment of the amino acids. Hence, fluorescence can also be used to measure changes in protein conformation. Other spectral techniques are used, like CD spectroscopy and simple absorbance measurements. For small, single-domain proteins (such as RNase) undergoing reversible denaturation, graphs showing the extent of denaturation using each technique above, as shown in Figure \(\PageIndex{9}\), are superimposable, giving strong validity to the two-state model.

Proteins that fold without easily discernable, long-lived intermediates and follow a simple two-state model, D ↔ N are said to undergo cooperative folding. This simple model needed to be expanded as more proteins were studied. Some intermediates in the process were detected.
Some proteins show two steps in refolding studies, one slow and one fast, suggesting an intermediate. The longer a protein is denatured, the more likely it is to display an intermediate. One accepted explanation for this observation is that during an extended time in the D state, some X-Pro bonds might isomerize from trans to the cis state to form an intermediate. Alternatively, as in the case of RNase, which has a cis X-Pro bond in the native state, denaturation causes isomerization to the trans state. In the case of RNase, to refold, the accumulating intermediate I must reisomerize in a slow step to the cis state, followed by a quick return to the N state.
Some proteins containing multiple disulfide bonds that must reform correctly after reductive denaturation could refold into intermediates with the wrong S-S partner. Such intermediates can be trapped by stopping further S-S formation during refolding by adding iodoacetamide as shown in Figure \(\PageIndex{10}\).
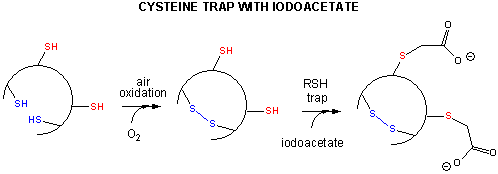
By adding iodoacetamide at varying times along the folding pathway and separating starting (unfolded), trapped intermediates on the pathway, and the final native state by HPLC, the entire folding path can, in principle, be determined. This has been done for many proteins, including bovine pancreatic trypsin inhibitor (BPTI), a small protein with 58 amino acids, a molecular weight of 6512, and three sets of disulfide bonds (C5-C55, C14-C38, and C30-C51). The structure of BPTI with native disulfides is shown in Figure \(\PageIndex{11}\).

Given its characteristics, BPTI has been used as a model protein to study protein folding. These studies have shown that no non-native disulfides form as intermediates in the pathway. Two major intermediates form quickly, each with two of the three native disulfide bonds. These intermediates are named N', with disulfide pairs 14-38 and 30-51, and N*, with pairs 5-55 and 14-38. These two intermediates slowly form a common intermediate NSHSH, with disulfide pairs 5-15 and 30-51, which converts quickly to the native N state with three correct pairs (5-55,14-38, and 30-51). This folding pathway is shown in parts a and b of Figure \(\PageIndex{12}\).

In going from N' or N* to NSHSH, the 14-38 disulfide, which is very solvent-exposed (see Figure \(\PageIndex{11}\)), must break before proceeding to the N (native state). Mousa et al. replaced that disulfide with a stable methylene thioacetal bridge (MT, alternative name methylenedithioether, S-CH2-S link) with the idea that once this stable (i.e., irreversible) 14-S-CH2-S38 bond formed in N' and N*, it would not break again. The formation of the methylenedithioether bond and its properties compared to disulfide bonds are shown in Figure \(\PageIndex{13}\).

Hence, the final intermediate, NSHSH, would not form, leaving just N' and N*. This is illustrated in Parts c and d in Figure \(\PageIndex{12}\).
In actuality, MT-BPTI does fold to the native form, whose crystal structure is virtually identical to native BPTI. Figure \(\PageIndex{12}\) shows "2D" folding plots that show the HPLC retention time of reactants, intermediates on one axis, and folding time on the other for wild-type BPTI (part a) and MT-BPTI (part b). Hence, the folding scheme is more complicated than the one shown in Figure \(\PageIndex{14}\).

Some proteins form partially folded but stable intermediates under partially denaturing conditions. A good example is lactalbumin, which, under mildly acidic conditions (pH 4), low levels of guanidine HCl, or neutral pH and low ionic strength in the absence of calcium (which normally binds to the protein), forms a stable, isolatable intermediate (I) called the molten globule (MG). Figure \(\PageIndex{15}\) shows the folded state with a bound calcium ion and circular dichroism spectra of the protein in various states.
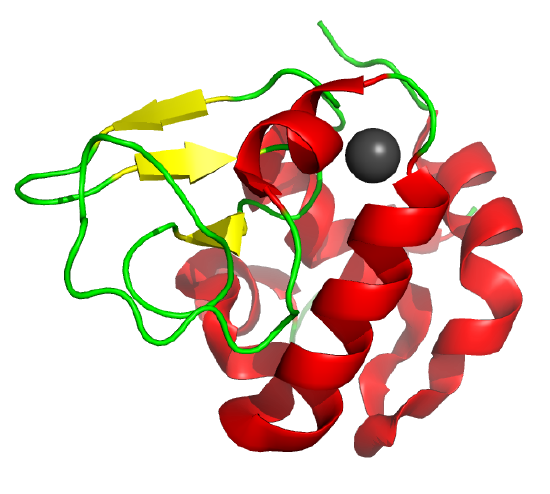

Data show that the MG is about 50% larger in volume than the N state. This compares to the denatured state, which can be 300% larger than the native state. Hence, it is more akin to the native state as studied by hydrodynamic techniques, but with greater solvent accessibility of hydrophobic side chains. The MG has a CD spectrum similar to that of the native state. Still, the aromatic side chains exhibit the same UV absorption and fluorescence characteristics as the protein in 6 M guanidine HCl, suggesting that the final tertiary state has not yet fully formed. The secondary structure in the MG may differ from that in the native state.
NMR can also be used to detect folding intermediates. Using this technique, proteins are unfolded in D2O, which will cause the exchange of all Cs with ionizable protons, including the amide Hs. An amine is a weak base (pKB around 3.5), so its conjugate acid, the protonated amine, has a pKa of around 9.5. An amide or peptide bond would be a weaker base than an amine, since its lone pair is less available (due to delocalization through resonance) for protonation. The pKa for the conjugate acid of the amide (in which the amide N is protonated and has a plus charge) is much lower, around -0.5, than the pKa for the conjugate acid of an amine. At 2 pH units above its pKa, the amide N is close to 100% deprotonated. The pKa of the protonated group is important because the rate of H exchange depends on it, holding other variables constant. The pKa of an unprotonated amine (i.e., for the reaction RNH2 → RNH- is very high (30s), and hence, deprotonation of the RNH2 is not likely under normal conditions. Figure \(\PageIndex{16}\) shows NMR D/H exchange/protection experiments for forming an alpha helix in a protein folding experiment.

