
DNA Replication
- Page ID
- 23858

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)1. Description of DNA Replication
The human body produces billions of new cells every day. But before undergoing cell division, a cell must first copy the genetic information contained in the cell nucleus – its DNA. In just 6-8 hours a cell is able to copy its entire genome. To accomplish this, DNA replication begins at multiple locations along each chromosome. As the two DNA strands are pulled apart, copying begins at the rate of about 50 nucleotides per second!
DNA Basics
DNA encodes the information needed to build proteins, to regulate physiological processes and maintain homeostasis in our bodies. The basic chemical components of DNA are phosphate, deoxyribose (a sugar) and 4 nitrogenous bases: adenine (A), guanine (G), cytosine (C) and thymine (T).
DNA is a double stranded molecule with the two strands lying antiparallel to each other (they lie parallel to each other but run in opposite directions). The two strands of DNA wind together to form a double helix – a structure that looks similar to a spiral staircase.
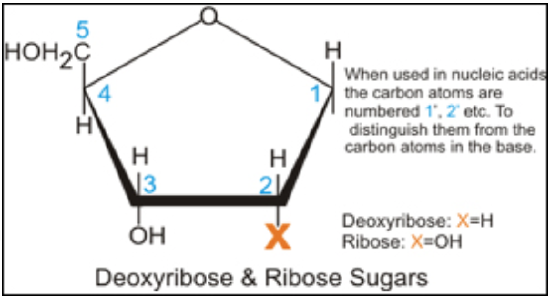
Figure \(\PageIndex{1}\). the chemical structure of DNA (CC BY-NC-SA; Madprime)
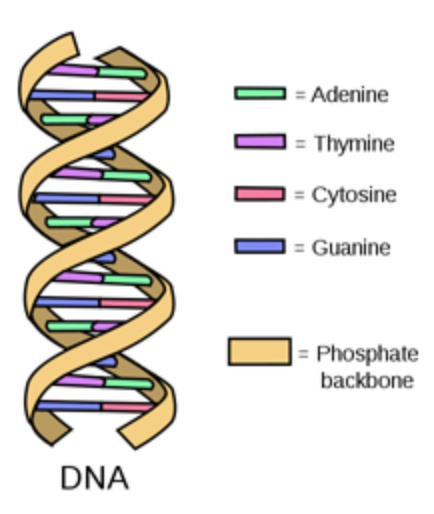
Figure \(\PageIndex{2}\). semi-conservative replication (CC BY-NC-SA; Madprime)
The strands of DNA are also complementary to each other due to specific base pairing between the two strands: adenine on one strand will always pair with thymine on the opposite strand and cytosine will always bind with guanine.
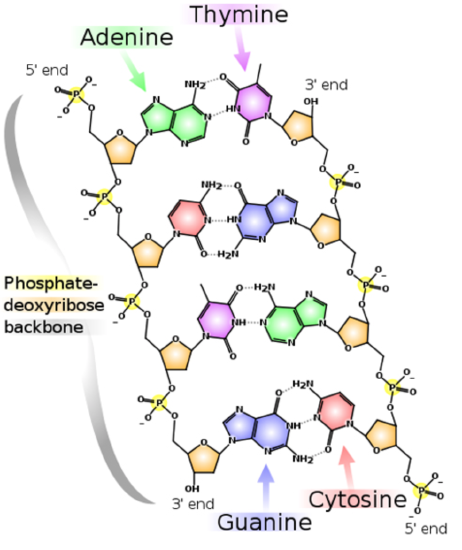
Figure \(\PageIndex{3}\). DNA replication (CC BY-NC-SA; LadyofHats)
During the process of DNA replication, the parental DNA unwinds and since nucleotides have exclusive partners, each DNA can act as its own template for replication. The two new DNA molecules each consist of one parental strand and one newly made strand. This is known as semiconservative DNA replication.
