
W2018_Bis2A_Lecture05_reading
- Page ID
- 25317
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Lipids
Lipids are a diverse group of hydrophobic compounds that include molecules like fats, oils, waxes, phospholipids, and steroids. Most lipids are at their core hydrocarbons, molecules that include many nonpolar carbon-carbon or carbon-hydrogen bonds. The abundance of nonpolar functional groups give lipids a degree of hydrophobic (“water fearing”) character and most lipids have low solubility in water. Depending on their physical properties (encoded by their chemical structure), lipids can serve many functions in biological systems including energy storage, insulation, barrier formation, cellular signaling. The diversity of lipid molecules and their range of biological activities are perhaps surprisingly large to most new students of biology. Let's start by developing a core understanding of this class of biomolecules.
Fats and oils
A common fat molecule or triglyceride. These types of molecules are generally hydrophobic and, while they have numerous functions, are probably best known for their roles in body fat and plant oils. A triglyceride molecule derived from two types of molecular components—a polar "head" group and a nonpolar "tail" group. The "head" group of a triglyceride is derived from a single glycerol molecule. Glycerol, a carbohydrate, is composed of three carbons, five hydrogens, and three hydroxyl (-OH) functional groups. The nonpolar fatty acid "tail" group consists of three hydrocarbons (a functional group composed of C-H bonds) that also have a polar carboxyl functional group (hence the term "fatty acid"—the carboxyl group is acidic at most biologically relevant pHs). The number of carbons in the fatty acid may range from 4–36; most common are those containing 12–18 carbons.

Note: possible discussion
The models of the triglycerides shown above depict the relative positions of the atoms in the molecule. If you Google for images of triglycerides you will find some models that show the phospholipid tails in different positions from those depicted above. Using your intuition, give an opinion for which model you think is a more correct representation of real life. Why?
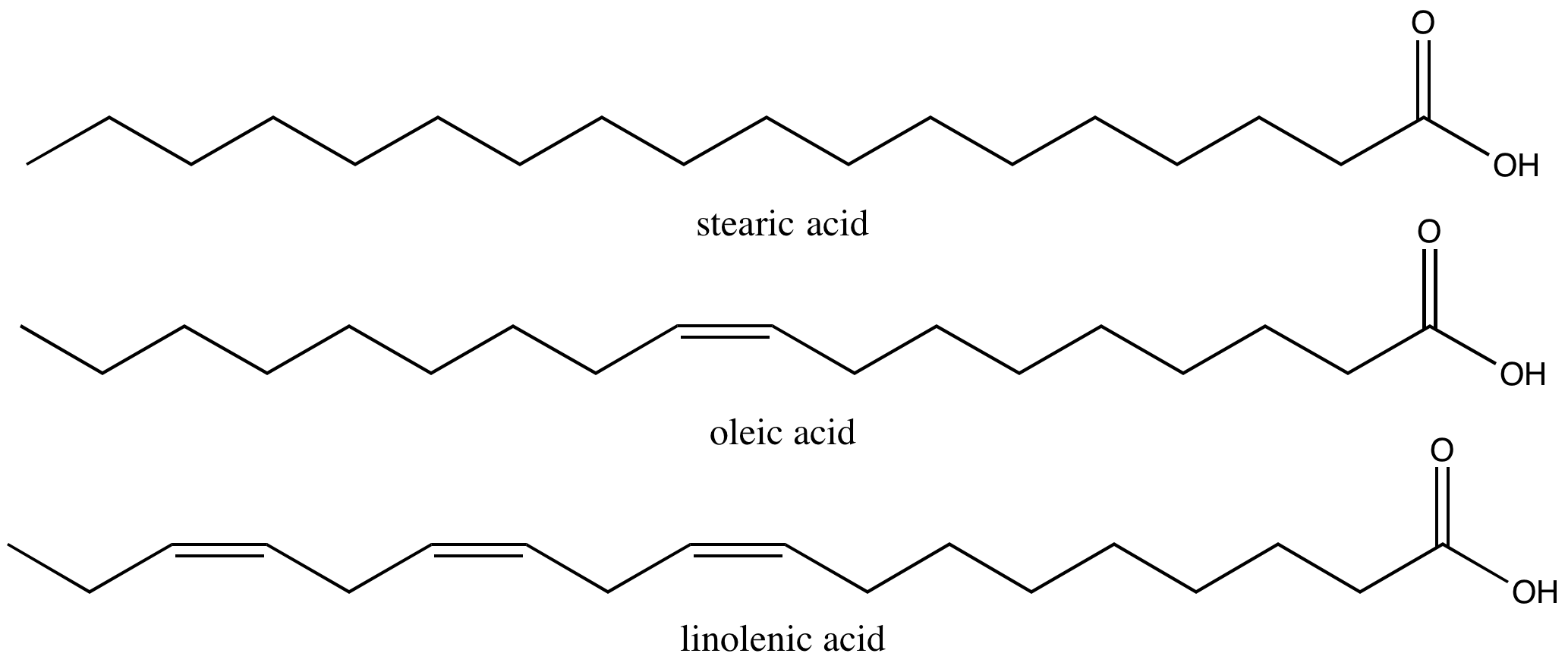
Figure 2. Stearic acid is a common saturated fatty acid; oleic acid and linolenic acid are common unsaturated fatty acids.