Refolding is initiated by diluting the protein into a solution without the denaturant, but still in D2O. As the protein folds and becomes more compact, the buried atoms are now sequestered from the solvent, and no longer readily exchange Ds. Then the protein is placed in H2O at pH 9.0 for 10 ms, followed by dropping the pH to 4.0. D → H exchange is promoted at high pH and quenched for the amide Ds and Hs at low pH. Amide Hs that continue to exchange must be accessible to water. Those that aren't are usually buried in secondary structure.
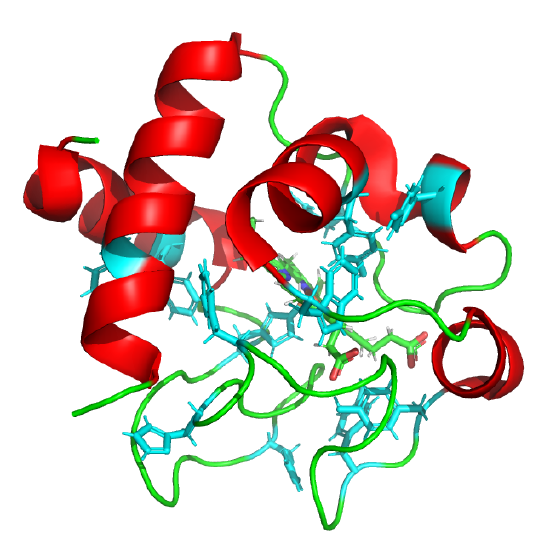
Hen Egg white lysozyme: Radford et al, Nature 358, pg 303 (1992) 2YVB

Cytochrome C: Elove et al, Biochemistry, 31, pg 6879 (1992). Cyan aromatic amino acids; Heme not shown. 5TY3

When the same techniques are applied to large, multidomain, or oligomeric proteins, only a few percent refold in vitro. Incorrect intermolecular interactions and heterogeneous aggregation appear to be the main problems that prevent correct protein folding in vitro
Here is a movie of a 6 us molecular dynamics simulation of the small protein villin.
The movie starts with the final crystal structure of villin and shows how it folds into its final structure.
With permission from the Beckman Institute for Advanced Science and Technology, National Institutes of Health //National Science Foundation, Physics, Computer Science, and Biophysics at the University of Illinois at Urbana-Champaign
The Denatured State
Although the structures of native and native-like states can be determined by X-ray crystallography and, in solution, NMR, little detailed information exists about the structures of denatured and intermediate states. Intermediate states are difficult to trap in a way that allows detailed structural analysis. In contrast to the "native" state, which consists of an ensemble of closely related states, intermediate and denatured states comprise many distinct states, making structural analysis more difficult. Religa and others from Fersht's lab have engineered a mutant of the Drosophila melanogaster engrailed homeodomain (En-HD) that enables such structural analyses. The mutation Leu16Ala (L16A) destabilizes the protein, making it denatured simply by changing the ionic strength. It is stable at high ionic strength and folds quickly under those conditions. However, it is "denatured" at physiological ionic strength, but contains significant alpha-helical structure and has nonnative contacts. It behaves like an early folding intermediate in that if placed in solutions of higher ionic strength, it rearranges to form the native state. It progressively "unfolds" to other states if placed in a lower ionic strength. Given the ambiguities in defining denatured and early folding intermediate states, Fersht's group suggests an "explicit" definition of the denatured state. They define the unfolded state (U) as the "maximally unfolded state of a protein, in which the backbone NH groups have little protection against 1H/2H exchange". They define the denatured state, D, as the "lowest energy non-native state under a defined set of conditions". In this scenario, the denatured state could also serve as a folding intermediate if placed under conditions that promote folding. Previous work from the group showed that the denatured state of En-HD has three helices protected from 2H exchange and was 1 kcal/mol (4.1 kJ/mol) lower in energy than the unfolded state.
Section 4.6 discussed the added complexities to a simple 2-state D ↔ N model for protein folding. These include Silent Single-nucleotide polymorphisms, Metamorphic Proteins, and Intrinsically Disordered Proteins (IDPs).
Protein Folding In Vivo
Many differences exist between how a protein folds or unfolds in a cell and a test tube.
- The total concentration of all the proteins and nucleic acids in cells is estimated to be about 350 g/L, or 350 mg/ml. Most measurements in the lab are conducted in the range of 0.1 to 10 mg/ml.
- Proteins are synthesized in cells from an N to C-terminal direction. Hence, the nascent protein, as it emerges from its site of synthesis (the ribosome), might fold into intermediate structures since the entire protein sequence is not yet available for direct folding.
- Proteins are synthesized in the cytoplasm but must then find their final destination within the cell. Some end up in membranes. Some must translocate across one or even two membranes to reach specific organelles, such as the Golgi, mitochondria, chloroplasts (in plant cells), nuclei, lysosomes, and peroxisomes. Do they translocate in their native state?
Additional evidence suggests that protein folding/translocation requires assistance (i.e., catalysis) in the cell.
- Mutant cells defective in certain proteins can accumulate misfolded and aggregated proteins.
- Eukaryotic genes (found in higher cells with nuclei and internal organelles) can be expressed to produce proteins when transferred into prokaryotes (such as bacteria like as E. coli). Still, they often misfold and aggregate in the bacterial cells, forming structures called inclusion bodies.
Hence, recombinant proteins expressed in vivo have the same folding problems as larger proteins in vitro. In both cases, conditions favor the accumulation of nonnative proteins with exposed hydrophobic groups, leading to aggregation. Aggregation also occurs in vivo when a protein is overexpressed or expressed at a higher temperature than normal. Why? Mutant cells have been selected that suppress the formation of inclusion bodies in vivo. This effect was mediated by a class of proteins expressed by the bacteria and other cells when their temperature is raised. The function of these proteins, called heat shock proteins (Hsp), was unknown until it was realized that they facilitate correct protein folding, in part, by binding to denatured proteins in the cells before they aggregate into inclusion bodies. Further studies discovered many proteins that facilitate protein folding and prevent aggregation in vivo. These proteins are now called molecular chaperones. Many are still named Hsp#, where # is the approximate molecular weight of the protein in kDa on a PAGE gel.
In a broader sense, a protein homeostatic environment exists within cells to maintain the proteome. This system includes chaperone proteins, which facilitate folding and refolding; the proteasome, which degrades ubiquitinated proteins; and the lysosome, which facilitates the autophagy of structures such as damaged mitochondria. Here, we will concentrate on chaperones, which are also involved in protein transport in the cell and in preventing aggregation. Some have used novel names to describe the various chaperone activities. These include holdases/translocases, unfoldases/foldases, and disaggregases, which process the various potential intermediates and end products. A simplified 2D free energy folding diagram showing the involvement of chaperones is shown in Figure \(\PageIndex{17}\).

