
3.2: Replication of DNA
- Page ID
- 138389
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In 1983, while working at the biotechnology company Cetus Corporation, Dr. Kary Mullis created a laboratory process for DNA amplification that mimicked the in vivo process of DNA replication. This process, named Polymerase Chain Reaction or PCR, used repeated cycles of heating and cooling to exponentially replicate a targeted DNA segment. Mullis set-up three water baths: a high temperature bath for DNA denaturation (95°C), a lower temperature bath for primer annealing (e.g. 50°C to 60°C), and a third water bath for the extension phase of the polymerase (72°C). The DNA was incubated in each water bath for a defined time period and then repeated over and over again. Initially, the process used a DNA polymerase from E. coli, which was not stable enough at the high temperatures required for DNA denaturation and had to be replenished during each cycle. The breakthrough came with the discovery of Taq polymerase, an enzyme isolated from the thermophilic bacterium Thermus aquaticus, which could withstand the high denaturing temperatures. PCR quickly gained recognition for its versatility and has became a foundational tool in genetics, diagnostics, forensics, and research. Mullis' work earned him the Nobel Prize in Chemistry in 1993.
Introduction to DNA Replication
During cell division, each daughter cell receives an identical copy of the DNA. For this to happen, the DNA must be copied through a process called DNA replication. The replication of DNA occurs during the synthesis phase, or S phase, of the cell cycle, before the cell enters mitosis or meiosis. The structure of the double helix provides a hint as to how DNA is copied. During DNA replication, each of the two "parental" DNA strands that make up the double helix will separate and serve as a template from which the new "daughter" DNA strands are copied. The newly made daughter DNA strand is complementary to the parental DNA strand. After replication, each new DNA helix will consist of one parental DNA strand and one new daughter DNA strand. This is known as semi-conservative replication because each of the parental DNA strands remains (i.e. is conserved) within the new helix (Figure \(\PageIndex{1}\)).

DNA is replicated in cells and in the laboratory using a series of enzyme-catalyzed steps. At the end of this section, you will be able to:
- List the major steps of DNA replication
- Explain the process of DNA replication in prokaryotes
- Define the role for each component of DNA replication
- Compare and contrast DNA replication in prokaryotes and eukaryotes
- Explain the steps of the Polymerase Chain Reaction (PCR) workflow
- List and explain the components of a PCR reaction
- Explain the events of one PCR cycle
- Explain how real-time PCR differs from semi-quantitative PCR
The Mechanism of DNA Replication
The process of DNA replication requires many components and is comprised of many stages. However, the process can be simplified into the following steps:
- The DNA helix is unwound at the origin of replication
- RNA primers bind to specific sequences of DNA
- DNA polymerases bind the primers and "read" the parental strands in order to create the new daughter strands. One new strand is made continuously, while the other strand is made in pieces
- Primers are removed, new DNA nucleotides are put in place of the primers and missing phosphodiester bonds are re-formed
Both the secondary and tertiary structures of DNA make it impossible to replicate. To eliminate the tertiary DNA structure of supercoiling, a topoisomerase enzyme complex breaks a phosphodiester bond in one of the two DNA strands, eliminating the supercoiling. The secondary structure of the helix is then eliminated by "unwinding" the helix into its two parental template strands. This step is accomplished by an enzyme called a DNA helicase (or helicase) (Figure \(\PageIndex{2}\)). The helicase recognizes a specific sequence of DNA known as an origin of replication. Two helicase complexes bind at this sequence and move along the DNA in opposite directions. As they move, they unwind or "unzip" the double-stranded DNA into single-strands. As the DNA helix unwinds, Y-shaped structures called replication forks are formed. Two replication forks are formed at each origin of replication as two helicase complexes move away from one another. The forks will grow in opposite directions as replication proceeds. Bacterial chromosomes, with their smaller sizes, typically have one origin of replication. The larger eukaryotic chromosomes will have several origins along their lengths so that replication can occur simultaneously from several places along each chromosome.

