W2018_Bis2A_Lecture04_reading
- Page ID
- 25316
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Hydrogen Bonds
When hydrogen forms a polar covalent bond with an atom of higher electronegativity, the region around the hydrogen will have a fractional positive charge (termed δ+). When this fractional positive charge encounters a partial negative charge (termed δ-) from another electronegative atom to which the hydrogen is NOT bound, AND it is presented to that negative charge in a suitable orientation, a special kind of interaction called a hydrogen bond can form. While chemists are still debating the exact nature of the hydrogen bond, in BIS2A, we like to conceive of it as a weak electrostatic interaction between the δ+ of the hydrogen and the δ- charge on an electronegative atom. We call the molecule that contributes the partially charged hydrogen atom "the hydrogen bond donor" and the atom with the partial negative charge the "hydrogen bond acceptor." You will be asked to start learning to recognize common biological hydrogen bond donors and acceptors and to identify putative hydrogen bonds from models of molecular structures.
Hydrogen bonds are common in biology both within and between all types of biomolecules. Hydrogen bonds are also critical interactions between biomolecules and their solvent, water.
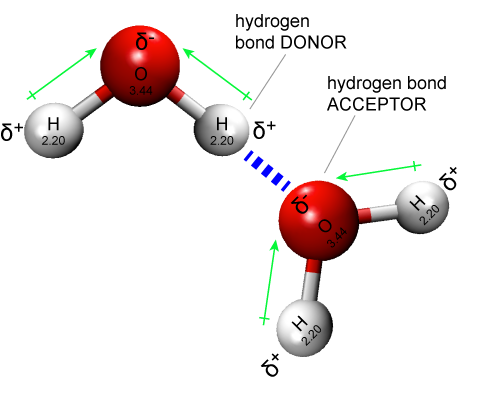
Figure 1: Two water molecules are depicted forming a hydrogen bond (drawn as a dashed blue line). The water molecule on top "donates" a partially charged hydrogen while the water molecule on the bottom accepts that partial charge by presenting a complementary negatively charged oxygen atom.
Attribution: Marc T. Facciotti (original work)
Chemical reactions
Chemical reactions occur when two or more atoms bond together to form molecules or when bonded atoms are broken apart. The substances that "go in" to a chemical reaction are called the reactants (by convention, these are usually listed on the left side of a chemical equation), and the substances found that "come out" of the reaction are known as the products (by convention, these are usually found on the right side of a chemical equation). An arrow linking the reactants and products is typically drawn between them to indicate the direction of the chemical reaction. By convention, for one-way reactions (a.k.a. unidirectional), reactants are listed on the left and products on the right of the single-headed arrow. However, you should be able to identify reactants and products of unidirectional reactions that are written in any orientation (e.g. right-to-left; top-to-bottom, diagonal right-to-left, around a circular arrow, etc.) by using the arrow to orient yourself.
2H2O2 (hydrogen peroxide) → 2H2O (water) + O2 (oxygen)
Note: possible discussion
Practice: Identify the reactants and products of the reaction involving hydrogen peroxide above.
Note: possible discussion
When we write H2O2 to represent the molecule of hydrogen peroxide, it is a model representing an actual molecule. What information about the molecule is immediately communicated by this molecular formula? That is, what do you know about the molecule just by looking at the term H2O2? What information is not explicitly communicated about this molecule by looking only at the formula?
While all chemical reactions can technically proceed in both directions some reactions tend to favor one direction over the other. Depending on the degree to which a reaction spontaneously proceed in either both or one direction a different name can be given to characterize the reactions reversibility. Some chemical reactions, such as the one shown above, proceed mostly in one direction with the "reverse" direction happening on such long time scales or with such low probability that, for practical purposes, we ignore the "reverse" reaction. These unidirectional reactions are also called irreversible reactions and are depicted with a single-headed (unidirectional) arrow. By contrast, reversible reactions are those that can readily proceed in either direction. Reversible reactions are usually depicted by a chemical equation with a double-headed arrow pointing toward both the reactants and the products. In practice, you will find a continuum of chemical reactions; some proceed mostly in one direction and nearly never reverse, while others change direction easily depending on various factors like the relative concentrations of reactants and products. These terms are just ways of describing reactions with different equilibrium points.
Use of vocabulary
You may have realized that the terms "reactants" and "products" are relative to the direction of the reaction. If you have a reaction that is reversible, though, the products of running the reaction in one direction become the reactants of the reverse. You can label the same compound with two different terms. That can be a bit confusing. So, what is one to do in such cases? The answer is that if you want to use the terms "reactants" and "products", you must be clear about the direction of reaction that you are referring to - even for when discussing reversible reactions. The choice of terms, "reactants" or "products" that you use will communicate to others the directionality of the reaction that you are considering.
