
8.2: Nucleic Acids - RNA Structure and Function
- Page ID
- 72649


\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)RNA: Structure and Function
Ribonucleic acids are very similar in chemical structure to DNA except they contain ribose instead of deoxyribose. They also have the pyrimidine base uracil instead of thymine, as shown in Figures 1 and 2 above. These two small changes (but mostly the first) confer on it a very different set of biological functions than DNA. This should not surprise us and the basis of all chemistry and biochemistry is that chemical structure determines chemical and biochemical functions and activities. We discussed in the previous section how RNA can adopt complex tertiary structures, which requires the presence of more noncanonical base pairs and chemical modification of bases. In this section we wi,ll explore the plethora of different types of RNA structures and their functions.
The sequence of RNA is made from DNA through a process called transcription (converting the information of DNA, a nucleic acid, into RNA, another nucleic acid). RNA can form double-stranded helices but typically these are viral in origin. DsRNA is a pathogen-associated molecular pattern (PAMP) that binds Toll-like receptor 3 (TLR3) as we saw in Chapter 5.5. If both strands of DNA are transcribed, the resulting strands can anneal form dsRNA. In addition, a single strand of RNA can fold on itself if the 5' and 3' ends are complementary to form a stem-hairpin loop. Figure \(\PageIndex{1}\) shows a stem-loop from a messenger RNA (4QOZ) when it is bound to a specific RNA binding protein (not shown).

Larger ss-RNA can form tertiary structures with many regions of intrastrand hydrogen bonds forming secondary structures, as shown in Figure \(\PageIndex{2}\) for one type of RNA called a transfer RNA
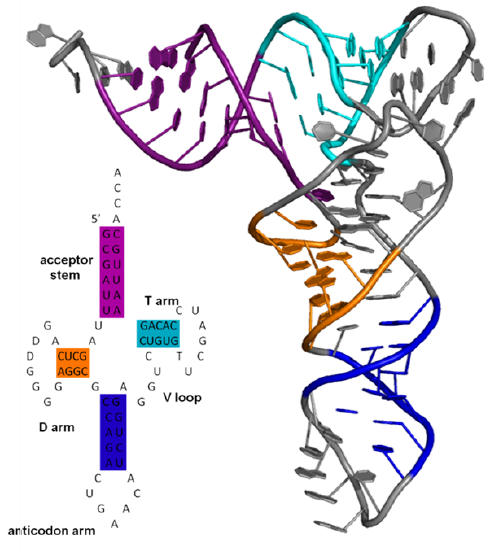
Figure \(\PageIndex{3}\) a computed model for secondary structure within a much larger single RNA molecule S11 that is part of the ribosome. The figure shows color-coded differences in accessibility when the S11 RNA is free (blue) and bound to the protein NSP2 (red), which induces structural rearrangements.

You can imagine that a different set of intrachain H-bonded double-stranded regions could easily form, with the most likely determined by sequence, local environment, and protein binding partners. Each RNA molecule would have a thermodynamic folding landscape similar to protein. Programs are available to determine secondary structures from RNA sequences. Each RNA molecule would have a thermodynamic folding landscape similar to protein. Also, the structures are dynamic as we saw with proteins.
Another feature that makes RNAs complicated is that many different types of RNA are made from DNA using RNA polymerases. They are loosely divided into two types of RNA. One is coding RNA, which contains the sequence information that will be translated into a protein sequence. The other type is called noncoding RNA. These RNAs regulate a myriad of cellular processes including transcription to produce the coding RNA.