Attribution: Marc T. Facciotti (own work)
Note: possible discussion
Natural fats like butter, canola oil, etc., are composed mostly of triglycerides. The physical properties of these different fats vary depending on two factors:
1) The number of carbons in the hydrocarbon chains;
2) The number of desaturations, or double bonds, in the hydrocarbon chains.
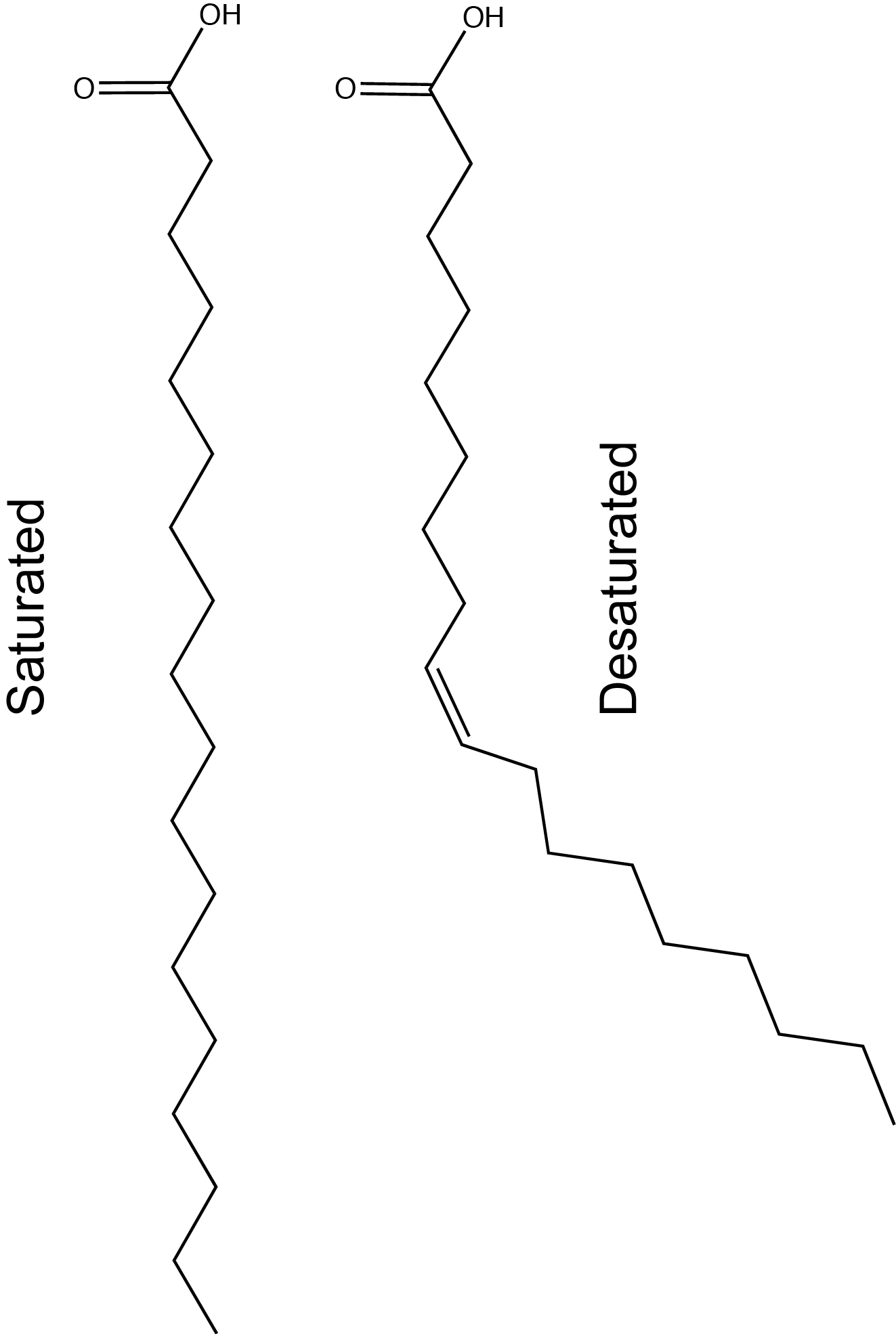
The first factor influences how these molecules interact with each other and with water, while the second factor dramatically influences their shape. The introduction of a double bond causes a "kink" in the otherwise relatively "straight" hydrocarbon, depicted in a slightly exaggerated was in Figure 3.
Based on what you can understand from this brief description, propose a rationale—in your own words—to explain why butter is solid at room temperature while vegetable oil is liquid.
Here is an important piece of information that could help you with the quesion: butter has a greater percentage of longer and saturated hydrocarbons in its triglycerides than does vegetable oil.
Sterols
Steroids are lipids with a fused ring structure. Although they do not resemble the other lipids discussed here, they are designated as lipids because they are also largely composed of carbons and hydrogens, are hydrophobic, and are insoluble in water. All steroids have four linked carbon rings. Many steroids also have the -OH functional group which puts them in the alcohol classification of sterols. Several steroids, like cholesterol, have a short tail. Cholesterol is the most common steroid. It is mainly synthesized in the liver and is the precursor to many steroid hormones such as testosterone. It is also the precursor to Vitamin D and of bile salts which help in the emulsification of fats and their subsequent absorption by cells. Although cholesterol is often spoken of in negative terms, it is necessary for the proper functioning of many animal cells, particularly in its role as a component of the plasma membrane where it is known to modulate membrane structure, organization, and fluidity.