Figure \(\PageIndex{17}\): 2D Free Energy Folding Diagram with Chaperone Assist. Moseck et al. Front. Mol. Biosci., 14 June 2021 | https://doi.org/10.3389/fmolb.2021.683132 Frontiers in Molecular Biosciences 8, pg 514, 2021 https://www.frontiersin.org/article/...lb.2021.683132. Creative Commons Attribution License (CC BY).
The nomenclature used to categorize chaperones is confusing. In general, chaperones in all cells interact with unfolded or misfolded proteins and essentially catalyze their folding. They can do so by removing them from environments that would inhibit folding. Some can prevent aggregate formation or remove them. Some interact with proteins as they exit the ribosome during translation, while others escort damaged proteins to proteasomal degradation sites.
Many chaperones are involved in maintaining proteostasis. They can be classified by molecular size or by groups based on overall structure and mechanism. We'll use the second approach. Here are some of the key players
Cage Chaperonins: Oligomeric High Molecular Nanoparticles
Chaperonins, whose subunits can still be called chaperones, assemble into oligomeric, high molecular weight nanoparticle cages. These complexes are involved in the folding of larger proteins. The complexes consist of two stacked rings. Inside is an inner cavity in which larger proteins can fold in isolation (an easy way to remember the name chaperonin). A somewhat silly analogy would be a person dressing alone in a closet. These complexes are ATPases, as ATP hydrolysis drives protein folding.
There are two main classes of chaperonins, Class I and Class II.
Group I: These are found in bacteria, in some archaea, and in mitochondria, which evolved through an endosymbiotic relationship with bacteria. Proteins in this group include Hsp60, which forms a homo 14-mer, and the co-chaperone Hsp10, which forms a homo 7-mer. In E. Coli, hsp60 is also called GroEL, while the small Hsp10 is called GroES. GroEL and GroES together form the GroEL/GroES Complex, which is shown in the interactive iCn3D model in Figure \(\PageIndex{18}\) (note: it loads slowly, given its large size).

Figure \(\PageIndex{18}\): GroEL/GroES Complex (1pcq). (Copyright; author via source).
Click the image for a popup (which loads slowly) or use this external link: https://structure.ncbi.nlm.nih.gov/icn3d/share.html?JNESMy2hS9ZBTST66
The 14 GroEL subunits form separate 7-mer (magenta) and 7-mer (gray) hollow rings that stack on one another. The gray ring monomers have an ADP/AlF3- (spacefill) bound. Seven GroES monomers, shown in cyan, form a "lid" over the end of the complex. This hetero-21-mer displays C7 global symmetry. Lid binding requires ATP.
Figure \(\PageIndex{19}\) shows a mechanism for the GroEL/GroES protein folding cycle (shown in a linear arrangement).

In the left-most structure, a substrate protein (colored line drawing) binds in the cavity formed by the GroEL ring that does not have the GroES 7-mer cap (cyan). Rearrangement of the substrate protein and interactions with the interior wall trigger binding of ATP, binding of the top GroES cap on the cis end (same end as bound protein substrate), and release of the previously bound ADP, the distal trans-GroES cap, and a folded protein (not shown) from the trans end. Transient interactions and substrate protein conformation changes lead to the folding of the colored protein substrate within the time frame needed for effective hydrolysis of the 7-bound ATPs. The binding of ATP and a new GroES cap at the bottom triggers the release of the folded protein at the top, along with the top GroES cap. The cycle then repeats with the binding of a new target protein substrate, ATP, and a GroES cap, leading to the dissociation of ADP and the other GroES cap.
The sequestration of the bound protein substrate prevents aggregation of the folding protein. The binding of any polymer to a confined, small volume must be entropically disfavored, as the polymer's conformational flexibility is reduced. Somehow, an entropic activation energy barrier is reduced inside the cage, perhaps similar to the restraining effects of disulfides on protein folding, allowing less conformational space to be explored during folding. GroEL has also been shown to bind in its hydrophobic cavity a fluorescent CdS semiconductor nanoparticle, which can be released on the addition and cleavage of ATP
Group 2: These are found in Archaea and eukaryotes. The eukaryotic chaperonin in this group is CCT (cytosolic chaperonin containing TCP1), also known as TRic (tailless complex polypeptide one ring complex or TCP1-ring complex). These also contain two stacked rings, but this time, they are 8-mers of molecular weight 50-60K. This is similar to the Hsp60 monomers in the GroEL/GroES complex, but the monomers in Group 2 are not named with the beginning letters Hp. In addition, the complex does NOT have a cap, as in the GroES co-chaperone 7-mer in the GroEL/GroES complex. Rather, they have a built-in cap that closes on folding. The CCT/TRic chaperonin complex interacts with other "co-chaperones," including a prefoldin 6-mer complex, which inhibits aggregation and "delivers" the protein substrate to CCT/TRic. It also binds to phosducin-like proteins. Well-known substrate proteins for CCT/TRic include actin and tubulin (cytoskeletal proteins) and proteins involved in cell cycle control. Still, many other proteins (up to 10% of cytosolic proteins) might interact with it.
The genes encoding the eight monomers in CCT/TRic arose from gene duplication and subsequent mutation, so they are different from each other (technically, they are called paralogs). The subunits are named α, β, ξ, δ, ε, ζ, η, and θ. Figure \(\PageIndex{20}\) shows generalized structures of CCT/TRic.

Panel A shows a cryoEM of the complex with one subunit outlined in white and an adjacent PDB structure of the alpha subunit (1A6D). The red domain binds ATP. The relative arrangements of the monomers are shown in B.
The Human TRiC/CCT complex (7LUP) with a protein substrate, reovirus outer capsid protein sigma-3, bound in the internal cavity, is shown in the interactive iCn3D model in Figure \(\PageIndex{21}\) (note: it loads slowly given its large size).