Let's look at an example of a reversible reaction in biology and discuss an important extension of these core ideas that arises in a biological system. In human blood, excess hydrogen ions (H+) bind to bicarbonate ions (HCO3-), forming an equilibrium state with carbonic acid (H2CO3). This reaction is readily reversible. If carbonic acid were added to this system, some of it would be converted to bicarbonate and hydrogen ions as the chemical system sought out equilibrium.
\[HCO_3^−+ H^+\rightleftharpoons H_2CO_3\]
The example above examines and "idealized" chemical systems as it might occur in a test-tube. In biological systems, however, equilibrium for a single reaction is rarely reached as it might be in the test-tube. In biological systems, reactions do not occur in isolation. Rather, the concentrations of the reactants and/or products are constantly changing, often with a product of one reaction being a reactant for another reaction. These linked reactions form what are known as biochemical pathways. The immediate example below illustrates this point. While the reaction between the bicarbonate/proton and carbonic acid is highly reversible, it turns out that, physiologically, this reaction is usually "pulled" toward the formation of carbonic acid. Why? As shown below, carbonic acid becomes a reactant for another biochemical reaction—the conversion of carbonic acid to CO2 and H2O. This conversion reduces the concentration of H2CO3, thus pulling the reaction between bicarbonate and H+ to the right. Moreover, a third, unidirectional reaction, the removal of CO2 and H2O from the system, also pulls the reaction further to the right. These kinds of reactions are important contributors to maintaining the H+ homeostasis of our blood.
\[ HCO_3^- + H^+ \rightleftharpoons H_2CO_3 \rightleftharpoons CO_2 + H_20 \rightarrow waste\]
The reaction involving the synthesis of carbonic acid is actually linked to its breakdown into \(CO_2\) and \(H_2O\). These products are then removed from the system/body when they are exhaled. Together, the breakdown of carbonic acid and the act of exhaling the products pull the first reaction to the right.
What is the role of Acid/Base Chemistry in Bis2A?
We have learned that the behavior of chemical functional groups depends greatly on the composition, order and properties of their constituent atoms. As we will see, some of the properties of key biological functional groups can be altered depending on the pH (hydrogen ion concentration) of the solution that they are bathed in.
For example, some of the functional groups on the amino acid molecules that make up proteins can exist in different chemical states depending on the pH. We will learn that the chemical state of these functional groups in the context of a protein can have have a profound effect on the shape of protein or its ability to carry out chemical reactions. As we move through the course we will see numerous examples of this type of chemistry in different contexts.
pH is formally defined as:
\[ pH = -\log_{10} [H^+]\]
In the equation above, the square brackets surrounding \(H^+\) indicate concentration. If necessary, try a math review at wiki logarithm or kahn logarithm. Also see: concentration dictionary or wiki concentration.
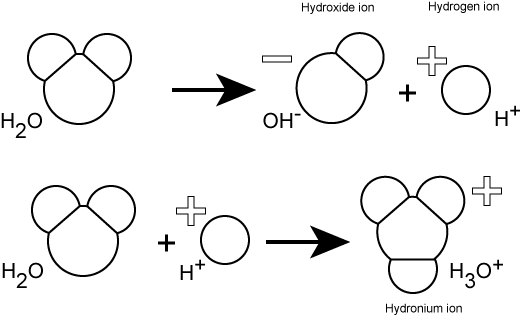
Hydrogen ions are spontaneously generated in pure water by the dissociation (ionization) of a small percentage of water molecules into equal numbers of hydrogen (H+) ions and hydroxide (OH-) ions. While the hydroxide ions are kept in solution by their hydrogen bonding with other water molecules, the hydrogen ions, consisting of naked protons, are immediately attracted to un-ionized water molecules, forming hydronium ions (H30+).
Still, by convention, scientists refer to hydrogen ions and their concentration as if they were free in this state in liquid water. This is another example of a shortcut that we often take - it's easier to write H+ rather than H3O+. We just need to realize that this shortcut is being taken; otherwise confusion will ensue.
The pH of a solution is a measure of the concentration of hydrogen ions in a solution (or the number of hydronium ions). The number of hydrogen ions is a direct measure of how acidic or how basic a solution is.
The pH scale is logarithmic and ranges from 0 to 14 (Figure 2). We define pH=7.0 as neutral. Anything with a pH below 7.0 is termed acidic and any reported pH above 7.0 is termed alkaline or basic. Extremes in pH in either direction from 7.0 are usually considered inhospitable to life, although examples exist to the contrary. pH levels in the human body usually range between 6.8 and 7.4, except in the stomach where the pH is more acidic, typically between 1 and 2.
Watch this video for a straightforward explanation of pH and its logarithmic scale.
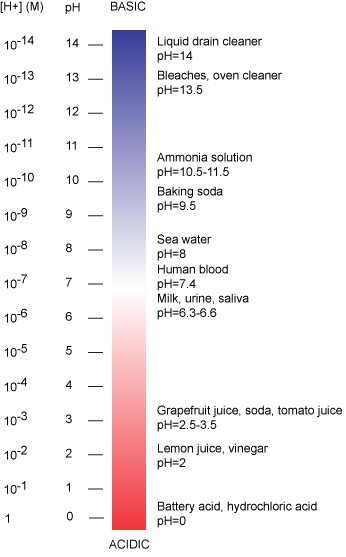
Figure 2: The pH scale ranging from acidic to basic with various biological compounds or substances that exist at that particular pH. Attribution: Marc T. Facciotti
For additional information:
Watch this video for an alternative explanation of pH and its logarithmic scale.
The concentration of hydrogen ions dissociating from pure water is 1 × 10-7 moles H+ ions per liter of water.
1 mole (mol) of a substance (which can be atoms, molecules, ions, etc), is defined as being equal to 6.02 x 1023 particles of the substance. Therefore, 1 mole of water is equal to 6.02 x 1023 water molecules. The pH is calculated as the negative of the base 10 logarithm of this unit of concentration. The log10 of 1 × 10-7 is -7.0, and the negative of this number yields a pH of 7.0, which is also known as neutral pH.