Coding RNA
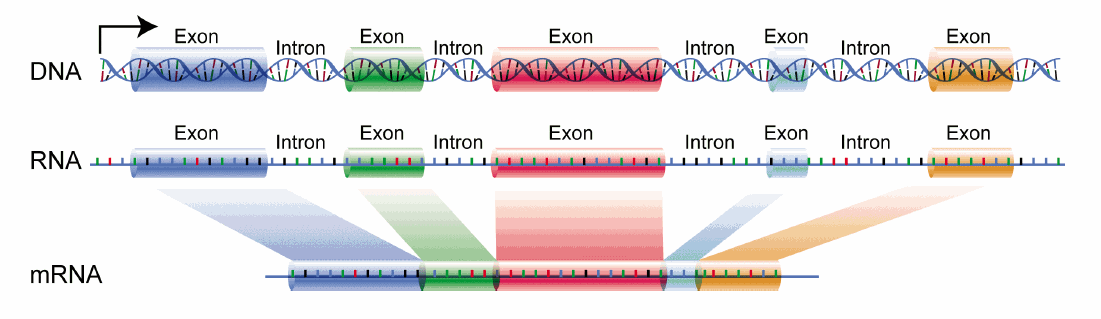
The DNA template from which the coding sequence of a translatable RNA is produced is called a gene. The coding RNA which has the exact sequence that is translated into protein is called messenger RNA (mRNA). The exact sequence of RNA in mRNA that encodes a protein is derived from a longer contiguous DNA sequence in the nucleus from which sections called intervening sequences or introns have been removed. The coding sequences of DNA which are separated by introns are called exons. When coding DNA is transcribed, a long contiguous sequence containing both exons and introns is transcribed into one long primary transcript called heteronuclear RNA. The introns in the heteronuclear RNA are removed, in a splicing reaction catalyzed by a large complex called the spliceosome to form mRNA. The process is illustrated in Figure \(\PageIndex{4}\). The first RNA sequence made is the heteronuclear RNA.
The long single stranded mRNA molecule binds to ribosomes, nanomachines which orchestrate the translation of the mRNA sequence into a protein sequence. There are around 20,000 human genes that produce an even large number of mRNA that arise from differential splicing of the primary transcript.
Noncoding RNA (ncRNA)
Not long ago, few thought about possible RNA transcripts from non protein-coding regions of the genome, except for two types of RNA required for the translation of mRNA. These two are ribosomal RNAs (rRNA) which are found in ribosomes and transfer RNAs, to which amino acids are esterified and transferred to a growing protein chain of the ribosome. Many more classes have been discovered and given names that are quite confusing to someone more vind with protein structures. One way to classify noncoding RNAs (ncRNAs), which implies non-protein coding RNAs is based on size.
- short noncoding RNAs (sncRNAs) are <200 nucleotides
- long noncoding RNAs (lncRNAs)are >200 nucleotides
These function to regulate gene expression at both the transcription and post-transcriptional levels. Some have catalytic functions. Some affect chromosome structure and chemical modification.
Long Noncoding RNAs (lncRNAs)
There many be between 16,000 to over 100,000 human lncRNAs encoded into the genome which adds much complexity to our understanding of the function of RNA transcripts. An online lncipedia is a database of searchable lncRNA sequences. There are many types of lncRNAs. The first we will consider is ribosomal RNA.
a. Ribosomal RNA (rRNA):
These RNAs fit the simple definition of lnRNAs (>200 nucleotides and are not protein- ing), but most would not think of them as lncRNAs since they have always been in their own category of a nonprotein-coding gene. rRNAs vary in length from between 1500 and 3000 nucleotides long in bacteria and about 1800 and 5000 nucleotides long in humans and are the core structure of ribosomes, the nanomachines which translate bound mRNA into a protein sequence.
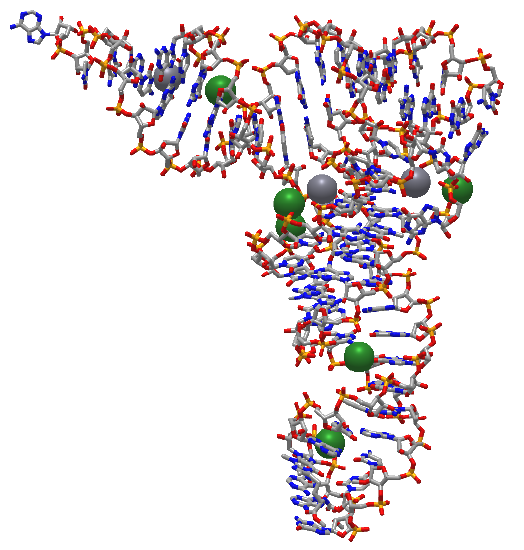
Figure \(\PageIndex{5}\) shows an interactive iCn3D model of the structure of 23S rRNA of the large ribosomal subunit from Deinococcus radiodurans (2O44) (long load time).
