
3.3: Proteins - Analyses and Structural Predictions of Protein Structure
- Page ID
- 47023


Introduction
In the last chapter section, we discussed how to purify a protein (mostly through differential salt precipitation and column chromatography) and follow the purity of a protein (mostly through various types of electrophoresis) during the process. Now we want to continue with the analysis of a "pure" protein, so we can understand it structure and the function conferred by that structure. We need many pieces of information to study protein structure/function relationships. Some are "low resolution" characteristics such as knowing the concentration of a protein. At the highest "resolution" end, we would like to know the 3D structure of a protein with a specific interacting ligand bound to a specific site on the protein. Our goal is then to understand proteins at varying levels of complexity or "resolution", some of which are illustrated in Figure \(\PageIndex{1}\).

A variety of chemical and spectra analysis techniques are used to achieve the specified level of structural elucidation. Spectral techniques can give us information on concentration (UV absorbance, fluorescence) and secondary structure (CD spectroscopy). Chemical analyses and mass spectroscopy give information on the amino acid composition and/or sequence. More sophistical techniques (x-ray crystallography, cryoelectron microscopy, NMR spectroscopy) can give us 3D structural information. Each of the analyses shown in the figure above will be summarized below. For some, for which readers might have less experience, more details will be offered.
Sequencing the cDNA can, of course, give you some of the information (amino acid composition, N- and C-terminal amino acids, and the primary structure (omitted from the figure above). Even DNA sequencing won't give information on post-translational modification and other covalent processing (limited proteolysis, disulfide bond formation) that some of the methods below would.
We will explore some commonly used methods for protein analysis in this section. In previous sections, we learned about the charge and chemical reactivity properties of isolated amino acids and amino acids in proteins. The analysis of a whole protein is complicated since each different amino acid might be represented many times in the sequence. Each protein has an N-terminal and C-terminal amino acid and secondary structure. Some proteins exist biologically as multisubunit proteins, which adds to the complexity of the analyses since now the proteins would have multiple N- and C-terminal ends. In addition, isolated proteins might have chemical modifications (post-translational) which add to the functionalities of the proteins but also add to the complexities of the analyses.
Spectral techniques are widely used to give information on concentration (UV absorbance, fluorescence) and secondary structure (CD spectroscopy). Chemical analyses and mass spectroscopy give information on the amino acid composition and/or sequence. More sophistical techniques (x-ray crystallography, cryoelectron microscopy, NMR spectroscopy) can give us 3D structural information. More complete descriptions for two techniques, fluorescence spectroscopy, and mass spectrometry, are presented as their uses in the analyses of biomacromolecules are underrepresented in curriculums as their use in actual laboratories becomes so prevalent.
Low-Resolution Analyzes
Protein Concentration
There are multiple ways to determine protein concentrations in samples. Other components of a protein solution may interfere with the assays so the choice of methods has to be carefully determined.
1. Direct mass determination. A known, accurate amount of a dried protein is added to a solution of specific ionic strength and composition. The absorbance at a specific wavelength (usually 280 nm) is determined, which is used to determine an extinction coefficient at that wavelength (ε1% = absorbance of a 1% protein solution = 1g protein/100 ml solution). If the molecular weight of the protein is known through sequence analysis, then a molar absorptivity can be determined. The concentration of the same protein in an unknown, pure solution of the protein can then be determined. There are several problems with this technique. It requires relatively large amounts of protein to make accurate measurements. An even more difficult problem is that proteins bind not only water but counter-ions. Even a freeze-dried protein (a protein which has been frozen at -600C and placed in a vacuum, which causes sublimation of water and volatile salts in the solution) has probably 10% by weight of bound water (water of hydration).
2. Quantitative amino acid analysis. The protein is hydrolyzed completely to amino acids with 6N HCl. The amino acids are then separated by high-performance liquid chromatography. As amino acids elute from the column, they are reacted with a fluorescent reagent such as ninhydrin, fluorescamine, on orthopthaldehdye (OPA) to produce a fluorescent-amino acid conjugate. The fluorescence intensity of the conjugates is proportional to the concentration of the amino acids in the protein. Before hydrolysis, a known quantity of an amino acid not present in proteins (norleucine, beta-alanine) is added and its recovery is determined at the end of the hydrolysis and fluorescence conjugation to normalize the recovery of the other amino acids. Several problems are encountered using this technique. Incomplete peptide bond hydrolysis, and partial or complete destruction of serine, threonine, tryptophan, and tyrosine occur during the acid hydrolysis. The OH-containing amino acids can be determined by quantitating these amino acids after several different time intervals of hydrolysis, and extrapolating the concentrations back to zero time. Incomplete reactions with the detecting reagent can also occur.
The most widely used and perhaps less analytically accurate than the two above are indirect, comparative protein assays based on the chemical properties of amide bonds or the spectrophotometric properties of the side chains Trp, Tyr, Phe. Unknown concentrations can be determined from a standard curve derived from performing the same reactions or spectrophotometric measurements on a series of solutions of known protein concentration. Below is a discussion of each of these techniques.
3. Modified Lowry protein determination. The Lowry Method is actually a modification of the biuret method, whose basis is described below. It is much more sensitive, however. Biuret, as its name implies, derives from the combination of two molecules of urea (bi-ur-et) as shown in the figure (panel A) below. If copper sulfate is added to Biuret in a concentrated hydroxide solution, a violet color results. An illustration of the copper (II) complex with biuret is shown in panel B of the figure. This biuret reaction also arises in the presence of any compound with three or more peptide bonds. Compare in Figure \(\PageIndex{2}\) the structure of Biuret and a polypeptide (Panel A).

4. Dye binding assay (Bradford method). This method is based on the binding of the dye Coomassie Brilliant Blue G-250 to protein, with a resultant change in the absorbance properties of the dye. The structure of the dye is shown in Figure \(\PageIndex{3}\).

The magnitude of the difference spectra at 595 nm is directly proportional to the protein concentration. The dye in the unbound, free state, has an absorbance maximum at 465 nm. The method was initially developed by Bradford (Analytic Biochemistry, 72, 1976), and is available commercially. The dye appears to bind to proteins through both hydrophobic interactions and electrostatic ones through a sulfonic acid group on the dye. The predominant advantage of this method is that its cheap, simple, rapid, 3x more sensitive than the modified Lowry method, and subjected to fewer interferences by other compounds. The color fully develops in about 5 minutes but decreases within 10-15 minutes when the proteins start to precipitate. Precipitation occurs more extensively at higher protein concentrations. Hence, the high-concentration standards will be affected more than the low-concentration standards.
5. Bicinchoninic Acid method (BCA). This method is based on the reduction of Cu++ to Cu+ by the peptide bond, and the chelation of the Cu+ by BCA, which is monitored by absorbance at 562 nm. This method, which has been commercialized, is subject to fewer interferences from other compounds than either the modified Lowry or the dye binding assay. Two solutions are required, a BCA solution and a copper sulfate solution. The two are mixed together to form an apple-green working solution. When protein is added, the resulting Cu+ chelates with 2 molecules of BCA as shown in Figure \(\PageIndex{4}\).

Figure \(\PageIndex{4}\): BCA analysis for protein quantitation
This results in a purple color, which can be monitored spectrophotometrically at 562 nm. An absorbance at 562 nm of 0.012 per microgram of protein added to the working reagent gives this technique high sensitivity.
6. Absorbance A280 or ratios at different wavelengths. This method is based on the fact that the three aromatic acids (Tyr, Phe, Trp) have significant absorbances in the UV. The absorption spectra of the three amino acids as a function of wavelength are shown in Figure \(\PageIndex{5}\). Note the log scale on the y-axis.

When separating proteins on chromatography columns, the absorbance at 280 nm of the elute is often measured in isolated fractions or continuously as a measure of the presence and concentrations of the eluting proteins.
The absorbance at 280 nm is often used to estimate the total concentration of proteins (an average protein at a concentration of 1 mg/ml has an A280 of about 1). However, only two amino acids absorb significantly at this wavelength, and since proteins have a variable number of these amino acids, this measurement can only be an estimate of the protein concentration of an unknown protein.
The Beer-Lambert law shows that the absorbance of a chromophore in solution is given by
\begin{equation}
\mathrm{A}=\epsilon \mathrm{l} \mathrm{c}
\end{equation}
where A is the absorbance at a given wavelength, ε is the molar absorptivity, l is the path length of the cuvette and c is the concentration (mol/L). Pace et al have shown that based on over a hundred measurements on 61 proteins in aqueous solution, the ε(280), the molar absorptivity at 280 nm, is given by this empirical equation:
\begin{equation}
\epsilon(280)\left(\mathrm{M}^{-1} \mathrm{~cm}^{-1}\right)=(\# \operatorname{Trp})(5,500)+(\# \mathrm{Tyr})(1,490)+(\# \text { cystine })(125)
\end{equation}
Proteins also absorb strongly at wavelengths less than 240 nm. This part of the absorption spectra arises from the above-mentioned amino acids along with contributions from His, Met, Cys, and the peptide bond. At these wavelengths, the absorbance is less dependent on the actual amino acid composition of the protein, but it becomes increasingly susceptible to interfering substances. Contaminating nucleic acids, which absorb maximally at 260 nm, also contribute to the absorbance at 280 nm. Hence the A280/A260 ratio can be determined and through appropriate calculations, the contribution of nucleic acids can be removed. Optimal reliability is obtained by measuring A280/A205 values, since at 205 nm, a large fraction of the absorbance is derived from the peptide bond. pH changes have little effect on the absorbance of the peptide bond but has a much larger effect on Tyr. At high pH's, the side change hydroxyl is deprotonated (pKa = 10.5), with concomitant changes in the A295. These changes can be used to follow the titration of the Tyr residues in a protein.
Molecular Weight
Molecular weights can be estimated by hydrodynamic techniques including size exclusion chromatography (under denaturing conditions using standards of known molecule weight), ultracentrifugation, and dynamic light scattering. In addition, they can be determined by polyacrylamide gel electrophoresis, again under denaturing conditions using standards. More precisely they could be determined through protein sequence or more easily through cDNA sequence analyses. The most accurate method for smaller proteins is mass spectrometry, as described in below.
Specific Amino Acids
Aromatic amino acids can be detected by their characteristic absorbance profiles. Amino acids with specific functional groups can be determined by chemical reactions with specific modifying groups, as shown in a previous section.
Amino Acid Composition
At a low level of resolution, we can determine the amino acid composition of the protein by hydrolyzing the protein in 6 N HCl, 100oC, under vacuum for various time intervals. After removing the HCl, the hydrolysate is applied to an ion exchange or hydrophobic interaction column, and the amino acids are eluted and quantitated with respect to known standards. A non naturally- occurring amino acid, like norleucine, is added in known amounts as an internal standard to monitor quantitative recovery during the reactions. The separated amino acids are often derivatized with ninhydrin or phenylisothiocyantate to facilitate their detection. The reaction is usually allowed to proceed for 24, 36, and 48 hours since amino acids with OH (like ser) are destroyed. A time course allows the concentration of Ser at time t=0 to be extrapolated. Trp is also destroyed during the process. In addition, the amide links in the side chains of Gln and Asn are hydrolyzed to form Glu and Asp, respectively.
N- and C-Terminal Amino Acid Analysis
The amino acid composition does not give the sequence of the protein. The N-terminus of the protein can be determined by reacting the protein with fluorodinitrobenzene (FDNB) or dansyl chloride, which reacts with any free amine in the protein, including the epsilon amino group of lysine. The amino group of the protein is linked to the aromatic ring of the dinitrobenzene through an amine and to the dansyl group by a sulfonamide, and are hence stable to hydrolysis. The protein is hydrolyzed in 6 N HCl, and the amino acids are separated by TLC or HPLC. Two spots should result if the protein was a single chain, with some Lys residues. The labeled amino acid other than Lys is the N-terminal amino acid. The C-terminal amino acid can be determined by the addition of carboxypeptidases, enzymes which cleave amino acids from the C-terminal. A time course must be done to see which amino acid is released first. N-terminal analysis can also be done as part of sequencing the entire protein as discussed using Edman degradation.
Primary Sequence
Protein Sequencing using Edman Degradation
Edman degradation, developed by Pehr Edman, is a method of sequencing amino acids in a peptide. In this method, the amino-terminal residue is labeled and cleaved from the peptide without disrupting the peptide bonds between other amino acid residues. The reaction is shown in Figure \(\PageIndex{6}\).

