
4: Genetic Drift and Neutral Diversity
- Page ID
- 96508

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Randomness is inherent to evolution, from the lucky birds blown off course to colonize some new oceanic island, to which mutations arise first in the HIV strain infecting an individual taking anti-retroviral drugs. One major source of stochasticity in evolutionary biology is genetic drift. Genetic drift occurs because more or less copies of an allele by chance can be transmitted to the next generation . This can occur because, by chance, the individuals carrying a particular allele can leave more or less offspring in the next generation. In a sexual population, genetic drift also occurs because Mendelian transmission means that only one of the two alleles in an individual, chosen at random at a locus, is transmitted to the offspring.
Genetic drift can play a role in the dynamics of all alleles in all populations, but it will play the biggest role for neutral alleles. A neutral polymorphism occurs when the segregating alleles at a polymorphic site have no discernible differences in their effect on fitness. We’ll make clear what we mean by "discernible" later, but for the moment think of this as "no effect" on fitness.
The neutral theory of molecular evolution
The role of genetic drift in molecular evolution has been hotly debated since the 60s when the Neutral theory of molecular evolution was proposed . The central premise of Neutral theory is that patterns of molecular polymorphism within species and substitution between species can be well understood by supposing that the vast majority of these molecular polymorphisms and substitutions were neutral alleles, whose dynamics were just subject to the vagaries of genetic drift and mutation. Early proponents of this view suggested that the vast majority of new mutations are either neutral or highly deleterious (e.g. mutations that disrupt important protein functions). This latter class of mutations are too deleterious to contribute much to common polymorphisms or substitutions between species, because they are quickly weeded out of the population by selection.
Neutral theory can sound strange given that much of the time our first brush with evolution often focuses on adaptation and phenotypic evolution. However, proponents of this world-view didn’t deny the existence of advantageous mutations, they simply thought that beneficial mutations are rare enough that their contribution to the bulk of polymorphism or divergence can be largely ignored. They also often thought that much of phenotypic evolution may well be adaptive, but again the loci responsible for these phenotypes are a small fraction of all the molecular change that occur. The neutral theory of molecular evolution was originally proposed to explain protein polymorphism. However, we can apply it more broadly to think about neutral evolution genome-wide. With that in mind, what types of molecular changes could be neutral? Perhaps:
- Changes in non-coding DNA that don’t disrupt regulatory sequences. For example, in the human genome only about 2% of the genome codes for proteins. The rest is mostly made up of old transposable element and retrovirus insertions, repeats, pseudo-genes, and general genomic clutter. Current estimates suggest that, even counting conserved, functional, non-coding regions, less than 10% of our genome is subject to evolutionary constraint .
- Synonymous changes in coding regions, i.e. those that don’t change the amino-acid encoded by a codon.
- Non-synonymous changes that don’t have a strong effect on the functional properties of the amino acid encoded, e.g. changes that don’t change the size, charge, or hydrophobic properties of the amino acid too much.
- An amino-acid change with phenotypic consequences, but little relevance to fitness, e.g. a mutation that causes your ears to be a slightly different shape, or that prevents an organism from living past 50 in a species where most individuals reproduce and die by their 20s.
There are counter examples to all of these ideas, e.g. synonymous changes can affect the translation speed and accuracy of proteins and so are subject to selection. However, the list above hopefully convinces you that the general thinking that some portion of molecular change may not be subject to selection isn’t as daft as it may have initially sounded.
Various features of molecular polymorphism and divergence have been viewed as consistent with the neutral theory of molecular evolution. In this chapter we’ll focus on the prediction of a high level of molecular polymorphism in many species (see for example Figure \ref{fig:Leffer}). In a subsequent chapter we’ll talk about the prediction of a molecular clock. We’ll see that various aspects of the original neutral theory have merit in describing some features and types of molecular change, but we’ll also see that it is demonstrably wrong in some cases. We’ll also see the primary utility of the neutral theory isn’t whether it is right or wrong, but that it serves as a simple null model that can be tested and in some cases rejected, and subsequently built on. The broader debate currently in the field of molecular evolution is the balance of neutral, adaptive, and deleterious changes that drive different types of evolutionary change.
Loss of heterozygosity due to drift
Genetic drift will, in the absence of new mutations, slowly purge our population of neutral genetic diversity, as alleles slowly drift to high or low frequencies and are lost or fixed over time.
Imagine a randomly mating population of a constant size \(N\) diploid individuals, and that we are examining a locus segregating for two alleles that are neutral with respect to each other. This population is randomly mating with respect to the alleles at this locus. See Figures Figure \(\PageIndex{1}\) and Figure \(\PageIndex{2}\) to see how genetic drift proceeds, by tracking alleles within a small population.
In generation \(t\) our current level of heterozygosity is \(H_t\), i.e. the probability that two randomly sampled alleles in generation \(t\) are non-identical is \(H_t\). Assuming that the mutation rate is zero (or vanishingly small), what is our level of heterozygosity in generation \(t+1\)?
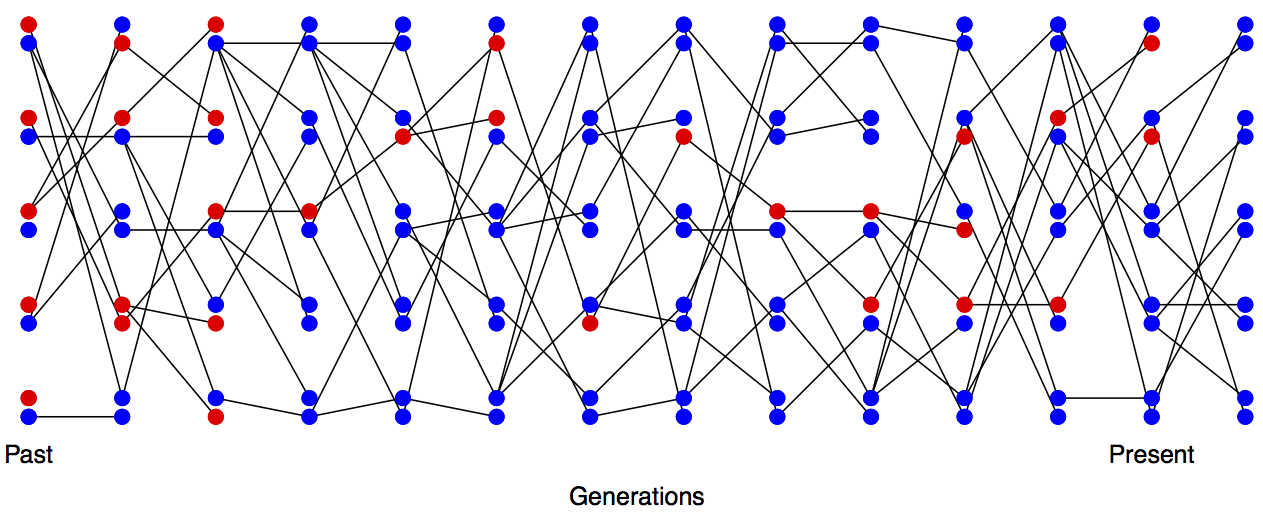
In the next generation (\(t+1\)) we are looking at the alleles in the offspring of generation \(t\). If we randomly sample two alleles in generation \(t+1\) which had different parental alleles in generation \(t\), that is just like drawing two random alleles from generation \(t\). So the probability that these two alleles in generation \(t+1\), that have different parental alleles in generation \(t\), are non-identical is \(H_t\).
Conversely, if the two alleles in our pair had the same parental allele in the proceeding generation (i.e. the alleles are identical by descent one generation back) then these two alleles must be identical (as we are not allowing for any mutation).
In a diploid population of size \(N\) individuals there are \(2N\) alleles. The probability that our two alleles have the same parental allele in the proceeding generation is \(\frac{1}{(2N)}\) and the probability that they have different parental alleles is is \(1-\frac{1}{(2N)}\). So by the above argument, the expected heterozygosity in generation \(t+1\) is
\[H_{t+1} = \frac{1}{2N} \times 0 + \left(1-\frac{1}{2N} \right)H_t\]
Thus, if the heterozygosity in generation \(0\) is \(H_0\), our expected heterozygosity in generation \(t\) is
\[H_t = \left(1-\frac{1}{2N} \right)^tH_0 \label{eqn:loss_het_discrete}\]
i.e. the expected heterozygosity within our population is decaying geometrically with each passing generation. If we assume that \(\frac{1}{(2N)} \ll 1\) then we can approximate this geometric decay by an exponential decay (see Question \ref{geoquestion} below), such that
\[H_t =H_{0} e^{ - \frac{t}{(2N)} }\]
i.e. heterozygosity decays exponentially at a rate \(\frac{1}{(2N)}\).
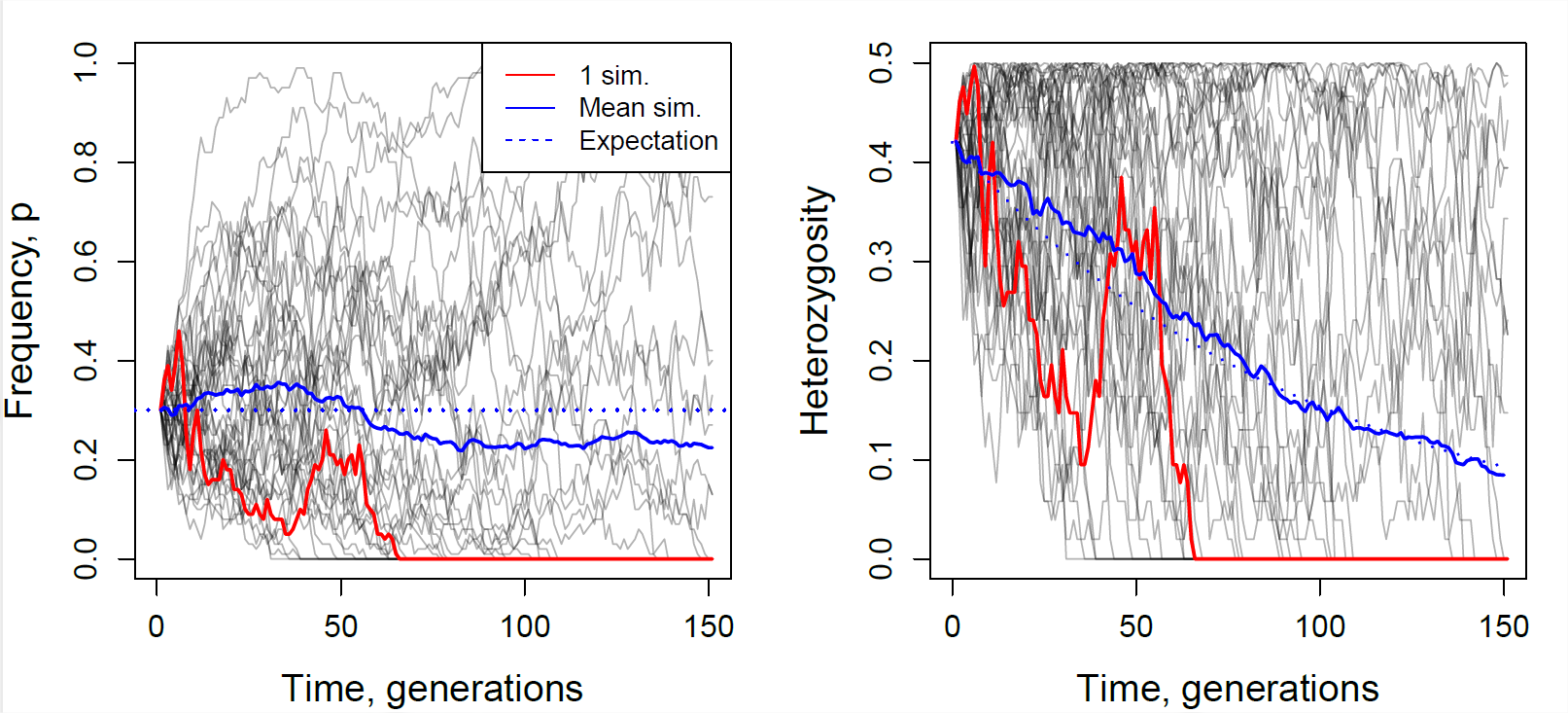
In Figure \(\PageIndex{3}\) we show trajectories through time for 40 independently simulated loci drifting in a population of 50 individuals. Each population was started from a frequency of \(30\%\). Some drift up and some drift down, eventually being lost or fixed from the population, but, on average across simulations, the allele frequency doesn’t change. We also track heterozygosity, you can see that heterozygosity sometimes goes up, and sometimes goes down, but on average we are losing heterozygosity, and this rate of loss is well predicted by Equation \ref{eqn:loss_het_discrete}.