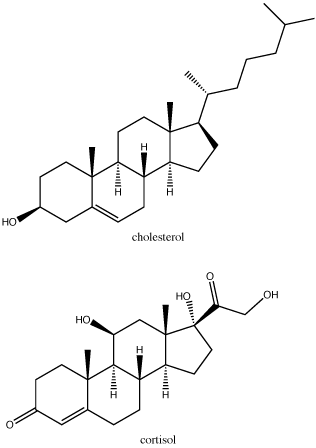
Note: possible discussion
In the molecule of cortisol above, what parts of the molecule would you classify as functional groups? Is there any disagreement over what should and should not be included as a functional group?
Phospholipids
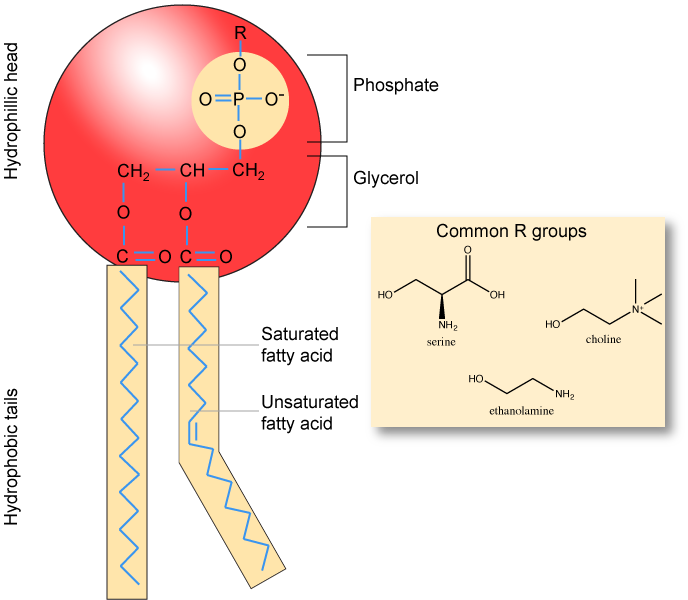
Phospholipids are major constituents of the cell membrane, the outermost layer of cells. Like fats, they are composed of fatty acid chains attached to glycerol molecule. Unlike the triacylglycerols, phospholipids have two fatty acid tails and a phosphate group attached to the sugar. Phospholipid are therefore amphipathic molecules, meaning it they have a hydrophobic part and a hydrophilic part. The two fatty acid chains extending from the glycerol are hydrophobic and cannot interact with water, whereas the phosphate-containing head group is hydrophilic and interacts with water. Can you identify the functional groups on the phospholipid below that give each part of the phospholipid its properties?
Note
Make sure to note in Figure 5 that the phosphate group has an R group linked to one of the oxygen atoms. R is a variable commonly used in these types of diagrams to indicate that some other atom or molecule is bound at that position. That part of the molecule can be different in different phospholipids—and will impart some different chemistry to the whole molecule. At the moment, however, you are responsible for being able to recognize this type of molecule (no matter what the R group is) because of the common core elements—the glycerol backbone, the phosphate group, and the two hydrocarbon tails.
In the presence of water, some phospholipids will spontaneously arrange themselves into a micelle (Figure 6). The lipids will be arranged such that their polar groups will be on the outside of the micelle, and the nonpolar tails will be on the inside. Under other conditions, a lipid bilayer can also form. This structure, only a few nanometers thick, is composed of two opposing layers of phospholipids such that all the hydrophobic tails align face-to-face in the center of the bilayer and are surrounded by the hydrophilic head groups. A phospholipid bilayer forms as the basic structure of most cell membranes and are responsible for the dynamic nature of the plasma membrane.
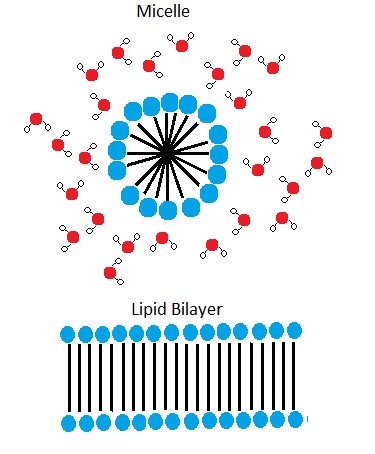
Note: possible discussion
As mentioned above, if you were to take some pure phospholipids and drop them into water that some of the phospholipid would spontaneously form into micelles. Why is the formation of micelles an energetically favorable reaction?
The phospholipid membrane is discussed in detail in a later module. It will be important to remember the chemical properties associated with the functional groups in the phospholipid in order to understand the function of the cell membrane.
Amino Acids
Amino acids are the monomers that make up proteins. Each amino acid has the same core structure, which consists of a central carbon atom, also known as the alpha (α) carbon, bonded to an amino group (NH2), a carboxyl group (COOH), and a hydrogen atom. Every amino acid also has another atom or group of atoms bonded to the alpha carbon known alternately as the R group, the variable group or the side-chain.

Amino acids have a central asymmetric carbon to which an amino group, a carboxyl group, a hydrogen atom, and a side chain (R group) are attached.