Phenyl isothiocyanate is reacted with an uncharged N-terminal amino group, under mildly alkaline conditions, to form a cyclical phenylthiocarbamoyl derivative. Then, under acidic conditions, this derivative of the terminal amino acid is cleaved as a thiazolinone derivative. The thiazolinone amino acid is then selectively extracted into an organic solvent and treated with acid to form the more stable phenylthiohydantoin (PTH)- amino acid derivative that can be identified by using chromatography or electrophoresis. This procedure can then be repeated again to identify the next amino acid.
A major drawback to Edman degradation is that the peptides being sequenced in this manner cannot have more than 50 to 60 residues (and in practice, under 30). The peptide length is limited due to the cyclical derivatization not always going to completion. The derivatization problem can be resolved by cleaving large peptides into smaller peptides before proceeding with the reaction. It is able to accurately sequence up to 30 amino acids with modern machines capable of over 99% efficiency per amino acid. An advantage of the Edman degradation is that it only uses 10 - 100 pico-moles of peptide for the sequencing process. The Edman degradation reaction was automated in 1967 by Edman and Beggs to speed up the process and 100 automated devices were in use worldwide by 1973.
Because the Edman degradation proceeds from the N-terminus of the protein, it will not work if the N-terminus has been chemically modified (e.g. by acetylation or formation of pyroglutamic acid). Sequencing will stop if a non-α-amino acid is encountered (e.g. isoaspartic acid), since the favored five-membered ring intermediate is unable to be formed. Edman degradation is generally not useful to determine the positions of disulfide bridges. It also requires peptide amounts of 1 picomole or above for discernible results.
Secondary Structure
The percent and type of secondary structure can be determined using circular dichroism (CD) spectroscopy. In this method, right and left circularly polarized light illuminates a protein, which, since it is made of all L-amino acids, is chiral. (The mirror image would be a protein of the same sequence made of D-amino acids.) Differential absorption of the right and left forms give a CD spectrum
Circularly polarized light can be made when plane-polarized light of the same amplitude and wavelength meet out of phase by 900. (If they were out of phase by 1800, they would cancel.)
- To see an animation of how circularly polarized light can be created, go to this page and select: 1. Superposition of plane-polarized waves 2.
If R and L circularly polarized light of the same wavelength and amplitude are passed through an optically inactive medium, the two waves combine (vectorially) to produce plane-polarized light.
- To see an animation of how circularly polarized light can be created, go to this page and select: 1. Superposition of circularly polarized waves
Optical activity is observed only when the environment in which a transition occurs is asymmetric.
The peptide (amide) bond absorbs UV light in the range of 180 to 230 nm (far-UV range) so this region of the spectra give information about the protein backbone, and more specifically, the secondary structure of the protein. The main electronic energy transitions are n → π* at 220 nm and π → π * at 190 nm for the peptide bond. There is a contribution from aromatic amino acid side chains but it is small, given the large number of peptide bonds. The lone pair on the nitrogen adjacent to the pi bond can be considered to be rehybridized from sp3 to sp2, allowing for conjugation of the p electrons (which lowers the energy of the electrons). The Hückel diagram shown in Figure \(\PageIndex{7}\) below shows 3 molecular (not atomic) orbitals generated from the 3 atomic p orbitals.

Figure \(\PageIndex{7}\): Hückel molecular orbitals for the peptide bond
The middle one (with 1 node) has energy similar to the separate atomic p orbitals and is considered a nonbonding molecular orbital. This is consistent with the lone nonbonding pair on the nitrogen atom.
The peptide bonds in a protein's asymmetric environment will absorb this wavelength range of light (promoting electrons to higher energy levels). In different secondary structures, the peptide bond electrons will absorb right and left circularly polarized light differently (for example, they have different molar absorptivities). Hence α, β and random coil structures all have distinguishable far UV CD spectra.
To see an animation of circularly polarized light, go to this page and select 1. Circularly polarized Waves
Stated in another way, if plane-polarized light, which is a superposition of right and left circularly polarized light, passes through an asymmetric sample, which absorbs right and left circularly polarized differently (i.e they display circular dichroism), then the light passing through the sample after vector addition of the right and left hand circularly polarized light gives elliptically polarized light.
To see an animation of elliptically polarized light, go to this page and select 2. Plane-polarized waves in a medium with circular dichroism
If the chiral molecules also have a different index of refraction for R and L circularly polarized light, an added net effect is the rotation of the angle of the elliptically of the polarized light. The far-UV CD spectrum of the protein is sensitive to the main chain conformation. The CD spectra of alpha and beta secondary structures are shown in Figure \(\PageIndex{8}\).
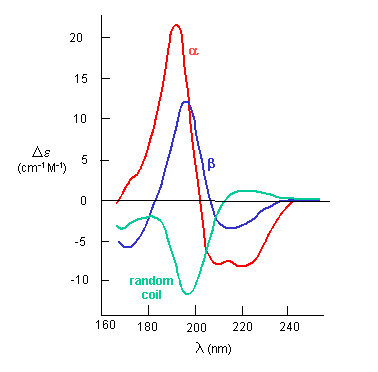
Protein side chains also find themselves in such an asymmetric environment. If irradiated with circularly polarized UV light in the range of 250-300 nm (near UV), differential absorption of right and circularly polarized light by the aromatic amino acids (Tyr, Phe, Trp) and disulfide bonds occur and a near UV CD spectra result. If the near UV CD spectra of a protein are taken under two different sets of conditions, and the spectra differ, then it can be surmised that the environment of the side chains is different, and hence the proteins have somewhat different conformations. It will not give information about the secondary structure of the backbone since that requires lower wavelengths for absorption of occur. Rather it can show differences in tertiary structure.
Analysis of Proteins Using Fluorescence Spectroscopy
Fluorescence spectroscopy is widely used to study many aspects of protein chemistry. This technique is not often used in lower-level undergraduate classes but it has become so important in the study of biomolecules, that a somewhat detailed explanation is necessary.
When electrons in a molecule absorb energy, they are promoted to higher electronic energy states. This is the basis of absorption spectroscopy. These excited state electrons can return to the ground state in processes that don't emit photons of light (ie. nonradiative processes) or radiative processes that do emit light. In simple absorption spectroscopy, the excited state electrons relax to the ground state through collision interactions. In radiative deexcitation, light is emitted. This process of light emission is called luminescence, which can be divided into two categories:
- fluorescence: If one electron from a ground state electron pair is excited to a higher energy state, the excited electrons can still be spin paired with its ground state counterpart - i.e. they have opposite spins. The excited electron can return to the ground state without reversing its spin. (The excited state is a singlet state with S, the total spin state, given the formula S = 2s +1 where s = 0 (sum of +1/2 and -1/2) and S = 1 for a singlet.) This process, which results in a rapid emission of a photon, is "spin allowed". The rate of photon emission is about 108 s-1, which results in a lifetime (the average time between excitation and emission) of the excited state of about 10 ns.
- phosphorescence: If, in contrast to the above case, the spin of the excited electron is flipped, then its transition back to the ground state is "spin forbidden" since the excited state electron and its ground state counterpart have the same spin state. (The excited state is a triplet state with S, the total spin state, given the formula S = 2s +1 where s = 1 (1/2 + 1/2) and S = 3 for triplet). Hence this transition occurs slowly (in the ms - s range). Toys that glow in the dark display even longer phosphorescence lifetimes. (Note: This guide will concentrate on fluorescence.)
Competing with the two deexcitation process are nonradiative processes (such as through collisions). Given these competing processes, it might be expected that phosphorescence in liquid solutions at room temperature might not be detectable
Molecules which fluoresce are typically aromatic, which absorb readily in the UV and visible light regions. Common fluorophores are quinine, found in tonic water (observe the faint blue glow at the surface when it is placed in direct sunlight), and fluorescein and rhodamine, two fluorophores often added to antifreeze. Atoms are usually nonfluorescent, with the exception of europium and terbium ions from the lanthanide series. These fluoresce when electronic transitions occur between f orbitals, which are shielded from solvent relaxation in these particular ions.
Among biological molecules, some, especially macromolecules with aromatic groups, fluoresce. These groups are called intrinsic fluorophores, and include, in the case of proteins, the side chains of tryptophan, tyrosine, and phenylalanine, the aromatic amino acids. The indole side chain of tryptophan is the most fluorescent, and its emission spectra, which is sensitive to solvent conditions, is often blue-shifted when it is buried, and red-shifted when solvent-exposed. Nucleic acids, although they also contain aromatic bases, are poor fluorophores. Many biological molecules can be made fluorescent by covalently modifying them (through nucleophiles on the biological molecule) with exogenously added fluorophores, such as fluorescein isothicyanate, rhodamine isothiocyante, dansyl chloride, etc. These are called extrinsic fluorophores. These include molecules that bind noncovalently to structures such as ds-DNA (ethidium bromide) or lipid membranes (diphenylhexatriene). Some biological fluorophores are substrates for enzyme reactions. An example is the oxidized flavins (FAD, FMN) and the reduced form of NAD (i.e. NADH). Another type of useful fluorophore is indicators, whose fluorescent properties change with a change in a parameter like pH or [Ca ion].
The electronic transitions that occur during fluorescence can be represented by a Jablonski diagram as shown in the two-part Figure \(\PageIndex{9}\) (A and B) below.