Figure \(\PageIndex{21}\): Human TRiC/CCT complex with reovirus outer capsid protein sigma-3 (7LUP) (Copyright; author via source).
Click the image for a popup (which loads slowly) or use this external link: https://structure.ncbi.nlm.nih.gov/i...Dxr3n6oy6zLsZ7
The cyan spacefill protein substrate is the encapsulated reovirus outer capsid protein sigma-3. The top ring 8-mers are in gray ribbon, while the bottom ones are in different colors. Each ring appears to bind 4 ATPs, for a total of 8, when the "attached lids" are closed.
Non-cage chaperones
Various chaperones not part of the nanoparticle chaperonin complex are also involved in protein folding in vivo. Some classify chaperones based on molecular weight into five classes: Hsp60 (which we discussed above as monomers in the chaperonin cage complexes), Hsp70, Hsp90, Hsp104, and the small Hsps. We'll focus mostly on Hsp70 and its "co-chaperone", Hsp 40, and their bacterial analogs, DnaK and DnaJ, respectively.
Hsp70/Hsp 40: Hsp70 binds to hydrophobic regions of proteins, which are more prevalent in unfolded and partially folded proteins, and helps refold them through repeated cycles of binding and release, dependent on ATP cleavage. It also helps unfold proteins through membranes and helps form/dissociate protein complexes. It's found in the cytoplasm and in various organelles, including chloroplasts, mitochondria, the nucleus, and the ER. There is a family of Hsp70 proteins (1, 1A, 1B, 2, 3, 4, 4L, 5–10, 12–18). Hsp70 proteins are made up of two regions. The nucleotide-binding domain (NBD) has intrinsic low ATPase activity and is located in the N-terminal region. The polypeptide substrate-binding domain (SBD) is at the carboxyl terminus. It transiently recognizes short peptides in the target protein. A flexible stretch of conserved amino acids connects the two domains. The substrate-binding domain contains a beta sheet where peptide substrates bind, and an alpha-helical region that acts as a lid.
From an evolutionary perspective, they are among the most conserved proteins. This shows the critical importance of protein folding to life. Some members of the Hsp70 family include DnaK (a bacterial Hsp70 widely studied with its Hsp40 co-chaperone partner, DnaJ), BiP (HSPA5), which assists protein folding in the ER, and alpha-crystallin in eukaryotes. Alpha crystalline comprises 30% of the lens proteins in the eye and, in part, functions to prevent nonspecific, irreversible aggregates. Some Hsp70 proteins are constitutively expressed, while others are induced by elevated temperatures or other stressors that affect protein structure, including radiation, inflammation, and exposure to heavy metals. They are key to maintaining proteostasis.
Hsp70 proteins:
- bind to growing polypeptide chains as they are synthesized on ribosomes.
- express activity as monomers.
- have ATPase activity - i.e., they cleave the phosphoanhydride ATP (which can drive reactions).
- bind short, extended peptides, which stimulate the ATPase activity
- release bound peptides after ATP cleavage
Hsp70s are highly flexible, so it is difficult to get detailed structural information when comparing bound (to target peptides) and free states. Hsp70 appears to clamp onto hydrophobic regions of target proteins, making transient interactions characterized by multiple binding and release steps until protein folding is complete. Hence, the affinity for the Hsp70 proteins must be low enough (i.e., a high dissociation constant, KD, for the target protein) for many binding and release steps. The affinity of the SBD for the target protein is regulated by the nucleotide-binding domain (NBD). When ADP is bound, the Hsp70 is in a closed state and has a high substrate affinity, so the bound target protein's release rate is slow. When ATP is bound, Hsp 70 is in the open state where the rate of association increases 100-fold, and the rate of dissociation increases 1000-fold, so the affinity is lowered significantly. This enables multiple cycles of release, folding, and rebinding.
As mentioned above, Hsp70s have intrinsic but low ATPase activity. When ATP is cleaved to ADP, Hsp70 returns to the closed, high-affinity state. Hence, ATP hydrolysis affects both the binding of protein substrate and the kinetics of folding. This activity increases upon binding of protein substrates and co-chaperones containing a J domain (as found in the bacterial co-chaperone DnaJ). Hence, considerable conformational changes and signaling occur between the NBD and SBDs in a process called allosterism.
The allosteric Hsp70 catalytic cycle is shown in Figure \(\PageIndex{22}\).

Figure \(\PageIndex{22}\): Hsp70 Catalytic Cycle for Protein Folding. Stetz G, Verkhivker GM (2015) Dancing through Life: Molecular Dynamics Simulations and Network-Centric Modeling of Allosteric Mechanisms in Hsp70 and Hsp110 Chaperone Proteins. PLoS ONE 10(11): e0143752. https://doi.org/10.1371/journal.pone.0143752. Creative Commons Attribution License,
Let's explore the catalytic cycle, starting with the left structure. (Note that NBD subdomains are colored as follows: IA (in blue), IB (in red), IIA (in green), IIB (in cyan))
- Left structure (9 o'clock): ADP is bound, so Hsp70 is in the closed (high affinity for protein substrate)state. The SBD consists of two parts or subdomains: the α-lid (magenta) section and the β-sheet subdomain (orange), where the actual protein substrate binds (not shown here). The α-helical lid of the SBD helps to keep the protein substrate from dissociating. The PDB ID for this structure is 2KHO, but no protein substrate is evident if you explore this structure. The two domains of Hsp70, the SBD and the NBD, are connected by the flexible interdomain linker (black) and do not interact; therefore, they are shown in the domain-undocked state.
- Top (12 o'clock): This represents an "intermediate" in which ATP is exchanging for bound ADP, and the complex changes to the open form without releasing the protein substrate. Note that the α-lid no longer interacts as tightly with the β-sheet subdomain of the SBD.
- Right (3 o'clock): The protein substrate (again not shown) is fully released, the α-lid is fully disengaged from the β-sheet subdomain of the SBD, and Hsp70 is in the open (to substrate binding) conformation. The SBD β-sheet subdomain and the NBD domains are still engaged and are shown in the domain-docked conformation.
- Bottom (6 o'clock): Weak protein substrate binding leads to an "intermediate" in which the α-lid engages with the β-sheet subdomain of the SBD. Substrate binding promotes ATP hydrolysis, which occurs as Hsp70 returns to the full closed conformation (left structure, 9 o'clock) with bound ADP
Figure \(\PageIndex{23}\) shows the incredible conformational change that occurs on movement from the ADP-bound higher-affinity closed form of E. Coli Hsp70 (DnaK) (2kho) to the ATP-bound lower-affinity open(to substrate binding) form (4jne). Note how the alpha-helical lid on the left-hand side of the RBD moves to engage with the NBD on the right-hand side.
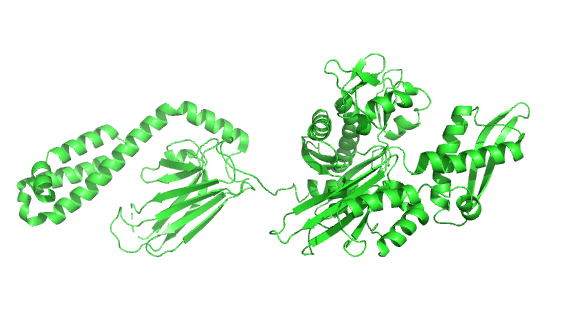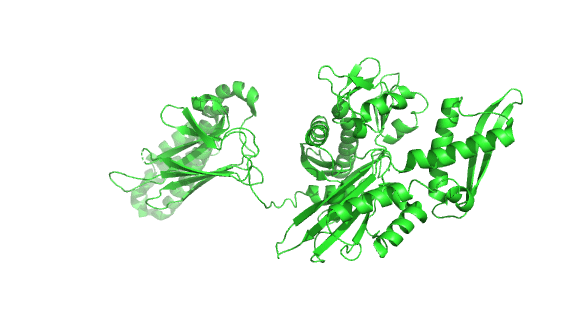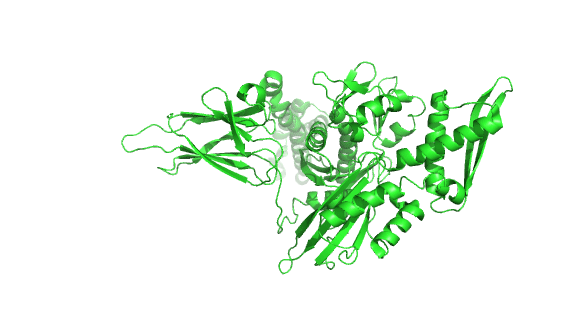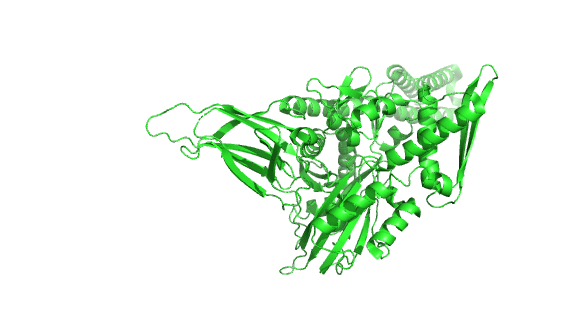
Figure \(\PageIndex{24}\) shows how the chaperonins and Hsp70/40 (DnaK/DnaJ) work in concert.