You are in charge of maintaining a population of delta smelt in the Sacramento River delta. Using a large set of microsatellites you estimate that the mean level of heterozygosity in this population is 0.005. You set yourself a goal of maintaining a level of heterozygosity of at least 0.0049 for the next two hundred years. Assuming that the smelt have a generation time of 3 years, and that only genetic drift affects these loci, what is the smallest fully outbreeding population that you would need to maintain to meet this goal?
Note how this picture of decreasing heterozygosity stands in contrast to the consistency of Hardy-Weinberg equilibrium from the previous chapter. However, our Hardy-Weinberg proportions still hold in forming each new generation. As the offspring genotypes in the next generation (\(t+1\)) represent a random draw from the previous generation (\(t\)), if the parental frequency is \(p_t\), we expect a proportion \(2p_t(1-p_t)\) of our offspring to be heterozygotes (and HW proportions for our homozygotes). However, because population size is finite, the observed genotype frequencies in the offspring will (likely) not match exactly with our expectations. As our genotype frequencies likely change slightly due to sampling, biologically this reflects random variation in family size and Mendelian segregation, the allele frequency will changed. Therefore, while each generation represents a sample from Hardy-Weinberg proportions based on the generation before, our genotype proportions are not at an equilibrium (an unchanging state) as the underlying allele frequency changes over the generations. We’ll develop some mathematical models for these allele frequency changes later on. For now, we’ll simply note that under our simple model of drift (formally the Wright-Fisher model), our allele count in the \(t+1^{th}\) generation represents a binomial sample (of size \(2N\)) from the population frequency \(p_t\) in the previous generation. If you’ve read to here, please email Prof Coop a picture of JBS Haldane in a striped suit with the title "I’m reading the chapter 3 notes”. (It’s well worth googling JBS Haldane and to read more about his life; he’s a true character and one of the last great polymaths. )
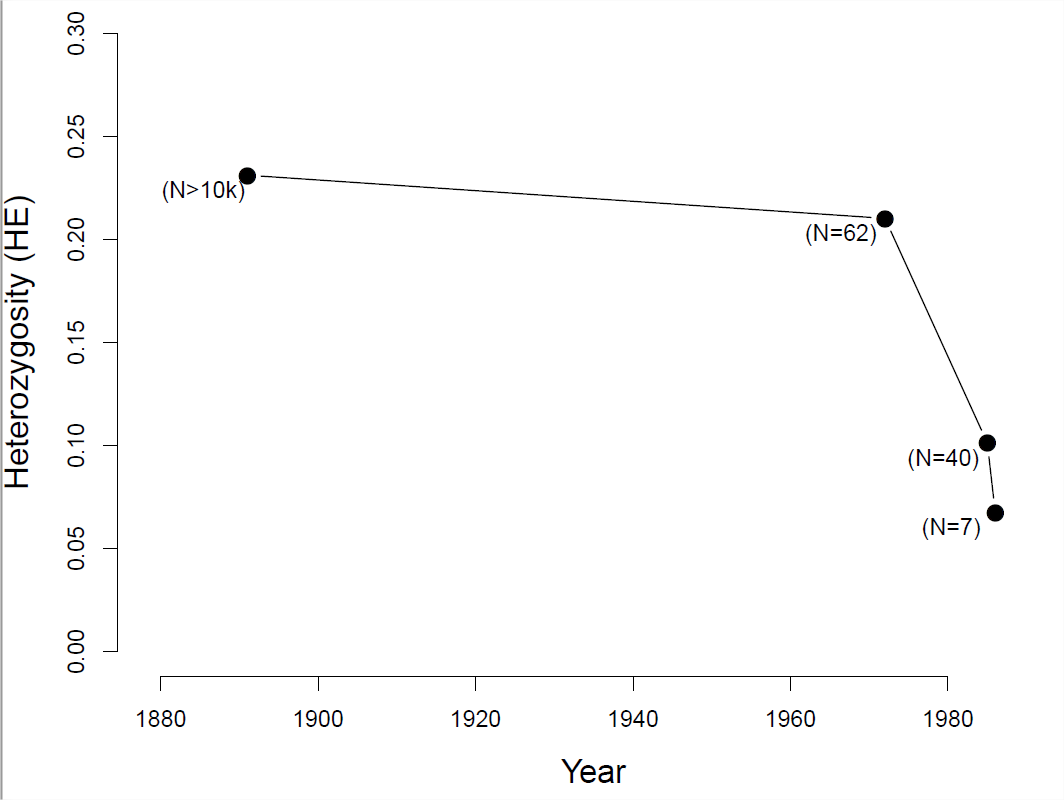
To see how a decline in population size can affect levels of heterozygosity, let’s consider the case of black-footed ferrets (Mustela nigripes). The black-footed ferret population has declined dramatically through the twentieth century due to destruction of their habitat and sylvatic plague. In 1979, when the last known black-footed ferret died in captivity, they were thought to be extinct. In 1981, a very small wild population was rediscovered (\(40\) individuals), but in 1985 this population suffered a number of disease outbreaks.

Figure \(\PageIndex{6}\): The black-footed ferret (M. nigripes).
Wild animals of North America, The National geographical society, 1918. Image from the Biodiversity Heritage Library. Contributed by American Museum of Natural History Library. Not in copyright.
At that point of the \(18\) remaining wild individuals were brought into captivity, 7 of which reproduced. Thanks to intense captive breeding efforts and conservation work, a wild population of over 300 individuals has been established since. However, because all of these individuals are descended from those 7 individuals who survived the bottleneck, diversity levels remain low. measured heterozygosity at a number of microsatellites in individuals from museum collections, showing the sharp drop in diversity as population sizes crashed (see Figure \ref{fig:LossHet_ferrets}).
In mathematical population genetics, a commonly used approximation is \((1-x) \approx e^{-x}\) for \(x << 1\) (formally, this follows from the Taylor series expansion of \(\exp(-x)\), ignoring second order and higher terms of \(x\), see Appendix \ref{eqn:Taylor_geo}). This approximation is especially useful for approximating a geometric decay process by an exponential decay process, e.g. \((1 - x)^t \approx e^{-xt}\). Using your calculator, or R, check how well this expression approximates the exact expression for two values of \(x\), \(x = 0.1\), and \(0.01\), across two different values of t, \(t=5\) and \(t=50\). Briefly comment on your results.
Levels of diversity maintained by a balance between mutation and drift
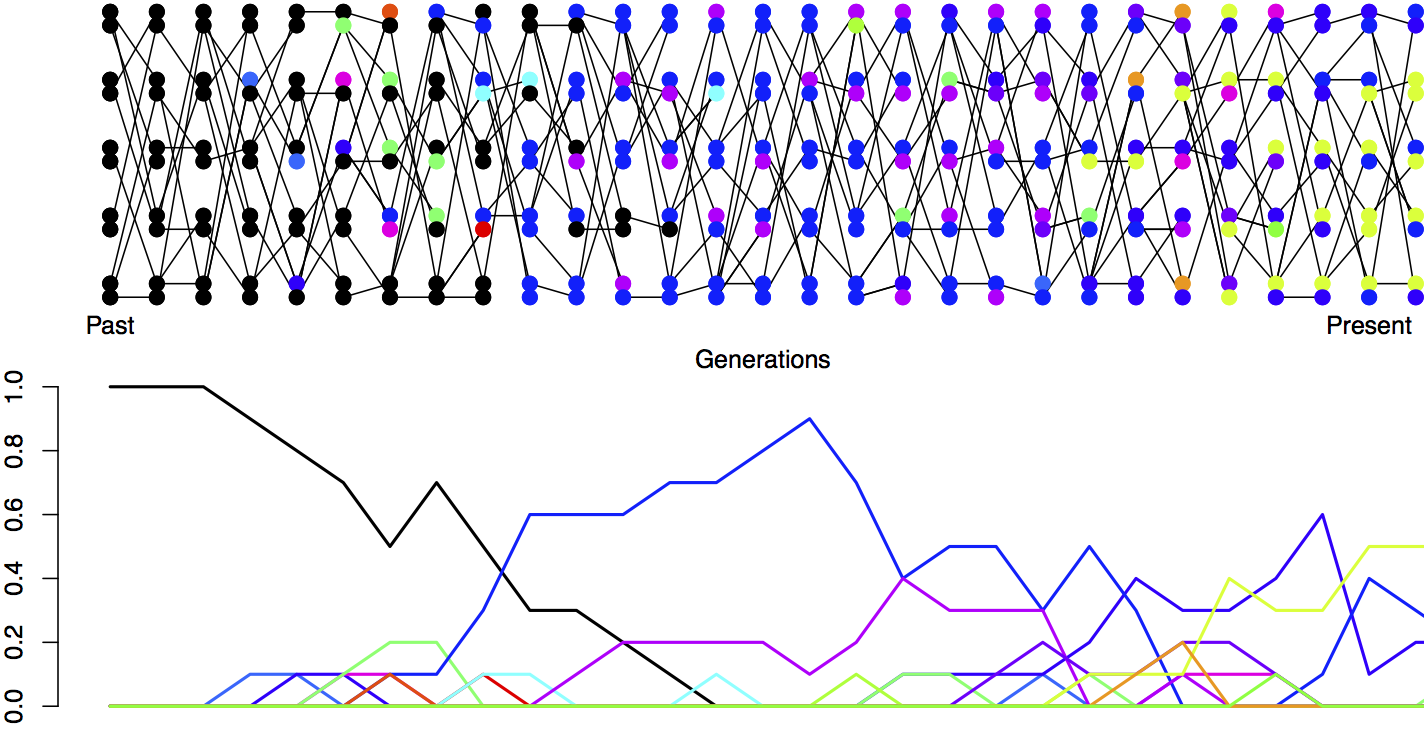
Next we’re going to consider the amount of neutral polymorphism that can be maintained in a population as a balance between genetic drift removing variation and mutation introducing new neutral variation, see Figure \ref{fig:Mut_Sel_balance} for an example. Note in our example, how no single allele is maintained at a stable equilibrium, rather an equilibrium level of polymorphism is maintained by a constantly shifting set of alleles.
The neutral mutation rate
We’ll first want to consider the rate at which neutral mutations arise in the population.Thinking back to our discussion of the neutral theory of molecular evolution, let’s suppose that there are only two classes of mutation that can arise in our genomic region of interest: neutral mutations and highly deleterious mutations. The total mutation rate at our locus is \(\mu\) per generation, i.e. per transmission from parent to child. A fraction \(C\) of our mutations are new alleles that are highly deleterious and so quickly removed from the population. We’ll call this \(C\) parameter the constraint, and it will differ according to the genomic region we consider. The remaining fraction \((1-C)\) are our neutral mutations, such that our neutral mutation rate is \((1-C)\mu\). This is the per generation rate. In the rest of the chapter for simplicity we’ll assume that \(C=0\) and use a neutral mutation rate of \(\mu\). However, we’ll return to this discussion of constraint when we discuss molecular divergence in a subsequent chapter.
It’s worth taking a minute to get familiar with both how rare, and how common, mutation is. The per base pair mutation rate in humans is around \(1.5\) \(\times\) \(10^{-8}\) per generation. That means, on average, we have to monitor a site for \(\sim 66.6\) million transmissions from parent to child to see a mutation. Yet populations and genomes are big places, so mutations are common at these levels.