In panel A, the ground and first excited electronic state are shown. Within each electronic state are multiple vibrational energy levels 0, 1, 2 ..and 0'. 1' 2' .... This simple diagram ignores quenching of fluorescence, resonance energy transfer, etc. The transitions, represented by vertical lines, are considered to be instantaneous. They take about 10-15 s so the nuclei don't move in the process. The ground state electron is considered to be in the 0 vibrational level, So, since thermal energy is insufficient to promote it to the next vibrational level. When light is absorbed, the electron is promoted to a higher vibrational level within a higher electronic level. Usually, the excited electrons relaxes quickly (< 1 ps) to the lowest vibrational level of S1 or possibly S2 through a process called internal conversion. Fluorescence emission then may occur from the lowest vibrational state of S1 to any of the vibrational states of So. Hence the photon emitted is lower in energy (longer in wavelength) than the absorbed photon. Also since both process involve the movement of the electron to different vibrational levels with absorption or emission of a photon, and nonradiative vibrational relaxation within those levels, the emission spectra is often the mirror image of the absorption spectra. (This assumes that the vibrational levels in So and S1 are similarly spaced. Alternatively, electrons in S1 may flip spin and convert to the T1 state, in a process called intersystem crossing, leading to phosphorescence.
Panel B above shows blue lines corresponding to individual absorbances and red lins corresponding to emissions. Note that the excitation from 0 to 8' has the highest energy of absorbance (lowest wavelength) but gives little intensity as it would occur with low frequency. If you were to draw a line over the tops of the lines in panel B you would get a simple excitation spectra and emission spectra, which would be mirror images of each other. The emission peak is at a longer wavelength since energy was lost on vibrational, nonradiative relaxation of the excited electron. The difference in peak wavelengths of excitation and emission is called the Stokes Shift. This shift is greatest for fluorophores in polar environments. Inferences can be made considering the disposition of a side chain (buried or surface) if changes in fluorescence properties (intensity, Stoke's shift) are noted on protein denaturation. Also, many probes are weakly fluorescent in aqueous solution, but fluoresce intensely in nonpolar mediums (bound to a hydrophobic pocket in a protein, in a bilayer or lipoprotein, etc.)
Emission spectra are usually independent of excitation wavelength (Kasha's rule): This occurs because of the rapid relaxation into the lowest vibrational energy level of the excited state. There are also exceptions to the mirror image rule. Deviations arise from a change in the geometry of nuclei in the excited state molecule. This may occur if the lifetime of the S1 state is long, allowing time for motion before emission. An example of this can be seen with p-terphenyl in cyclohexane, in which the rings become more coplanar in the excited state. Since there is an electron shift in the excited state, a complex between the excited fluorophore and another solution component may arise (charge-transfer complex). Alternatively, some fluorophores form complexes with themselves (pyrene) with increasing concentration. At high concentrations, changes in the emission spectra occur, arising from emission from an excited-state dimer or excimer. Acridine shows two emission spectra at different pH's, arising from changes in the pKa on excitation (5.45 to 10.7). Finally, exciting a fluorophore at different wavelengths (EX 1, EX 2, EX 3) does not change the emission profile but does produce variations in fluorescence emission intensity (EM 1, EM 2, EM 3) that correspond to the amplitude of the excitation spectrum.
Fluorophores can be used to chemically modify nucleophilic side chains such as lysines and cysteines. Changes in intrinsic fluorescence in proteins can be used to measure the binding of ligands and conformation changes in the protein that occur on binding interactions, change in solution conditions, and protein denaturation. Let's explore a few fluorescence methods widely used to explore protein structure and function.
Fluorescence Quenching
Some chemical species (for example iodide and monomeric unpolymerized acrylamide), when added to a protein solution, can decrease the fluorescence from an intrinsic surface accessible fluorophore such as the tryptophan side chain, providing information on the local environment of the intrinsic fluorophore (example tryptophan side chain accessibility). For example, a buried tryptophan or probe will show little change in fluorescence intensity in the presence of a large, polar quencher, while a surface tryptophan or probe will show a significant decrease in fluorescent intensity. It is somewhat amazing that O2 when added to a solution under increasing pressure, can quench the fluorescence of even buried tryptophan side chain, implying that there are minimal diffusional barriers to O2 access. This suggests significant conformational flexibility of the protein.
Quenching can be dynamic, occurring on collision of the quench with the intrinsic fluorophore, or static, when the quencher binds to a site near the fluorophore as a prelude to quenching.
Collisional quenching is described by the Stern-Volmer equation.
\begin{equation}
\frac{F_{0}}{F}=1+k_{q} \tau_{0}[Q]=1+K_{D}[Q]
\end{equation}
where Fo and F are the fluorescent intensities in the absence and presence of the quencher, kq is the biomolecular quenching constant, τo is the lifetime of the fluorophore in the absence of the quencher and [Q] is the concentration of the quencher. kqτo = KD is the Stern-Volmer quenching constant.
A plot of Fo/F vs [Q] is linear, with a slope of KD. 1/KD is the quencher concentration at which Fo/F = 2, or 50% of the fluorescence intensity is quenched. A linear plot indicates a single class of fluorophores, all equally accessible to the quencher. A nonlinear plot would be found for quenching of tryptophan fluorescence in proteins by charged or polar quenchers for proteins with more than one tryptophan and in which some are buried. Static quenching also results in a linear SV plot. Dynamic and static quenching can be distinguished by different dependencies on temperature and viscosity. Since dynamic quenching depends on diffusion, and higher temperatures result in higher diffusion coefficients, kq should increase with temperature. If static quenching is involved, higher temperatures will probably reduce complex formation.
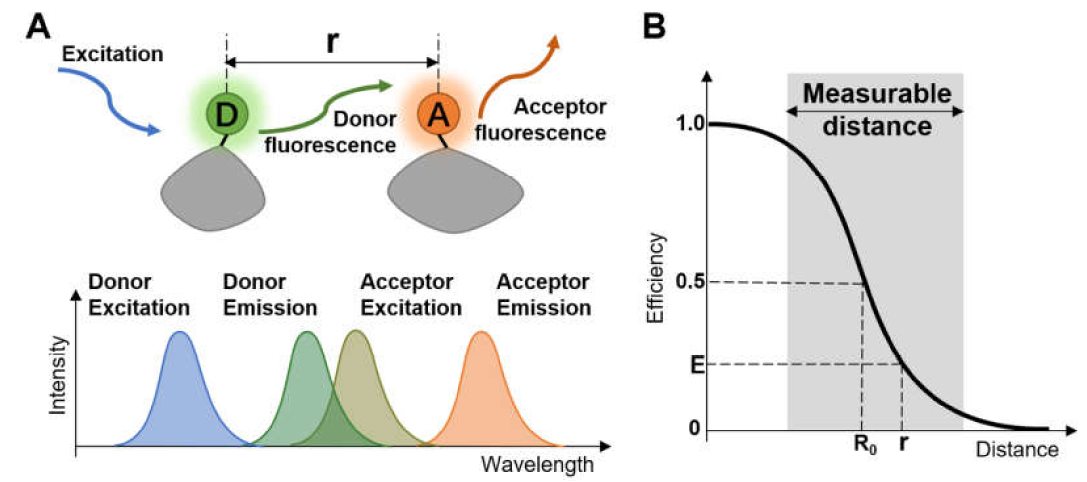
Fluorescence Resonance Energy Transfer (FRET)
If an absorbing species is in close proximity to an excited state fluorophore, and if the emission spectra of the fluorophore overlaps the absorption spectra of the second species, coupling of the two dipoles can occur, and energy can be transferred from the excited state of the fluorophore (donor D) to the second absorbing species (acceptor A). This transfer of energy is through dipole coupling and not through the trivial release and absorption of an emitted photon. No photon is produced. This process is called fluorescence resonance energy transfer (FRET). Efficiency, E, of FRET for a single donor/acceptor pair at a fixed distance is given by:
\begin{equation}
\mathrm{E}=\frac{\mathrm{R}_{0}^{6}}{\left(\mathrm{R}_{0}^{6}+\mathrm{r}^{6}\right)}=\frac{1}{1+\left(\frac{\mathrm{r}}{\mathrm{R}_{0}}\right)^{6}}
\end{equation}
where Ro is the Förster distance (or radius) with a 50% transfer efficiency and r is the distance between the donor and acceptor. Ro is a measure of the spectral overlap of the donor and acceptor (for which most biological macromolecules have a similar value of 30-60 angstroms). This equation shows an efficiency dependent on 1/r 6, making FRET exquisitely sensitive to distance. FRET and its dependency of distance is illustrated in Figure \(\PageIndex{10}\) below.
Anisotropy or polarization
These measure the extent of rotation of the fluorophore during its fluorescent lifetime. If a small fluorophore binds to a large molecule, its rotation diffusion constant decreases, and its anisotropy increases as illustrated in Figure \(\PageIndex{11}\).
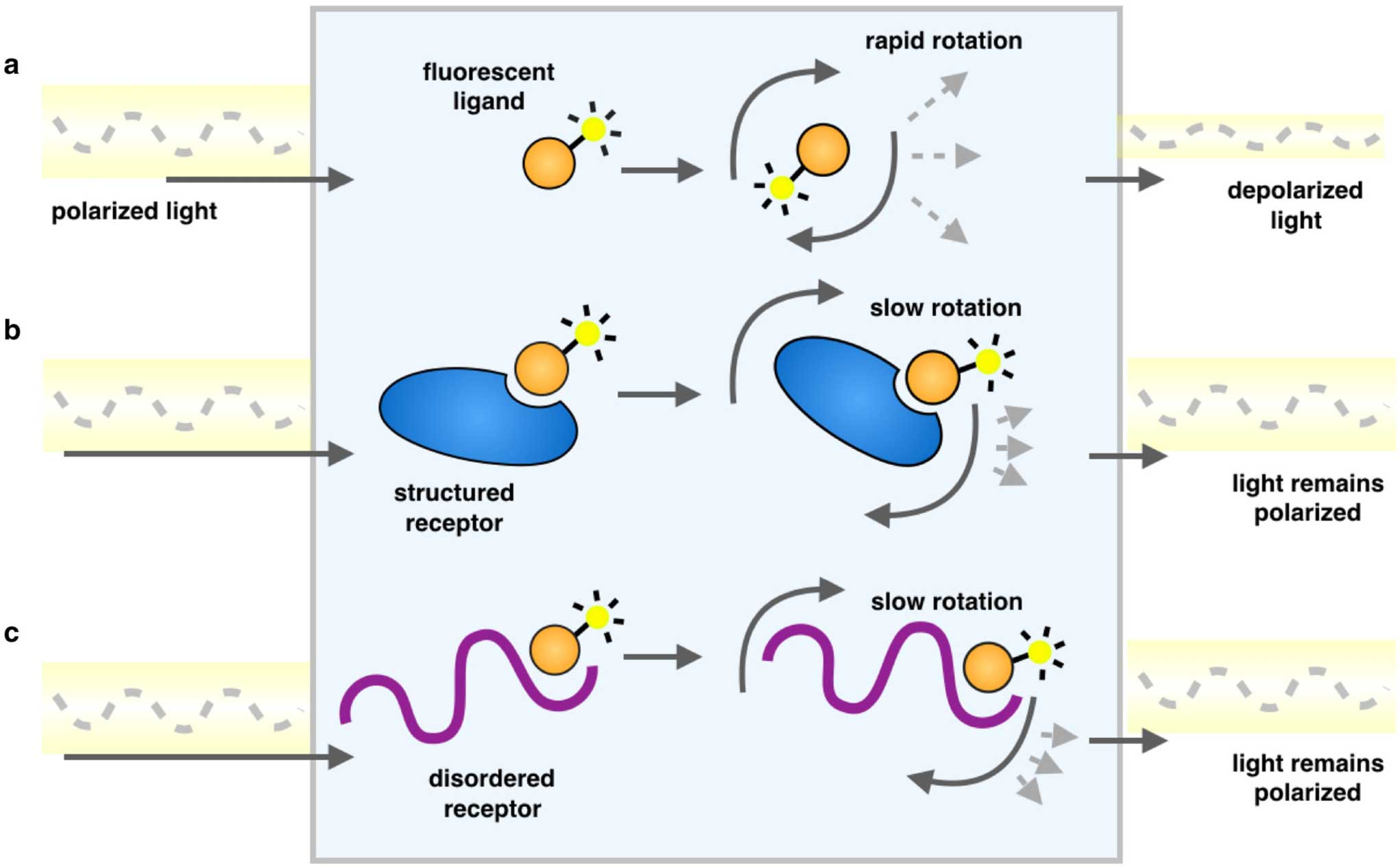
Schematic representation of a fluorescence polarization experiment. As a result of rapid tumbling of molecules in solution, when a fluorescently labeled ligand is excited with plane-polarized light, the resulting emitted light is largely depolarized (a). Upon binding another species, a larger proportion of the emitted light remains in the same plane as the excitation energy, because the rotation is slowed as the effective molecular size increases, whether it is an ordered molecular structure (b) or one that is disordered (c)". Since viscosity decreases rates of rotational diffusion, changes in fluorescence (such as inside a bilayer) can be inferred from these measurements. For example, membranes more enriched in saturated fatty acids should show increased anisotropy of a hydrophobic, fluorescent probe, in comparison to the same probe in a bilayer enriched in polyunsaturated fatty acids.
Analysis of Protein Using Mass Spectrometry
Mass spectrometry is supplanting more traditional methods (see above) as the choice to determine the molecular mass and structure of a protein. Its power comes from its exquisite sensitivity and modern computational methods to determine structure through comparisons of ion fragment data with computer databases of known protein structures. In mass spectrometry, a molecule is first ionized in an ion source. The charged particles are then accelerated by an electric field into a mass analyzer where they are subjected to an external magnetic field. The external magnetic field interacts with the magnetic field arising from the movement of the charged particles, causing them to deflect. The deflection is proportional to the mass to charge ratio, m/z. Ions then enter the detector which is usually a photomultiplier. Sample introduction into the ion source occurs though simple diffusion of gases and volatile liquids from a reservoir, by injection of a liquid sample containing the analyte by spraying a fine mist, or for very large proteins by desorbing a protein from a matrix using a laser. Analysis of complex mixtures is done by coupling HPLC with mass spectrometry in a LCMS.
There are many methods to ionize molecules, including atmospheric pressure chemical ionization (APCI), chemical ionization (CI), or electron impact (EI). The most common methods for protein/peptide analyses are electrospray ionization (ESI) and matrix-assisted laser desorption ionization (MALDI).
Electrospray ionization (ESI)