Non-neutral pH readings result from dissolving acids or bases in water. High concentrations of hydrogen ions yields a low pH number, whereas low levels of hydrogen ions result in a high pH.
This inverse relationship between pH and the concentration of protons confuses many students - take the time to convince yourself that you "get it."
An acid is a substance that increases the concentration of hydrogen ions (H+) in a solution, usually by having one of its hydrogen atoms dissociate. For example, we have learned that the carboxyl functional group is an acid. The hydrogen atom can dissociate from the oxygen atom resulting in a free proton and a negatively charged functional group. A base provides either hydroxide ions (OH–) or other negatively charged ions that combine with hydrogen ions, effectively reducing the H+ concentration in the solution and thereby raising the pH. In cases where the base releases hydroxide ions, these ions bind to free hydrogen ions, generating new water molecules. For example, we have learned that the amine functional group is a base. The nitrogen atom will accept hydrogen ions in solution, thereby reducing the number of hydrogen ions which raises the pH of the solution.

Additional pH resources
Here are some additional links on pH and pKa to help learn the material. Note that there is an additional module devoted to pKa.
Chemwiki Links
Khan Academy Links
Simulations
Buffers
Since changes in pH can dramatically influence the function of many biomolecules, unicellular and multicellular organisms have developed various means of protecting themselves against changes in pH. One of these mechanisms is the use of small molecules that can, based on their chemical properties, be classified as buffers. Buffers are typically small molecules that can reversibly bind and unbind protons in solution. If the pH in an environment is lower than the pKa of a protonatable functional group on the buffer molecule, that group will tend to become protonated and therefore "remove" a proton from solution. Alternatively, if the pH in an environment is higher than the pKa of the same protonatable functional group on the buffer molecule, that group will tend to become or stay deprotonated, lowering the local pH.
Maintaining a constant blood pH is critical to a person’s well-being. The buffer maintaining the pH of human blood involves carbonic acid (H2CO3), bicarbonate ion (HCO3–), and carbon dioxide (CO2). When bicarbonate ions combine with free hydrogen ions and become carbonic acid, hydrogen ions are removed, moderating pH changes. Similarly, excess carbonic acid can be converted to carbon dioxide gas and exhaled through the lungs. This prevents too many free hydrogen ions from building up in the blood and dangerously reducing its pH. Likewise, if too much OH– is introduced into the system, carbonic acid will react with it to create bicarbonate, lowering the pH. Without this buffer system, the body’s pH would fluctuate enough to put survival in jeopardy.

Figure 1. This diagram shows the body’s buffering of blood pH levels. The blue arrows show the process of raising pH as more CO2 is made.
Other examples of buffers are antacids used to combat excess stomach acid. Many of these over-the-counter medications work in the same way as blood buffers, usually with at least one ion capable of absorbing hydrogen and moderating pH, bringing relief to those that suffer from “heartburn” after eating. In addition to the many beneficial characteristics of water, its unique properties that contribute to this capacity to balance pH are essential to sustaining life on Earth.
Types of Biomolecules:
In BIS2A, we are concerned primarily with developing a functional understanding of a biological cell. In the context of the Design Challenge, we might say that we want to solve the problem of building a cell. If we break this big task down into smaller problems, or alternatively, ask what types of things do we need to understand in order to do this, it would be reasonable to conclude that understanding what the cell is made of would be important. That said, it isn't sufficient to appreciate WHAT the cell is made of. We also need to understand the PROPERTIES of the materials that make up the cell. This requires us to dig into a little bit of chemistry—the science of the "stuff" (matter) that makes up the world we know. As a student in BIS2A, you will be asked to classify macromolecules into groups by looking at their chemical composition and, based on this composition, also infer some of the properties they might have.
Carbohydrates
Carbohydrates are one of the four main classes of macromolecules that make up all cells and are an essential part of our diet; grains, fruits, and vegetables are all natural sources. While we may be most familiar with the role carbohydrates play in nutrition, they also have a variety of other essential functions in humans, animals, plants, and bacteria. In this section, we will discuss and review basic concepts of carbohydrate structure and nomenclature, as well as a variety of functions they play in cells.
Molecular structures
In their simplest form, carbohydrates can be represented by the stoichiometric formula (CH2O)n, where n is the number of carbons in the molecule. For simple carbohydrates, the ratio of carbon-to-hydrogen-to-oxygen in the molecule is 1:2:1. This formula also explains the origin of the term “carbohydrate”: the components are carbon (“carbo”) and the components of water (“hydrate”). Simple carbohydrates are classified into three subtypes: monosaccharides, disaccharides, and polysaccharides, which will be discussed below. While simple carbohydrates fall nicely into this 1:2:1 ratio, carbohydrates can also be structurally more complex. For example, many carbohydrates contain functional groups (remember them from our basic discussion about chemistry) besides the obvious hydroxyl. For example, carbohydrates can have phosphates or amino groups substituted at a variety of sites within the molecule. These functional groups can provide additional properties to the molecule and will alter its overall function. However, even with these types of substitutions, the basic overall structure of the carbohydrate is retained and easily identified.