Attribution: Marc T. Facciotti (own work)
Note: Possible discussion
Recall that one of the learning goals for this class is that you (a) be able to recognize, in a molecular diagram, the backbone of an amino acid and its side chain (R-group) and (b) that you be able to draw a generic amino acid. Make sure that you practice both. You should be able to recreate something like the figure above from memory (a good use of your sketchbook is to practice drawing this structure until you can do it with the crutch of a book or the internet).
The Amino Acid Backbone
The name "amino acid" is derived from the fact that all amino acids contain both an amino group and carboxyl-acid-group in their backbone. There are 20 common amino acids present in natural proteins and each of these contain the same backbone. The backbone, when ignoring the hydrogen atoms, consists of the pattern:
N-C-C
When looking at a chain of amino acids it is always helpful to first orient yourself by finding this backbone pattern starting from the N terminus (the amino end of the first amino acid) to the C terminus (the carboxylic acid end of the last amino acid).

Peptide bond formation is a dehydration synthesis reaction. The carboxyl group of the first amino acid is linked to the amino group of the second incoming amino acid. In the process, a molecule of water is released and a peptide bond is formed.
Try finding the backbone in the dipeptide formed from this reaction. The pattern you are looking for is: N-C-C-N-C-C
Attribution: Marc T. Facciotti (own work)
The sequence and the number of amino acids ultimately determine the protein's shape, size, and function. Each amino acid is attached to another amino acid by a covalent bond, known as a peptide bond, which is formed by a dehydration synthesis (condensation) reaction. The carboxyl group of one amino acid and the amino group of the incoming amino acid combine, releasing a molecule of water and creating the peptide bond.
Amino Acid R group
The amino acid R group is a term that refers to the variable group on each amino acid. The amino acid backbone is identical on all amino acids, the R groups are different on all amino acids. For the structure of each amino acid refer to the figure below.

There are 20 common amino acids found in proteins, each with a different R group (variant group) that determines its chemical nature. R-groups are circled in teal. Charges are assigned assuming pH ~6.0. The full name, three letter abbreviation and single letter abbreviations are all shown.
Attribution: Marc T. Facciotti (own work)
Note: Possible Discussion
Let's think about the relevance of having 20 different amino acids. If you were using biology to build proteins from scratch, how might it be useful if you had 10 more different amino acids at your disposal? By the way, this is actually happening in a variety of research labs - why would this be potentially useful?
pKa
Don't panic!
Many BIS2A students find the concept of pKa overwhelming. Although it might seem complex and require a deep understanding of chemistry, it really doesn't. To understand cellular processes, you will need to know the properties of the functional groups on biomolecules at physiological pH (~pH 7). For example, carboxyl groups usually have a negative charge (CO2-) in the cell because they have lost a hydrogen ion (H+) at physiological pH. Based on your understanding of chemical bonds, you should be able to appreciate the fact that CO2- will be able to form ionic bonds. In contrast, the uncharged form CO2H cannot. Most of our discussion about pKa will focus on the properties of the functional groups present in amino acids.
pKa is defined as the negative log10 of the dissociation constant of an acid, its Ka. Therefore, the pKa is a quantitative measure of how easily or how readily the acid gives up its proton [H+] in solution and thus a measure of the "strength" of the acid. Strong acids have a small pKa, weak acids have a larger pKa.
The most common acid we will talk about in BIS2A is the carboxylic acid functional group. These acids are typically weak acids, meaning that they only partially dissociate (into H+ cations and RCOO- anions) in neutral solution. HCL (hydrogen chloride) is a common strong acid, meaning that it will fully dissociate into H+ and Cl-.
Note that the key difference in the figure below between a strong acid or base and a weak acid or base is the single arrow (strong) versus a double arrow (weak). In the case of the single arrow you can interpret that by imagining that nearly all reactants have been converted into products. Moreover, it is difficult for the reaction to reverse backwards to a state where the protons are again associated with the molecule there were associated with before. In the case of a weak acid or base, the double-sided arrow can be interpreted by picturing a reaction in which:
- both forms of the conjugate acid or base (that is what we call the molecule that "holds" the proton - i.e. CH3OOH and CH3OO-, respectively in the figure) are present at the same time and
- the ratio of those two quantities can change easily by moving the reaction in either direction.

Figure 1. An example of strong acids and strong bases in their protonation and deprotonation states. The value of their pKa is shown on the left. Attribution: Marc T. Facciotti
Electronegativity plays a role in the strength of an acid. If we consider the hydroxyl group as an example, the greater electronegativity of the atom or atoms (indicated R) attached to the hydroxyl group in the acid R-O-H results in a weaker H-O bond, which is thus more readily ionized. This means that the pull on the electrons away from the hydrogen atom gets greater when the oxygen atom attached to the hydrogen atom is also attached to another electronegative atom. An example of this is HOCL. The electronegative Cl polarizes the H-O bond, weakening it and facilitating the ionization of the hydrogen. If we compare this to a weak acid where the oxygen is bound to a carbon atom (as in carboxylic acids) the oxygen is bound to the hydrogen and carbon atom. In this case, the oxygen is not bound to another electronegative atom. Thus the H-O bond is not further destabilized and the acid is considered a weak acid (it does not give up the proton as easily as a strong acid).