The analyte, dissolved in a volatile solvent like methanol or acetonitrile, is injected through a fine stainless steel capillary at a slow flow rate into the ion source. A high voltage (3-4 kV) is maintained on the capillary giving it a positive charge with respect to the other oppositely charged electrode. The flowing liquid becomes charged with the same polarity as the polarity of the positively charged capillary. The high field leads to the emergence of the sample as a charged aerosol spray of charged microdrops, which reduces electrostatic repulsions in the liquid. This method essentially uses electrical energy to produce the aerosol instead of mechanical energy to produce a liquid aerosol, as in the case of a perfume atomizer. Surrounding the capillary is a flowing gas (nitrogen) which helps to move the aerosol toward the mass analyzer. The microdrops become smaller in size as the volatile solvent evaporates, increasing the positive charge density on the drops. Eventually, electrostatic repulsions cause the drops to explode in a series of steps, ultimately producing the analyte devoid of solvent. This gentle method of ionization produces analytes that are not cleaved but ready for introduction into the mass analyzer. Proteins emerge from this process with a roughly Gaussian distribution of positive charges on basic side chains. In organic chemistry, you studied mass spectrums of small molecules induced by electron bombardment. This produces ions of +1 charge as an electron is stripped away from the neutral molecule. The highest m/z peak in the spectrum is the parent ion or M+ ion. The highest m/z ratio detectable in the mass spectrum is in the thousands. However, large peptides and proteins with large molecular masses can be detected and resolved since the charge on the ions are great than +1. In 2002, John Fenn was awarded a Noble Prize in Chemistry for the development and use of ESI to study biological molecules.
An example of an ESI spectrum of apo-myoglobin is shown in Figure \(\PageIndex{12}\).
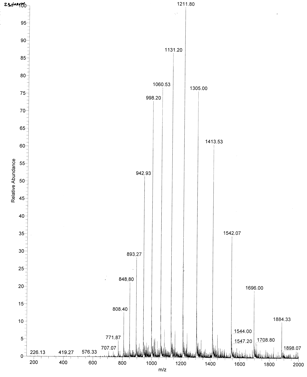
Note the roughly Gaussian distribution of the peaks, each of which represents the intact protein with charges differing by +1. Proteins have positive charges by virtue of both protonation of amino acid side chains as well as charges induced during the electrospray process itself. Based on the amino acid sequence of myoglobin and the assumption that the pKa of the side chains are the same in the protein as for isolated amino acids, the calculated average net charges of apomyoglobin (apoMb) would be approximately +30 at pH 3.5, +20 at pH 4.5, +9 at pH 6, and 0 at pH 7.8 (the calculated pI). The mass spectrum below was taken by direct injection into the MS of apoMb in 0.1% formic acid (pH 2.8). Charges on the peptide result from those present on the peptide before the electrospray and changes in charges induced during the process.
The molecular mass of the protein can be determined by analyzing two adjacent peaks, as shown in Figure \(\PageIndex{13}\).
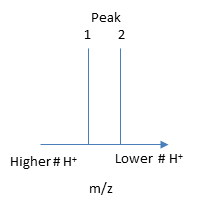
If M is the molecular mass of the analyte protein, and n is the number of positive charges on the protein represented in a given m/z peak, then the following equations gives the molecular mass M of the protein for each peak:
\begin{equation}
\begin{gathered}
\mathrm{M}_{\text {peak } 2}=\mathrm{n}(\mathrm{m} / \mathrm{z})_{\text {peak } 2}-\mathrm{n}(1.008) \\
\mathrm{M}_{\text {peak } 1}=(\mathrm{n}+1)(\mathrm{m} / \mathrm{z})_{\text {peak } 1}-(\mathrm{n}+1)(1.008)
\end{gathered}
\end{equation}
where 1.008 is the atomic weight of H. Since there is only one value of M, the two equations can be set equal to each other, giving:
\begin{equation}
\mathrm{n}(\mathrm{m} / \mathrm{z})_{\text {peak } 2}-\mathrm{n}(1.008)=(\mathrm{n}+1)(\mathrm{m} / \mathrm{z})_{\text {peak } 1}-(\mathrm{n}+1)(1.008)
\end{equation}
Solving for n gives:
\begin{equation}
\mathrm{n}=\frac{(\mathrm{m} / \mathrm{z})_{\mathrm{peak} 1}-(1.008)}{(\mathrm{m} / \mathrm{z})_{\mathrm{peak} 2}-(\mathrm{m} / \mathrm{z})_{\mathrm{peak} 1}}
\end{equation}
Knowing n, the molecular mass M the protein can be calculated for each m/z peak. The best value of M can then be determined by averaging the M values determined from each peak (16,956 from the above figure). For peaks from m/z of 893-1542, the calculated values of n ranged from +18 to +10.
Matrix assisted laser desorption ionization (MALDI)
In this technique, used for larger biomolecules like proteins and polysaccharides, the analyte is mixed with an absorbing matrix material. Laser excitation is used to excite the matrix, leading to energy transfer that results in ionization and the "launching" of the matrix and analyte in ion form from the solid mixture. Parent ion peaks of (M+H)+ and (M-H)- are formed.
Mass Analyzer takes the created ion and separates them based on m/z ratios. Let's consider two, quadrupole ion tap and time of flight. on mass-to-charge ratios. There are several general types of mass analyzers, including magnetic sector, time of flight, quadrupole, ion trap
Quadrupole ion trap (used in ESI) - A complex mixture of ions can be contained (or trapped) in this type of mass analyzer. Two common types are linear and 3D quadrupole. If a dipole has two poles (+ and -) separated by some distance, then a quadrupole has four poles (+, -, +, and -) arranged geometrically such that each + has a - on each side and vice versa. Figure \(\PageIndex{14}\) below shows linear and 3D quadrupoles
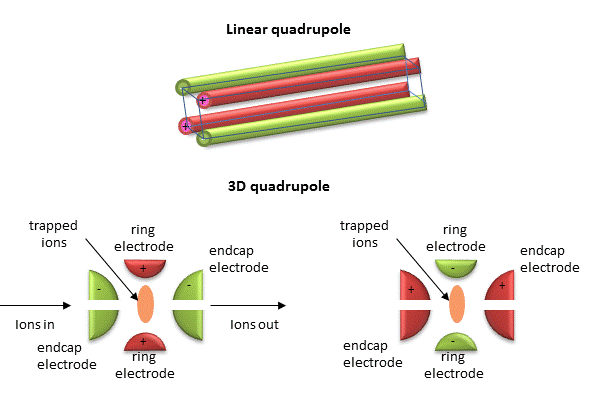
As dipoles display positive and negative charge separation on a linear axis, quadrupoles have either opposite electrical charges or opposite magnetic fields at the opposing ends of a square or cube. In charge separation, the monopole (sum of the charges) and dipoles cancel to zero, but the quadrupole moment does not. The quadrupole traps ions using a combination of fixed and alternating electric fields. The trap contains helium at 1 mTorr. For the 3D trap, The ring electrode has an oscillating RF voltage which keeps the ions trapped. The end caps also have an AC voltage. Ions oscillate in the trap with a "secular" frequency determined by the frequency of the RF voltage, and of course, the m/z ratio. By increasing the amplitude of the RF field across the ring electron, ion motion in the trap becomes destabilized and leads to ion ejection into the detector. When the secular frequency of ion motion matches the applied AC voltage to the end cap electrodes, resonance occurs and the amplitude of motion of the ions increases, also allowing leakage out of the ion trap into the detector.
Tandem Mass Spectrometry (MS/MS): Quadrupole mass analyzers, which can select ions of varying m/z ratios in the ion traps, are commonly used in tandem mass spectrometry (MS/MS). In this technique, the selected ions are further fragmented into smaller ions by a process called collision-induced dissociation (CID). When performed on all of the initial ions present in the ion trap, the sequence of a peptide/protein can be determined. This technique usually requires two mass analyzers with a collision cell in between where selected ions are fragmented by collision with an inert gas. It can also be done in a single mass analyzer using a quadrupole ion trap.
Time of Flight (TOF) tube (used in MALDI) - a long tube is used and the time required for ion detection is determined. The small molecular mass ions take the shortest time to reach the detector.
Sequence Determination Using Mass Spectrometry
In a typical MS/MS experiment to determine a protein sequence, a protein is cleaved into protein fragments with an enzyme such as trypsin, which cleaves on the carboxyl side of positively charge Lys and Arg side chains. The average size of proteins in the human proteome is approximately 50,000. If the average molecular mass of an amino acid in a protein is around 110 (18 subtracted since water is released on amide bond formation), the average number of amino acids in the protein would be around 454. If 10% of the amino acids are Arg and Lys, then on average there would be approximately 50 Lys and Arg, and hence 50 tryptic peptides of average molecular mass 1000. The fragments are introduced in the MS where a peptide fragment fingerprint analysis can be performed. The molecular weights of the fragments can be identified and compared to known peptide digestion fragments from known proteins to identify the analyte protein.
Ions with the original N terminus are denoted as a, b, and c, while ions with the original C terminus are denoted as x, y, and z. c and y ions gain an extra proton from the peptide to form positively charged -NH3+ groups. Figure \(\PageIndex{15}\) below shows peaks for a 4-amino acid peptide fragmentation pattern
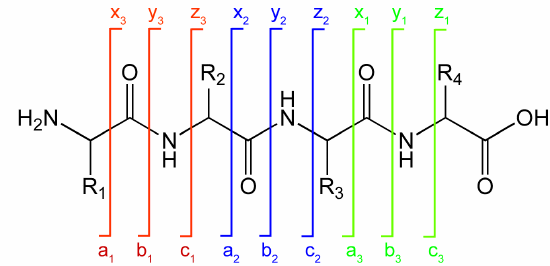
Figure \(\PageIndex{15}\): 4-amino acid peptide fragmentation peaks. https://commons.wikimedia.org/wiki/F...gmentation.gif. Creative Commons Attribution-Share Alike 3.0 Unported
Ions with the original N terminus are denoted as a, b, and c, while ions with the original C terminus are denoted as x, y, and z. c and y ions gain an extra proton from the peptide to form positively charged -NH3+ groups. The actual ions observed depend on many factors including the sequence of the peptide, its original charge, the energy of the collision inducing the fragmentation, etc. Low energy fragmentation of peptides in ion traps usually produces a, b, and y ions, along with peaks resulting from loss of NH3 (a*, b* and y*) or H2O (ao, bo, and yo). No peaks resulting from the fragmentation of side chains are observed. Fragmentation at two sites in the peptide (usually at b and y sites in the backbone) forms an internal fragment.
The y1 peak represents the C-terminal Lys or Arg (in this example) of the tryptic peptide. Peak y2 has one additional amino acid compared to y1 and the molecular mass difference identifies the extra amino acid. Peak y3 is likewise one amino acid larger than y2. All three y fragments peaks have a common Lys/Arg C-terminal and the charged fragment contains the C-terminal end of the original peptide. All b fragment peaks for a given peptide contain a common N terminal amino acid with b1 the smallest. Note that the subscript represents the number of amino acids in the fragment. By identifying b and y peaks the actual sequence of small peptides can be determined. Usually, spectra are matched to databases to identify the structure of each peptide and ultimately that of the protein. The actual m values for fragments can be calculated as follows, where (N is the molecular mass of the neutral N terminal group, (C) is the molecular mass of the neutral c terminal group, and (M) is the molecule mass of the neutral amino acids. (For N terminal amino acid, add 1 H. for C terminus add OH)
- a: (N)+(M)-CHO
- b: (N)+(M)
- y: (C)+(M)+H (note in the figure above that the amino terminus of the y peptides has an extra proton in the +1 charged peptides.)
m/z values can be calculated from the calculated m values and by adding the one H mass to the overall z if the overall charge is +1, etc.
As an example, from these MW values, the sequence of the human Glu1- fibrinopeptide B can be determined from MS/MS spectra shown in an annotated form in Figure \(\PageIndex{16}\). Note that most of the b peaks are b* resulting from the loss of NH3 from the N terminus.