- Your autosomal genome is \(\sim\) 3 billion base pairs long (\(3\) \(\times\) \(10^9\)). You have two copies, the one you received from your mum and one from your dad. What is the average (i.e. the expected) number of mutations that occurred in the transmission from your mum and your dad to you?
- The current human population size is \(\sim\)7 billion individuals. How many times, at the level of the entire human population, is a single base-pair mutated in the transmission from one generation to the next?
Levels of heterozygosity maintained as a balance between mutation and drift
Looking backwards in time from one generation to the previous generation, we are going to say that two alleles which have the same parental allele (i.e. find their common ancestor) in the preceding generation have coalesced, and refer to this event as a coalescent event. If our pairs of alleles are to be different from each other in the present day, a mutation must have occured more recently on one or other lineage before they found a common ancestor.
The probability that our pair of randomly sampled alleles have coalesced in the preceding generation is \(\frac{1}{(2N)}\), and the probability that our pair of alleles fail to coalesce is \(1-\frac{1}{(2N)}\).
The probability that a mutation changes the identity of the transmitted allele is \(\mu\) per generation. So the probability of no mutation occurring is \((1-\mu)\). We’ll assume that when a mutation occurs it creates some new allelic type which is not present in the population. This assumption (commonly called the infinitely-many-alleles model) makes the math slightly cleaner, and also is not too bad an assumption biologically. See Figure \ref{fig:Mut_Sel_balance} for a depiction of mutation-drift balance in this model over the generations.
This model lets us calculate when our two alleles last shared a common ancestor and whether these alleles are identical as a result of failing to mutate since this shared ancestor. For example, we can work out the probability that our two randomly sampled alleles coalesce \(2\) generations in the past (i.e. they fail to coalesce in generation \(1\) and then coalesce in generation \(2\)), and that they are identical as
\[\left(1- \frac{1}{2N} \right) \frac{1}{2N} (1-\mu)^4\]
Note the power of \(4\) is because our two alleles have to have failed to mutate through \(2\) meioses each.
More generally, the probability that our alleles coalesce in generation \(t+1\) (counting backwards in time) and are identical due to no mutation to either allele in the subsequent generations is
\[\mathbb{P}(\textrm{coal. in t+1 \& no mutations}) = \frac{1}{2N} \left(1- \frac{1}{2N} \right)^t \left(1-\mu \right)^{2(t+1)}\]
To make this slightly easier on ourselves let’s further assume that \(t \approx t+1\) and so rewrite this as:
\[\mathbb{P}(\textrm{coal. in t+1 \& no mutations}) \approx \frac{1}{2N} \left(1- \frac{1}{2N} \right)^t \left(1-\mu \right)^{2t}\]
This gives us the approximate probability that two alleles will coalesce in the \((t+1)^\text{th}\) generation. In general, we may not know when two alleles may coalesce: they could coalesce in generation \(t=1, t=2, \ldots\), and so on. Thus, to calculate the probability that two alleles coalesce in any generation before mutating, we can write:
\[\begin{aligned} \mathbb{P}(\textrm{coal. in any generation \& no mutations}) \approx & \mathbb{P}(\textrm{coal. in} \; t=1 \; \textrm{\& no mutations}) \; + \nonumber\\ & \mathbb{P}(\textrm{coal. in} \; t=2 \; \textrm{\& no mutations}) + \ldots \nonumber\\ %P(\textrm{coal. in} \; t=3 \; \textrm{\& no mutations}) +\ldots \nonumber\\ = & \sum_{t=1}^\infty \mathbb{P}(\textrm{coal. in } \; t \; \textrm{generations \& no mutation})\end{aligned}\]
an example of using the Law of Total Probability, see Appendix Equation \ref{eqn:law_tot_prob}, combined with the fact that coalescing in a particular generation is mutually exclusive with coalescing in a different generation.
While we could calculate a value for this sum given \(N\) and \(\mu\), it’s difficult to get a sense of what’s going on with such a complicated expression. Here, we turn to a common approximation in population genetics (and all applied mathematics), where we assume that \(\frac{1}{(2N)} \ll 1\) and \(\mu \ll 1\). This allows us to approximate the geometric decay as an exponential decay (see Appendix Equation \ref{eqn:Taylor_exp}). Then, the probability two alleles coalesce in generation \(t+1\) and don’t mutate can be written as:
\[\begin{aligned} \mathbb{P}(\textrm{coal. in t+1 \& no mutations}) &\approx \frac{1}{2N} \left(1- \frac{1}{2N} \right)^t \left(1-\mu \right)^{2t} \\ & \approx \frac{1}{2N} e^{-t/(2N)} e^{-2\mu t } \\ &=\frac{1}{2N} e^{-t(2\mu+1/(2N))} \end{aligned}\]
Then we can approximate the summation by an integral, giving us:
\[\frac{1}{2N} \int_0^{\infty} e^{-t(2\mu+1/(2N))} dt = \frac{1/(2N)}{1/(2N)+2\mu} \label{eqn:coal_no_mut}\]
The equation above gives us the probability that our two alleles coalesce at some point in time, and do not mutate before reaching their common ancestor. Equivalently, this can be thought of as the probability our two alleles coalesce before mutating, i.e. that they are homozygous.
Then, the complementary probability that our pair of alleles are non-identical (or heterozygous) is simply one minus this. The following equation gives the equilibrium heterozygosity in a population at equilibrium between mutation and drift:
\[H = \frac{2\mu}{1/(2N)+2\mu} = \frac{4N\mu}{1+4N\mu} \label{eqn:hetero}\]
The compound parameter \(4N\mu\), the population-scaled mutation rate, will come up a number of times so we’ll give it its own name:
\[\theta = 4N\mu\]
What’s the intuition of our \ref{eqn:hetero}, well the probability that any event happens in a particular generation is \(\mathbb{P}(\textrm{mutation or coalescence}) \approx \frac{1}{(2N)}+2\mu\), so conditional on an event happening the probability that it is a mutation is \(\mathbb{P}(\textrm{mutation} \mid \textrm{mutation or coalescence}) = \frac{2\mu}{\left(\frac{1}{(2N)}+2\mu \right)}\).
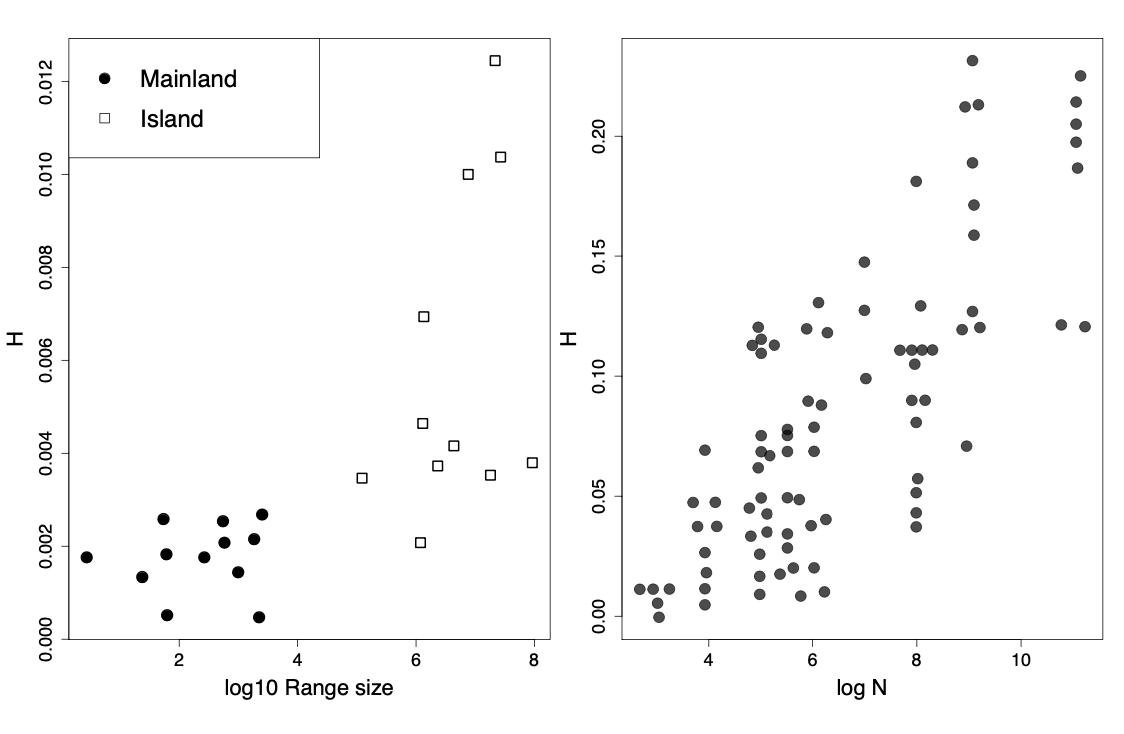
So all else being equal, species with larger population sizes should have proportionally higher levels of neutral polymorphism. Indeed, populations of animals, e.g. birds, on small islands have lower levels of diversity than closely related species on the mainland with larger ranges. More generally, we do see higher levels of heterozygosity in larger census population sizes across animals Figure \ref{fig:allozyme_N}. However, while census population sizes vary over many orders of magnitude, levels of diversity vary much less than that. So, if levels of diversity in natural populations represent a balance between genetic drift and mutation, levels of genetic drift in large populations must be a lot faster than their census population size suggests. In the next section we’ll talk about some possible reasons why.
The effective population size
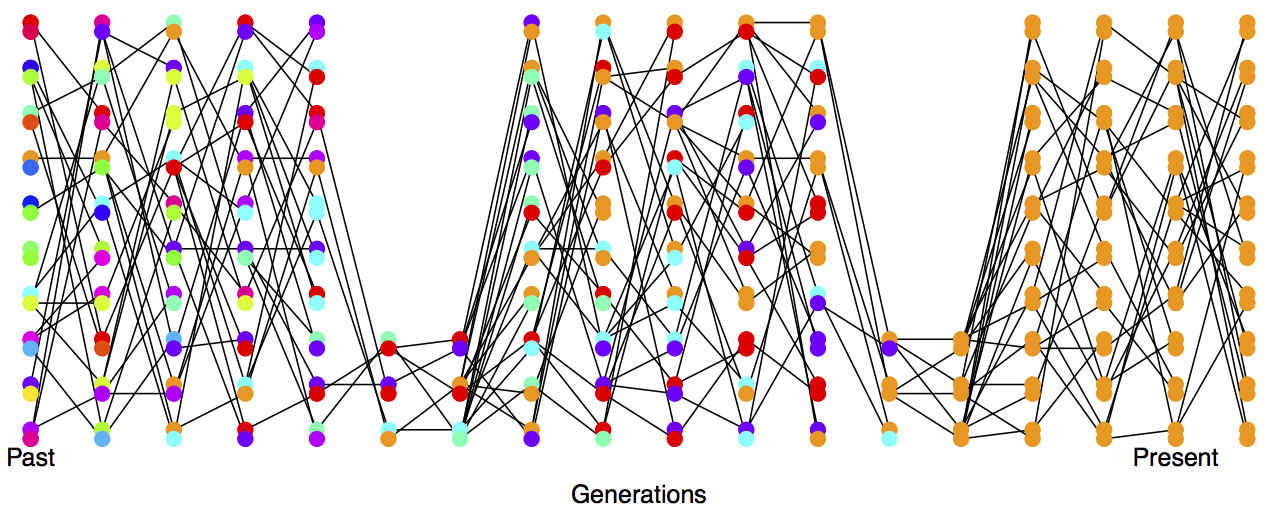
In practice, populations rarely conform to our assumptions of being constant in size with low variance in reproductive success. Real populations experience dramatic fluctuations in size, and there is often high variance in reproductive success. Thus rates of drift in natural populations are often a lot higher than the census population size would imply. See Figure \ref{fig:LossHet_varying_pop} for a depiction of a repeatedly bottlenecked population losing diversity at a fast rate.