Nomenclature
One issue with carbohydrate chemistry is the nomenclature. Here are a few quick and simple rules:
- Simple carbohydrates, such as glucose, lactose, or dextrose, end with an "-ose."
- Simple carbohydrates can be classified based on the number of carbon atoms in the molecule, as with triose (three carbons), pentose (five carbons), or hexose (six carbons).
- Simple carbohydrates can be classified based on the functional group found in the molecule, i.e ketose (contains a ketone) or aldose (contains an aldehyde).
- Polysaccharides are often organized by the number of sugar molecules in the chain, such as in a monosaccharide, disaccharide, or trisaccharide.
For a short video on carbohydrate classification, see the 10-minute Khan Academy video by clicking here.
Monosaccharides
Monosaccharides ("mono-" = one; "sacchar-" = sweet) are simple sugars; the most common is glucose. In monosaccharides, the number of carbons usually ranges from three to seven. If the sugar has an aldehyde group (the functional group with the structure R-CHO), it is known as an aldose; if it has a ketone group (the functional group with the structure RC(=O)R'), it is known as a ketose.
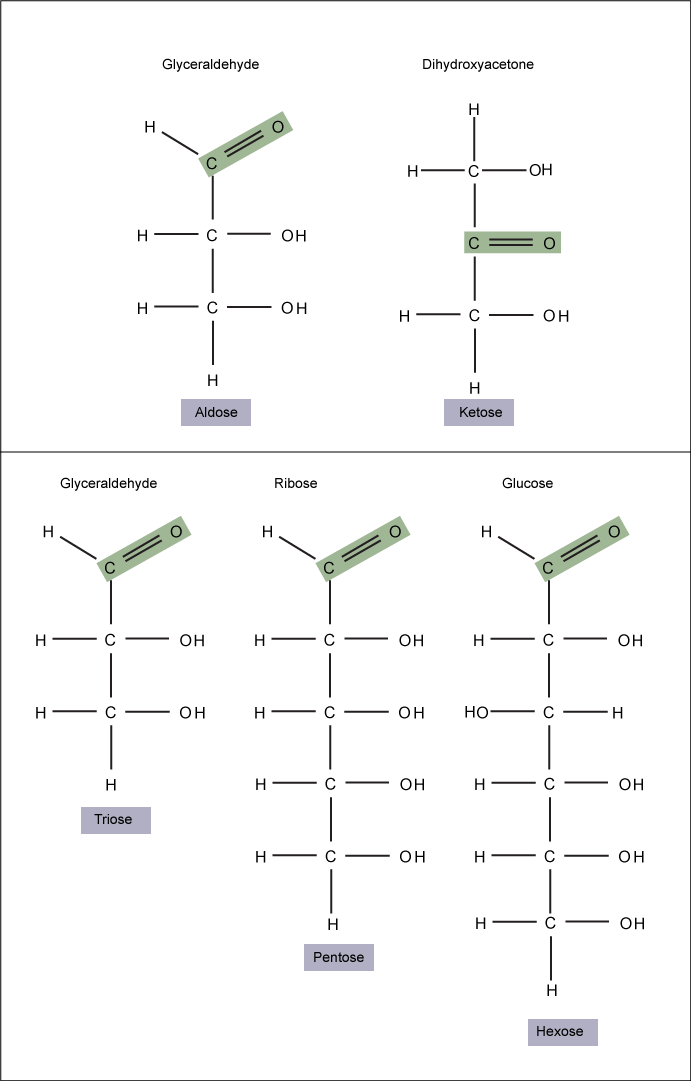
Figure 1. Monosaccharides are classified based on the position of their carbonyl group and the number of carbons in the backbone. Aldoses have a carbonyl group (indicated in green) at the end of the carbon chain and ketoses have a carbonyl group in the middle of the carbon chain. Trioses, pentoses, and hexoses have three, five, and six carbons in their backbones, respectively. Attribution: Marc T. Facciotti (own work)
Glucose versus galactose
Galactose (part of lactose, or milk sugar) and glucose (found in sucrose, glucose disaccharride) are other common monosaccharides. The chemical formula for glucose and galactose is C6H12O6; both are hexoses, but the arrangements of the hydrogens and hydroxyl groups are different at position C4. Because of this small difference, they differ structurally and chemically and are known as chemical isomers because of the different arrangement of functional groups around the asymmetric carbon; both of these monosaccharides have more than one asymmetric carbon (compare the structures in the figure below).
Fructose versus both glucose and galactose
A second comparison can be made when looking at glucose, galactose, and fructose (the second carbohydrate that with glucose makes up the disaccharide sucrose and is a common sugar found in fruit). All three are hexoses; however, there is a major structural difference between glucose and galactose versus fructose: the carbon that contains the carbonyl (C=O).
In glucose and galactose, the carbonyl group is on the C1 carbon, forming an aldehyde group. In fructose, the carbonyl group is on the C2 carbon, forming a ketone group. The former sugars are called aldoses based on the aldehyde group that is formed; the latter is designated as a ketose based on the ketone group. Again, this difference gives fructose different chemical and structural properties from those of the aldoses, glucose, and galactose, even though fructose, glucose, and galactose all have the same chemical composition: C6H12O6.