Figure 2. The strength of the acid can be determined by the electronegativity of the atom the oxygen is bound to. For example, the weak acid Acetic Acid, the oxygen is bound to carbon, an atom with low electronegativity. In the strong acid, Hypochlorous acid, the oxygen atom is bound to an even more electronegative Chloride atom.
Attribution: Erin Easlon
In Bis2A you are going to be asked to relate pH and pKa to each other when discussing the protonation state of an acid or base, for example, in amino acids. How can we use the information given in this module to answer the question: Will the functional groups on the amino acid Glutamate be protonated or deprotonated at a pH of 2, at a pH of 8, at a pH of 11?
In order to start answering this question we need to create a relationship between pH and pKa. The relationship between pKa and pH is mathematically represented by Henderson-Hasselbach equation shown below, where [A-] represents the deprotonated form of the acid and [HA] represents the protonated form of the acid.
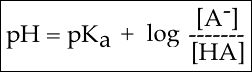
Figure 3. The Henderson-Hasselbach equation
A solution to this equation is obtained by setting pH = pKa. In this case, log([A-] / [HA]) = 0, and [A-] / [HA] = 1. This means that when the pH is equal to the pKa there are equal amounts of protonated and deprotonated forms of the acid. For example, if the pKa of the acid is 4.75, at a pH of 4.75 that acid will exist as 50% protonated and 50% deprotonated. This also means that as the pH rises, more of the acid will be converted into the deprotonated state and at some point the pH will be so high that the majority of the acid will exist in the deprotonated state.

Figure 4. This graph depicts the protonation state of acetic acid as the pH changes. At a pH below the pKa, the acid is protonated. At a pH above the pKa the acid is deprotonated. If the pH equals the pKa, the acid is 50% protonated and 50% deprotonated. Attribution: Ivy Jose
In BIS2A, we will be looking at the protonation state and deprotonation state of amino acids. Amino acids contain multiple functional groups that can be acids or bases. Therefore their protonation/deprotonation status can be more complicated. Below is the relationship between the pH and pKa of the amino acid Glutamic Acid. In this graph we can ask the question we posed earlier: Will the functional groups on the amino acid Glutamate be protonated or deprotonated at a pH of 2, at a pH of 8, at a pH of 11?
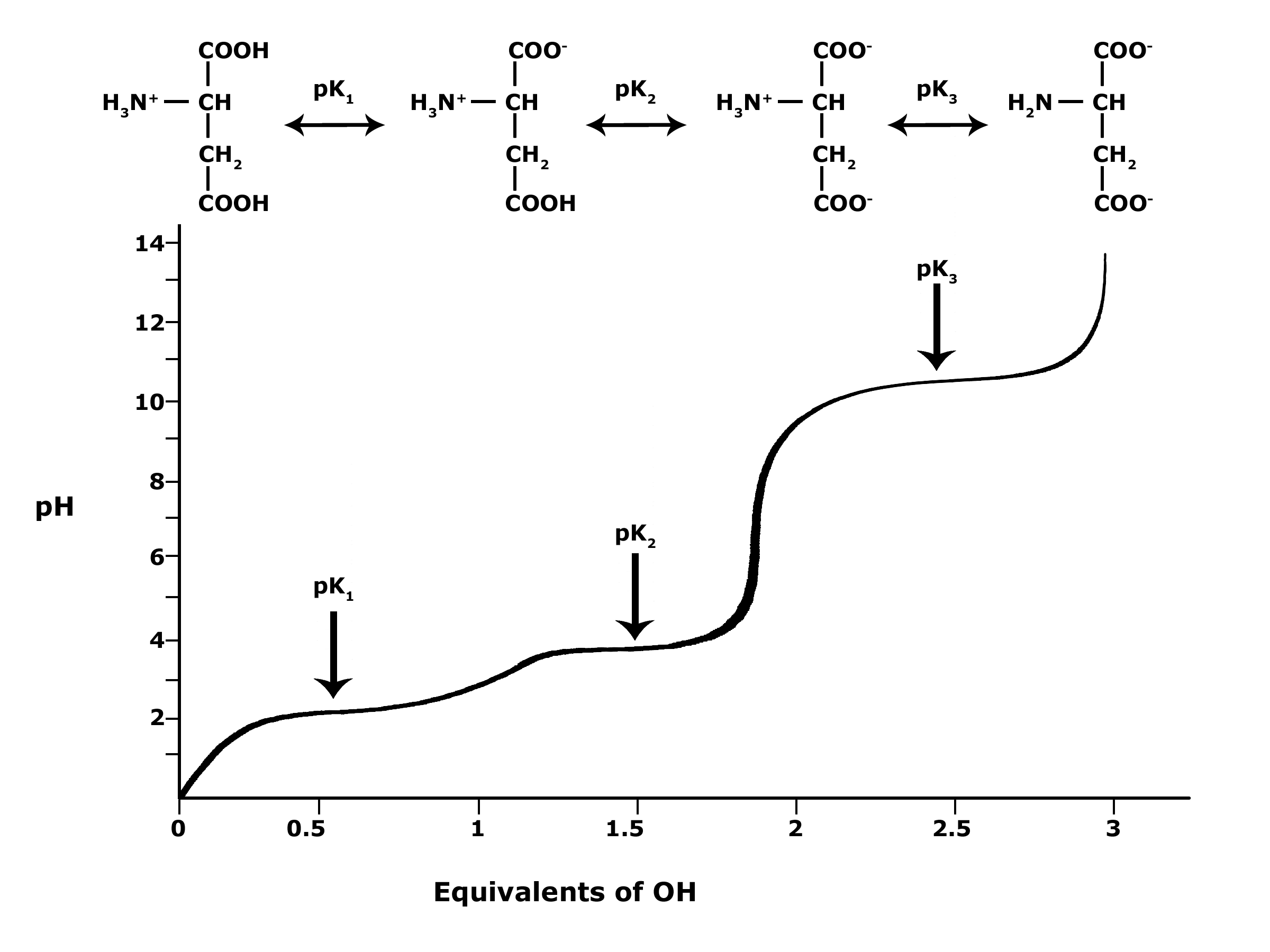
Figure 5. This graph depicts the protonation state of glutamate as the pH changes. At a pH below the pKa for each functional group on the amino acid, the functional group is protonated. At a pH above the pKa for the functional group it is deprotonated. If the pH equals the pKa, the functional group is 50% protonated and 50% deprotonated.