To cope with this discrepancy, population geneticists often invoke the concept of an effective population size (\(N_e\)). In many situations (but not all), departures from model assumptions can be captured by substituting \(N_e\) for \(N\).
If population sizes vary rapidly in size, we can (if certain conditions are met) replace our population size by the harmonic mean population size. Consider a diploid population of variable size, whose size is \(N_t\) \(t\) generations into the past. The probability our pairs of alleles have not coalesced by generation \(t\) is given by
\[\prod_{i=1}^{t} \left(1-\frac{1}{2N_i} \right) \label{eqn:var_pop_coal}\]
Note that this simply collapses to our original expression \(\left(1-\frac{1}{2N } \right)^t\) if \(N_i\) is constant. Under this model, the rate of loss of heterozygosity in this population is equivalent to a population of effective size
\[N_e =\frac{1}{\frac{1}{t} \sum_{i=1}^{t} \frac{1}{N_i} }. \label{eq:Ne_harmonic}\]
This is the harmonic mean of the varying population size.
Thus our effective population size, the size of an idealized constant population which matches the rate of genetic drift, is the harmonic mean true population size over time. The harmonic mean is very strongly affected by small values, such that if our population size is one million \(99\%\) of the time but drops to \(1000\) every hundred or so generations, \(N_e\) will be much closer to \(1000\) than a million.
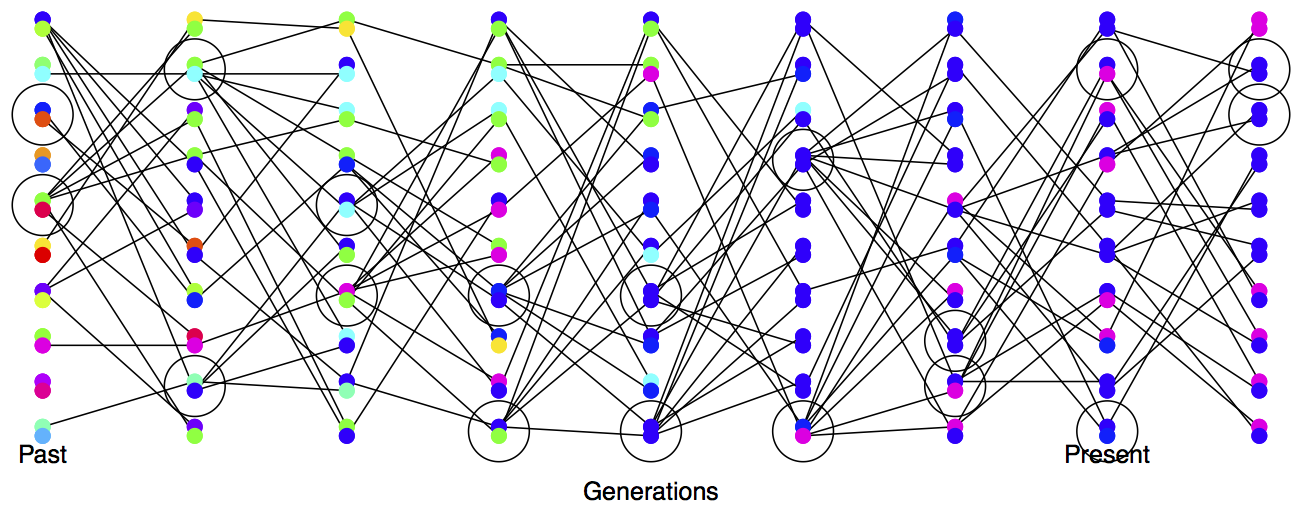
Variance in reproductive success will also affect our effective population size. Even if our population has a large constant size \(N\) individuals, if only small proportion of them get to reproduce, then the rate of drift will reflect this much smaller number of reproducing individuals. See Figure \ref{fig:LossHet_varying_RS} for a depiction of the higher rate of drift in a population where there is high variance in reproductive success.
To see one example of this, consider the case where \(N_F\) of females get to reproduce and \(N_M\) males get reproduce. While every individual has a biological mother and father, not every individual gets to be a parent. In practice, in many animal species far more females get to reproduce than males, i.e. \(N_M <N_F\), as a few males get many mating opportunities and many males get no/few mating opportunities . When our two alleles pick an ancestor, \(25\%\) of the time our alleles were both in a female ancestor, in which case they are IBD with probability \(1/(2N_F)\), and \(25\%\) of the time they are both in a male ancestor, in which case they coalesce with probability \(1/(2N_M)\). The remaining \(50\%\) of the time, our alleles trace back to two individuals of different sexes in the prior generation and so cannot coalesce. Therefore, our probability of coalescence in the preceding generation is
\[\frac{1}{4}\left(\frac{1}{2N_M} \right)+\frac{1}{4}\left(\frac{1}{2N_F} \right) %= %\frac{1}{8}\frac{N_F+N_M}{N_FN_M}\]
i.e. the rate of coalescence is the harmonic mean of the two sexes’ population sizes, equating this to \(\frac{1}{2N_e}\) we find
[fig:Hamadryas_baboon]
\[N_e = \frac{4N_FN_M}{N_F+N_M}\]
Thus if reproductive success is very skewed in one sex (e.g. \(N_M \ll N/2\)), our autosomal effective population size will be much reduced as a result. For more on how different evolutionary forces affect the rate of genetic drift, and their impact on the effective population size, see Charlesworth (2009).

Brehm’s Tierleben (Brehm’s animal life). Brehm, A.E. 1893. Image from the Biodiversity Heritage Library. Contributed by University of Illinois Urbana-Champaign. Not in copyright.
You are studying a population of 500 male and 500 female Hamadryas baboons. Assume that all of the females but only 1/10 of the males get to mate. What is the effective population size for the autosome?
Variance in male and female reproductive success can have very different effects on chromosomes with differing modes of inheritance such as the X chromosome, mitochondria, and Y chromosome. The mitochondria (mtDNA) and Y chromosome are haploid and only inherited through the females and males respectively, so they have a haploid effective population sizes of \(N_M\) and \(N_F\).
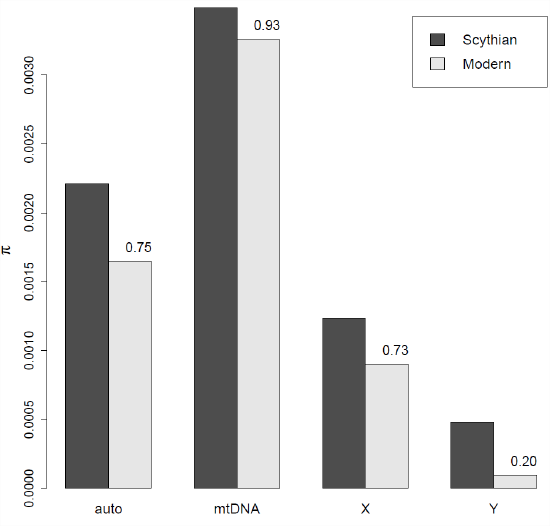 Figure \(\PageIndex{12}\): Levels of genome-wide diversity in Scythian horses from \(2300\) year old Scythian horses and Modern horses (Nordic). The numbers next to each column given the fraction of diversity remaining in the present day, Data from . .
Figure \(\PageIndex{12}\): Levels of genome-wide diversity in Scythian horses from \(2300\) year old Scythian horses and Modern horses (Nordic). The numbers next to each column given the fraction of diversity remaining in the present day, Data from . .
Photograph: V Terebenin/State Hermitage Museum Image from wikimedia contributed by Inritter. This is a faithful photographic reproduction of a two-dimensional, public domain work of art..
Librado et al. (2017) sequenced ancient DNA from 13 sacrificed stallions from an \(2300\) year old Scythian burial mound in Kazakhstan. The Scythian were a nomadic people whose Russian Steppe empire stretched from the Black Sea to the borders of China. They were among the first people to master horseback warfare with both men and women riding armed with short bows.
By comparing these data to modern horses, Librado et al. (2017) found that levels of diversity had been substantially reduced on the autosomes and greatly reduced on the Y chromosome. This contrasts with the mtDNA where levels of diversity have decreased only slightly. This pattern likely reflects the fact that much of modern horse breeding relies on a breeding a small number of stallions to a large number of mares, and so the effective population size of the Y chromosome has been much smaller than the mtDNA leading to a much higher rate of loss of diversity on the Y than on other chromosomes.
长江三角洲及邻近地区孢子植物志 (Spore Flora of
the Yangtze River Delta and Adjacent Areas) 1989. 上海自然博物馆 Image from the Biodiversity Heritage Library. Contributed by Institute
of Botany, Chinese Academy of Sciences. No known copyright restrictions.
Using the data on the reduction in horse genetic diversity in Figure \ref{fig:Scythian_horses_pi}:
- Estimate the effective number of stallions and mares contributing to the horse population using the mtDNA and Y chromosome data
- Predict what the reduction in diversity over the \(2300\) years should be on the autosomes using these numbers?
Assume a horse generation time of \(8\) years. Assume no new mutations during this time interval.
One of the highest levels of genetic diversity is seen in the diploid split-gill fungus, Schizophyllum commune. Populations in the USA have a sequence-level heterozygosity of \(0.13\) per synonymous base . sequenced parents and multiple offspring to estimate that \(\mu= 2 \times 10^{-8} bp^{-1}\) per generation. What is your estimate of the effective population size of S. commune?
The Coalescent and patterns of neutral diversity
“Life can only be understood backwards; but it must be lived forwards” – Kierkegaard
Pairwise Coalescent time distribution and the number of pairwise differences.
Thinking back to our calculations we made about the loss of neutral heterozygosity and equilibrium levels of diversity (in Sections 1.1 and 1.1.1), you’ll note that we could first specify which generation a pair of sequences coalesce in, and then calculate some properties of heterozygosity based on that. That’s because neutral mutations do not affect the probability that an individual transmits an allele, and so don’t affect the way in which we can trace ancestral lineages back through the generations.
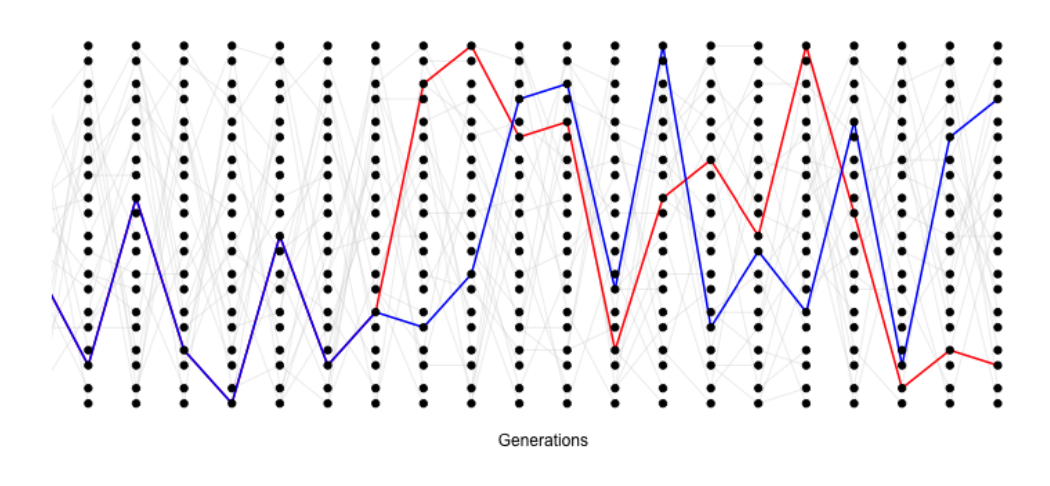
As such, it will often be helpful to consider the time to the common ancestor of a pair of sequences (\(T_2\)), and then think of the impact of that time to coalescence on patterns of diversity. See Figure \(\PageIndex{15}\) for an example of this.