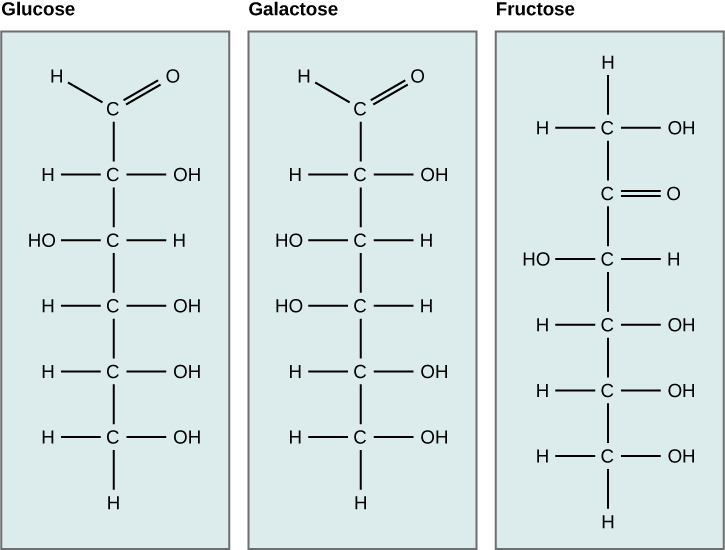
Figure 2. Glucose, galactose, and fructose are all hexoses. They are structural isomers, meaning they have the same chemical formula (C6H12O6) but a different arrangement of atoms.
Linear versus ring form of the monosaccharides
Monosaccharides can exist as a linear chain or as ring-shaped molecules. In aqueous solutions, monosaccharides are usually found in ring form (Figure 3). Glucose in a ring form can have two different arrangements of the hydroxyl group (OH) around the anomeric carbon (C1 that becomes asymmetric in the process of ring formation). If the hydroxyl group is below C1 in the sugar, it is said to be in the alpha (α) position, and if it is above C1 in the sugar, it is said to be in the beta (β) position.
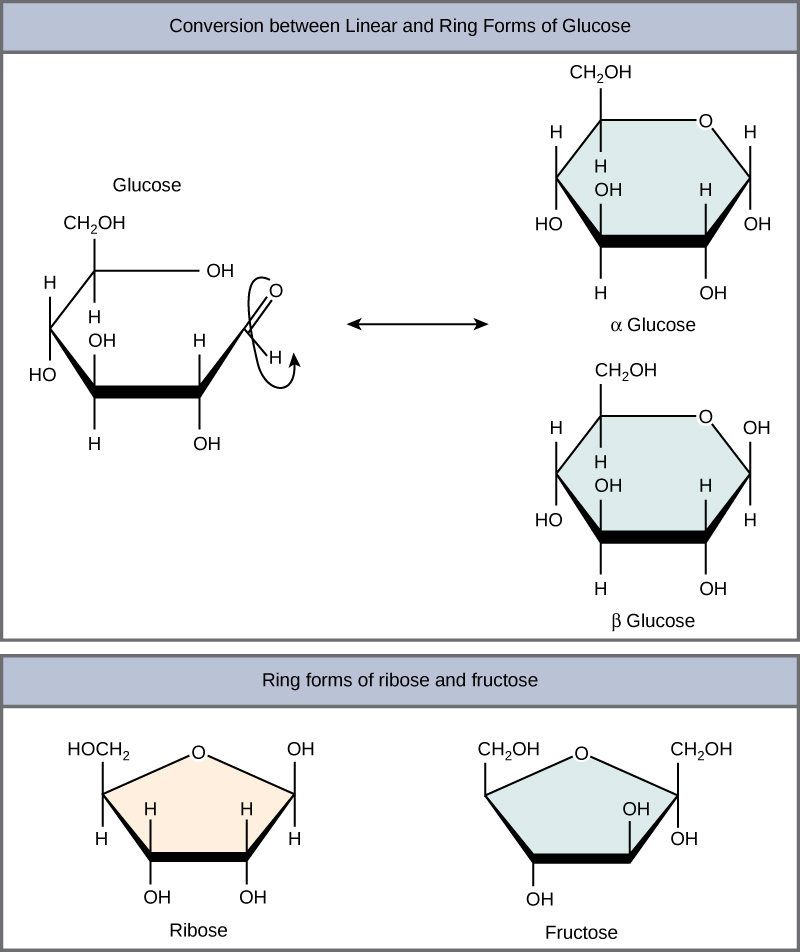
Figure 3. Five- and six-carbon monosaccharides exist in equilibrium between linear and ring form. When the ring forms, the side chain it closes on is locked into an α or β position. Fructose and ribose also form rings, although they form five-membered rings as opposed to the six-membered ring of glucose.
Disaccharides
Disaccharides ("di-" = two) form when two monosaccharides undergo a dehydration reaction (also known as a condensation reaction or dehydration synthesis). During this process, the hydroxyl group of one monosaccharide combines with the hydrogen of another monosaccharide, releasing a molecule of water and forming a covalent bond. A covalent bond formed between a carbohydrate molecule and another molecule (in this case, between two monosaccharides) is known as a glycosidic bond. Glycosidic bonds (also called glycosidic linkages) can be of the alpha or the beta type.