Attribution: Ivy Jose
Note: Possible discussion
- What is the overall charge of free Glutamate at a pH of 5?
- What is the overall charge of free Glutamate at a pH of 10?
Proteins
Proteins are class of biomolecules that perform a wide array of functions in biological systems. Some proteins serve as catalysts for specific biochemical reactions. Other proteins act as signaling molecules that allow cells to "talk" with one another. Proteins, like the keratin in fingernails, can also act in a structural capacity. While the variety of possible functions for proteins is remarkably diverse, all of these functions are encoded by a linear assembly of amino acids, each connected to their neighbor via a peptide bond. The unique composition (types of amino acids and the number of each) and the order in which they are linked together determine the final three dimensional form that the protein will adopt and therefore, also the protein's biological "function". Many proteins can, in a cellular environment, spontaneously and often rapidly take on their final form in a process called protein folding. To watch a short (four minutes) introduction video on protein structure click here.
Protein structure
Protein structures can be described by four different levels of structural organization called primary, secondary, tertiary, and quaternary structures. These are briefly introduced in the sections that follow.
Primary structure
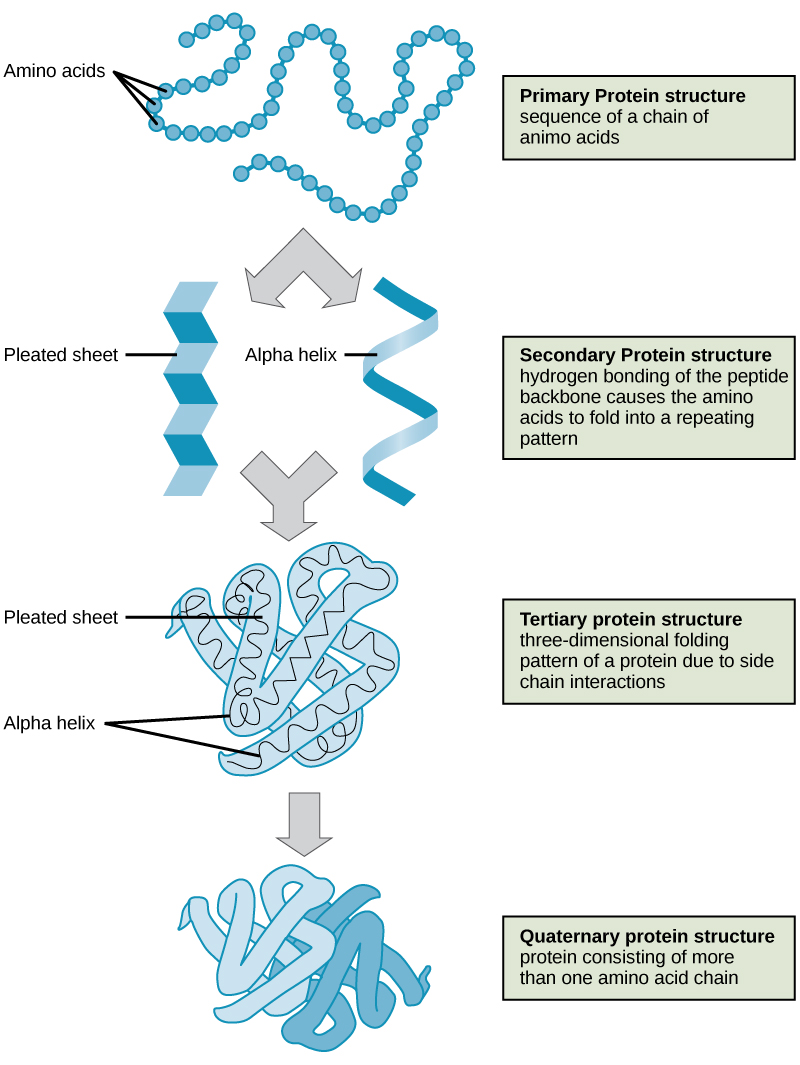
The unique sequence of amino acids in a polypeptide chain is its primary structure (Figure 1). The amino acids in this chain are linked to one another other via a series of peptide bonds. The chain of amino acids is often referred to as a polypeptide (multiple peptides).