The probability that a pair of alleles have failed to coalesce in \(t\) generations and then coalesce in the \(t+1\) generation back is
\[\mathbb{P}(T_2=t+1) = \frac{1}{2N} \left(1- \frac{1}{2N} \right)^{t} \label{eqn:coal_time_dist}\]
For example, the probability that a pair of sequences coalesce three generations back is the probability that they fail to coalesce in generation 1 and 2, which is \(\left(1- \frac{1}{2N} \right) \times \left(1- \frac{1}{2N} \right)\), multipled by the probability that they find a common ancestor, i.e. coalesce, in the third generation, which happens with probability \(\frac{1}{2N}\).
From the form of Equation \ref{eqn:coal_time_dist} we can see that the coalescent time of our pair of alleles is a Geometrically distributed random variable, where the probability of success is \(p=\frac{1}{2N}\). The waiting time for a pair of lineages to coalesce is like the number of tails thrown while waiting for a head on a coin with the probability of a head is \(\frac{1}{2N}\), i.e. if the population is large we might be waiting for a long time for our pair to coalesce. We’ll denote this geometric distribution by \(T_2 \sim \text{Geo}(1/(2N))\). The expected (i.e. the mean over many replicates) coalescent time of a pair of alleles is then
\[\mathbb{E}(T_2) = 2N\]
generations. This form to the expectation follows from the fact that the mean of an geometric random variable is \(\frac{1}{p}\).
Conditional on a pair of alleles coalescing \(t\) generations ago, there are \(2t\) generations in which a mutation could occur. See Figure \(\PageIndex{16}\) for an example. If the per generation mutation rate is \(\mu\), then the expected number of mutations between a pair of alleles coalescing \(t\) generations ago is \(2 t\mu\) (the alleles have gone through a total of \(2t\) meioses since they last shared a common ancestor).
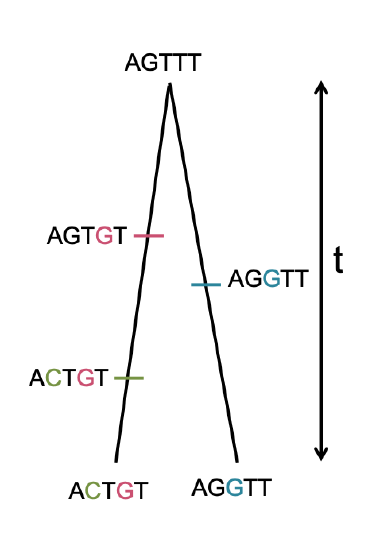
So we can write the expected number of mutations (\(S_2\)) separating two alleles drawn at random from the population as
\[\begin{aligned} \mathbb{E}(S_2) &= \sum_{t=0}^{\infty} \mathbb{E}(S_2 | T_2=t) P(T_2=t) \nonumber\\ & =\sum_{t=0}^{\infty} 2 \mu t P(T_2=t) \nonumber\\ & =2\mu \mathbb{E}(T_2) \nonumber\\ & = 4 \mu N \end{aligned}\]
this makes use of the law of total expectation (see Appendix Equation \ref{eqn:tot_exptation_def}) to average which generation our pair of sequences coalesce in. We’ll assume that mutation is rare enough that it never happens at the same basepair twice, i.e. no multiple hits, such that we get to see all of the mutation events that separate our pair of sequences. This is assumption that repeat mutation is vanishingly rare at a basepair is called the infinitely-many-sites assumption, which should hold if \(N\mu_{BP} \ll 1\), where \(\mu_{BP}\) is the mutation rate per basepair. Thus the number of mutations between a pair of sites is the observed number of differences between a pair of sequences. In the previous chapter we denote the observed number of pairwise differences at putatively neutral sites separating a pair of sequences as \(\pi\) (we usually average this over a number of pairs of sequences for a region). Therefore, under our simple, neutral, constant population-size model we expect
\[\mathbb{E}(\pi) = 4 N \mu = \theta \label{eqn:pi_expectation}\]
So we can get an empirical estimate of \(\theta\) from \(\pi\), let’s call this \(\widehat{\theta}_{\pi}\), by setting \(\widehat{\theta}_{\pi}=\pi\), i.e. our observed level of pairwise genetic diversity. If we have an independent estimate of \(\mu\), then from setting \(\pi =\widehat{\theta}_{\pi} = 4N\mu\) we can furthermore obtain an estimate of the population size \(N\) that is consistent with our levels of neutral polymorphism. If we estimate the population size this way, we should call it the effective coalescent population size (\(N_e\)). It’s best to think about \(N_{e}\) estimated from neutral diversity as a long-term effective population size for the species, but there are many caveats that come along with that assumption. For example, past bottlenecks and population expansions are all subsumed into a single number and so this estimated \(N_{e}\) may not be very representative of the population size at any time. That said, it’s not a bad place to start when thinking about the rate of genetic drift for neutral diversity in our population over long time-periods.
Let’s take a moment to distinguish our expected heterozygosity (Equation \ref{eqn:hetero}) from our expected number of pairwise differences (\(\pi\)). Our expected heterozygosity is the probability that two alleles at a locus, sampled from a population at random, are different from each other. If one or more mutations have occurred since a pair of alleles last shared a common ancestor, then our sequences will be different from each other. On the other hand, our \(\pi\) measure keeps track of the average total number of differences between our loci. As such, \(\pi\) is often a more useful measure, as it records the number of differences between the sequences, not just whether they are different from each other (however, for certain types of loci, e.g. microsatellites, heterozygosity is often used as we cannot usually count up the minimum number of mutations in a sensible way). In the case where our locus is a single basepair, the two measures will usually be close to one another, as \(H \approx \theta\) for small values of \(\theta\). For example, comparing two sequences at random in humans, \(\pi \approx 1/1000\) per basepair, and the probability that a specific base pair differs between two sequences is \(\approx 1/1000\). However, these two quantities start to differ from each other when we consider regions with higher mutation rates. For example, if we consider a 10kb region, our mutation rate will 10,000 times larger than a single base pair. For this length of sequence the probability that two randomly chosen haplotypes differ is quite different from the number of mutational differences between them. (Try a mutation rate of \(10^{-8}\) per base and a population size of \(10,000\) in our calculations of \(\E[\pi]\) and H to see this.)

Diseases and enemies of poultry. Pearson and Warren. (1897) Image from the Biodiversity Heritage Library. Contributed by University of California Libraries. Not in copyright.
Robinson found that the endangered Californian Channel Island fox on San Nicolas had very
found that the endangered Californian Channel Island fox on San Nicolas had very low levels of diversity (\(\pi =0.000014 \text{bp}^{-1}\)) compared to its close relative the California mainland gray fox (\(0.0012\text{bp}^{-1}\)).
- Assuming a mutation rate of \(2\times 10^{-8}\) per bp, what effective population sizes do you estimate for these two populations?
- Why is the effective population size of the Channel Island fox so low? [Hint: quickly google Channel island foxes to read up on their history, also to see how ridiculously cute they are.]
In your own words describe why the coalescent time of a pair of lineages scales linearly with the (effective) population size.
More details on the pairwise coalescent and the randomness of mutation
We found that our pairwise coalescent times followed a Geometric distribution, Equation \ref{eqn:coal_time_dist}. However, that assumes discrete generations, and we’ll often was to think about populations that lack discrete generations (i.e. individuals reproducing at random times with some mean generation time). Using our exponential approximation, we can see that is
\[\approx \frac{1}{2N} e^{-t/(2N)}\]
and so think of a continuous random variable, i.e. we could say that the coalescent time of a pair of sequences (\(T_2\)) is approximately exponentially distributed with a rate \(1/(2N)\), i.e. \(T_2 \sim \text{Exp}\left( 1/(2N) \right)\). Formally we can do this by taking the limit of the discrete process more carefully. See Appendix Equation \ref{eqn:exp_rv_def} for more on exponential random variables.
We’ve derived the expected number of differences between a pair of sequences and talked about the variability of the coalescent time for a pair of sequences. The mutation process is also very variable; even if two sequences coalesce in the very distant past by chance, they may still be identical in the present if there was no mutation during that time.
Conditional on the coalescent time \(t\), the probability that our pair of alleles are separated by \(S_2\) mutations since they last shared a common ancestor is bionomially distributed
\[\mathbb{P}(S_2 | T_2 = t ) = {2t \choose j} \mu^{j} (1-\mu)^{2t-j}\]
i.e. mutations happen in \(j\) generations and do not happen in \(2t-j\) generations (with \({2t \choose j}\) ways this combination of events can possibly happen). See Appendix Equation \ref{eqn:binomial_dist} for discussion of the binomial distribution. Assuming that \(\mu \ll 1\) and that \(2t-j \approx 2t\), then we can approximate the probability that we have \(S_2\) mutations as a Poisson distribution:
\[\mathbb{P}(S_2 | T_2 = t ) = \frac{ (2 \mu t )^{j} e^{-2\mu t}}{j!}\]
i.e. a Poisson with mean \(2\mu t\). This is an example of taking the binomial distribution to its Poisson distribution limit, see Appendix Equation \ref{eqn:bionom_to_poiss} for more details. We’ll not make much use of this result, but it is very useful in thinking about how to simulate the process of mutation.
The coalescent process of a sample of alleles.
Usually we are not just interested in pairs of alleles, or the average pairwise diversity. Generally we are interested in the properties of diversity in samples of a number of alleles drawn from the population. Instead of just following a pair of lineages back until they coalesce, we can follow the history of a sample of alleles back through the population.
Consider first sampling three alleles at random from the population. The probability that all three alleles choose exactly the same ancestral allele one generation back is \(\frac{1}{(2N)^2}\). If \(N\) is reasonably large, then this is a very small probability. As such, it is very unlikely that our three alleles coalesce all at once, and in a moment we’ll see that it is safe to ignore such unlikely events.
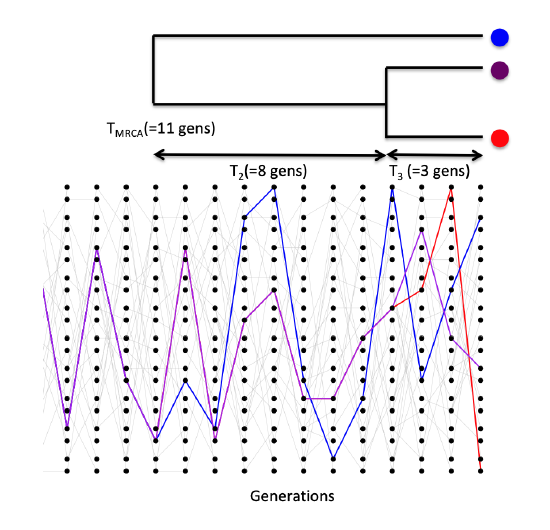
The probability that a specific pair of alleles find a common ancestor in the preceding generation is still \(\frac{1}{(2N)}\). There are three possible pairs of alleles, so the probability that no pair finds a common ancestor in the preceding generation is
\[\left(1-\frac{1}{2N} \right)^3 \approx \left( 1- \frac{3}{2N} \right)\]
In making this approximation we are multiplying out the right hand-side and ignoring terms of \(1/N^2\) and higher (a Taylor approximation, see Appendix Equation \ref{eqn:Taylor_exp}). See Figure \ref{fig:Coalescent_simulation_3} for a random realization of this process.
More generally, when we sample \(i\) alleles there are \({i \choose 2}\) pairs, i.e. \(i(i-1)/2\) pairs. Thus, the probability that no pair of alleles in a sample of size \(i\) coalesces in the preceding generation is
\[\left(1-\frac{1}{(2N)} \right)^{i \choose 2} \approx \left( 1- \frac{i \choose 2}{2N}\right)\]
while the probability any pair coalesces is \(\approx \frac{i \choose 2}{2N}\), again using Equation \ref{eqn:Taylor_exp}.
We can ignore the possibility that more than pairs of alleles (e.g. tripletons) simultaneously coalesce at once as terms of \(\frac{1}{N^2}\) and higher can be ignored as they are vanishingly rare. Obviously in reasonable sample sizes there are many more triples (\({i \choose 3}\)) and higher order combinations than there are pairs (\({i \choose 2}\)), but if \(i \ll N\) then we are safe to ignore these terms.