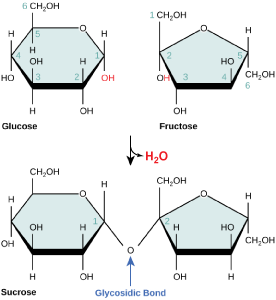
Figure 4. Sucrose is formed when a monomer of glucose and a monomer of fructose are joined in a dehydration reaction to form a glycosidic bond. In the process, a water molecule is lost. By convention, the carbon atoms in a monosaccharide are numbered from the terminal carbon closest to the carbonyl group. In sucrose, a glycosidic linkage is formed between the C1 carbon in glucose and the C2 carbon in fructose.
Common disaccharides include lactose, maltose, and sucrose (Figure 5). Lactose is a disaccharide consisting of the monomers glucose and galactose. It is found naturally in milk. Maltose, or malt/grain sugar, is a disaccharide formed by a dehydration reaction between two glucose molecules. The most common disaccharide is sucrose, or table sugar, which is composed of the monomers glucose and fructose.
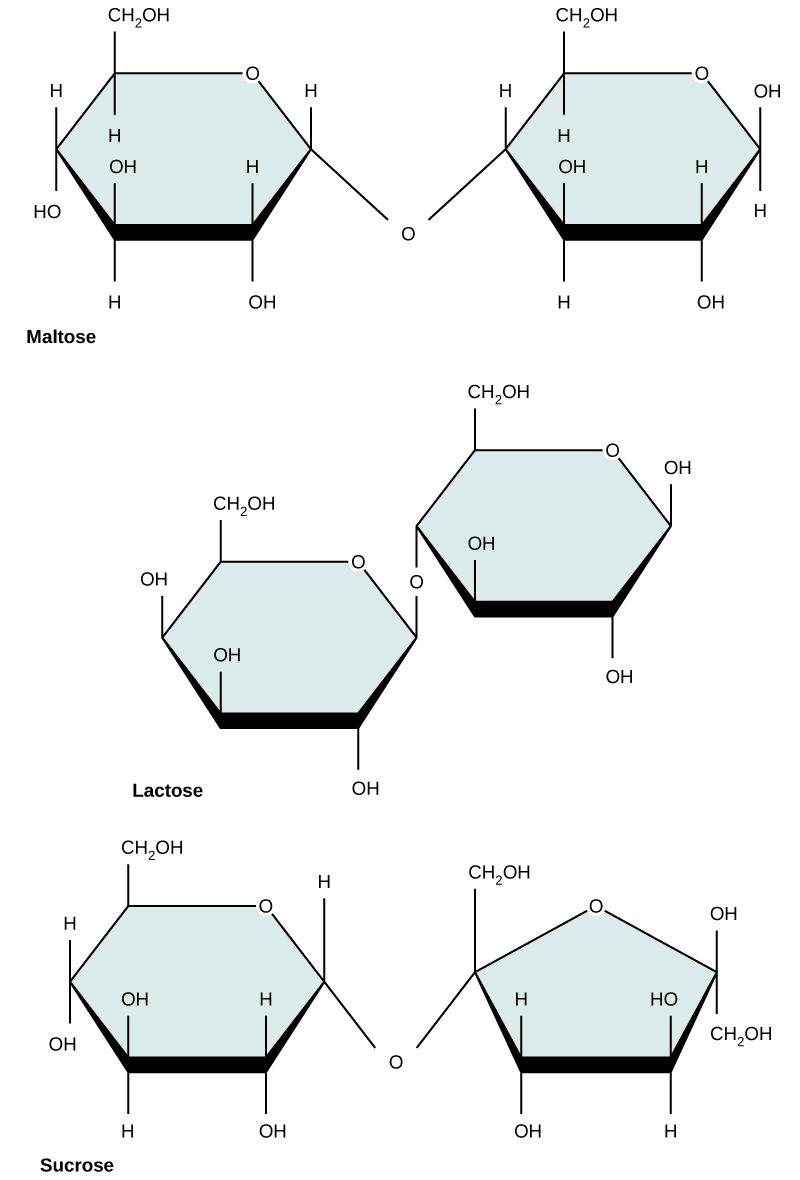
Figure 5. Common disaccharides include maltose (grain sugar), lactose (milk sugar), and sucrose (table sugar).
Polysaccharides
A long chain of monosaccharides linked by glycosidic bonds is known as a polysaccharide ("poly-" = many). The chain may be branched or unbranched, and it may contain different types of monosaccharides. The molecular weight may be 100,000 Daltons or more, depending on the number of monomers joined. Starch, glycogen, cellulose, and chitin are primary examples of polysaccharides.
Starch is the stored form of sugars in plants and is made up of a mixture of amylose and amylopectin; both are polymers of glucose. Plants are able to synthesize glucose. Excess glucose, the amount synthesized that is beyond the plant’s immediate energy needs, is stored as starch in different plant parts, including roots and seeds. The starch in the seeds provides food for the embryo as it germinates and can also act as a source of food for humans and animals who may eat the seed. Starch that is consumed by humans is broken down by enzymes, such as salivary amylases, into smaller molecules, such as maltose and glucose.
Starch is made up of glucose monomers that are joined by 1-4 or 1-6 glycosidic bonds; the numbers 1-4 and 1-6 refer to the carbon number of the two residues that have joined to form the bond. As illustrated in Figure 6, amylose is starch formed by unbranched chains of glucose monomers (only 1-4 linkages), whereas amylopectin is a branched polysaccharide (1-6 linkages at the branch points).