Now let's step back and get a broader picture of structure analysis by mass spectrometry. In general, proteins are analyzed either in a "top-down" approach in which proteins are analyzed intact, or a "bottom-up" approach in which proteins are first digested into fragments. An intermediate "middle-down" approach in which larger peptide fragments are analyzed may also sometimes be used. The top-down approach however is mostly limited to low-throughput single-protein studies due to issues involved in handling whole proteins, their heterogeneity, and the complexity of their analyses.
In the second approach, referred to as the "bottom-up" MS, proteins are enzymatically digested into smaller peptides using a protease such as trypsin, which cleaves peptide chains mainly at the carboxyl side of the amino acids lysine or arginine, except when either is followed by proline. It is used for numerous biotechnological processes. The process is commonly referred to as trypsin proteolysis or trypsinization, and proteins that have been digested/treated with trypsin are said to have been trypsinized.
Subsequently, these peptides are introduced into the mass spectrometer and identified by peptide mass fingerprinting or tandem mass spectrometry. Hence, this approach uses identification at the peptide level to infer the existence of proteins pieced back together with de novo repeat detection. The smaller and more uniform fragments are easier to analyze than intact proteins and can be also determined with high accuracy, this "bottom-up" approach is therefore the preferred method of studies in proteomic studies. A further approach that is beginning to be useful is the intermediate "middle-down" approach in which proteolytic peptides larger than the typical tryptic peptides are analyzed.
Proteins of interest are usually part of a complex mixture of multiple proteins and molecules, which co-exist in the biological medium. This presents two significant problems. First, the two ionization techniques used for large molecules only work well when the mixture contains roughly equal amounts of constituents, while in biological samples, different proteins tend to be present in widely differing amounts. If such a mixture is ionized using electrospray or MALDI, the more abundant species have a tendency to "drown" or suppress signals from less abundant ones. Second, the mass spectrum from a complex mixture is very difficult to interpret due to the overwhelming number of mixture components. This is exacerbated by the fact that the enzymatic digestion of a protein gives rise to a large number of peptide products.
In light of these problems, the methods of one- and two-dimensional gel electrophoresis and high-performance liquid chromatography are widely used for the separation of proteins. The first method fractionates whole proteins via two-dimensional gel electrophoresis (Figure 3.31). The first dimension of 2D gel electrophoresis is isoelectric focusing (IEF). In this dimension, the protein is separated by its isoelectric point (pI) and the second dimension is SDS-polyacrylamide gel electrophoresis (SDS-PAGE). This dimension separates the protein according to its molecular weight. Once this step is completed in-gel digestion occurs.
In some situations, it may be necessary to combine both of these techniques. Gel spots identified on a 2D Gel are usually attributable to one protein. If the identity of the protein is desired, usually the method of in-gel digestion is applied, where the protein spot of interest is excised and digested proteolytically. The peptide masses resulting from the digestion can be determined by mass spectrometry using peptide mass fingerprinting. If this information does not allow unequivocal identification of the protein, its peptides can be subject to tandem mass spectrometry for de novo sequencing. Small changes in mass and charge can be detected with 2D-PAGE. The disadvantages of this technique are its small dynamic range compared to other methods. Some proteins are still difficult to separate due to their acidity, basicity, hydrophobicity, and size (too large or too small).
The second method, high-performance liquid chromatography is used to fractionate peptides after enzymatic digestion. Characterization of protein mixtures using HPLC/MS is also called shotgun proteomics and MuDPIT (Multi-Dimensional Protein Identification Technology). A peptide mixture that results from the digestion of a protein mixture is fractionated by one or two steps of liquid chromatography. The eluant from the chromatography stage can be either directly introduced to the mass spectrometer through electrospray ionization, or laid down on a series of small spots for later mass analysis using MALDI.
The general schema for analyzing proteins by mass spectrometry is shown in Figure \(\PageIndex{17}\).
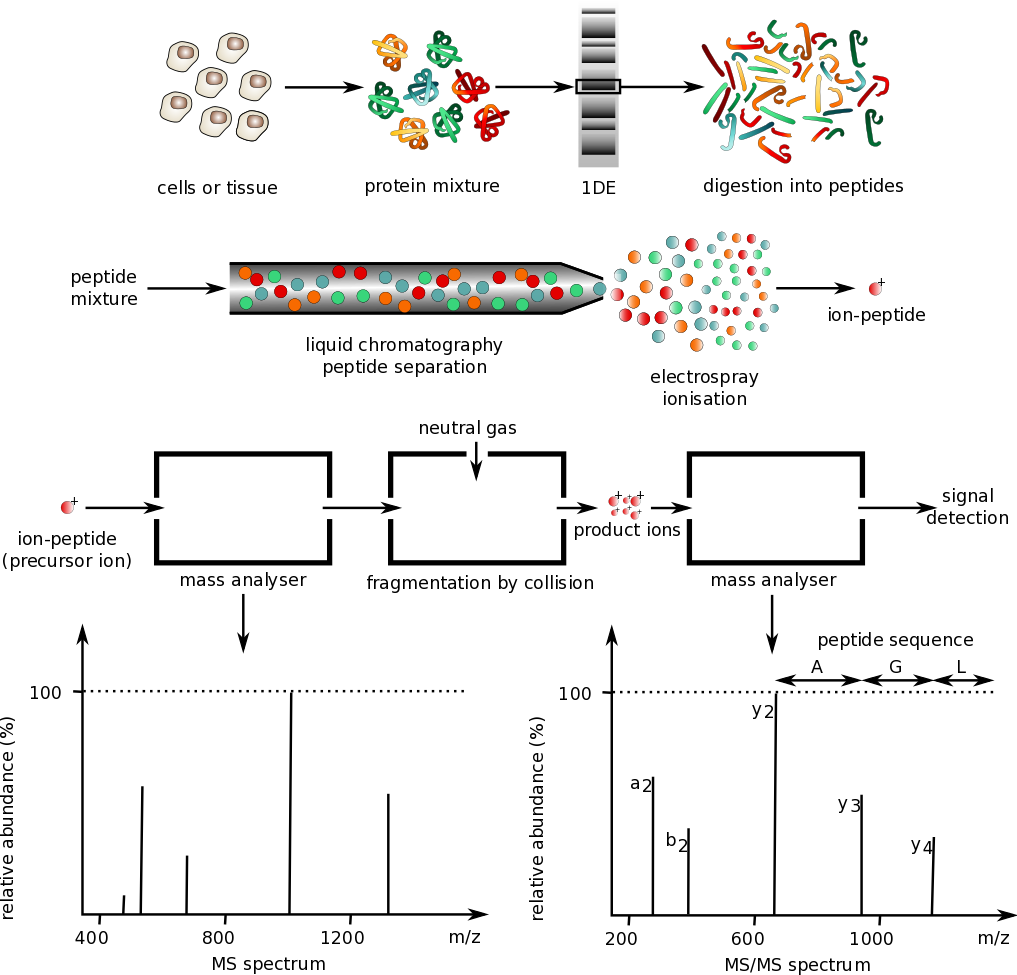
Protein mixtures are prepared from cell culture or tissue samples and separated by gel electrophoresis. Single proteins are isolated and digested using trypsin to produce a peptide mixture. Peptides are separated by liquid chromatography and analyzed by mass spectrometry
3D Structural Determination
There are four main ways that the 3D structure of a protein can be determined. These include X-ray crystallography, multidimensional NMR, cryoelectron microscopy, and computer modeling using artificial intelligence and machine learning.
X-Ray Crystallography
In this technique, proteins are induced to form solid crystals in which the individual molecules pack in a well-defined crystal lattice. X-rays are aimed at the crystals. The x-rays are scattered off of the crystal and collected by a detector. The scattered x-rays engage in constructive and destructive interference (much as water waves do) and form a diffraction pattern. The diffraction pattern is determined by the spacing and types of atoms in the crystal. Hence from a given 3D structure, a specific diffraction pattern is formed. Using some sophisticated mathematics (Fourier Transformations), the diffraction pattern can be converted back into the 3D structure of the object, in this case, the atoms with the protein.
Constructive and destructive interference and the formation of a "diffraction" pattern can be readily seen performing two PHET simulations. Follow the instructions below.
Simulation 1: Slits
- Select Slits to open the simulation and select these choices in order:
- Type of wave: pick one that looks like a bullet
- Frequency (middle green)
- Amplitude: max
- Check Screen
- Choose 2 Slits
- Slit width 200
- Slit separation 400
- Click the Green button.
You will see light/dark patterns moving toward the screen. The light zones arise from constructive interference and dark from destructive interference of the two waves as they emerge from the slits.
Simulation 2: Diffraction
Now, look at the diffraction pattern arising from light moving through simple and more complex openings and interacting with an object, using the PHET animation and the step below.
- First, refresh the browser window
- Select Diffraction to open the simulation and select these choices in order
- Pick 450 nm wavelength
- Choose in succession the 4 vertical icons (circle, square, circle/square, array of circles, person)
- Observe the diffraction patterns as you change the slit size
X-ray scattering can also be envisioned as light "reflecting" from a series of planes formed by atoms in the crystal in which the planes are separated by specific distances (in the Angstroms range). The x-rays that are "reflected" from innumerable planes recombine constructively and destructively to form a diffraction pattern. X rays are used since the size of the "slits", and the distance between these "reflective" planes, must be comparable to the wavelength of the incident light, which for x-rays is 0.5 – 2.5 Å.
A diffraction pattern is mathematically decoded to form an electron density map since it is the electrons that actually scatter the x-rays. Hydrogen atoms don't appear in x-ray crystal structures since they don't have enough electrons to be effective scattering centers. Computer programs are used to fit the electron density map to a 3D arrangement of atoms separated by characteristic bond distances corresponding to the functions groups and side chains found in protein. The quality/amount of crystals helps determine the quality of the diffraction pattern and the resulting structure. X-ray crystallographers define quality in terms of resolution. A resolution of 5Å - 10Å can reveal the structure of polypeptide chains, 3 Å - 4 Å of groups of atoms, and 1 Å - 1.5 Å of individual atoms.
Figure \(\PageIndex{18}\) shows the process from crystal to model.
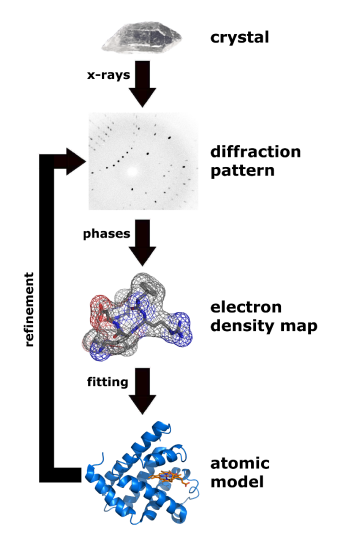
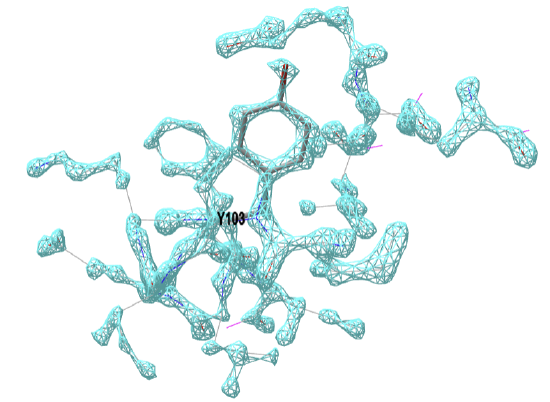
Figure \(\PageIndex{19}\) below shows the electron density map around tyrosine 103 from myoglobin from crystal structures at two different resolutions (left, 1a6m, 1.0 Å resolution and right, 108m, 2.7 Å resolution).
 |
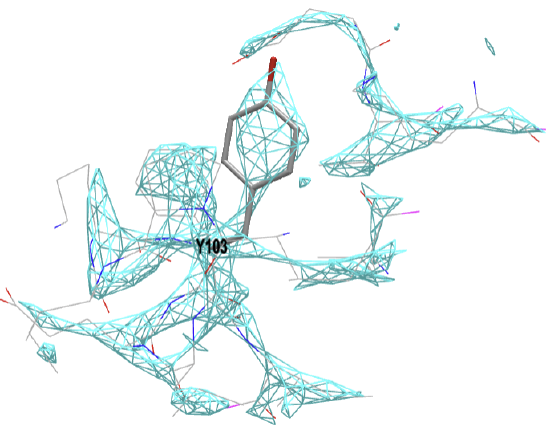 |
Figure \(\PageIndex{19}\): Electron density map around tyrosine 103 from myoglobin from crystal structures at two different resolutions (left, 1a6m, 1.0 Å resolution and right, 108m, 2.7 Å resolution). Click on the images to see full iCn3D models showing the electron density map around the Y103. (Choice of Y103 from https://pdb101.rcsb.org/learn/guide-...ata/resolution)
This figure shows 2Fo-Fc electron density maps which use the observed diffraction data, Fo, with the diffraction data calculated from the atomic model, Fc. Proteopedia has an excellent description of electron density maps.
Not all proteins can be readily crystallized. The process is in many ways an art as much as it is a science. Membrane proteins fall into this category.
Nuclear Magnetic Resonance (NMR)
Many readers have probably performed 1H-NMR on small molecules introductory and organic chemistry labs. Interpreting spectra of molecules with many hydrogen atoms in straight and branched chains, in rings, and in functional groups is not simple. Imagine doing that to determine the structure of a small protein with 1000s of hydrogen atoms! The spectrum would be essentially indecipherable. Luckily multi-dimension NMR techniques have allowed the solution (not crystal) structure of small proteins to be determined. These methods are outside of the scope of this book. For those interested in more detail, read A brief introduction to NMR spectroscopy of proteins by Poulsen.
Let's give a brief introduction to a 2D NMR peak for a simple molecule, ethylacetate. The 1D 1H-NMR spectrum for the molecule is shown in Figure \(\PageIndex{20}\).

