
20.5: Statistical Methods
- Page ID
- 6030

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)What do the data tell us?
There are two kinds of numerical data acquired by biologists:
- counting; e.g. the number of females in a population
- measuring a continuous variable such as length or weight
In the first case, everyone can agree on the "true" value. In the second case, the measured values always reflect a range, the size of which is determined by such factors as
- precision of the measuring instrument and
- individual variability among the objects being measured.
How are such data handled?
Calculating the Standard Deviation
The first step is to calculate a mean (average) for all the members of the set. This is the sum of all the readings divided by the number of readings taken.
But consider the data sets:
46,42,44,45,43 and 52,80,22,30,36
Both give the same mean (44), but I'm sure that you can see intuitively that an experimenter would have much more confidence in a mean derived from the first set of readings than one derived from the second.
One way to quantify the spread of values in a set of data is to calculate a standard deviation (S) using the equation
\[s =\sqrt{ \dfrac{\sum (x-\bar{x})^2}{n-1}}\]
where ("x minus x-bar)2 is the square of the difference between each individual measurement (x) and the mean ("x-bar") of the measurements. The symbol sigma indicates the sum of these, and n is the number of individual measurements.
Using the first data set, we calculate a standard deviation of 1.6.
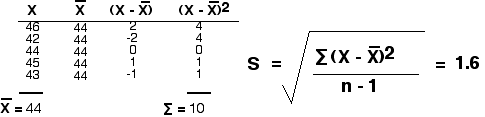
The second data set produces a standard deviation of 22.9.
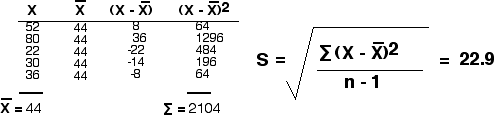
(Many inexpensive hand-held calculators are programmed to do this job for you when you simply enter the values for X.)
Standard Error of the Mean
In our two sets of 5 measurements, both data sets give a mean of 44. But both groups are very small. How confident can we be that if we repeated the measurements thousands of times, both groups would continue to give a mean of 44? To estimate this, we calculate the standard error of the mean (S.E.M. or Sx-bar) using the equation
\[ S_{\bar{x}} = \dfrac{S}{\sqrt{n}}\]
where S is the standard deviation and n is the number of measurements.
In our first data set, the S.E.M. is 0.7.
\[ S_{\bar{x}} = \dfrac{S}{\sqrt{5}} = \dfrac{1.6}{2.23} = 0.7\]
In the second group it is 10.3.
\[ S_{\bar{x}} = \dfrac{S}{\sqrt{5}} = \dfrac{22.9}{2.23} = 10.3\]
95%Confidence Limits
It turns out that there is a 68% probability that the "true" mean value of any effect being measured falls between +1 and −1 standard error (S.E.M.). Since this is not a very strong probability, most workers prefer to extend the range to limits within which they can be 95% confident that the "true" value lies. This range is roughly between −2 and +2 times the standard error.
So
- for our first group, 0.7 x 2 = 1.4
- for our second group, 10.3 x 2 = 20.6
So
- if our first group is representative of the entire population, we are 95% confident that the "true" mean lies somewhere between 42.6 and 45.4 (44 ± 1.4 or 42.6 ≤ 44 ≤ 45.4).
- for our second group, we are 95% confident that the "true" mean lies somewhere between 23.4 and 64.6 (44 ± 20.6 or 23.4 ≤ 44 ≤ 64.6).
Put another way, when the mean is presented along with its 95% confidence limits, the workers are saying that there is only a 1 in 20 chance that the "true" mean value lies outside those limits.
Put still another way: the probability (p) that the mean value lies outside those limits is less than 1 in 20 (p = <0.05 ).
An example:
Assume that 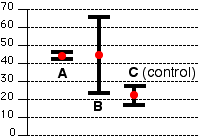
- the first data set ("A") (46,42,44,45,43) represents measurements of five animals that have been given a particular treatment and
- the second data set ("B") (52,80,22,30,36) measurements of five other animals given a different treatment.
- A third set ("C") of five animals was used as controls; they were given no treatment at all, and their measurements were 20,23,24,19,24. The mean of the control group is 22, and the standard error is 2.1.
Did treatment A have a significant effect? Did treatment B?
The graph shows the mean for each data set (red dots). The dark lines represent the 95% confidence limits (± 2 standard errors).
Although both experimental means (A and B) are twice as large as the control mean, only the results in A are significant. The "true" value of B could even be simply that of the untreated animals, the controls (C).
Rejecting the null hypothesis
In principle, a scientist designs an experiment to disprove, or not, that an observed effect is due to chance alone. This is called rejecting the null hypothesis.
The value p is the probability that there is no difference between the experimental and the controls; that is, that the null hypothesis is correct. So if the probability that the experimental mean differs from the control mean is greater than 0.05, then the difference is usually not considered significant. If p = <0.05, the difference is considered significant, and the null hypothesis is rejected.
In our hypothetical example, the difference between the experimental group A and the controls (C) appears to be significant; that between B and the controls does not.
Narrowing the confidence limits
Two approaches can be taken to narrow the confidence limits.
- enlarge the size of the sample being measured (increases n)
- find ways to reduce the fluctuation of measurements about the mean.
The second goal is often much more difficult to achieve; if it proves impossible, perhaps the null hypothesis is right after all!