.png?revision=1&size=bestfit&width=348&height=287)
The red (highlighted yellow) spacefill is the 5' start of the rRNA. The chain has a complex tertiary structure, much like a protein sequence, and ends at the cyan spacefilling 3' end. It has 2880 nucleotides.
Let's focus on more classical examples of long noncoding RNAs (i.e not rRNA). One way to categorize them is based on the position in the genome that encodes them. The different types include long intergenic noncoding RNAs (lincRNA), intronic lncRNAs, antisense RNAs (as lncRNAs) and other variants. These are illustrated in Figure \(\PageIndex{6}\), where the lncRNA is shown in pink.
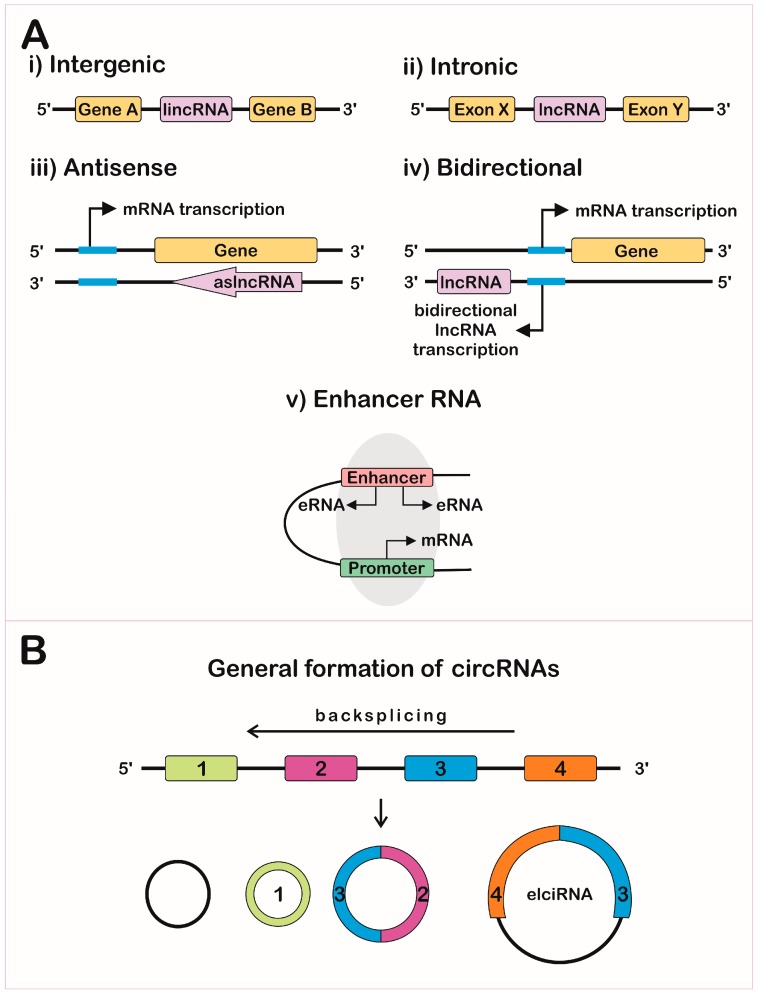
Another variant is exon and intron-containing circRNAs (EIciRNAs) as illustrated in panel B in Figure \(\PageIndex{13}\). These are presumably produced from pre-mRNA for a given mRNA, and appear to regulate gene expression through RNA-RNA interactions with U1 snRNA, which starts the assembly of the spliceosome on pre-mRNA when it binds to the 5′ pre-mRNA splice site.