When there are \(i\) alleles, the probability that we wait until the \(t+1\) generation before any pair of alleles coalesces is
\[\mathbb{P}(T_i =t+1) = \frac{i \choose 2}{2N}\left( 1- \frac{i \choose 2}{2N}\right)^{t} \label{eqn:T_i}\]
Thus the waiting time to the first coalescent event while there are \(i\) lineages is a geometrically distributed random variable with probability of success \(p=\frac{i \choose 2}{2N}\), which we denote by
\[T_i \sim \text{Geo} \left( \frac{i \choose 2}{2N} \right).\]
The mean waiting time till any of pair within our sample coalesces is
\[\mathbb{E}( T_i) = \frac{2N}{i \choose 2} \label{eqn:E_T_i}\]
which again follows from the mean of a geometric random variable being \(\frac{1}{p}\).
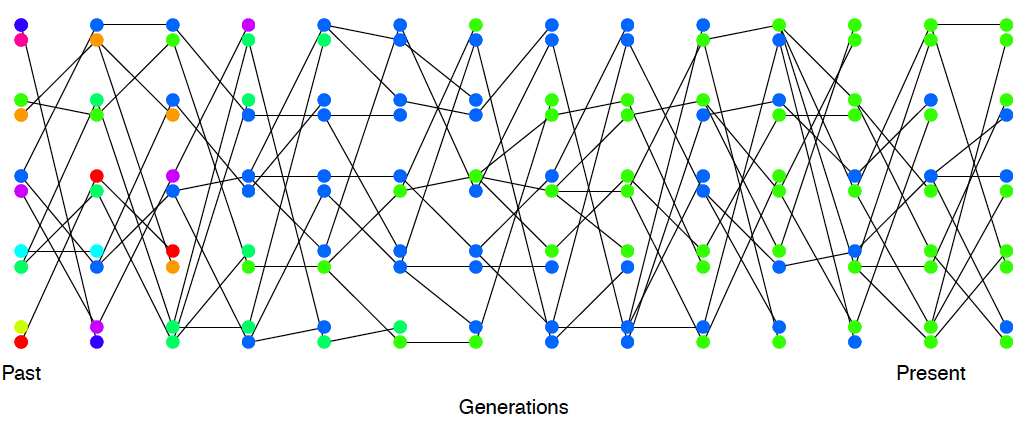
After a pair of alleles first finds a common ancestral allele some number of generations back in the past, we only have to keep track of that common ancestral allele for the pair when looking further into the past. In our example coalescent genealogy for our 3 alleles, shown in Figure \(\PageIndex{18}\), we start by tracking the 3 lineages, then by chance the blue and purple coalesce in the four generations back. Then we’re tracking just two lineages, the red lineage and the ancestral lineage of the blue and purple alleles; then those two coalesce and we’ve found our most recent common ancestor of our sample. Another example with four tips is shown in Figure \(\PageIndex{19}\); we’re track four lineages, then a pair coalesce, then we tracking three lineages, then a pair coalesce, then we’re tracking two lineages, then this final pair coalesce and we’ve found the most recent common ancestor of our sample (fin, end scene).
More generally, when a pair of alleles in our sample of \(i\) alleles coalesces, we then switch to having to follow \(i-1\) alleles back in time. Then when a pair of these \(i-1\) alleles coalesce, we then only have to follow \(i-2\) alleles back. This process continues until we coalesce back to a sample of two, and from there to a single most recent common ancestor (MRCA).
To simulate a coalescent genealogy at a locus for a sample of \(n\) alleles we therefore simply follow the following algorithm:
- Set \(i=n\).
- Simulate a random variable to be the time \(T_i\) to the next coalescent event from \(T_i \sim \text{Exp}\left(\frac{i \choose 2}{2N} \right)\)
- Choose a pair of alleles to coalesce at random from all possible pairs.
- Set \(i=i-1\)
- Continue looping steps 2-4 until \(i=1\), i.e. the most recent common ancestor of the sample is found.
By following this algorithm we are generating realizations of the genealogy of our sample.
Expected properties of coalescent genealogies and mutations
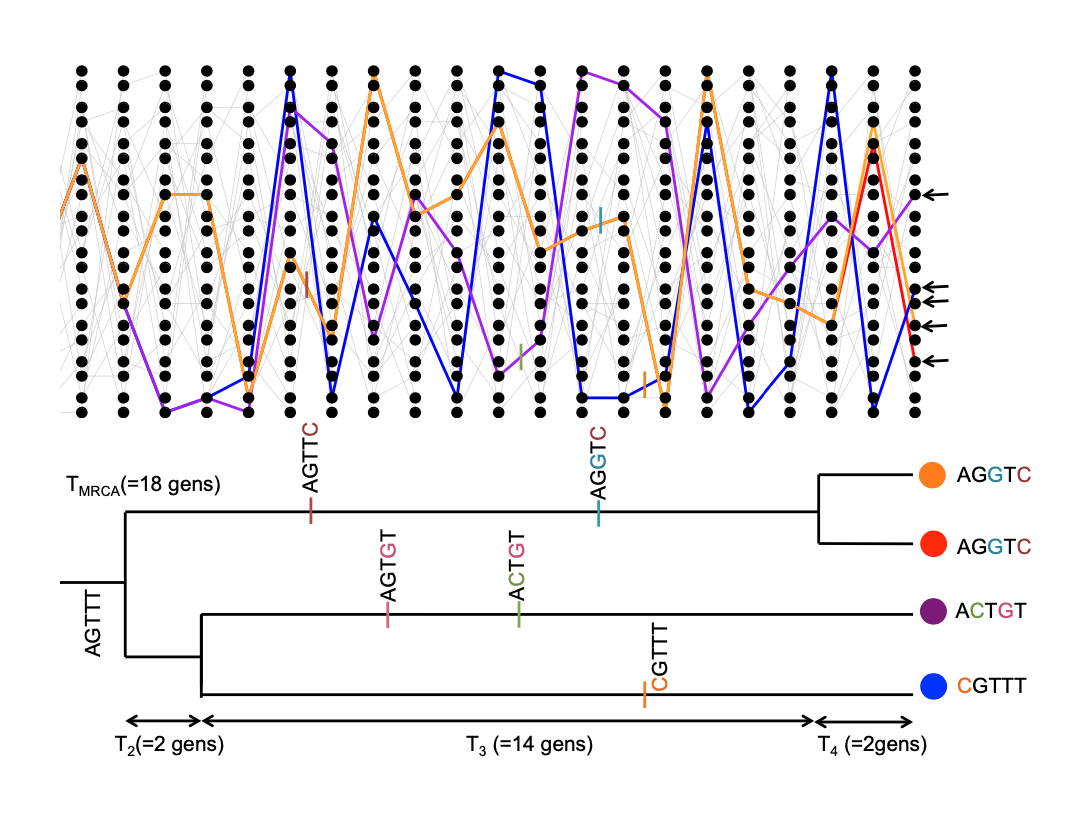
The expected time to the most recent common ancestor.
We will first consider the time to the most recent common ancestor of the entire sample (\(T_{MRCA}\)). This is
\[T_{MRCA} = \sum_{i=n}^2 T_i\]
generations back, where we are summing from \(i=n\) alleles counting backwards to \(i=2\) alleles (see Figure \(\PageIndex{19}\) for example). As our coalescent times for different \(i\) are independent, the expected time to the most recent common ancestor is
\[\mathbb{E}(T_{MRCA}) = \sum_{i=n}^2 \mathbb{E}(T_i) = \sum_{i=n}^2 2N/{i \choose 2}\]
Using the fact that \(\frac{1}{i(i-1)}=\frac{1}{i-1} - \frac{1}{i}\) and a bit of rearrangement, we can rewrite this as
\[\mathbb{E}(T_{MRCA}) = 4N\left(1- \frac{1}{n} \right) \label{TMRCA_neutral}\]
So the average \(T_{MRCA}\) scales linearly with population size \(N\). Interestingly, as we move to larger and larger samples (i.e. \(n \gg 1\)), the average time to the most recent common ancestor converges on \(4N\). What’s happening here is that in large samples our lineages typically coalesce rapidly at the start and very soon coalesce down to a much smaller number of lineages.
Assume an autosomal effective population of 10,000 individuals (roughly the long-term human estimate) and a generation time of 30 years. What is the expected time to the most recent common ancestor of a sample of 20 people? What is this time for a sample of 500 people?
The expected total time in a genealogy and the number of segregating sites.
Mutations fall on specific lineages of the coalescent genealogy and are transmitted to all descendants of their lineage. Furthermore, under the infinitely-many-sites assumption, each mutation creates a new segregating site. The mutation process is a Poisson process, and the longer a particular lineage, i.e. the more generations of meioses it represents, the more mutations that can accumulate on it. The total number of segregating sites in a sample is thus a function of the total amount of time in the genealogy of the sample, or the sum of all the branch lengths on the genealogical tree, \(T_{tot}\). Our total amount of time in the genealogy is
\[T_{tot} = \sum_{i=n}^2 iT_i\]
as when there are \(i\) lineages, each contributes a time \(T_i\) to the total time (see Figure \(\PageIndex{19}\) for an example). Taking the expectation of the total time in the genealogy,
\[\mathbb{E}(T_{tot}) = \sum_{i=n}^2 i \frac{2N}{{i \choose 2} } = \sum_{i=n}^2 \frac{4N}{i -1} =\sum_{i=n-1}^1 \frac{4N}{i} \label{eqn:E_T_tot}\]
we see that our expected total amount of time in the genealogy scales linearly with our population size \(N\). Our expected total amount of time is also increasing with sample size \(n\), but is doing so very slowly. This again follows from the fact that in large samples, the initial coalescence usually happens very rapidly, so that extra samples add little to the total amount of time in the genealogical tree. We saw above that the number of mutational differences between a pair of alleles that coalescence \(T_2\) generations ago was Poisson with a mean of \(2 \mu T_2\), where \(2T_{2}\) is the total branch length in this simple 2-sample genealogical tree. A mutation that occurs on any branch of our genealogy will cause a segregating polymorphism in the sample (meeting our infinitely-many-sites assumption). Thus, if the total time in the genealogy is \(T_{tot}\), there are \(T_{tot}\) generations for mutations. So the total number of mutations segregating in our sample (\(S\)) is Poisson with mean \(\mu T_{tot}\). Thus the expected number of segregating sites in a sample of size \(n\) is
\[\mathbb{E}(S) = \mu \mathbb{E}(T_{tot}) = \sum_{i=n-1}^1 \frac{4N\mu }{i} = \theta \sum_{i=n-1}^1 \frac{1}{i} \label{eqn:seg_sites}\]
Note that this is growing with the sample size \(n\), albeit very slowly (roughly at the rate of the \(\log\) of the sample size). We can use this formula to derive another estimate of the population scaled mutation rate \(\theta\), by setting our observed number of segregating sites in a sample (\(S\)) equal to this expectation. We’ll call this estimator \(\widehat{\theta}_W\):
\[\widehat{\theta}_W =\frac{ S}{\sum_{i=n-1}^1 \frac{1}{i}} \label{watterson_theta}\]
This estimator of \(\theta\) was devised by , hence the \(W\).
The neutral site-frequency spectrum
We can use our coalescent process to find the expected number of derived alleles present \(i\) times out of a sample size \(n\), e.g. how many singletons (\(i = 1\)) do we expect to find in our sample? For example, in Figure \(\PageIndex{19}\ in our sample of four sequences, there are 3 singletons and 2 doubletons. The number of sites with these different allele frequencies depends on the lengths of specific genealogical branches. A mutation that falls on a branch with \(i\) descendants will create a derived allele with frequency \(i\). For example, in our example tree in Figure \(\PageIndex{19}\, the total number of generations where a mutation could arise and be a doubleton is \(T_3+2T_2\), the total length of the branch ancestral to just the orange and red allele \((T_3+T_2)\) plus the branch ancestral to just the blue and purple allele \((T_2)\).