The unwinding of the DNA helix produces the two parental strands that serve as templates for daughter strand synthesis. The parental strands are prevented from reforming the DNA helix through the binding of several small single-stranded binding proteins (SSBs) to each parental strand. As the helicase unwinds the helix, the parental DNA is "copied" by a DNA polymerase, a large enzyme complex made of several subunits, each with specific functions in replication. The DNA polymerase is limited, however, in that it cannot bind single-stranded DNA. To fix this, an enzyme complex called a primase creates a short RNA primer that is complementary to the parental DNA template. The DNA polymerase clamps itself onto the parental DNA strand at the 3' end of the primer and glides along this strand towards its 5' end. As it moves to the 5' end, it uses the parental strand as a template, adding and linking complementary DNA nucleotides to create the DNA daughter strand. As DNA replication proceeds, RNA primers are removed and the gaps filled with new DNA nucleotides by another type of DNA polymerase. Finally, missing phosphodiester bonds between nucleotides in the daughter strands are formed by a DNA ligase enzyme complex, creating a continuous piece of daughter DNA.
DNA replication (Figure \(\PageIndex{3}\)) is a complex process that presents numerous challenges to the cell. Several of these are solved by enzyme complexes like the helicase (which unwinds the DNA helix) and the primase (which creates the primer). But the biggest challenges are: 1) the fact that both parental strands must be replicated at the same time and 2) the requirement that daughter DNA must be made in the 5' to 3' direction. In other words, incoming DNA nucleotides can only be added to a daughter DNA strand at its 3' end. The first challenge is solved easily. Two DNA polymerases, linked to one another, replicate both parental templates at the same time. The second challenge is more difficult. The requirement that daughter DNA "grows" in the 5' to 3' direction is not a problem for the DNA polymerase replicating the parental strand that is in the 3' to 5' orientation. The daughter DNA strand made from this template will be synthesized continuously in a process known as leading strand synthesis. The daughter strand made through this process is often called the leading strand.

However, replication of the other parental template strand that is in the 5' to 3' orientation cannot be done continuously. Instead, this template must be replicated in short pieces called Okazaki fragments, in a process called lagging strand synthesis. In lagging strand synthesis, a short stretch of parental DNA, beginning with an RNA primer, is "looped" so that it has its orientation reversed (i.e. from 5' to 3' to 3' to 5'). This reversal of orientation to 3' to 5' means that the DNA polymerase can synthesize daughter DNA in the 5' to 3' direction and it creates an Okazaki fragment. The DNA polymerase then takes a new section of parental DNA and reverses and replicates it. As these Okazaki fragments are made, a DNA ligase will link them together by forming new phosphodiester bonds, thus creating a continuous piece of DNA that is the lagging strand.
Animation: DNA Replication
DNA Replication in Prokaryotes vs. Eukaryotes
DNA replication was first studied in prokaryotes, primarily because of the small size of the genome. As an example, E. coli has 4.6 million base pairs in its single, circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the chromosome in both directions. This means that approximately 1000 nucleotides are added per second. The process is much more rapid than in eukaryotes, whose rate of replication ranges from 500 to 5000 nucleotides added per minute at each replication fork.
While there are many similarities in DNA replication between prokaryotes and eukaryotes, there are several important differences (Table \(\PageIndex{1}\). The major difference lies in the composition and function of the DNA polymerases. Specifically, three polymerases (DNA polymerase I, II, and III) are involved in prokaryotic DNA replication, whereas eukaryotes utilize five polymerases (alpha, beta, delta, gamma, and epsilon).