A few other chaperones acting downstream from Hsp70/Hsp40 and DnaK/DnaJ are shown in the image:
- TF (Trigger factor) and NAC/RAC: These are ribosome-binding chaperones
- Prefoldin (Pfd) binds unfolding proteins and shuffles them off to TRic.
- Hop: mediates interactions between Hsp70/Hsp40 and Hsp90
- Hsp90: This chaperone targets protein receptors (including steroid hormone receptors, protein kinases, and proteins with nucleotide-binding site and leucine-rich repeat (NLR) domains as are found in inflammasomes) and has a cycle similar to Hsp70 with some differences. Hsp90 has N-terminal nucleotide-binding domains, middle domains that interact with protein substrates, and C-terminal dimerization domains, so the protein exists as a homodimer; when bound to ADP or in the absence of nucleotides, the homodimer forms an open V-shape conformation (as shown in the figure above). When ATP binds, a huge conformational change closes the V-shaped clamp. The protein has intrinsic ATPase activity, which reverses the conformational change. Many co-chaperones bind to the HSP90 dimer and modulate the cycle at different points.
Additional Proteins also catalyze protein folding at key steps in the process. Here are two examples.
- Protein Disulfide Isomerase (PDI) - converts wrongly-paired disulfides to their correct pairing. The active site consists of 2 sets of the following sequence - Cys-Gly-His-Cys, in which the pKa of the cysteines is much lower (7.3) than normal (8.5). How would this facilitate disulfide isomerization?
- Peptidyl Prolyl-Isomerase - catalyzes X-Pro isomerization by a mechanism that probably involves bending the X-Pro peptide bond. How would this facilitate the process?
Many proteins have been found to possess PPI activity. One class is the immunophilins. These small cytoplasmic proteins bind anti-rejection drugs to prevent tissue rejection after transplantation. The immunophilin FK506 binding protein (FKBP) binds FK506, while the protein cyclophilin binds the anti-rejection drug cyclosporin. The complex of cyclophilin:cyclosporin or FKBP:FK506 binds to and inhibits calcineurin, an important protein (with phosphatase activity) in immune cells (T cells) required for T cell function. In this case, immunophilin, a drug that binds to calcineurin, inhibits T cell activity, preventing immune attack on the transplanted tissue and rejection. The immunosuppressant drugs (FK506 and cyclosporin) inhibit the PPI activity of their respective immunophilin. The extent to which cyclophilin's PPI activity is required for its function is unclear, but it appears important for some of its biological effects.
Given the complexity of protein folding and the large number of chaperones involved in in vivo folding, it should not be surprising that chaperone proteins bind to protein substrates through more than hydrophobic interactions. Some chaperones (Spy and Trigger Factor) bind to charged regions on the surface of proteins, while the ER proteins calnexin and calreticulin bind to carbohydrates on glycoproteins. GroEL/GroES and TRiC/CCT also interact with protein substrates via electrostatic interactions. Nucleoplasm, a chaperone protein found in the nucleus, binds to histones, which are positively charged DNA-binding proteins.
Unfolded Protein Response
As the site responsible for the folding of membrane proteins and proteins destined for secretion, as well as the major site of lipid synthesis, the endoplasmic reticulum (ER) must maintain homeostatic conditions to ensure proper protein folding. Plasma cells that synthesize antibodies for secretion as part of the immune activation show large increases in protein chaperones and ER membrane size
The unfolded protein response (UPR) signaling pathway is the main pathway controlling ER biology. If demand for protein synthesis in the ER exceeds capacity, unfolded proteins accumulate. This ER stress condition activates IRE1, a transmembrane Ser/Thr protein kinase (which phosphorylates proteins). IRE1 activates a transcription factor that controls the transcription of many genes associated with protein folding in the ER. Another protein, ERAD (ER-associated degradation), returns unfolded proteins to the cytoplasm, where the proteasome degrades them. Proteins involved in lipid synthesis are also activated as lipids are needed for membranes, since the size of the ER increases. If the stress can not be mitigated, the signaling pathway leads to programmed cell death (apoptosis).
Schuck et al. investigated the specific role and importance of the UPR in ER homeostasis, as modeled in the yeast Saccharomyces cerevisiae. The UPR signaling pathway was analyzed using light and electron microscopy to visualize and quantify ER growth under various stress conditions. Western blotting was performed to determine chaperone protein concentrations after stress induction and to assess the association with ER expansion after the ER was exposed to various treatment conditions. The authors found that ER membrane expansion occurred through lipid synthesis, as stress induces the synthesis of proteins involved in lipid synthesis. Expansion failed when the proteins were absent, and the lipid concentration was low. In addition, these lipid synthesis proteins were activated by the UPR signaling pathway. By separating ER size control and UPR signaling, they found that expansion occurred regardless of chaperone protein concentrations. However, if lipid synthesis genes were unavailable, raising ER chaperone levels helped alleviate ER stress.
If unfolded proteins accumulate beyond the cellular machinery's ability to fold them, they can aggregate into structures toxic to the cells, triggering a proteotoxic stress response (PSR). This occurs in a type of immune cell, a cytotoxic T cell, which expresses the CD8 protein on its surface. These cells normally kill virally-infected and tumor cells. In contrast to normal cells, which decrease protein synthesis in response to stress, CD8 cytotoxic T cells increase global protein synthesis in response to chronic viral exposure and in cancer. Protein aggregates form, along with stress granules, which contain precipitated aggregates of translation factors, mRNAs, RNA-binding proteins (RBPs), and other proteins, leading to the formation of exhausted T cells (Tex). Tex can be made artificially by growing normal effector T cells with an amino acid similar to proline called AZC, as shown in Figure \(\PageIndex{25}\) below.