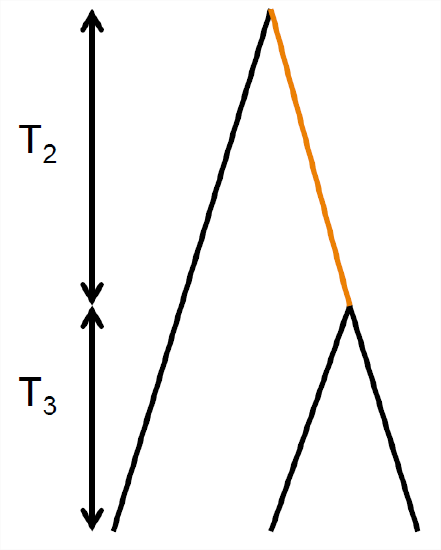
To see how we could go about working this out, let’s start by considering the simple coalescent tree, shown in Figure \(\PageIndex{20}\, for sample of \(3\) alleles drawn from a population. Mutations that fall on the branches coloured in black will be derived singletons, while mutations that fall along the orange branch will be doubletons in the sample. The total number of generations where a singleton mutation could arise is \(3 T_3 + T_2\). Note that we only count the time where there are two lineages \((T_{2})\) once. So our expected number of singletons, using Equation \ref{eqn:E_T_i}, is
\[\mathbb{E}(S_i) = \mu \left( 3\mathbb{E}(T_3) + \mathbb{E}(T_2) \right) = \mu \left( 3 \frac{2N}{3}+ 2N \right) = \theta\]
By similar logic, the time where doubletons could arise is \(T_2\) and our expected number of doubletons is \(\mathbb{E}(S_i) =\theta/2\). Thus, there are on average half as many doubletons as singletons.
Extending this logic to larger samples might be doable, but is tedious (I mean really tedious: for 10 alleles there are thousands of possible tree shapes and the task quickly gets impossible even computationally). A nice, relatively simple proof of the neutral site frequency spectrum is given by , but we won’t give this here. The general form is:
\[\mathbb{E}(S_i) = \frac{\theta }{i} \label{eqn:neutral_freq_spec}\]
i.e. there are twice as many singletons as doubletons, three times as many singletons as tripletons, and so on. The other thing that will be helpful for us to know is that neutral alleles at intermediate frequency tend to be old, and those that are rare in the sample are on average young. We expect to see a lot more rare alleles in our sample than common alleles.
There are two possible tree shapes that could relate four samples. Draw both of them and separately colour (or otherwise mark) the branches by where singletons, doubletons, and tripleton derived alleles could arise.
We can also ask the probability of observing a derived allele segregating at frequency \(i/n\) given that the site is polymorphic in our sample of size \(n\) (i.e. given that \(0<i<n\) ). We can obtain this probability by dividing the expected number of sites segregating for an allele at frequency \(i\) by the expected number segregating at all of the possible allele frequencies for polymorphisms in our sample
\[\begin{aligned} \mathbb{P}(i |0<i<n) &=\frac{\mathbb{E}(S_i)}{\sum_{j=1}^{n-1} \mathbb{E}(S_j)} = \frac{\frac{1}{i}}{\sum_{j=1}^{n-1} \frac{1}{j}}.\end{aligned}\]
We can interpret this probability as the fraction of polymorphic sites we expect to find at a frequency \(i/n\).
Tests based on the site frequency spectrum
Population geneticists have proposed a variety of ways to test whether an observed site frequency spectrum conforms to its neutral, constant-size expectations. These tests are useful for detecting population size changes using data across many loci, or for detecting the signal of selection at individual loci. One of the first tests was proposed by , and is called Tajima’s \(D\). Tajima’s \(D\) is
\[D = \frac{\hat{\theta}_{\pi}-\hat{\theta}_{W}}{C} \label{eqn_Tajimas_D}\]
where the numerator is the difference between the estimate of \(\theta\) based on pairwise differences and that based on segregating sites. As these two estimators both have expectation \(\theta\) under the neutral, constant-size model, the expectation of \(D\) is zero. The denominator \(C\) is a positive constant; it’s the square-root of an estimator of the variance of this difference under the constant population size, neutral model. This constant was chosen for \(D\) to have mean zero and variance \(1\) under the null model, so we can test for departures from this simple null model.
An excess of rare alleles compared to the constant-size, neutral model will result in a negative Tajima’s \(D\), because each additional rare allele increases the number of segregating sites by \(1\), but only has a small effect on the number of pairwise differences between samples. In contrast, a positive Tajima’s \(D\) reflects an excess of intermediate frequency alleles relative to the constant-size, neutral expectation. Alleles at intermediate-frequency increase pairwise diversity more per segregating site than typical, thus increasing \(\theta_{\pi}\) more than \(\theta_{W}\). In the next section we’ll see how long-term changes in population size systematically change the site frequency spectrum and so are detectable by statistics such as Tajima’s \(D\).
Demography and the coalescent
We’ve already seen how changes in population size can change the rate at which heterozygosity is lost from the population (see the discussion around Equation \ref{eqn:var_pop_coal}). If the population size in generation \(i\) is \(N_i\), the probability that a pair of lineages coalesce is \(\frac{1}{(2N_i)}\); this conforms to our intuition that if the population size is small, the rate at which pairs of lineages find their common ancestor is faster. We can potentially accommodate rapid random fluctuations in population size by simply using the effective population size \(N_e\) in place of \(N\). However, longer-term, more systematic changes in population size will distort the coalescent genealogies, and hence patterns of diversity, in more systematic ways.
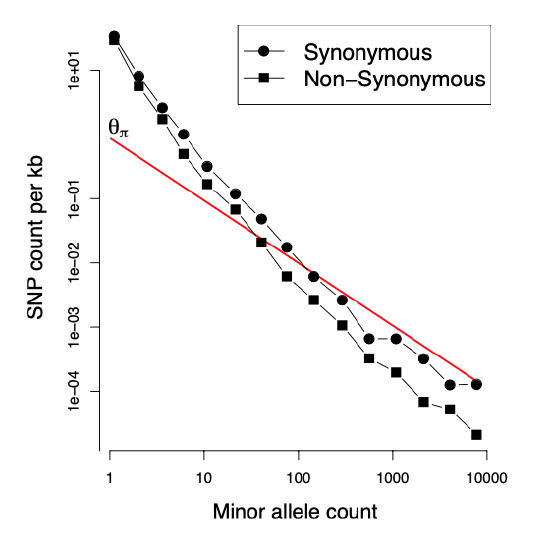
We can see how demography potentially distorts the observed frequency spectrum away from the neutral expectation in a very large sample of humans shown in Figure \(\PageIndex{21}\). For comparison, the neutral frequency spectrum, Equation \ref{eqn:neutral_freq_spec}, is shown as a red line. There are vastly more rare alleles than expected under our neutral, constant-size-size model, but the neutral prediction and reality agree somewhat more for alleles that are more common.
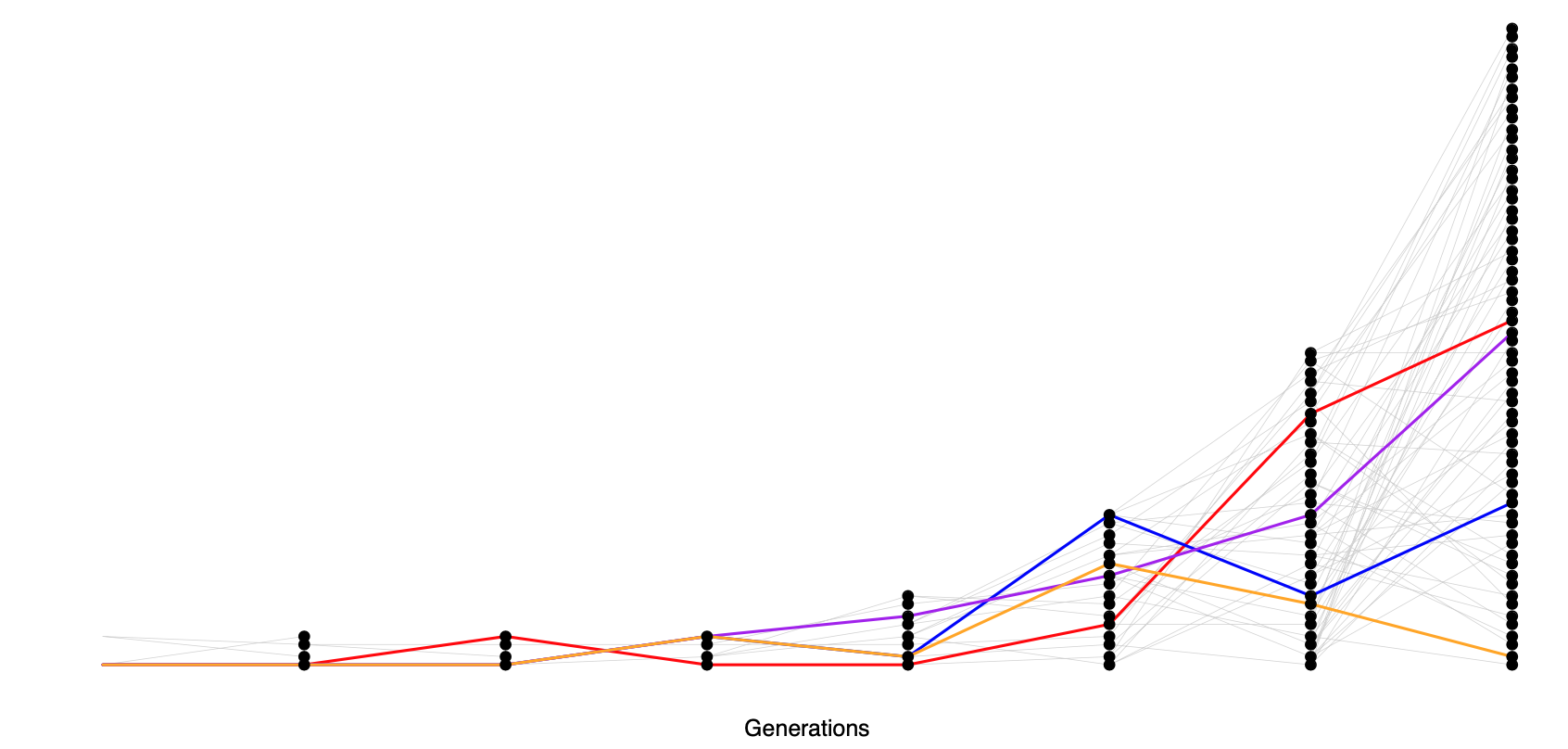
Why is this? Well, these patterns are likely the result of the very recent explosive growth in human populations. If the population has grown rapidly, then the pairwise-coalescent rate in the past may be much higher than the coalescent rate closer to the present. (see Figure \(\PageIndex{22}\)).
One consequence of a recent population expansion is that there is much less genetic diversity in the population than you’d predict using the census population size. Humans are one example of this effect; there are \(7\) billion of us alive today, but this is due to very rapid population growth over the past thousand to tens of thousands of years. Our level of genetic diversity is very much lower than you’d predict given our census size, reflecting our much smaller ancestral population. A second consequence of recent population expansion is that the deeper coalescent branches are much more squished together in time compared to those in a constant-sized population. Mutations on deeper branches are the source of alleles at more intermediate frequencies, and so there are even fewer intermediate-frequency alleles in growing populations. That’s why there are so many rare alleles, especially singletons, in this large sample of Europeans.
Another common demographic scenario is a population bottleneck. In a bottleneck, the population size crashes dramatically, and subsequently recovers. For example, our population may have had size \(N_{\textrm{Big}}\) and crashed down to \(N_{\textrm{Small}}\). One example of a bottleneck is shown in Figure \(\PageIndex{23}\).