Due to the common backbone structure of amino acids, the resulting backbone of the protein has a repeating -N-Cα-C-N-Cα-C- pattern that can be readily identified in atomic resolution models of protein structures (Figure 2). Be aware that one of the learning goals for this class is for you to be able to examine a model like the one below and to identify the backbone from the side chain atoms (e.g. create the purple trace and blue shading if there aren't any). This can be done by finding the -N-Cα-C-N-Cα-C- pattern. Moreover, another learning goal for this class is that you are able to create drawings that model the structure of a typical protein backbone and its side chains (aka. variable group, R group). This task can be greatly simplified if you remember to start your model by first creating the -N-Cα-C-N-Cα-C- pattern and then filling in the variable groups.

Secondary structure
Due to the specific chemistry of the peptide bond the backbone between adjacent alpha-carbon atoms forms a highly planar structure (Figure 3). This means that all of the atoms linked by the pink quadrilateral lie on the same plane. The polypeptide is therefore structurally constrained since very little rotation can happen around the peptide bond itself. Rather, rotations occur around the two bonds extending away from the alpha carbons. These structural constraints lead to two commonly observed patterns of structure that are associated with the organization of the backbone itself.
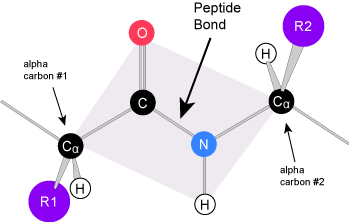
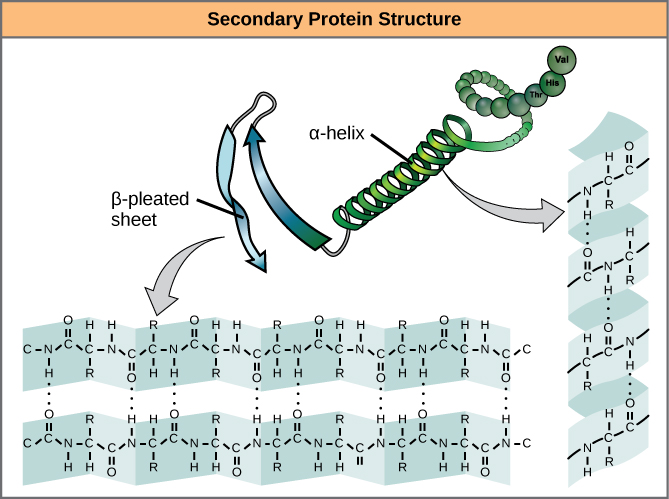
We call these patterns of backbone structure the secondary structure of the protein. The most common secondary structure patterns occurring via rotations of the bonds around each alpha-carbon, are the α-helix, β-sheet and loop structures. As the name suggests, the α-helix is characterized by a helical structure made by twisting the backbone. The β-sheet is actually the association between two or more structures called β-strands. If the orientation (N-terminus to C-terminus direction) of two associating β-strands are oriented in the same/parallel direction, the resulting β-sheet is called a parallel β-sheet. Meanwhile, if two associating β-strands are oriented in opposite/anti-parallel directions, the resulting β-sheet is called an anti-parallel β-sheet. The α-helix and β-sheet are both stabilized by hydrogen bonds that form between backbones atoms of amino acids in close proximity to one another. More specifically, the oxygen atom in the carbonyl group from one amino acid can form a hydrogen bond with a hydrogen atom bound to the nitrogen in the amino group of another amino acid. Loop structures by contrast refer to all secondary structure (e.g. backbone structure) that can not be identified as either α-helix or β-sheet.
Tertiary structure
The backbone and secondary structure elements will further fold into a unique and relatively stable three-dimensional structure called the tertiary structure of the protein. The tertiary structure is what we typically associate with the "functional" form of a protein. In Figure 6 two examples of tertiary structure are shown. In both structures, the protein is abstracted into a "cartoon" that depicts the polypeptide chain as a single continuous line or ribbon tracing the path between alpha carbons of amino acids linked to one another by peptide bonds - the ribbon traces the backbone of the protein (Figure 5).

The ribbon created by joining alpha-carbons can be drawn as a simple continuous line or it can be enhanced by uniquely representing secondary structural elements. For instance, when an α-helix is identified, the helix is usually highlighted by accentuating/broadening the ribbon to make the helical structure stand out. When a β-strand is present, the ribbon is usually broadened and an arrow is typically added to the C-terminal end of each β-strand - the arrow helps to identify the orientation of the polypeptide and whether β-sheets are parallel or anti-parallel. The thin ribbon connecting α-helix and β-strand elements is used to represent the loops. Loops in proteins can be highly structured and play an important role in the protein's function. They should not be treated lightly or dismissed as unimportant because their name lacks a Greek letter.