Now let's consider more typical examples of long non-coding RNAs (lncRNAs), which are often bound to target proteins.
b. mamRNA (a lnc RNA)
The lncRNA named mamRNA (Mmi1 and Mei2-associated RNA) binds two proteins, Mmi1 and Mei2 in Schizosaccharomyces pombe that control the balane between meisois and mitosis in yeast. (Schizosaccharomyces pombe is a "fission" yeast that divides by fission and not budding.) The MamRNA has two variants of length 550 and 700 nucleotides. Binding of mamRNA leads to the ubiquitinylation of the Mei2 in the complex. Mmi1 R is an RNA-binding protein that binds to a modified version of adenosine that has been methylated at N6 and is found internally in mRNA. Mei2 (meiosis protein 2) is necessary of meiosis. The binding of mamRNA leads to the ubiquitinylation of the Mei2 in the complex, targeting it for proteolysis. Mei2 concentrations relatively increase, shifting yeast from mitosis to meiosis. Figure \(\PageIndex{7}\) shows a cartoon depicting these interactions.

Figure \(\PageIndex{8}\) shows an interactive iCn3D model of the S. pombe Mei2 RRM3 protein domain bound to the Mei2 binding "domain" of mamRNA (6YYM) which in this structure is only 8 nucleotides long (not the full length this lncRNA which is 550 and 700 nucleotides long).
c. ToxI - a lnRNA inhibitor of the endonuclease ToxN
Those with a more chemistry-centric background might be surprised to know that viruses also "infect" bacteria. These viruses are called bacteriophages. It is estimated that there are over 1030 in nature. Some covalently incorporate into genomes where they reside and are incorporated permanently into the genome. They are a main driver of bacterial genome evolution as they shape the bacteria's immune response and adaptation.
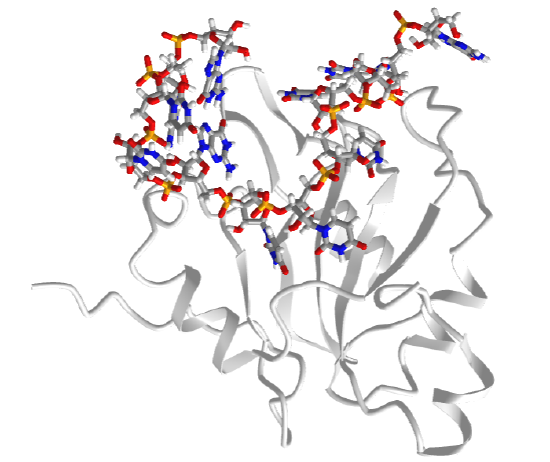
One very interesting example is the type III toxin-antitoxin (TA) system in E. Coli. It consists of a toxin, ToxN, which is a nuclease that cleaves internally after the second A in a AAA sequence. It acts on mRNA but especially pre-mRNA sequences. It is inhibited by the binding of a lncRNA called ToxI (toxin inhibitor). The RNA sequence of the ToxI inhibitor has 36 "domain" repeats of a pseudoknot, one of which is sufficient to inhibit the ToxN. The ToxN endonuclease cleaves the ToxI lncRNA as it assembles the complex. It also cleaves its mRNA. Figure \(\PageIndex{9}\) shows an interactive iCn3D model of the protein toxin (ToxN):lncRNA (ToxI) which is a shortened version of 29 nucleotide section from Pectobacterium atrosepticum (2xdb).
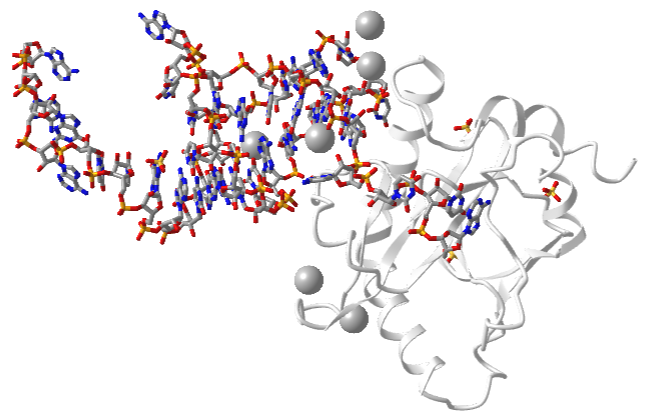_LncRNAantitoxin_(ToxI))_complex_(2xdb).png?revision=1&size=bestfit&width=498&height=318)
Short Noncoding RNA
Short noncoding RNAs (sncRNAs) are less than 200 nucleotides in length. By definition, this would include transfer RNAs (tRNAs) which bring to the ribosome amino acids covalently attached to their 3' end for incorporation into a growing protein chain during the translation of mRNA. As with rRNA for lncRNAs, these are really in a class of their own. Others include small nuclear RNAs (snRNAs) involved in splicing, small nucleolar RNAs (snoRNAs) involved in the modification of rRNAs, and microRNAs (miRNAs), involved in the inhibition of translation and transcription, PIWI-interacting RNAs (piRNAs), and endogenous small interfering RNAs (siRNAs). It is difficult to remember the subtle difference among these, which makes them a bit difficult to understand. We will tell their stories with a few targeted examples.