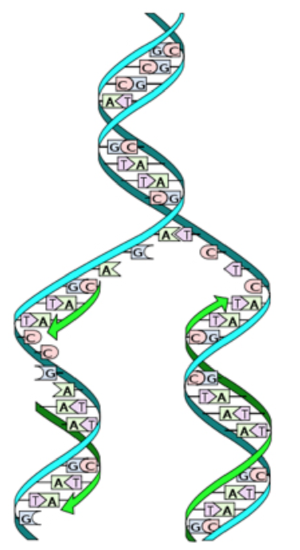
Figure \(\PageIndex{4}\). DNA double helix (CC BY-NC-SA; Forluvoft)
Important Players in DNA Replication
DNA Helicase: breaks the hydrogen bonds between DNA strands (unwinds DNA)
Topoisomerase: alleviates positive supercoiling (twisting of DNA) ahead of the replication fork
Single-stranded binding proteins (SSBPs): keeps the parental strands apart
Primase: synthesizes an RNA primer (gets synthesis of new strand started)
DNA Polymerase III: synthesizes a daughter strand of DNA
DNA Polymerase I: excises the RNA primers and fills in with DNA
DNA ligase: covalently links the Okazaki fragments together
Mechanism of DNA Replication
Getting replication started
The replication of DNA begins at special sites called origins of replication. Bacteria, which have relatively small circular chromosomes, contain just a single origin of replication. Eukaryotic chromosomes, which are long, linear strands of DNA contain many origins of replication along the DNA strands (see below). Proteins that recognize the origins of replication bind to these sequences and separate the two strands, opening up a replication “bubble”. Replication then proceeds in both directions until the entire molecule is copied.
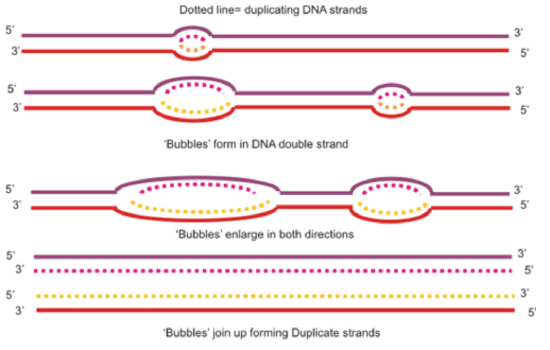
Figure \(\PageIndex{5}\). replication bubbles (CC BY-NC-SA; Boumphreyfr)
At the end of each replication bubble is a replication fork, a Y shaped region where the parental strands of DNA are unwound so that the replication machinery can copy the DNA. Helicases are enzymes that are responsible for untwisting the double helix at the replication forks, separating the two strands and making them available to serve as templates for DNA replication. The untwisting of the double helix by helicase causes additional twisting of the DNA molecule ahead of the replication fork. Topoisomerase is the enzyme that helps to relieve this strain by breaking, untwisting and rejoining the DNA strands. After the parental strands have been separated by helicase, single stranded binding proteins bind to the parental strands to keep them from reannealing to each other.
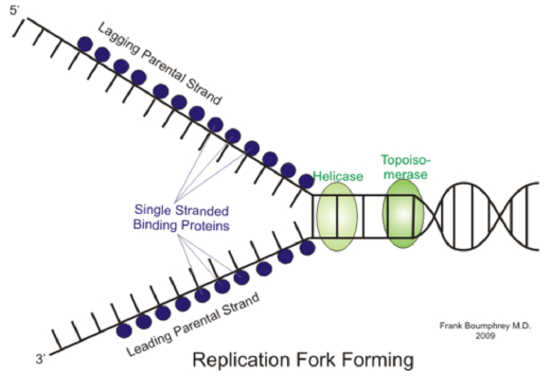
Figure \(\PageIndex{6}\). replication fork forming (CC BY-NC-SA; César Benito Jiménez)
The unwound parental strands are now ready to be copied, but DNA Polymerase, the enzyme responsible for copying DNA, cannot initiate the synthesis of DNA, it can only add nucleotides onto an existing chain of nucleotides. To solve this problem, RNA primase puts down a short sequence of RNA complementary to the template DNA, called a primer that can be used to get DNA replication started. DNA polymerase is then able to synthesize new DNA by adding nucleotides to this preexisting chain.
Making a new DNA strand
As mentioned above, DNA polymerases catalyze the synthesis of new DNA by adding nucleotides to the RNA primer that was laid down by RNA Primase. It should be mentioned that in E.coli there are several different DNA polymerases, but two appear to play major roles: DNA Pol III and DNA Pol I. In eukaryotes, the situation is more complex, with at least 11 different DNA polymerases discovered so far, but the general principles we will discuss in this tutorial are applicable to both systems.
In E.coli, DNA Pol III adds a DNA nucleotide to the 3' end of the RNA primer and then continues adding DNA nucleotides complementary to the template strand. As was mentioned previously, the two ends of a DNA strand are different, in that they are antiparallel to each other. This directionality is important for the synthesis of DNA, because DNA polymerase can only add nucleotides to the 3’ end of a growing DNA strand (not the 5’ end). Thus, a new DNA strand can only be made in the 5’ to 3’ direction.