Figure \(\PageIndex{25}\): Structural comparision of Proline and AZC
Given their structural similarity, AZC is incorporated into proteins instead of proline, leading to protein misfolding and subsequent aggregation. This causes Tex formation in the absence of viral challenge. In Tex, there is also an increase in the expression of specialized chaperones, such as gp96 (also called GRP94) from the Hsp90b1 gene and of the chaperone BiP. BiP is an HSP70 chaperone in the ER lumen, where it binds to nascent proteins as they are translocated in the ER. It functions to prevent oligomers and aggegrates, allowing time for folding.
Finally, conversion of normal to Tex cells involves the persistent activation of a special signaling pathway involving the membrane protein AKT. (For more information on AKT, go to Chapter 28.3).
These findings suggest that inhibiting the persistent activation of AKT and the specifically activated chaperones could enable the normal function of cytotoxic T cells and allow them to kill tumor cells.
Redox Chemistry and Protein Folding
In general, we envision the interior of a cell as a reducing environment. Cells have sufficient concentrations of "beta-mercaptoethanol"-like molecules (used to reduce disulfide bonds in proteins in vitro), such as glutathione (g-Glu-Cys-Gly) and reduced thioredoxin (with an active site Cys), to prevent disulfide bond formation in cytoplasmic proteins. For disulfide bonds to occur in a protein, a free sulfhydryl reacts with another one on the protein to form the more oxidized disulfide bond. This reaction occurs more readily if one of the Cys side chains has a lower pKa (due to its immediate environment), making it a better nucleophile. Most cytoplasmic proteins contain Cys with side-chain pKa > 8, which would minimize disulfide bond formation because Cys are predominantly protonated at that pH.
Disulfide bonds in proteins are typically found in extracellular proteins, which help maintain the structure of multisubunit proteins as they become diluted in the extracellular milieu. These proteins destined for secretion are cotranslationally inserted into the endoplasmic reticulum (see below), which presents an oxidizing environment to the folding protein and where sugars are covalently attached to the folding protein and disulfide bonds are formed (see Chapter 3D: Glycoproteins - Biosynthesis and Function). Protein enzymes involved in disulfide bond formation contain free Cys residues, which form mixed disulfides with their target substrate proteins. The enzymes (thiol-disulfide oxidoreductases, protein disulfide isomerases) have a Cys-XY-Cys motif and can promote disulfide bond formation or their reduction to free sulfhydryls. They are especially redox-sensitive since their Cys side chains must cycle between free and disulfide forms.
Intracellular disulfide bonds are found in proteins in the periplasm of prokaryotes and the endoplasmic reticulum (ER) and mitochondrial intermembrane space (IMS) of eukaryotes. For these proteins, the initial stage of protein synthesis (in the cytoplasm) is temporally and spatially separated from disulfide bond formation and the final folding site. Disulfide bonds can be generated in a target protein by concomitant reduction of a disulfide in a protein catalyst, leaving the net number of disulfides constant (unless an independent process reoxidizes the enzyme). Alternatively, a disulfide can be formed by electron transfer to oxidizing agents, such as dioxygen.
In the ER, disulfide bond formation is catalyzed by proteins in the disulfide isomerase family (PDI). To function as catalysts in this process, the PDIs must be in an oxidized state, capable of accepting electrons from the protein target to form disulfide bonds. A flavoprotein, Ero1, recycles PDI back to an oxidized state, and the reduced Ero1 is regenerated by passing electrons to dioxygen to form hydrogen peroxide. In summary, on the formation of disulfides in the ER, electrons flow from the nascent protein to PDIs to the flavin protein Ero1 to dioxygen (i.e., to better and better electron acceptors). The first step is a disulfide shuffle, which, when coupled with subsequent steps, leads to de novo disulfide bond formation.
In the mitochondria, disulfide bond formation occurs in the intermembrane space (IMS) and is guided by the mitochondrial disulfide relay system. This system requires two important proteins: Mia40 and Erv1. Mia40 contains a redox-active disulfide bond, Cys-Pro-Cys, and oxidizes Cys residues in polypeptide chains. Erv1 can then reoxidize Mia40, which, in turn, can be reoxidized by the heme in cytochrome c. Reduced cytochrome C is oxidized by cytochrome C oxidase of the electron transport chain through the transfer of electrons to dioxygen to form water. The importance of IMS protein oxidation is less well understood, but it is believed that oxidative stress caused by dysfunction can lead to neurodegenerative diseases.
A recent review by Riemer et al compares the ER and mitochondrial processes for disulfide bond formation:
- Many more diverse proteins form disulfides in the ER than in the IMS. Most in the IMS have low molecular mass and have two disulfide bonds between helix-turn-helix motifs. These protein substrates include chaperones that facilitate the localization of inner-membrane proteins and proteins involved in electron transport in the inner membrane.
- There are many PDIs in the ER, probably reflecting the structural diversity of protein substrates there. However, Mia40 appears to be the only PDI in the IMS.
- "De novo" disulfide bond formation is initiated by Ero1 in the ER and Erv1 in the IMS. Convergent evolution led to similar structures in both—a 4-helix bundle that binds FAD with two proximal Cys.
- The mitochondrial pathway leads to the formation of water during the reduction of dioxygen, not hydrogen peroxide, thereby minimizing the formation of reactive oxygen species in the mitochondria. The peroxide formed in the ER is presumably converted to an inert form.
- The IMS is in closer contact with the cytoplasm via outer membrane proteins called porins, which allow some glutathione to enter the cytoplasm. The IMS presents a more oxidizing environment than the cytoplasm (with more glutathione). The ER, without a porin analog, would be more oxidizing.
- The reversible formation of disulfides in the ER regulates protein activity.
Disulfide Bond Regulation in the Periplasmic Space of Bacteria
The redox sensitivity of the Cys side chain is important in regulating protein activity. In particular, the thiol group of the amino acid Cys, an important nucleophile often found in the active site, can be modified to control protein activity. The formation of a disulfide bond or the oxidation of free thiols to sulfenic acid, and ultimately to sulfinic or sulfonic acid, can block protein activity. In a reduction reaction, the E. Coli periplasmic protein DsbA (disulfide bond A) converts adjacent free thiols into disulfide-linked Cystine. DsbB is reoxidized by DsbA back to its catalytically active form. What about a periplasmic protein like YbiS with an active site Cys? Since the environment of the periplasm is oxidizing, YbiS is protected from the oxidative conversion of the free Cys to either sulfinic or sulfonic acids, causing the protein to become inactive. The mechanism involves two periplasmic proteins, DsbG and DsbC, similar to thioredoxin. These two proteins can donate electrons to the unprotected thiol, preventing its oxidation and allowing YbiS to remain active in the periplasm. DsbG and DsbC are reduced by another periplasmic protein, DsbD, to maintain activity.
Protein Transport Across Membranes
How does a protein "decide" its final location after synthesis? Protein synthesis occurs in the cytoplasm, but proteins may end up outside the cell, in cell membranes, internalized into various organelles, or remain in the cytoplasm. How is the decision made? There must be signals in the protein that target proteins to various sites in a cell where processing can occur. Proteins destined for secretion or plasma membrane insertion typically have a signal peptide at the N-terminus that binds to a signal recognition particle in a cotranslational process, temporarily arresting translation and nascent folding. This complex docks to signal recognition complex docking sites in the endoplasmic reticulum membrane, where translation continues as the nascent polypeptide extends through a protein pore in the ER membrane. Transport across the ER membrane can also occur, partially or fully, post-translationally if nascent proteins are partially or fully folded through interactions with cytoplasmic chaperones such as Hsp70/40. Figure \(\PageIndex{26}\) shows the cotranslational (a) and post-translational (b) pathways for uptake into the ER lumen.