a. Transfer RNA:
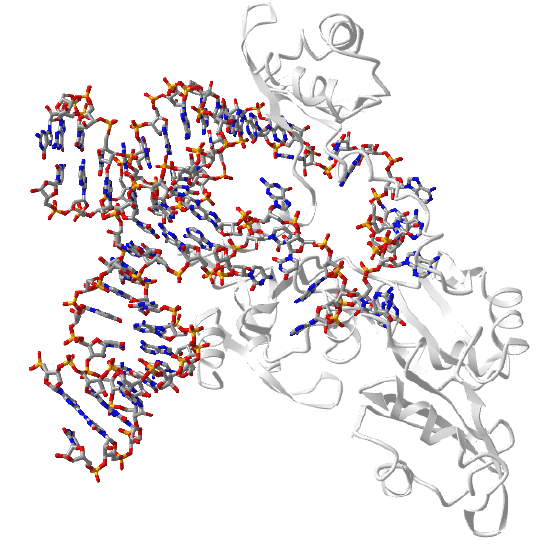
Transfer RNAs act as adapter molecules between transcription and translation. They are between 76 and 90 nucleotides long and have a cloverleaf shape. An enzyme, aminoacyl-tRNA synthase, covalently attaches a select amino acid at its 3' end. Another end of the tRNA hydrogen bonds through 3 nucleotides (the anticodon) to a triplet nucleotide (the codon) on the mRNA that encodes a specific amino acid at that triplet position. Figure \(\PageIndex{10}\) shows an interactive iCn3D model of the structure of yeast phenylalanine tRNA (1EHZ)
b. Small nuclear RNA (snRNA):
The spliceosome is a nanoparticle that catalyzes the removal of introns from pre-mRNA in eukaryotes (prokaryotes appear devoid of introns). The yeast spliceosome has a molecular weight of 1.3 million and contains 5 small ribonucleoproteins (RNPs) with many other associated proteins. Each of the 5 RNPs has a small nuclear RNA (U1, U2, U4, U5 and U,6) which is enriched in uracils. U6 is highly conserved and is directly involved in catalysis. Figure \(\PageIndex{11}\) shows an interactive iCn3D model of the core structure of the U6 small nuclear ribonucleoprotein complex with most of the U6 RNA bound.
c. MicroRNAs (miRNAs) and small inhibitory RNAs (siRNAs)
MicroRNAs (miRNAs) control the expression of thousands of genes in plants and animals. They are single-stranded but fold on themselves to form a stem-hairpin. The miRBase is a microRNA database containing almost 40,000 miRNA sequences. miRNAs are highly conserved and are found in animals, plants, and some unicellular eukaryotes. They interact with the 3′ untranslated regions of mRNAs and inhibit or prevent their translation. Several key proteins, RNA polymerase II, Drosha and Dicer are involved in the canonical pathway while the others appear to be independent of Drosha, which is a ribonuclease III double-stranded (ds) RNA endoribonuclease.