Leading and Lagging Strands
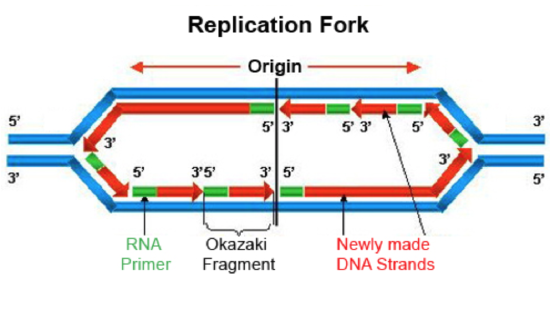
Figure \(\PageIndex{7}\). replication fork (CC BY-NC-SA; César Benito Jiménez)
If we look at the replication fork, we see that this 5’ to 3’ directionality poses a problem. Along one of the template strands, DNA Pol III can synthesize a complementary strand continuously by elongating the new DNA in the 5’ to 3’ direction. This is called the leading strand and it requires only one RNA primer to be made to start replication. However, to elongate the other strand in the 5’ to 3’ direction, DNA Pol III must elongate the new DNA strand in a direction opposite to the movement of the replication fork. This strand is known as the lagging strand. As the replication form proceeds and exposes a new section of the lagging strand template, RNA Primase must put down a new primer for DNA Pol III to elongate. In this way, the lagging strand is completed in a discontinuous manner. The synthesized DNA fragments on the lagging strand are called Okazaki fragments. Another DNA polymerase, DNA Pol I is responsible for removing the RNA primers and replacing them with DNA. DNA ligase then seals the gaps between the Okazaki fragments to complete the newly synthesized lagging strand.
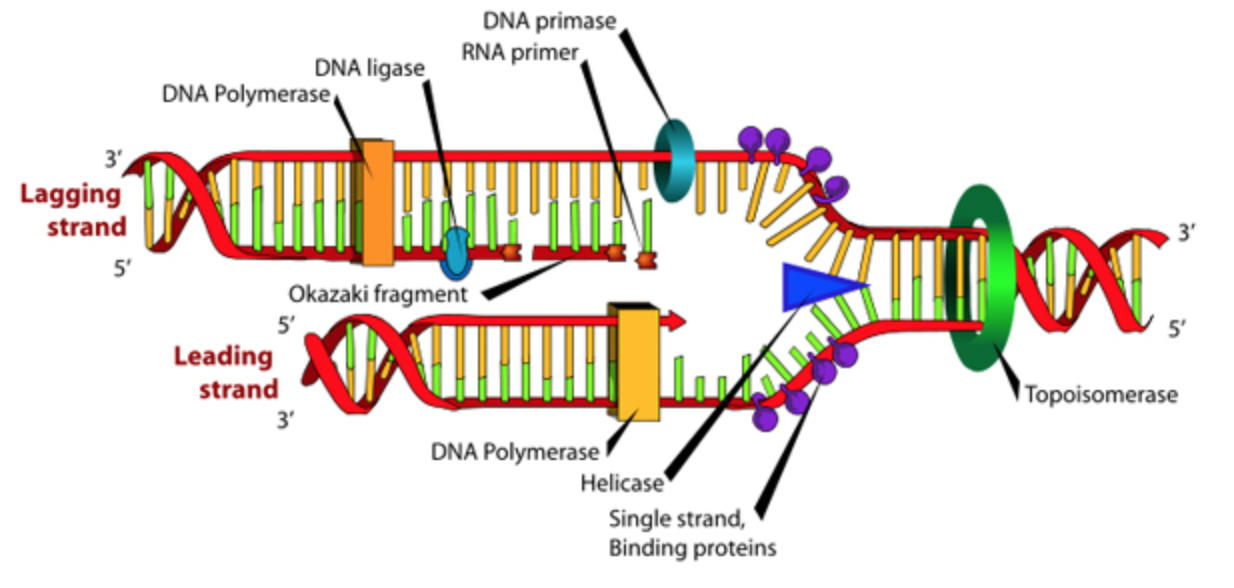
Figure \(\PageIndex{8}\). (CC BY-NC-SA)

DNA Replication Tutorial by Dr. Katherine Harris is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This tutorial was funded by the Title V-STEM Grant #P031S090007.