| Category | Prokaryotes | Eukaryotes |
|---|---|---|
| Replication site | nucleoid | nucleus |
| DNA organization | single, circular chromosome | multiple, linear chromosomes |
| DNA condensing | supercoiling | chromatin condensed into chromosomes |
| Origin of replication | one | multiple |
| Direction of replication | bidirectional | bidirectional |
| Replication rate | 1000 - 2000 nucleotides per second | 100 nucleotides per second |
| Removal of supercoiling | DNA topoisomerase II (DNA gyrase) | DNA topoisomerase II (DNA gyrase) |
| Unwinding of DNA helix | Helicase | Helicase |
| RNA primer production | Primase | DNA polymerase a |
| Synthesis of DNA | DNA polymerase III |
DNA polymerase d (lagging strand) DNA polymerase e (leading strand) |
| Removal of RNA primers | DNA polymerase I | RNAse H??? |
| Replacement of primers with DNA | DNA polymerase I | DNA polymerase e |
| Joining of DNA fragments | DNA Ligase | DNA Ligase |
| DNA repair | DNA polymerase II | DNA polymerases, b and d |
Polymerase Chain Reaction (PCR): DNA Replication in the Laboratory
Polymerase chain reaction (PCR) is a laboratory protocol that amplifies a small amount of DNA into significant amounts that can be manipulated in a lab. PCR has become an incredibly powerful tool in the lab, widely used in forensics, research and clinical labs. Included in the myriad of uses for PCR is its use in amplifying enough DNA for downstream analysis (e.g. sequencing, restriction digest, DNA fingerprinting) and cloning.
The workflow for PCR is relatively straightforward (Figure \(\PageIndex{4}\)). PCR reactions are set-up and placed into a "PCR machine" or thermocycler. The thermocycler is programmed to run a repetitive series of PCR cycles. Upon the conclusion of the PCR program, the PCR reactions are analyzed through agarose gel electrophoresis, to confirm the presence of the correct PCR product, in addition to other downstream applications, such as sequencing.

The PCR reaction
In amplifying DNA, PCR mimics DNA replication of the cell. Indeed, the components found in a PCR reaction are the same components, or very similar, to those found in cells undergoing DNA replication (Figure \(\PageIndex{5}\)).
The components of a PCR reaction are:
- The DNA polymerase: At the core of a PCR reaction is a DNA polymerase capable of replicating a DNA template. The most common DNA polymerase used in PCR reactions is called Taq polymerase – a thermostable bacterial polymerase isolated from Thermus aquaticus, a thermostable DNA polymerase isolated from the bacteria Thermus aquaticus in 1988. Taq polymerase maintains activity across a wide range of temperatures that will be encountered during a PCR cycle.
- The template DNA: The DNA added to the PCR reaction will contain the target region of DNA to be amplified.
- Two DNA primers: As with in vivo DNA replication, replication by Taq polymerase requires a primer to initiate DNA synthesis. PCR uses two primers, known as the forward primer and the reverse primer. The forward and reverse primers will flank the DNA region to be amplified and are made of short sequences of DNA complementary to the DNA template. The forward primer sequence is designed to be complementary to the anti-sense template and the reverse primer is designed to be complementary to the sense DNA strand. PCR primers are often referred to as oligonucleotides or "oligos" because of their short length. Rather than being made of RNA, the two primers are made of DNA. However, they will act as the in vivo RNA primer does in replication by base pairing to the template DNA and providing a 3' end from which the Taq polymerase can extend.
- The four DNA Nucleotides: As with in vivo DNA replication, the replicated DNA strands will be synthesized using the four DNA nucleotide bases, dATP, dGTP, dCTP, and dGTP.
- A reaction buffer: To optimize Taq polymerase activity, the PCR reaction will be set-up using a reaction buffer that is a mixture of monovalent and divalent cations (e.g. Mg2+) buffered to a specific pH.

The components listed above are missing some critical components of in vivo DNA replication. First and foremost, the helicase of DNA replication is not used in a PCR reaction. The unwinding of the template DNA helix is achieved by incubating the PCR reaction at a very high temperature (i.e. 95°C). This high temperature unwinds or denatures the double-stranded DNA into two single strands. There is no need for a topoisomerase because the template DNA used in PCR reactions is typically small enough that supercoiling is not found. Finally, the "reannealing" of the two parental DNA strands back into a helix is prevented by the rapid binding of the forward and reverse primers to their complementary regions. In this way, single-stranded binding proteins (SSBs) are not required.