Dicer is a dsRNA) endoribonuclease which cleaves long dsRNAs and short hairpin pre-microRNAs (miRNA) into fragments of either 21-23 nucleotides (short interfering RNA) or 19-25 nucleotides (microRNAs). Each has two nucleotides that are unpaired at the 3' end. These bind to the enzyme complex RISC ( RNA-induced silencing complex) whicn then targets the to mRNA complementary to the siRNA/miRNA (RISC) causing cleavage of the mRNA and hence inhibiting translation.
Small inhibitory RNAs (siRNAs) are very similar to miRNA (to the point that differentiating between them is somewhat arbitrary). They both engage in RNA interference (RNAi) of mRNA translation. Here some reported differences:
- The substrate for dicer cleavage is dsRNA (that could be added exogenously) of length 30-100+ for siRNA but the actual pre-miRNA of length 7-100 nucleotides that may contain hairpins with some mismatches (i.e. not a perfect stem and hairpin)
- The final RNA after dicer processing is double-stranded for both and 21-23 nucleotides long for siRNA and 19-25 for miRNA
- siRNAs are perfectly complementary to the target mRNAs while miRNAs, which are not necessarily perfectly complementary, bind typically to the 3' untranslated end of the mRNA
- Because of the perfect complementarity to target mRNA, siRNA interact with only one mRNA while miRNAs, given that they are not perfectly complementary to their target sequences, can bind different mRNAs
- Given their higher affinity binding, the siRNA leads to dicer endonuclease cleavage of the target mRNA while inhibition of mRNA translation by miRNAs arises from binding of the miRNA to the mRNA or, if the match between the miRNA and mRNA is high enough, endonuclease cleavage of the mRNA.
Figure \(\PageIndex{12}\) shows a canonical and several alternative pathways for their transcription and processing from the noncoding miRNA genes.

Figure 1. Canonical and non-canonical pathways of microRNA biogenesis. (A) Canonical pathway—microRNA gene is transcribed by RNA polymerase II into primary microRNA (pri-miRNA), cleaved by microprocessor complex Drosha/DGCR8, and precursor microRNA (pre-miRNA) is exported from the nucleus to the cytoplasm by Exportin 5 (XPO5) and further processed by Dicer and its partners into 18–25 nucleotide long microRNA duplex with 2-nucleotide 30 overhangs. The guide strand is subsequently bound by the Argonaute proteins 1-4 (AGO1-4) and retained in the microRNA-induced silencing complex to target mRNAs for post-transcriptional silencing. (B) Mirtrons—generated through mRNA splicing independently of Drosha-mediated processing step. (C) Small nucleolar RNA-derived microRNAs—Drosha-independent pathway. (D) Exportin 5-independent transport of pre-miRNAs from the nucleus to the cytoplasm has been described in the case of miR-320 family. (E) Dicer-independent processing of miR-451—pre-miR-451 is directly loaded into AGO2, cleaved and trimmed by poly(A)-specific ribonuclease PARN to produce mature miR-451. Gregorova et al. Cancers 2021, 13, 1333. https://doi.org/10.3390/cancers13061333. Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/)
siRNA that are perfect matches to specific mRNA can be easily designed and purchased for translation inhibition and through that gene silencing studies. Both miRNAs and siRNA are potentially therapeutic as it is much simpler to design a drug that targets a mRNA sequence (a 1D sequence target) than a protein active site (a 3D target). Additionally, they can be used to inhibit protein synthesis of target proteins that don't have a "druggable" active site.
The protein Argonaute is involved in miRNA and siRNA silencing of genes through their mRNAs in the RISC ( RNA-induced silencing complex). RISC contains the protein argonaute 2 (AGO2) bound to a "guide" RNA which is either microRNA (miRNA) or short interfering RNA (siRNA). It is the miRNA or siRNA that directly interacts with the "target" - the mRNA.