Attribution: Marc T. Facciotti (own work)
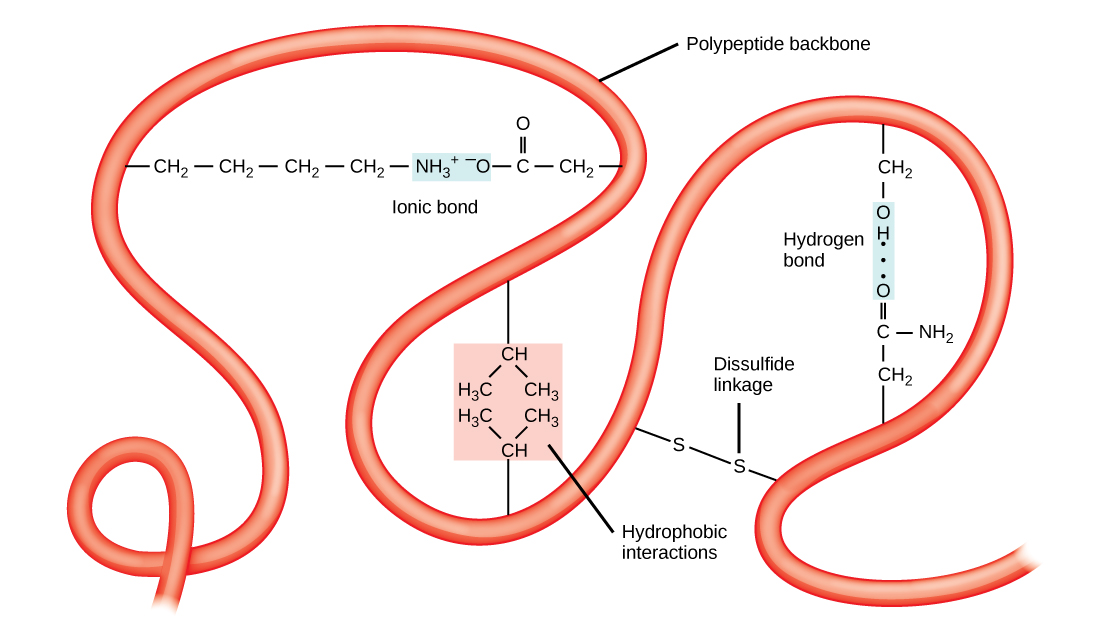
The tertiary structure is the product of many different types of chemical interactions among amino acid R groups, backbone atoms, ions in solution and water. These bonds include ionic, covalent, and hydrogen bonds and Van der Waals interactions. For example, ionic bonds may form between various ionizable side chains. It may, for instance, be energetically favorable for a negatively charged R group (e.g. an Aspartate) to interact with a positively charged R group (e.g. an Arginine). The resulting ionic interaction may then become part of the network of interactions that helps to stabilize the three dimensional fold of the protein. By contrast, R groups with like charges will likely be repelled by each other and be therefore unlikely to form a stable association thereby disfavoring a structure that would include that association. Likewise, hydrogen bonds may form between various R groups or between R groups and backbone atoms. These hydrogen bonds may also contribute to stabilizing the tertiary structure of the protein. In some cases covalent bonds may also form between amino acids. The most commonly observed covalent linkage between amino acids involves two cysteines and is termed a disulfide bond or disulfide linkage.
Finally, the association of the protein's functional groups with water also helps to drive chemical associations that help to stabilize the final protein structure. The interactions with water can, of course, include the formation of hydrogen bonds between polar functional groups on the protein and water molecules. Perhaps more importantly, however, is the drive for the protein to avoid placing too many hydrophobic functional groups in contact with water. The result of this desire to avoid interactions between water and hydrophobic functional groups means that the less polar side chains will often associate with one another away from water resulting in some energetically favorable Van der Waals interactions and the avoidance of energetic penalties associated with exposing the non-polar side chains to water. Indeed, the energetic penalty is so high for "exposing" the non-polar side chains to water that burying these groups away from water is thought to be one of the primary energetic drivers of protein folding and stabilizing forces holding the protein together in its tertiary structure.
Quaternary structure
In nature, the functional forms of some proteins are formed by the close association of several polypeptides. In such cases the individual polypeptides are also known as subunits. When the functional form of a protein requires the assembly of two or more subunits we call this level of structural organization the protein's quaternary structure. Yet again, combinations of ionic, hydrogen, and covalent bonds together with Van der Waals associations that occur through the "burial" of hydrophobic group at the interfaces between subunits help to stabilize the quaternary structures of proteins.
Denaturation
As was previously described, each protein has its own unique structure that is held together by various types of chemical interactions. If the protein is subject to changes in temperature, pH, or exposure to chemicals, that change the nature of or interfere with the associations between functional groups, the protein's secondary, tertiary and/or quaternary structures may change, even though the primary structure remains the same. This process is known as denaturation. While in the test tube denaturation is often reversible, in the cell the process can often be, for practical purposes, irreversible, leading to loss of function and the eventual recycling of the protein's amino acids. Resistance to environmental stresses that can lead to denaturation vary greatly amongst the proteins found in nature. For instance, some proteins are remarkably resistant to high temperatures; for instance, bacteria that survive in hot springs have proteins that function at temperatures close to the boiling point of water. Some proteins are able to withstand the very acidic, low pH, environment of the stomach. Meanwhile some proteins are very sensitive to organic solvents while others can be found that are remarkably tolerant of these chemicals (the latter are prized for use in various industrial processes).
Finally, while many proteins can form their three dimensional structures completely on their own, in many cases proteins often receive assistance in the folding process from protein helpers known as chaperones (or chaperonins) that associate with their protein targets during the folding process. The chaperones are thought to act by minimizing the aggregation of polypeptides into non-functional forms - a process that can occur through the formation of non-ideal chemical associations.