The PCR "cycle" is made of three temperatures
A PCR reaction is run using a repetitive series of temperatures. Each series is known as a "cycle" and consists of three temperatures (Figure \(\PageIndex{6}\)). These temperatures are the:
- Denaturing temperature: A very high temperature (~95°C) that breaks the hydrogen bonds between complementary bases and causes the two parental DNA strands to separate. The denaturing step of PCR is typically very short (~30 to 60 seconds).
- Annealing temperature: A lower temperature designed to promote the base-pairing between the forward and reverse primers to their complementary sequences in the template strands. Because the PCR primers are added to the reaction in excess amounts, when the reaction is cooled, they will anneal to their complementary DNA regions before the two parental strands can re-anneal with each other. Annealing temperatures typically range from 50°C to 60°C and depend on the primer sequences. Annealing times in a PCR reaction usually range from 1 to 2 minutes to ensure sufficient primer annealing.
- Extension temperature: The temperature that allows the Taq polymerase to bind and extend off the annealed primers. For Taq polymerase this temperature is 72°C. Extension steps are usually between 30 and 60 seconds.
A typical PCR program will repeat this three-temp cycle 30 to 40 times. Each cycle increases the amount of target DNA amplified. Only the region of template DNA found between the two annealed primers is replicated At the end of the program, millions of replicated pieces of DNA outlined by the two primers will be created.
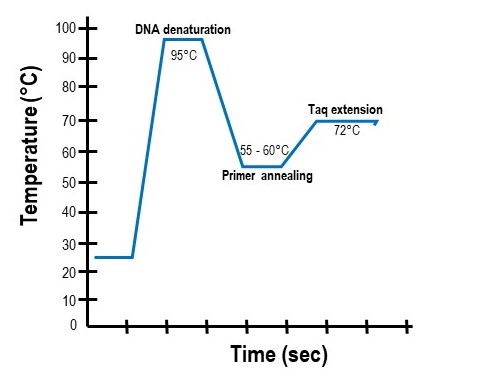
(The PCR Cycle by Patricia Zuk, CC BY 4.0)
The Taq polymerase amplifies the DNA found between the two PCR primers
The strength of PCR lies in its ability to amplify a targeted region of DNA inside a much larger piece. For example, a scientist wanting to study a single human gene (or a specific region inside of it) only needs to amplify that gene (or region) from the enormous human genome of approximately three billion base pairs. “Outlining” the target DNA to be amplified is done using the forward and reverse primers. Therefore, researchers will design these primers to flank the region of DNA they wish to amplify. The animation below illustrates how PCR will amplify the regions between the two primers.
Animation: PCR amplification of a target region
Real-time PCR: Quantitative PCR
The PCR described above is known as "semi-quantitative" because it can give a general idea of DNA quantity found in the PCR product. However, this type of PCR can be adapted into a truly quantitative protocol known as real-time PCR or qPCR. In real-time PCR, a fluorescently-labeled probe is used to quantitate the degree of cDNA amplification in the PCR reaction. Two major approaches are used in real-time PCR: Taqman and SYBR green.
The "Taqman protocol" was developed by Applied Biosystems (now part of Thermo Fisher). In this protocol, a 20X Gene Expression Mix, containing custom forward and reverse primers, in addition to a fluorescently-labeled "Taqman probe", is used to amplify a sequence of DNA through a standard PCR reaction. The Taqman probe binds the DNA template somewhere between the forward and reverse primers. The DNA sequence of the probe is bound to a fluorophore and a quencher that prevents fluorescence. Commonly used fluorescent probes include fluorescein (FAM), VIC, HEX, and JOE. When the probe is bound to the DNA template, the quencher prevents fluorescence. However, as the Taq polymerase amplifies the region between the forward and reverse primers, it displaces the fluorescent probe, which is followed by probe cleavage. As a result, the fluorescent probe is separated from its quencher and is excited. Fluorescent emission is then detected by the thermocycler (Figure \(\PageIndex{7}\)). The expression data for each PCR reaction is provided as a value known as a Ct (threshold cycle) value - the cycle number at which a detectable fluorescent signal was measured. These Ct values can be analyzed and either converted to absolute values or compared to one another so that changes in gene expression can be determined.