In both (a) and (b), the protein is shown during synthesis as it is bound to the ribosome (40S/60S) nanoparticles. The cytoplasmic signal recognition particle (SRP) binds to the hydrophobic signal sequence of the nascent protein. The signal is typically at or near the N-terminus of the growing protein. Either co- or post-translationally, the nascent protein is delivered to Sec61, a ribosome receptor and gated pore that allows passage of the target protein. Sec61 is part of a larger ER translocon complex including Sec62 and Sec63. The membrane topology and subunit structure of the Sec proteins are shown in (c). Additional proteins, including the chaperones BiP and Hsp70/40, are also shown.
Protein transport across the endoplasmic reticulum membrane. Mechanism of (a) co-translational and (b) post-translational transport of precursor proteins through the Sec61 channel. (c) Topological domains of Sec61α1/ß/γ, (d) Sec62 and (e) Sec63. We note that (i) Sec63 interacts with Sec62 involving a cluster of negatively charged amino-acid residues near the C terminus of Sec63 and positively charged cluster in the N-terminal domain of Sec62, (ii) Sec62 interacts with the N-terminal domain of Sec61α via its C-terminal domain, (iii) BiP can bind to ER luminal loop 7 of Sec61 α via its substrate-binding domain and mediated by the ATPase domain of BiP and the J-domain in the ER luminal loop of Sec63, (iv) Ca2+-CaM can bind to an IQ motif in the N-terminal domain of Sec61α and (v) LC3 can bind to a LIR motif in the C-terminal domain of Sec62. 40S, 40S ribosome subunit; 60S, 60S ribosome subunit; SR, heterodimeric SRP receptor; SRP, signal recognition particle.
Figure \(\PageIndex{27}\) shows an interactive iCn3D model of the Sec Complex from yeast (6ND1).
.png?revision=1)
Figure \(\PageIndex{27}\): Sec Complex from yeast (6ND1). (Copyright; author via source).
Click the image for a popup (which loads slowly) or use this external link: https://structure.ncbi.nlm.nih.gov/i...6VoV8gTiUCQko8
The model shows Sec 61 and Sec 63 from Figure 25 above. Sec 61 is the ER protein-conducting channel (the analog in prokaryotes is Sec Y).
The model is colored as follows:
- Protein transport protein SEC61 (B)- magenta
- Protein translocation protein SEC63 (A) - blue
- Protein transport protein SSS1 - darker brown
- Protein transport protein SBH1 - green
- Translocation protein SEC66 - gold
- Translocation protein SEC72 - salmon
If the signal sequence of the protein to be imported is not very hydrophobic, it doesn't bind the signal recognition particle and, hence, is imported post-translationally. The Sec61 channel requires additional proteins, Sec62 and Sec63. These also required the BiP Hsp70/40 ATPase for import. Sec63 opens a gate on Sec61, leading to a wide opening that allows proteins into the lipid bilayer.
If destined for secretion, a protein enters the lumen of the ER. Proteins destined for insertion into the cell surface membrane get "stuck" in the ER membrane and, through vesiculation, merge with the Golgi and eventually with the cell surface membrane. Protein import into organelles, such as mitochondria, occurs post-translationally and requires the assistance of protein chaperones. Final protein folding occurs inside the organelle. In both cases, nonnative proteins pass through the membrane and then undergo final folding.
Amino acid sequences encoded in a protein help localize it to the ER and nucleus, as described above (for example, the signal peptide for ER translocation). However, the sequences required to direct proteins to many different organelles and specific molecular condensates remain unclear. A new AI language model, ProtGPS (in analogy to the GPS in your phone), trained on protein sequences from known organelles and compartments, can predict the locations of sequences not included in the training dataset and identify aberrant localization in mutated sequence codes. Hence, there is not only a folding code (we can generally predict a protein's 3D structure from its sequence) but also a localization code. This should be no great surprise, but it took AI to discover the code. Other factors, including the chemical microenvironment of a condensate, are also important.
An intriguing question is how the decision is made to keep a protein either in the membrane or allow it to pass through completely (in the case of proteins destined for secretion). Hessa et al. investigated this "decision-making" process by studying the eukaryotic membrane pore protein complex, Sec 61 translocon (shown in the above figures), whose activity must be closely regulated with the folding of the growing protein. In studying this process, they considered three regions of a membrane: the hydrophobic region, comprising the nonpolar acyl tails of membrane lipids; the interfacial region, in the vicinity of the polar head groups; and the aqueous regions (bulk water) on each side of the head groups. A 19-amino-acid peptide was used as the experimental model protein and added to the translocon. This length was chosen since it is long enough to span the hydrophobic part of the membrane if the peptide were in an alpha-helical conformation (which is common in membrane-spanning proteins). They varied the proportion of amino acids that tend to partition into each of the three regions and studied the disposition of the peptide after interaction with the membrane and translocon. To test whether the results were consistent with thermodynamics of amino acid partitioning into nonpolar environments (rather than kinetic considerations), they used the Wimley-White hydrophobicity scale, based on the free energy of transfer of amino acid side chains into nonpolar environments, to predict target peptide disposition within the membrane. The table below shows the propensity of amino acids to be in each region at equilibrium based on this hydrophobicity scale.
Table: Amino Acid Partitioning Into Membrane Regions
| Region | Amino Acids |
| Bulk water | Arg, Asn, Asp, Gln, Glu, His, Lys, Pro |
| Bulk water + interfacial | Ala, Cys, Gly, Ser, Thr |
| Interfacial | Tyr |
| Hydrophobic | Ile, Leu, Met, Phe, Trp, Val |
Their experimental results were consistent with the predictions of the above scale. If a polyalanine 19 mer was used, no insertion was observed. With five leucines in the peptide, almost 90% was inserted into the membrane. The results would be modeled using a two-state equilibrium: Peptide inserted ↔ Peptide translocated.