Now let's show a simulated 2D COSY spectra of the same molecule. The image and explanation below are adapted from Structure & Reactivity in Organic, Biological and Inorganic Chemistry by Chris Schaller, which is licensed under a Creative Commons Attribution-NonCommercial 3.0 Unported License. Structure and Reactivity
In homonuclear correlation spectroscopy (COSY), we can look for hydrogens that are coupled to each other. In ethyl acetate, it's pretty clear where they are. There is a quartet and a triplet; the hydrogens corresponding to those two peaks are probably beside each other in the structure. The COSY spectrum simply takes that 1H spectrum and spreads it out into two dimensions. Instead of being displayed as a row of peaks, the peaks are spread out into a 2D array. Figure \(\PageIndex{21}\) shows an annotated simulated COSY spectrum. The peaks are displayed along one axis and the same peaks are also displayed along the other axis.

What does it mean to be coupled? It means that magnetic information is transmitted between the atoms. How can we tell? Essentially, we can send a pulse of electromagnetic radiation into one set of hydrogens and look for a response somewhere else. Of course, if we send a pulse of radio waves at a frequency that will be absorbed by a particular hydrogen, we will see a response in that hydrogen itself. That's why we see the peaks on the diagonal (dotted line). The peaks along the diagonal in the spectra (1.26, 1.26; 2.04, 2.04; 4.12, 4.12) hence don't give any new information since they are the main peaks in the 1D NMR.
However, we also see responses from other hydrogens that are magnetically linked to the original one. They give the peaks (shown as purple circles) that do not appear along the diagonal. Those peaks indicate which hydrogens are coupled to which other hydrogens. The hydrogens at 1.26 ppm are coupled to the ones at 4.12 ppm, and that gives a "cross-peak" at (1.26, 4.12). There is also a cross-peak at (4.12, 1.26), because that relationship goes both ways.
This coupling should make sense because the protons that give the signals at 4.12 (-O-CH2-CH3) and 1.26 (-CH2-CH3) are on adjacent carbons and split each other's signals as seen in the 1D NMR. This examples shows how we can get information on which protons in a 2D NMR spectra are coupled through 3 bonds (H-C-C-H), critical information for determining protein structures by NMR.
There are variants of 2D NMR that are used in protein structure as well. They use NMR-active nuclei in addition to 1H, including 13C (natural abundance 1%) and 15N (natural abundance 0.37%). Given these low abundances, proteins for NMR structure determination are often purified in cells grown in media enriched in 13C and 15N precursors.
HMBC (Heteronuclear Multiple Bond Correlation) and HMQC (Heteronuclear Multiple Quantum Coherence): Just as COSY spectra show which protons are coupled to each other, HMBC (and the related HMQC) give information about the relative relationships between protons and carbons in a structure. In an HMQC spectrum, a 13C spectrum is displayed on one axis and a 1H spectrum is displayed on the other axis. Cross-peaks show which proton is attached to which carbon. COSY spectra show 3-bond coupling (from H-C-C-H), whereas HMQC shows a 1-bond coupling (just C-H).
Nuclear Overhauser Effect (NOE) Spectroscopy (NOESY): This technique shows through-space interactions within the molecule, rather than the through-bond interactions seen in COSY and HMBC/HMBQ. This method is especially useful for determining stereochemical relationships in a molecule. In two stereoisomers, the atoms are all connected in exactly the same order, through exactly the same bonds. A COSY or an HMBC spectrum wouldn't be able to distinguish between these isomers.
HNCA: This is an example of 3D NMR. It shows a correlation between an amide proton, the amide nitrogen to which it is attached, and the carbons that are attached to the amide nitrogen. HNCA data are viewed in slices, in which you look at one nitrogen at a time. One axis shows the shift of the proton attached to that nitrogen, and the other axis shows the shifts of the carbons attached to the nitrogen. The abbreviation comes from the pathway for transfer of the magnetization (amide H to amide N, and then the attached Cs).
NMR structures found in the Protein Data Bank show an ensemble of slightly different structures. This arises from the dynamic behavior of the proteins in water, compared to when the structure is determined from a crystal. Comparative analyses between crystal and NMR structures show that secondary structures are equally accurate, that loops in NMR structures are probably too flexible, and that loops in protein, often on the surface, are too rigid, which makes sense given the packing restraints with a crystal lattice.
Cryo-electron Microscopy
Cryogenic-electron microscopy (cryo-EM) has recently emerged as a powerful technique in structural biology that is capable of delivering high-resolution density maps of macromolecular structures. A cryo-EM and structure determined from it are shown in Figure \(\PageIndex{22}\).

Resolutions approaching 1.5 Å are now possible and maps in the 1–4-Å range inform the construction of atomistic models with a high degree of confidence. This new capacity for investigators to determine macromolecular structures at high resolution and without the need to form crystals has led to an explosion of interest in adopting cryo-EM.
Protein suspensions are frozen on 3-mm-diameter transmission-electron microscope (TEM) support grids made from a conductive material (e.g. Cu or Au) that are coated with a carbon film with a regular array of perforations 1–2 μm in diameter. A total of 3–5 μl of sample is loaded onto the grid which is then immediately blotted with filter paper with the aim of creating a film of buffer/protein on the grid that, when frozen, will be thin enough for the electron beam to penetrate. Optimizing the ice thickness is a vital step in sample preparation as thicker layers of ice increase the probability that the incident electron will undergo multiple scattering events and thereby reduce the image quality. In the case of extreme ice thickness, the electron beam does not penetrate at all. After blotting, the grid is rapidly plunged into a bath of liquid ethane—a very effective cryogen that freezes water with sufficient rapidity to prevent the formation of ice crystals. The formation of a vitreous layer of ice is the fundamental step in cryo-EM and preserves the target in a near-native state. The resulting vitreous ice layer with suspended protein molecules must then remain close to liquid nitrogen temperature (− 196 °C) during storage and imaging in the TEM to prevent phase changes to other types of ice that are not amenable to high-quality imaging and preservation of protein structure.
Figure \(\PageIndex{23}\) shows a summary of the process and single particle structure determination.

Figure \(\PageIndex{23}\): Principle of cryo-EM and single-particle reconstruction. Agirrezabala, X., Frank, J., 2010. From DNA to proteins via the ribosome: Structural insights into the workings of the translation machinery. Human Genomics 4, 226.. https://doi.org/10.1186/1479-7364-4-4-226. CC BY 4.0
The above figure shows cryoEM structure determination process for ribosomes. When frozen, they are found in random orientations embedded in a thin layer of ice. Exposure to a low-dose electron beam in the transmission electron microscope produces a projection image (i.e the electron micrograph). A typical electron micrograph shows E. coli ribosomes as low-contrast single particles on a noisy background. After the orientations of the particles have been determined, usually by matching them with a reference through computer algorithms, they are used to reconstruct a density map by a back-projection or a similar reconstruction algorithm. This density map is segmented into the different components (subunits, ligands), and the different components are displayed using different colors in a surface representation (bottom panel; small and large subunits are shown in yellow and blue, respectively. A- and P-site tRNAs are colored red pink and green, respectively).
Given the increasing popularity of this technique, we present Figure \(\PageIndex{24}\) below which shows another representation with the end-point of a 3D model of higher resolution.