The "SYBR green protocol" depends on the intercalating dye, SYBR Green I. When unbound in the PCR reaction, the SYBR Green dye has negligible fluorescence. However, when the Taq polymerase synthesizes it complementary DNA strand, SYBR Green I is incorporated into the PCR product and emits a strong fluorescent signal. At the start of the next PCR cycle, the fluorescent signal is decreased when the double-stranded DNA (dsDNA) template is denatured but increases again as the PCR product is made. Therefore, the fluorescent signal of the sample is collected at the end of the elongation step of each PCR cycle to determine the relative change in amplified products (Figure \(\PageIndex{8}\)). Since SYBR Green I is a non-specific dsDNA binding dye, it cannot distinguish between amplified PCR products and non-specific piece of dsDNA. Therefore, corrective methods must be used in data analysis.

Lab Protocols
- Lab Technique: Polymerase Chain Reaction (PCR)
- Lab Technique: Quantitative PCR
- Lab Technique: Agarose Gel Electrophoresis
DNA replication duplicates the two strands of the DNA helix. Some major concepts to remember are:
- each of the two "parental" DNA strands serve as templates for "daughter" DNA strand synthesis
- the two"parental" DNA strands of the DNA helix are separated by a Helicase enzyme prior to replication
- single-stranded binding proteins hold the two parental DNA strands apart
- DNA replication is performed by a DNA polymerase that reads a parental template strand to create a daughter strand made of complementary DNA nucleotides
- DNA polymerase requires a short primer of RNA to begin replication of a daughter strand. This primer is made by a Primase enzyme
- DNA polymerase makes the daughter DNA strand in the 5' to 3' direction. This means that one daughter strand (i.e. the leading strand) can be synthesized continuously. The other daughter strand (i.e. the lagging strand) is made in short pieces called Okazaki fragments
- the enzyme DNA ligase joins all DNA fragments to finish DNA replication
- after replication, each new DNA helix consists of one parental strand and one new daughter strand (i.e. semi-conservation replication)
Glossary
DNA Ligase: An enzyme that joins Okazaki fragments together by forming phosphodiester bonds.
DNA Polymerase: An enzyme that adds nucleotides to a growing DNA strand during replication.
DNA Replication: The biological process by which a cell makes an identical copy of its DNA before cell division.
Daughter strand: The complementary DNA strand made by DNA polymerase during DNA replication.
Helicase: An enzyme that unwinds the DNA double helix by breaking hydrogen bonds between base pairs.
Leading Strand: The DNA strand that is synthesized continuously in the 5’ to 3’ direction during replication.
Lagging Strand: The DNA strand that is synthesized discontinuously in short segments known as Okazaki fragments.
Okazaki Fragments: Short DNA fragments synthesized on the lagging strand during replication; joined together by DNA ligase.
Origin of Replication: A specific sequence in the genome where DNA replication begins; the site of binding of the helicase and other replication proteins.
Parental DNA strand: One of the two original strands found in the DNA helix; used as a template for synthesis of the leading and lagging strands.
Primase: An enzyme that synthesizes a short RNA primer to provide a starting point for DNA polymerase.
Replication Fork: The Y-shaped region where the DNA double helix is unwound and new strands are synthesized.
RNA Primer: A short RNA sequence synthesized by primase that initiates DNA synthesis.
Topoisomerase: An enzyme that prevents DNA supercoiling and relieves tension ahead of the replication fork.
Single-Strand Binding Proteins (SSBs): Proteins that stabilize the separated DNA strands during replication to prevent them from reannealing.
Semi-Conservative Replication: A method of DNA replication in which each new DNA molecule consists of one original (parental) strand and one newly synthesized strand.