Figure 6. Amylose and amylopectin are two different forms of starch. Amylose is composed of unbranched chains of glucose monomers connected by 1-4 glycosidic linkages. Amylopectin is composed of branched chains of glucose monomers connected by 1-4 and 1-6 glycosidic linkages. Because of the way the subunits are joined, the glucose chains have a helical structure. Glycogen (not shown) is similar in structure to amylopectin but more highly branched.
Glycogen
Glycogen is a common stored form of glucose in humans and other vertebrates. Glycogen is the animal equivalent of starch and is a highly branched molecule usually stored in liver and muscle cells. Whenever blood glucose levels decrease, glycogen is broken down to release glucose in a process known as glycogenolysis.
Cellulose
Cellulose is the most abundant natural biopolymer. The cell wall of plants is mostly made of cellulose, which provides structural support to the cell. Wood and paper are mostly cellulosic in nature. Cellulose is made up of glucose monomers that are linked by β 1-4 glycosidic bonds.
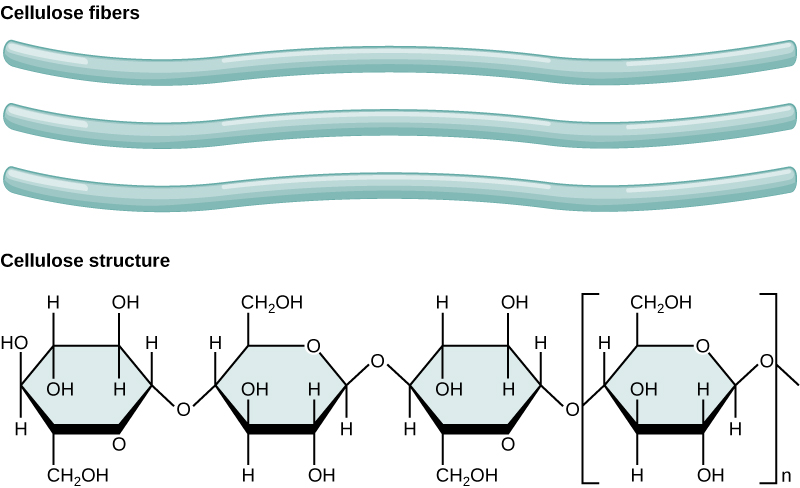
Figure 7. In cellulose, glucose monomers are linked in unbranched chains by β 1-4 glycosidic linkages. Because of the way the glucose subunits are joined, every glucose monomer is flipped relative to the next one, resulting in a linear, fibrous structure.
Note: possible discussion
Cellulose is not very soluble in water in its crystalline state; this can be approximated by the stacked cellulose fiber depiction above. Can you suggest a reason for why (based on the types of interactions) it might be so insoluble?
As shown in the figure above, every other glucose monomer in cellulose is flipped over, and the monomers are packed tightly as extended, long chains. This gives cellulose its rigidity and high tensile strength—which is so important to plant cells. While the β 1-4 linkage cannot be broken down by human digestive enzymes, herbivores such as cows, koalas, buffalos, and horses are able, with the help of the specialized flora in their stomach, to digest plant material that is rich in cellulose and use it as a food source. In these animals, certain species of bacteria and protists reside in the rumen (part of the digestive system of herbivores) and secrete the enzyme cellulase. The appendix of grazing animals also contains bacteria that digest cellulose, giving it an important role in the digestive systems of ruminants. Cellulases can break down cellulose into glucose monomers that can be used as an energy source by the animal. Termites are also able to break down cellulose because of the presence of other organisms in their bodies that secrete cellulases.
Interactions with carbohydrates
We have just discussed the various types and structures of carbohydrates found in biology. The next thing to address is how these compounds interact with other compounds. The answer to that is that it depends on the final structure of the carbohydrate. Because carbohydrates have many hydroxyl groups associated with the molecule, they are therefore excellent H-bond donors and acceptors. Monosaccharides can quickly and easily form H-bonds with water and are readily soluble. All of those H-bonds also make them quite "sticky". This is also true for many disaccharides and many short-chain polymers. Longer polymers may not be readily soluble.
Finally, the ability to form a variety of H-bonds allows polymers of carbohydrates or polysaccharides to form strong intramolecular and intermolocular bonds. In a polymer, because there are so many H-bonds, this can provide a lot of strength to the molecule or molecular complex, especially if the polymers interact. Just think of cellulose, a polymer of glucose, if you have any doubts.
Nucleic acids
There are two types of nucleic acids in biology: DNA and RNA. DNA carries the heritable genetic information of the cell and is composed of two antiparallel strands of nucleotides arranged in a helical structure. Each nucleotide subunit is composed of a pentose sugar (deoxyribose), a nitrogenous base, and a phosphate group. The two strands associate via hydrogen bonds between chemically complementary nitrogenous bases. Interactions known as "base stacking" interactions also help stabilize the double helix. By contrast to DNA, RNA can be either be single stranded, or double stranded. It too is composed of a pentose sugar (ribose), a nitrogenous base, and a phosphate group. RNA is a molecule of may tricks. It is involved in protein synthesis as a messenger, regulator, and catalyst of the process. RNA is also involved in various other cellular regulatory processes and helps to catalyze some key reactions (more on this later). With respect to RNA, in this course we are primarily interested in (a) knowing the basic molecular structure of RNA and what distinguishes it from DNA, (b) understanding the basic chemistry of RNA synthesis that occurs during a process called transcription, (c) appreciating the various roles that RNA can have in the cell, and (d) learning the major types of RNA that you will encounter most frequently (i.e. mRNA, rRNA, tRNA, miRNA etc.) and associating them with the processes they are involved with. In this module we focus primarily on the chemical structures of DNA and RNA and how they can be distinguished from one another.