Example miRNA:
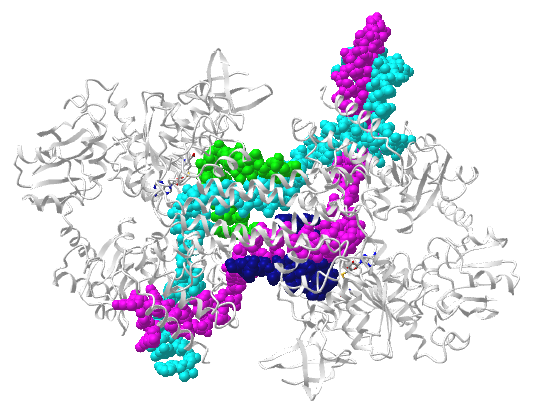
Figure \(\PageIndex{13}\) shows an interactive iCn3D model of human Argonaute2 Bound to a Guide (miRNA) and Target RNA (4W5O). The two RNA sequences are 5' UUCACAUUGCCCAAGUCUUU 3' and 5' CAAUGUGAAA 3'.
.png?revision=1&size=bestfit&width=379&height=322)
Example: siRNA (Small interfering RNA)
Virus genomes are ultimately decoded into new viruses by the host replication, transcription and translation machinery. Host cells have evolved ways to silence mRNAs from viruses. Unfortunately, viruses, in response, evolve ways to suppress host RNA silencing. Many viral proteins are used to suppress silencing by the host. One is the viral p19 protein, which preferentially binds to host short interfering RNAs (siRNAs) than to microRNAs (miRNAs). A single mutation in the viral p19 proteins changes selectivity which allows it to bind to a specific human miRNA called miR-122. This shows the subtle complexities of protein:RNA interactions. Figure \(\PageIndex{14}\) shows an interactive iCn3D model of the viral suppressor of RNA silencing protein and a 21 residue small interfering RNAs (6BJV)
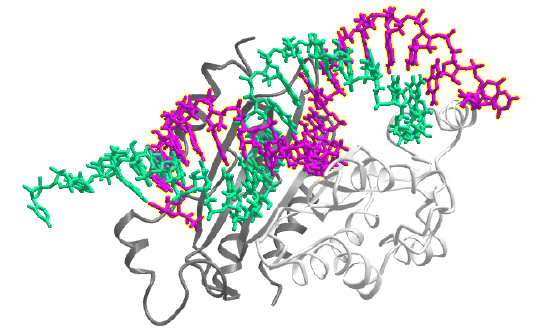
Example: piRNA (a specific miRNA)
Piwi proteins are RNA-binding proteins in plants and animals and are similar in structure to argonaute. They bind a guide RNA called piwi-interacting RNAs (piRNAs) and lead to the silencing of sequences in the genome called transposable elements that can move around the genome. piWi has endonuclease activity and can cleave mRNA. The piRNAs are just one type of miRNA. Figure \(\PageIndex{15}\) shows an interactive iCn3D model of Ephydatia fluviatilis (a sponge) PiwiA with a guide (piRNA) and-target RNA(7KX9)
.png?revision=1&size=bestfit&width=400&height=328)
After the decoding of the human genome, many have been struggling to understand how the complexity of the human brain (large size, greater connectivity among neurons) arises given that we appear to have only around 20,000 proteins genes encoded by the genome (not counting small proteins of less than 100 amino acids). Long noncoding RNAs (lncRNAs) and miRNAs appear to be significant pieces of this puzzle. Their ability to regulate transcription during development may hold the key. Additional roles on these RNAs outside of transcriptional regulation are being discovered. Some are transported away from the nucleus to serve other functions in axons, dendrites, etc. For example, the lncRNA Gm38257 binds to proteins that structure the synapse.
something rather unexpected: Instead of simply regulating gene expression, it binds to proteins
The repertoire of miRNA appears to be significantly increased in "intelligent" organisms such as humans and octopi. For example, a large increase (179) in miRNAs occurs in proceeding in the evolutionary scale from mice (which have about 24,000 protein-encoding genes) to humans (around 20,000). miRNAs and lncRNAs may be involved (causative or correlative?) with brain disease. An example is the miR-124 is significantly elevated (3.5X) times higher in hippocampal cells from mouse models of Alzheimer's compared to normal mice. Altered expression of the lncRNA named Gomafu, RNCR2 or MIAT) appears to affect certain psychiatric diseases.