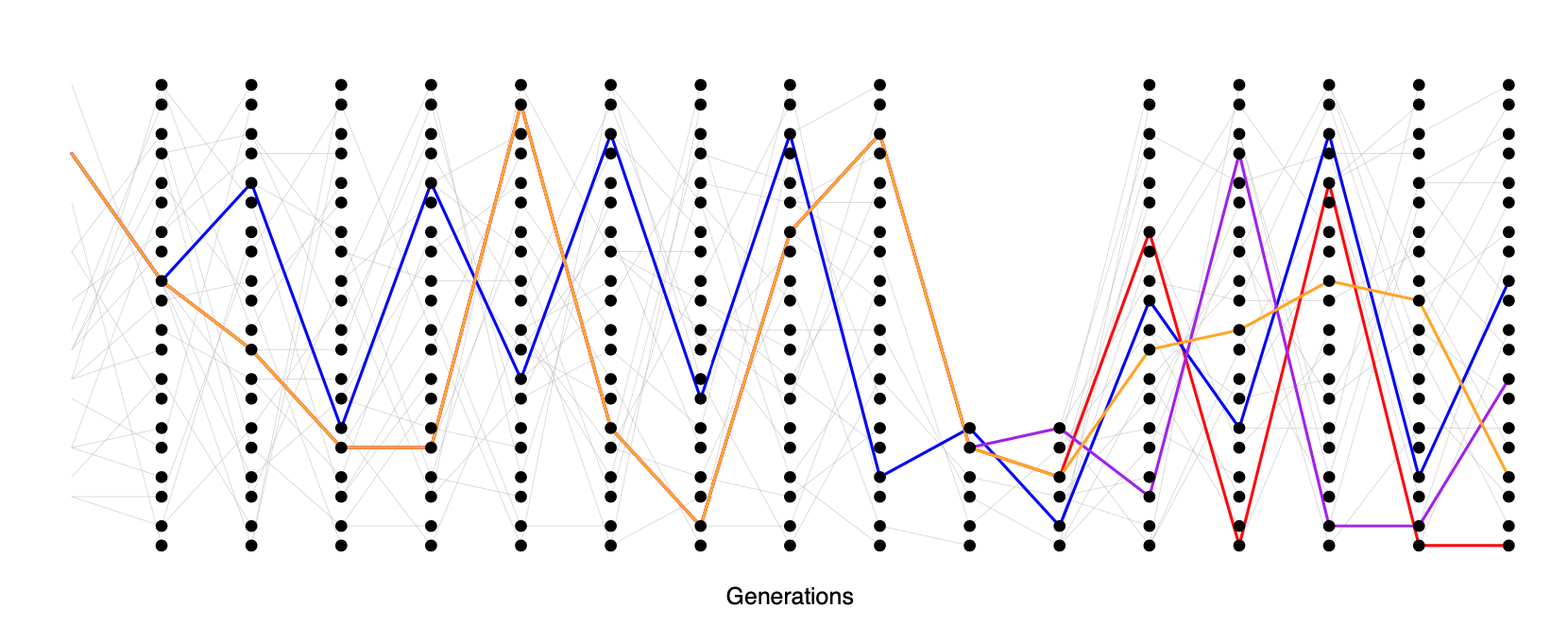
Looking at a sample of lineages drawn from the population today, if the bottleneck was somewhat recent (\(\ll N_{\textrm{Big}}\) generations in the past) many of our lineages will not have coalesced before reaching the bottleneck, moving backward in time. But during the bottleneck our lineages coalesce at a much higher rate, such that many of our lineages will coalesce if the bottleneck lasts long enough (\(\sim N_{\textrm{Small}}\) generations). If the bottleneck is very strong, then all of our lineages will coalesce during the bottleneck, and the resulting site frequency spectrum may look very much like our population growth model (i.e. an excess of rare alleles). However, if some pairs of lineages escape coalescing during the bottleneck, they will coalesce much more deeply in time (e.g. the blue and orange ancestral lineages in Figure \(\PageIndex{23}\)).
An example of this is shown Figure \(\PageIndex{24}\), data from Brandvain et al. (2014). Mimulus nasutus is a selfing species that arose recently from an out-crossing progenitor M. guttatus, and experienced a strong bottleneck. M. guttatus has very high levels of genetic diversity (\(\pi=4\%\) at synonymous sites), but M. nasutus has lost much of this diversity (\(\pi =1\%\)). Looking along the genome, between a pair of M. guttatus chromosomes, levels of diversity are fairly uniformly high.
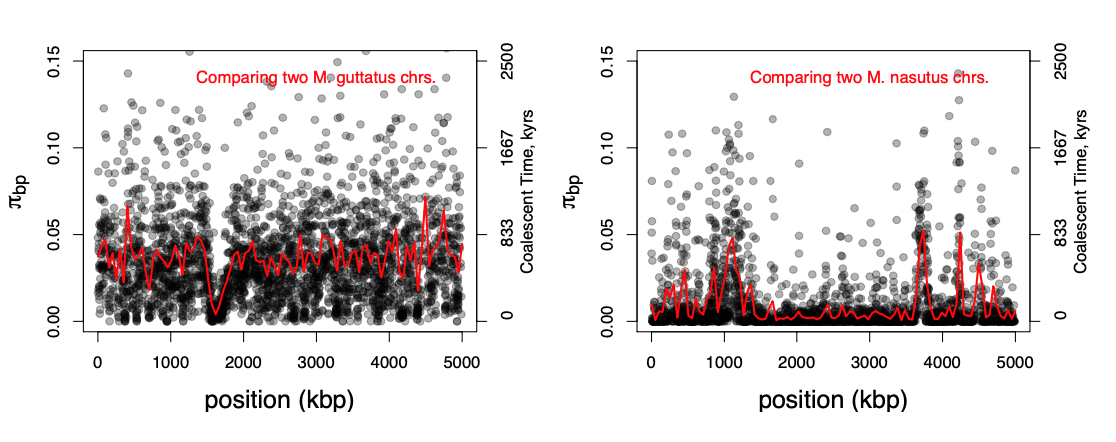
But in comparing two M. nasutus chromosomes, diversity is low because the pair of lineages generally coalesce recently. Yet in a few places we see levels of diversity comparable to M. guttatus; these regions correspond to genomic sites where our pair of lineages fail to coalesce during the bottleneck and subsequently coalesce much more deeply in the ancestral M. guttatus population.

Figure \(\PageIndex{25}\): Yellow Monkeyflower M. guttatus. Choix des plus belles fleurs et des plus beaux fruits. Pierre-Joseph Redouté. (1833). Contributed to Flickr by Swallowtail Garden Seeds. Public Domain.
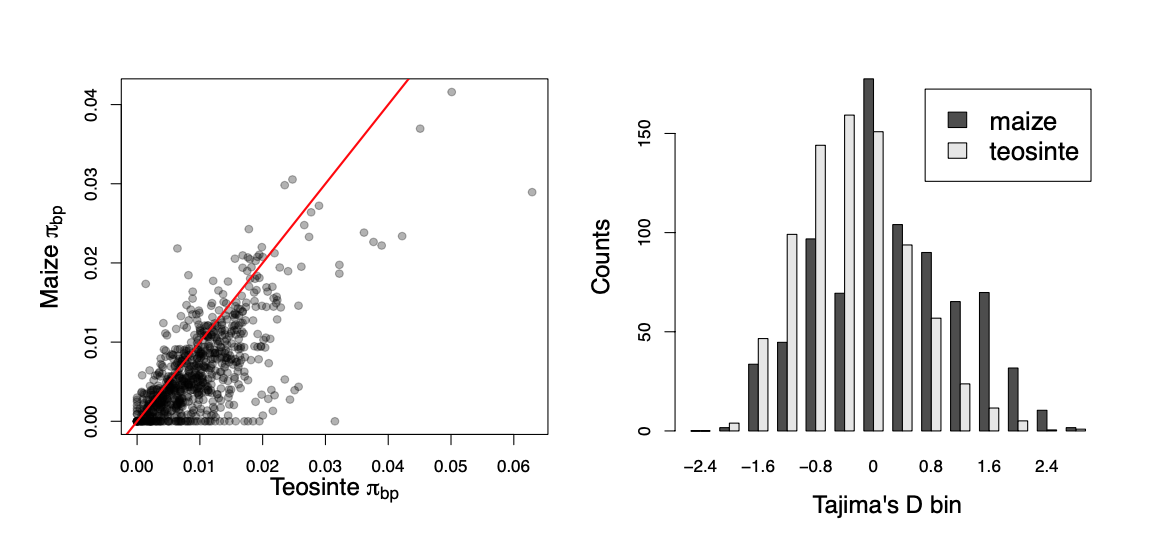
Mutations that arise on deeper lineages will be at intermediate frequency in our sample, and so mild bottlenecks can lead to an excess of intermediate frequency alleles compared to the standard constant-size model. This can skew Tajima’s D (see Equation \ref{eqn_Tajimas_D}) towards positive values and away from its expectation of zero. One example of this skew is shown in Figure \ref{fig:maize_Tajimas_D}. Maize (Zea mays subsp. mays) was domesticated from its wild progenitor teosinte (Zea mays subsp. parviglumis) roughly ten thousand years ago. We can see how the bottleneck associated with domestication has resulted in a loss of genetic diversity in maize compared to teosinte, and the polymorphism that remains is somewhat skewed towards intermediate frequencies resulting in more positive values of Tajima’s D.
Voight et al. (2005) sequenced 40 autosomal regions from 15 diploid samples of Hausa people from Yaounde, Cameroon. The average length of locus they sequenced for each region was \(2365\)bp. They found that the average number of segregating sites per locus was \(S= 11.1\) and the average \(\pi = 0.0011\) per base over the loci. Is Tajima’s D positive or negative? Is a demographic model with a bottleneck or growth more consistent with this result
Summary
- Genetic drift is the random change in allele frequencies due to alleles by chance leaving more or fewer copies of themselves to the next generation. It is directionless, with alleles equally likely to go up or down in frequency thanks to drift. Genetic drift occurs at a slower rate in larger populations as there is a greater degree of averaging in larger populations that reduces the impact of the randomness in individuals’ reproduction.
- On average genetic drift acts to remove genetic diversity (e.g. heterozygosity) from the population. The rate at which neutral genetic diversity is lost from the population is inversely proportional the population size.
- A balance of mutation and genetic drift can maintain an equilibrium level of neutral genetic diversity in a population. This equilibrium level is determined by the population-scaled mutation rate (\(N \mu\)).
- In practice, genetic drift will rarely occur at the rate suggested by the census population size, e.g. due to large variance in reproductive success and short-term population size fluctuations. In many situations, we can address this by using an effective population size in place of the census population size. We can estimate this effective population size by matching our observed rate of genetic drift to that expected in an idealized population.
- A key insight in thinking about patterns of neutral diversity is to realize that neutral mutations do not alter the shape of the genetic tree (or genealogy) relating individuals, and so it is often helpful to think about the tree first and then think of neutral mutations scattered on top of this tree.
- Coalescent theory describes the properties of these trees, and the mutational patterns generated, under a model of neutral evolution.
- Long-term changes in population size alter the rate of coalescence in a predictable way that impacts patterns of variation. These patterns can be used to detect violations of a constant population model and to estimate more complex demographic models.
Based on museum samples from \(\sim 1800\), you estimate that the average heterozygosity in Northern Elephant Seals was \(0.0304\) across many loci. Based on further samples, you estimate that in \(1960\) this had dropped to \(0.011\). Elephant Seals have a generation time of \(8\) years.
What effective population size do you estimate is consistent with this drop?
- Why are large populations expected to harbor more neutral variation?
- What is the effective population size? Is it usually higher or lower than the census population size?
- Why does the effective population size differ across the autosomes, Y chromosome, and mtDNA?
You sequence a genomic region of a species of Baboon. Out of 100 thousand basepairs, on average, 200 differ between each pair of sequences. Assume a per base mutation rate of \(1 \times 10^{-8}\) and a generation time of ten years.
- What is the effective population size of these Baboons?
- What is the average coalescent time (in years) of a pair of sequences in this species?