Nucleotide structure
The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA and RNA are made up of monomers known as nucleotides. Individual nucleotides condense with one another to form a nucleic acid polymer. Each nucleotide is made up of three components: a nitrogenous base (for which there are five different types), a pentose sugar, and a phosphate group. These are depicted below. The main difference between these two types of nucleic acids is the presence or absence of a hydroxyl group at the C2 position, also called the 2' position (read "two prime"), of the pentose (see Figure 1 legend and section on the pentose sugar for more on carbon numbering). RNA has a hydroxyl functional group at that 2' position of the pentose sugar; the sugar is called ribose, hence the name ribonucleic acid. By contrast, DNA lacks the hydroxyl group at that position, hence the name, "deoxy" ribonucleic acid. DNA has a hydrogen atom at the 2' position.

The nitrogenous base
The nitrogenous bases of nucleotides are organic molecules and are so named because they contain carbon and nitrogen. They are bases because they contain an amino group that has the potential of binding an extra hydrogen, and thus acting as a base by decreasing the hydrogen ion concentration in the local environment. Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G), cytosine (C), and thymine (T). By contrast, RNA contains adenine (A), guanine (G) cytosine (C), and uracil (U) instead of thymine (T).
Adenine and guanine are classified as purines. The primary distinguishing structural feature of a purine is double carbon-nitrogen ring. Cytosine, thymine, and uracil are classified as pyrimidines. These are structurally distinguished by a single carbon-nitrogen ring. You will be expected to recognize that each of these ring structures is decorated by functional groups that may be involved in a variety of chemistries and interactions.
Note: practice
Take a moment to review the nitrogenous bases in Figure 1. Identify functional groups as described in class. For each functional group identified, describe what type of chemistry you expect it to be involved in. Try to identify whether the functional group can act as either a hydrogen bond donor, acceptor, or both?
The pentose sugar
The pentose sugar contains five carbon atoms. Each carbon atom of the sugar molecule are numbered as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”). The two main functional groups that are attached to the sugar are often named in reference to the carbon to whch they are bound. For example, the phosphate residue is attached to the 5′ carbon of the sugar and the hydroxyl group is attached to the 3′ carbon of the sugar. We will often use the carbon number to refer to functional groups on nucleotides so be very familiar with the structure of the pentose sugar.
The pentose sugar in DNA is called deoxyribose, and in RNA, the sugar is ribose. The difference between the sugars is the presence of the hydroxyl group on the 2' carbon of the ribose and its absence on the 2' carbon of the deoxyribose. You can, therefore, determine if you are looking at a DNA or RNA nucleotide by the presence or absence of the hydroxyl group on the 2' carbon atom—you will likely be asked to do so on numerous occasions, including exams.
The phosphate group
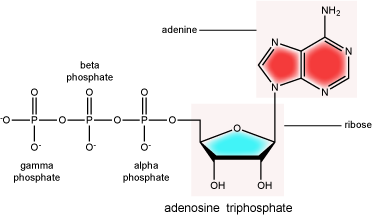
There can be anywhere between one and three phosphate groups bound to the 5' carbon of the sugar. When one phosphate is bound, the nucleotide is referred to as a Nucleotide MonoPhosphate (NMP). If two phosphates are bound the nucleotide is referred to as Nucleotide DiPhosphate (NDP). When three phosphates are bound to the nucleotide it is referred to as a Nucleotide TriPhosphate (NTP). The phosphoanhydride bonds between that link the phosphate groups to each other have specific chemical properties that make them good for various biological functions. The hydrolysis of the bonds between the phosphate groups is thermodynamically exergonic in biological conditions; nature has evolved numerous mechanisms to couple this negative change in free energy to help drive many reactions in the cell. Figure 2 shows the structure of the nucleotide triphosphate Adenosine Triphosphate, ATP, that we will discuss in greater detail in other chapters.
Note: "high-energy" bonds
The term "high-energy bond" is used A LOT in biology. This term is, however, a verbal shortcuts that can cause some confusion. The term refers to the amount of negative free energy associated with the hydrolysis of the bond in question. The water (or other equivalent reaction partner) is an important contributor to the energy calculus. In ATP, for instance, simply "breaking" a phosphoanhydride bond - say with imaginary molecular tweezers - by pulling off a phosphate would not be energetically favorable. We must, therefore, be careful not to say that breaking bonds in ATP is energetically favorable or that it "releases energy". Rather, we should be more specific, noting that they hydrolysis of the bond is energetically favorable. Some of this common misconception is tied to, in our opinion, the use of the term "high energy bonds". While in Bis2a we have tried to minimize the use of the vernacular "high energy" when referring to bonds, trying instead to describe biochemical reactions by using more specific terms, as students of biology you will no doubt encounter the potentially misleading - though admittedly useful - short cut "high energy bond" as you continue in your studies. So, keep the above in mind when you are reading or listening to various discussions in biology. Heck, use the term yourself. Just make sure that you really understand what it refers to.