f. small nucleolar RNA
The nucleolus is a small structure in the nucleus that helps assemble the ribosomal RNAs that are synthesized in the nucleus. They then are transported through the nuclear membrane into the cytoplasm where they combine with proteins translated from mRNA in the cytoplasm to form complete ribosomes. As we will describe below, rRNA is chemically modified by enzymes (much like the post-translational modification of proteins). One such modification is 2'-O-methylation in archaea and eukaryotes. A class of small nucleolar RNAs (snoRNAs) which vary from 10-21 base pairs are called C/D RNAs, and they "guide" the modification. Hence they are also called "guide" RNAs. These snoRNAs bind to 3-4 proteins into ribonucleoproteins. Figure \(\PageIndex{16}\) shows an interactive iCn3D model of the box C/D ribonucleoprotein 40 nt snoRNA "guide" and a 10 nucleotide RNA target substrates. It appears that the maximal duplex RNA formed (from the guide and target) is 10 base pairs long.
References
Börner, R., Kowerko, D., Miserachs, H.G., Shaffer, M., and Sigel, R.K.O. (2016) Metal ion induced heterogeneity in RNA folding studied by smFRET. Coordination Chemistry Reviews 327 DOI: 10.1016/j.ccr.2016.06.002 Available at: https://www.researchgate.net/publication/303846502_Metal_ion_induced_heterogeneity_in_RNA_folding_studied_by_smFRET
Hardison, R. (2019) B-Form, A-Form, and Z-Form of DNA. Chapter in: R. Hardison’s Working with Molecular Genetics. Published by LibreTexts. Available at: https://bio.libretexts.org/Bookshelves/Genetics/Book%3A_Working_with_Molecular_Genetics_(Hardison)/Unit_I%3A_Genes%2C_Nucleic_Acids%2C_Genomes_and_Chromosomes/2%3A_Structures_of_Nucleic_Acids/2.5%3A_B-Form%2C_A-Form%2C_and_Z-Form_of_DNA
Lenglet, G., David-Cordonnier, M-H., (2010) DNA-destabilizing agents as an alternative approach for targeting DNA: Mechanisms of action and cellular consequences. Journal of Nucleic Acids 2010, Article ID: 290935, DOI: 10.4061/2010/290935 Available at: https://www.hindawi.com/journals/jna/2010/290935/
Mechanobiology Institute (2018) What are chromosomes and chromosome territories? Produced by the National University of Singapore. Available at: https://www.mechanobio.info/genome-regulation/what-are-chromosomes-and-chromosome-territories/
National Human Genome Research Institute (2019) The Human Genome Project. National Institutes of Health. Available at: https://www.genome.gov/human-genome-project
Wikipedia contributors. (2019, July 8). DNA. In Wikipedia, The Free Encyclopedia. Retrieved 02:41, July 22, 2019, from https://en.Wikipedia.org/w/index.php?title=DNA&oldid=905364161
Wikipedia contributors. (2019, July 22). Chromosome. In Wikipedia, The Free Encyclopedia. Retrieved 15:18, July 23, 2019, from en.Wikipedia.org/w/index.php?title=Chromosome&oldid=907355235
Wikilectures. Prokaryotic Chromosomes (2017) In MediaWiki, Available at: https://www.wikilectures.eu/w/Prokaryotic_Chromosomes
Wikipedia contributors. (2019, May 15). DNA supercoil. In Wikipedia, The Free Encyclopedia. Retrieved 19:40, July 25, 2019, from en.Wikipedia.org/w/index.php?title=DNA_supercoil&oldid=897160342
Wikipedia contributors. (2019, July 23). Histone. In Wikipedia, The Free Encyclopedia. Retrieved 16:19, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Histone&oldid=907472227
Wikipedia contributors. (2019, July 17). Nucleosome. In Wikipedia, The Free Encyclopedia. Retrieved 17:17, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Nucleosome&oldid=906654745
Wikipedia contributors. (2019, July 26). Human genome. In Wikipedia, The Free Encyclopedia. Retrieved 06:12, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Human_genome&oldid=908031878
Wikipedia contributors. (2019, July 19). Gene structure. In Wikipedia, The Free Encyclopedia. Retrieved 06:16, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Gene_structure&oldid=906938498