They then substituted each of the twenty amino acids into a given position in a target peptide. They used the results to develop an empirical scale for membrane transfer, rather than one based on simple transfer to a nonpolar medium. This new scale matched the hydrophobicity scale, suggesting that insertion and transfer decisions were based on the thermodynamics of side chain partitioning. They also varied the position of the varied amino acids in the test peptide. If the amino acid favored the bulk and/or interfacial region, the peptide would be inserted if that amino acid were at the end of the peptide, not the middle. The peptide had to be amphiphilic for translocation, with one face polar and the other nonpolar.
They developed a simple equilibrium model to show the processes involved, as shown below in a top-down view of the membrane in Figure \(\PageIndex{28}\).
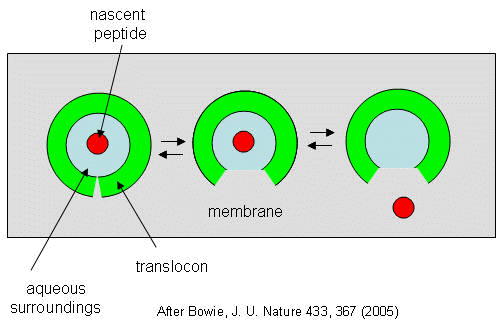
The translocon, shown in green, has a water-filled pore and a sideways opening toward the membrane interior. The target peptide enters the pore. Transient conformational changes in the pore expose the peptide to the nonpolar membrane core. Based on the above transcription, the target peptide samples both the aqueous and nonpolar environments and partitions into them. If it partitions more favorably into the hydrophobic core, it will, causing the peptide to become membrane-bound. Otherwise, it will pass through to the other side. This can be modeled as an equilibrium process if the translocation rate is slow relative to the rates of translocon conformational change and the peptide's environmental sampling. The process becomes more complicated if the target is a large protein.
Bacterial toxin proteins also have evolved ways to pass through a cell membrane, again in a nonnative state, via a membrane protein channel. Krantz et al have recently discovered how the anthrax toxin protein moves through eukaryotic cell membranes. Three anthrax proteins are involved. One is a "prepore" protein that binds to specific proteins on the cell membrane, where it is activated by limited proteolysis to form a pore protein that assembles into a homoheptamer in the membrane. Two other proteins secreted by the bacteria, lethal factor and edema factor, bind to the heptamer complex, and the whole assembly is then taken up into the cell by invagination, forming a vesicle with the pore complex in the membrane. This vesicle fuses with a lysosome in the cell, and upon acidification, a conformational change in the pre-pore complex triggers its activation. The lethal and edema factors unfold partially, possibly to a molten globule state, and are then passed through the pore into the cell, where they exert their toxic influences. An electrochemical potential gradient (which we will discuss later in the semester) is required to pass the factors through the membrane. The active pore further unravels the factor protein, facilitating transport.
Krantz et al. studied the pore protein by mutating two amino acids, Phe427 and Ser429, on each monomer to Cys. They then modified the Cys with [2-(trimethylammonium) ethylmethanethiosulfonate and observed effects on ion conductance of the pore and pore conformations. They noted that ion conductance was blocked when both residues were mutated and chemically modified, suggesting that these side chains were localized in the narrowest part of the channel. When Phe 427 alone was mutated to smaller side chains (Ala), ion conductance increased, but peptide transfer from the factor proteins was inhibited. This suggested that an aromatic ring in the narrow part of the channel opening participates in the translocation of bacterial proteins across the membrane. They then analyzed the transport of various small molecules with varying hydrophobicity through the wild-type pore. Their results were consistent with the binding of the molecules through hydrophobic and aromatic π-π interactions. They suggest a transport mechanism, consistent with their data, in which the unfolded protein "ratchets" through the pore, promoting the unfolding of the factor protein and exposing more hydrophobic groups to the nonpolar aromatic ring. This mechanism is similar to how the chaperone complex GroEL/GroES unfolds proteins in its large central cavity, a process that requires ATP hydrolysis rather than a transmembrane potential. In addition, the Sec61 translocon in the inner membrane of bacteria and eukaryotic ER membranes also has a pore containing a ring of hydrophobic groups (Ile).
Summary
In this chapter, we explore the dynamic nature of protein folding through the lens of thermodynamics and molecular kinetics. Unlike static images of folded proteins or lipid aggregates, protein folding is an inherently dynamic process that unfolds in three dimensions, navigating an expansive free-energy landscape. We begin by contrasting a simplified “funnel” view—where an unfolded protein smoothly funnels into a single, low-energy native state—with a more realistic rugged landscape featuring multiple local energy minima and intermediates. These intermediates, which may be transiently trapped, illustrate how proteins sample a vast array of conformations on the way to their final structure.
The discussion introduces the Levinthal paradox, which highlights the astronomical number of possible conformations that a protein could theoretically explore. Yet, proteins fold within seconds by efficiently funneling through native-like intermediates rather than random conformational sampling. This efficiency is underscored by the idea that the protein’s amino acid sequence inherently encodes the necessary information for rapid and correct folding.
A key experimental model is Anfinsen’s classic RNase refolding experiment, where a denatured protein—unfolded by urea and reducing agents—is allowed to refold in an oxidizing environment. This experiment demonstrated that the primary sequence contains all the information required for the protein to achieve its native conformation, despite the potential for myriad disulfide bond combinations (illustrated via the “socks” analogy). Moreover, the chapter covers various experimental techniques such as fluorescence, circular dichroism, and NMR D/H exchange that have been used to monitor folding transitions and probe the existence of intermediates.
Finally, the chapter contrasts in vitro folding—conducted under highly controlled conditions—with the complex, chaperone-assisted folding processes that occur in vivo. In cells, proteins fold as they are synthesized on ribosomes and often require assistance from molecular chaperones to prevent misfolding and aggregation. This integrated view of protein folding emphasizes that both intrinsic sequence information and the cellular environment contribute to the efficiency and fidelity of the folding process.
Overall, this chapter provides a comprehensive overview of the kinetic and thermodynamic principles underlying protein folding, the experimental methods used to study this process, and the biological mechanisms that ensure proper folding in vivo.