Figure \(\PageIndex{24}\): A schematic of the single-particle reconstruction cryoEM pipeline. Hey Tony et al., 2020Machine learning and big scientific data. Phil. Trans. R. Soc. A.3782019005420190054. http://doi.org/10.1098/rsta.2019.0054. Creative Commons Attribution License http://creativecommons.org/licenses/by/4.0/
When the beam strikes the ice lays in which the single structure is found, the ices domes which cause motion. Motion pictures are taken with fast detectors and computers are used to adjust the images for the motion, which would dull and lower the resolution of the structure. In addition, as X-rays damage molecules, so can electron beams. Earlier frames in the movie show less damage. Both the motion and damage effects of the beam can now be corrected to increase the resolution.
Here is a YouTube video from PDB 101 that describes the technique.
Methods for determining atomic structure. PDB-101: Educational resources supporting molecular explorations through biology and medicine. Christine Zardecki, Shuchismita Dutta, David S. Goodsell, Robert Lowe, Maria Voigt, Stephen K. Burley. (2022) Protein Science 31: 129-140 https://doi.org/10.1002/pro.4200. CC By 4.0 license.
Homology Modeling and Artificial Intelligence/Machine Learning
None of the above techniques would be required (except for validation) if the 3D structure of a protein could be determined from its sequence. Computationally this is an astoundingly large problem, given the astronomically large number of possible conformations for a given protein sequence. However, using the nearly 200,000 structures in the PDB database, modern computer methods utilizing artificial intelligence and machine learning have perhaps solved the folding problem. New protein structure prediction programs such as AlphaFold (using a neural network-based model) and RoseTTAFold have led to the solving of structures for which crystals or homologous proteins are not available. A comparison of protein structures obtained using the program with known 3D structures obtained through x-ray crystallography or other techniques are almost identical. Different metrics can be used to compared predicted structures to the actual one. The root mean squared deviation (RMSD) is a common one. For example, developers of RoseTTAFold used a TM-score, a metric for assessing the topological similarity of protein structures. Compared to RMDS, the TM-score weights smaller distance errors higher than larger distance errors and makes it sensitive to the global fold, not local structural differences. TM values range from 0-100 (100 is a perfect match). Scores below 17 indicate no topology match while those greater than 50 suggest a common fold.
The software is described as a "neural network, meaning it simultaneously considers patterns in protein sequences, how a protein’s amino acids interact with one another, and a protein’s possible three-dimensional structure. In this architecture, one-, two-, and three-dimensional information flows back and forth, allowing the network to collectively reason about the relationship between a protein’s chemical parts and its folded structure". Programs of this type might allow the generation of proteins with new therapeutic or commercial potential just based on sequences. These include vaccines, sensors, specific immune system suppressors or activators, and antivirals.
AlphaFold has now been used to predict the structure of 214 million proteins from more than one million species — essentially all known protein-coding sequences. We have included many AlphaFold iCn3D models throughout this book.
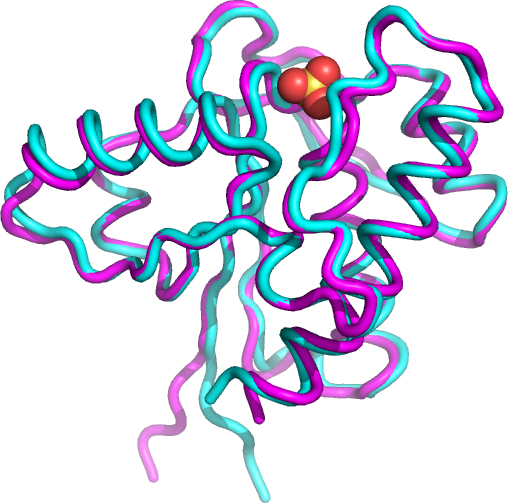
Figure \(\PageIndex{25}\) shows the backbone tube cartoon of the x-ray pdb structure of the small protein (1xww, cyan) and the structure predicted by both RoseTTAFold program and AlphaFold (magenta) just from its primary sequence. Sulfate, a competitive inhibitor, is shown (spacefill) bound in the active site. The alignment is quite spectacular, except for the N-terminal 5 amino acids shown at the very bottom of the figure (6 oclock). This stretch has more disorder even in the x-ray structure as the amino acids have high B-factors, indicating more conformational flexibility.
 |
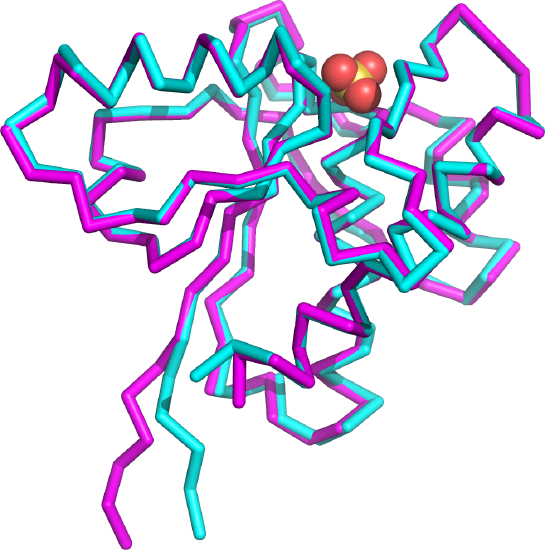 |
Left panel: X-ray structure (cyan) of low molecular weight protein tyrosine phosphatase with bound SO42- (1xww) and corresponding structure predicted by the RoseTTAFold (magenta).
Right panel: Same structures using AlphaFold for the structural prediction.
AlphaFold has also been used to predict the structure of protein complexes in which multiples of the same or of a different protein subunit combine to form a larger, quaternary structure.
In yet another expansion of the use of machine learning and artifical intelligence, programs can now start with a desired 3D shape (protein backbone, for example) and determine the amino acid sequence necessary to get it. One such program is called ProteinMPNN. It allows protein structure design, not structure prediction. In addition, predicted symmetric protein oligomers (about 30% of all proteins in the Protein Data Bank) can also be generated using "deep network hallucination" which requires as input the number of monomers in the structure and the length of the monomer. The "hallucinated structures" are quite different from typical homooligomeric structures found in the PDB, but the predicted structures match well with cryoEM structures of the designed oligomers.
We will explore how large language modules in AI/machine learning are used to predict structure and function in macromolecules and even in the analyses of large interconnected metabolic and signaling pathways in Chapter 4.13: Predicting Structure and Function of Biomolecules Through Natural Language Processing Tools.
Comparisons of 3D Structure Determination Methods
Obtaining a pure, highly concentrated (mM) protein sample is a major bottleneck for both x-ray crystallography and NMR. The high concentration is required because both techniques are insensitive to single molecule analysis, and a large population of a particular protein is required to overcome the signal-to-noise barrier. On a similar note, the sample needs to be very homogenous, so protein purification is necessary at some point. Cryo-EM requires considerably less protein than the other two methods, but still 'a lot' by any standard. Typically, Cryo-EM requires preparations at a concentration of 1 mg/ml in a volume of at least 50 μl, whereas crystal formation might require 500 μl of protein at a concentration of 5 -10 mg/ml. Cryo-Em also requires the protein to be prepared in a low-salt buffer, with minimal additives, to ensure good freezing and image contrast.
Recombinant protein production using E. coli is the method of choice when large quantities of protein are required. This process involves taking the gene (often cDNA) of the protein of interest, splicing it into a suitable inducible vector, transforming the vector into an E. coli host, and growing the culture in a rich medium. The bacterial host will multiply during a growth phase, after which it is induced to express the protein of interest. If all goes well, the protein will express solubly and in high numbers. Unfortunately, this process is easier said than done. Many eukaryotic proteins do not express well in prokaryotic hosts, and oftentimes modifications need to be made to optimize the bacterial host, codon usage, media, etc. to obtain a decent yield of recombinant protein. Additionally, proteins often express insolubly as inclusion bodies and require high concentrations (2M to 8M) of denaturants such as urea or guanidine hydrochloride to solubilize them, and then stepwise dialysis into an appropriate buffer to refold them. Alternatively, eukaryotic organisms such as S. cerevisiae (yeast), insect, and mammalian cell lines can be used, especially when post-translation modifications are required, though a decrease in yield and increase in overall cost is common with these organisms.
The difficulty of protein production is compounded for NMR by the fact that all proteins need to be 15N and/or 13C labeled, as only these isotopes have nuclei with + ½ and - ½ spin states which enable the energy transitions required for a radiofrequency NMR signal; note that 1H also has ½ spin states but is highly abundant.
Protein stability is an issue for both crystallography and NMR. Once a protein has been expressed, purified, and concentrated, it must maintain its structural integrity for the duration of the experiments. For crystallography, this involves the crystallization process, where the protein sample is placed in a variety of solutions (most often involving high concentrations of polyethylene glycol) that induce crystallization. Often referred to as a voodoo technique, crystallization conditions are tested in a high throughput method using 96-well screening plates, and any hits are further optimized using a larger volume of the particular solution. While a crystallization condition may eventually be found, the process can take anywhere from a few days to even a year or two to happen, making the crystallization process the rate-limiting step for protein crystallographers. During this time, the protein must stay in solution and maintain its structure so as to produce a high-quality crystal; a condition that is not often the case.
Similarly, a stable, highly concentrated protein sample is required to perform many of the more advanced NMR experiments. This is because many of these experiments require days and even weeks to run, during which the homogeneity of the solution is key to acquiring quality spectra. Should the protein unfold or precipitate out of solution during an experiment, the resulting chemical change would either not produce any signal, or one which could not be used for structure/dynamics determination.
For Cryo-EM, working with frozen-hydrated specimens brings a number of challenges both for manipulations and imaging. When handling cryo-EM grids to load them into the microscope, exposure to atmospheric water vapor rapidly leads to frost buildup on the grid. Under the TEM, these ice crystals on the grid surface appear as huge boulders that completely block the electron beam. Thus, grids are kept under liquid nitrogen as much as possible to minimize frost contamination. Problems with ice conditions are common—insufficient rapid freezing leads to the formation of hexagonal ice, while devitrification occurs when samples warm up, leading to the formation of cubic ice. Various degrees of contamination may occur, and frosting at atmospheric pressure causes the above-mentioned ice crystal deposition, while contamination within the column or under low-vacuum conditions gives rise to a more subtle artifact.
One of the hallmarks of protein crystallography is that size does not matter. Whether one is working with a 25 kDa monomeric protein, or a 900 kDa multimeric complex, if it can be crystallized and produce a high-resolution diffraction pattern its structure can be determined. This is due to the fact that once in crystal form, a protein is in a more-or-less static conformation which, after passing it through the x-ray beam at different angles, can produce a single structural model. Cryo-EM is similar in this regard. Very large structures, including massive nucleoprotein complexes, such as the ribosome, can be elucidated using Cryo-EM. The same cannot be said for NMR.
In NMR, the protein is in a soluble state and therefore in constant movement. The most important movement that governs the spectral quality is that of the molecular tumbling rate. For proteins larger than about 40 kDa, the tumbling rate decreases significantly, in turn increasing the transverse relaxation rate (T2). Essentially, this results in a weaker and rapidly decaying NMR signal, which manifests itself in peak broadening and spectral overlap.
One of the major advantages of NMR is its ability to record small and large-scale protein dynamics, a phenomenon that is generally suppressed when a protein is crystallized. Although a crystallized protein may exhibit a certain amount of motion within the lattice, the motions manifest themselves as static or dynamic disorder, the former of which may result in two different conformations of a particular region, and the latter in averaged electron density. In general, crystallization may restrict a protein’s natural flexibility and motions. Cryo-EM suffers from this same limitation as samples are frozen and immobile. However, cryo-EM is capable of capturing a snapshot of the native structure as freezing is instantaneous and does not require the formation of a crystal lattice.
Crystallography, however, is not left in the cold when it comes to dynamic structural analysis. Time-resolved crystallography can be used to monitor changes in the protein structure upon the addition of some ligand, or change in the environment. Because all protein crystals are highly hydrated, they are able to serve as crucibles for some biochemical reactions. The crystal is typically soaked in a solution containing the ligand of interest to initiate the biochemical reaction, after which the crystal is quickly placed into the beam line and the diffraction pattern is obtained. This can be performed multiple times if necessary to obtain a variety of structural intermediates. The process though requires many things to go right: the protein cannot become disordered nor should the crystal become cracked during the soaking process, and a high-powered synchrotron is required to collect high-quality diffraction data over short exposure times.
In the end, protein X-ray crystallography, cryo-EM, and NMR spectroscopy are not mutually exclusive techniques; one can easily pick up where the other falls short. In analyzing NMR dynamics experiments, for example, one can greatly benefit from existing crystal structure data, or cryo-EM data onto which the NMR structural data can be superimposed. Similarly, NMR structure data can be used to supplement a cryo-EM or crystal structure with more information on the protein's dynamics, binding information, and conformational changes in solution.
Recent Updates 8/4/23
Molecular Dynamics Simulations
Introduction to Molecular Mechanics and Molecular Dynamics
Molecular modeling and computational chemistry are important parts of modern biochemistry. Modeling is important to display in a meaningful and instructive fashion the large amounts of data produced when X-ray crystallography and NMR are used to determine the structure of large biological molecules and complexes. Remember, however, that primary X-ray crystal data (in the form of electron density maps) are just that, and the data must be interpreted like any other type of data. Structures need to be refined and energy minimized to produce more realistic structures (without van der Waals overlap or missing atoms, for example). In addition, atoms within any molecule are not static, but move as bonds vibrate, angles bend, etc. This implies that large biomolecules could adopt many possible conformations of different energies. For proteins, some of these conformations might center around an average conformation situated at a local or global energy minimum separated from each other by activation energy barriers.
In contrast to small molecules whose structure can be minimized using ab initio or semi-empirical quantum mechanics (using programs such as Spartan), large molecular structures (like DNA, RNA, proteins, and their complexes) must be minimized using molecular mechanics, based on Newton's laws. Atoms are treated as masses, and bonds as springs with appropriate force constants. A force field, containing all the relevant parameters for a given atom (for example sp3, sp2, sp2 aromatic, and sp C) and bond types is used to solve energy equations that sum all energies over all atoms and bonds in the molecule. These energies include interactions among bonded atoms (stretching, bending, torsion, wagging) and those among nonbonded atoms (electrostatic and van der Waals). For minimization calculations, the positions of the atoms within a molecule must be systematically or randomly moved and the energy recalculated with the goal of finding a lower energy and hence more stable molecule. Minimization calculations can not probe all conformational space and can not easily move a structure from a local minimum to a global minimum if two are separated by a large energy barrier. Energy minimizations are usually done in the absence of solvent. Common force fields used for macromolecules are CHARMM, AMBER, and GROMOS. Parameters for specific atom type in a given bond include atomic mass, van der Waals radius, partial charge for atoms (from quantum mechanics) and bond length (from electron diffraction data), angles, and force constants for bonds (modeled as springs, obtained from IR). These parameters are derived from experiments and theoretical (usually quantum mechanical) calculations on small organic molecules. A potential energy equation comprised of terms from bond stretching, angle bending, and torsion angle changes (bonded interactions) as well as electrostatic and van der Waals interactions (nonbonded) is then solved (described below).
The goal of molecular dynamics is to simulate the actual changes in a molecule as a function of time after an energy input (heat application at a higher temperature) is added to a molecule at equilibrium. To make the simulation realistic, the structure is placed in a "bath" of thousands of water molecules. As is described below, if the energies of atoms in a large molecule are known, the forces acting on those atoms can be deduced. From Newton's Second Law (F=ma), the velocity or change of position of an atom in the structure with time can be determined. If the dynamic simulation can be run for a long enough period of time, alternate conformations (perhaps those centered around a global minimum as well as those nearby in energy space - a local minimum) may be sampled. By determining what fraction of the simulated conformations resemble the two alternative conformations, the ΔG for the interconversion of the two states can be calculated. As you can imagine, these calculations require large amounts of computer time. They give very important information, however, since protein conformational changes are often, if not always associated with the binding of a biological molecule to a binding partner. In silico experiments offer important clues and support to results obtained using other methods of study.
Molecular mechanics (MM) and molecular dynamics (MD) have become powerful tools in analyzing and predicting the properties of complex biological structures. The Noble Prize in Chemistry in 2013 was awarded to Martin Karplus, Michael Levitt, and Arieh Warshel "for the development of multiscale models for complex chemical systems". Karplus in particular developed much of the present basis for MD simulations.
Energy (E), Force (F), and Motion
To make the energy equations for the individual components more understandable, it is useful to consider the relationship between force and energy. You have studied two general force equations in introductory chemistry and physics courses. One is Coulomb’s Law, which describes the electrostatic force of attraction, FC, between two charges, q1 and q2, separated by a distance r.
\begin{equation}
F_C=k \frac{q_1 q_2}{r^2}
\end{equation}
The other is Hooke’s Law, which describes the restorative force on a mass connected to a spring on stretching or compression of the spring.
\begin{equation}
F=-k x
\end{equation}
where x is the displacement of the spring from an equilibrium (at rest) position.
Our first interest is to understand how these equations might lead us to equations that describe the potential energy of a two-charge system or of a compressed or stretched spring. We can best understand this by studying the simple example of a ball placed at various locations on a hill. If placed on a flat surface at the top and bottom of the hill, there is no net force on the ball (Fnet = 0), so it will not move. If placed at various locations on the down slope, it will experience a net downward force, shown in a qualitative fashion in Figure \(\PageIndex{26}\) below.

Figure \(\PageIndex{26}\): Potential Energy vs r for a ball on a hill
Astute observers will note that the magnitude of the force vector is proportional to the slope. From this simplistic approach, we come to the following equation relating F to E:
\begin{equation}
F=-\frac{d E}{d r}
\end{equation}
The minus sign is required since the force is downward but the energy increases upward.
This simplified approach can be extended into three dimensions, to give the following equation (which will have meaning to those with advance calculus background) where F is the negative gradient of the potential energy:
\begin{equation}
F=-\left(\frac{\partial}{\partial x}+\frac{\partial}{\partial y}+\frac{\partial}{\partial z}\right) E=-\nabla E
\end{equation}
Applying the 1D equation to Hooke’s Law gives
\begin{equation}
\begin{aligned}
& d E=-F d r=-k x d x \\
& \int d E=-k \int x d x
\end{aligned}
\end{equation}
which gives
\begin{equation}
E=\frac{k x^2}{2}
\end{equation}
This gives a parabolic graph of E vs displacement. Figure \(\PageIndex{27}\) below shows an interactive PHET simulation of Hooke's Law. Click Energy and then select energy to see the parabolic plot. Change the force constant to alter the "steepness" of the resulting parabolic curve.
Figure \(\PageIndex{27}\): PHET simulation of Hooke's Law. https://phet.colorado.edu/en/simulations/hookes-law
The same approach can be applied to Coulomb's Law. Notice that the result equation for E results in increasingly negative values as r get smaller only when q1 and q2 have opposite charges.
\begin{equation}
\begin{aligned}
& d E=-F d r=-k \frac{q_1 q_2}{r^2} d r \\
& \int d E=-k q_1 q_2 \int r^{-2} d r
\end{aligned}
\end{equation}
gives
\begin{equation}
E=\frac{k q_1 q_2}{r}
\end{equation}
![]()
A graph of E vs r for both attractive and repulsive interactions is shown in Figure \(\PageIndex{28}\) below.

Figure \(\PageIndex{28}\): E vs r for both attractive and repulsive interactions
Molecular Mechanics
Note: The following review is based on an NIH Guide to Molecular Modeling (1996), which to the best of our knowledge was removed from the web.
Molecular mechanics uses Newtonian mechanics to calculate energy of atoms in large molecules like proteins. It assumes that nuclei and electrons are one particle with radii and calculated charges. Bonds are treated as springs connecting atoms. Energies are calculated classically (not with quantum mechanics). Parameters, many based on quantum mechanics calculations on small molecules, are assigned to all bonds, angles, dihedrals, etc. Interactions are bonded (local) and nonbonded.
Bonded interactions involved atoms connected by one bond (bond stretch), two bonds (angle bending) and 3 bonds (dihedral angle change). These three types of bonded interactions are shown with black arrows on the right-hand side of Figure \(\PageIndex{29}\) below.
Figure \(\PageIndex{29}\): Bonded and Nonbonded Interactions in Proteins. Force field (chemistry). (2023, July 15). In Wikipedia. https://en.wikipedia.org/wiki/Force_field_(chemistry). CC BY-SA 3.0
Non-bonded atoms (greater than two bonds apart) interact through induced dipole-induced dipole interactions (one example of which is steric repulsions) and electrostatic attraction/repulsion. And example of a nonbonded interaction is shown in the double black arrow labeled Lennard Jones in the above figure.
All energy terms from these interactions are summed to give the energy of a given conformation. The energy should be considered relative to those of other conformations. Here is the basic energy equation for all of these energy terms:
\begin{equation}
\text { Energy }(\mathrm{E})=\mathrm{E}_{\text {Stretch }}+\mathrm{E}_{\text {Bending }}+\mathrm{E}_{\text {Torsion }}+\mathrm{E}_{\text {Non-bonded Interactions }}
\end{equation}
The "force field" consists of the energy equations and the parameters for each of the energy terms. There are many different commercially available force fields.
Bonded Interaction Energies
The mathematical form of the energy terms varies from force-field to force-field. The more common forms will be described.
Stretching (Vibrational) Energy
\begin{equation}
\mathrm{E}_{\text {stretch }}=\Sigma_{\text {bonds }} \mathrm{k}_{\mathrm{b}}\left(r-\mathrm{r}_{\mathrm{o}}\right)^2
\end{equation}
Figure \(\PageIndex{30}\) illustrates bond stretching or vibration

Figure \(\PageIndex{30}\): Bond stretching or vibration
The stretching energy equation is based on Hook's law. The kb parameter defines the stiffness of the bond spring. R0 is the equilibrium distance between the two atoms. It should make sense that deviations from the equilibrium length would be associated with higher energy. The E vs r curve is hence a parabola as shown in Figure \(\PageIndex{3}\) below for a system when the lowest energy is at r=6.

Figure \(\PageIndex{31}\): Energy vs r (r0=6) for bond stretching (vibration)
Obviously, only small changes in r are allowed as too large an r value would lead to bond breaking.
Bending Energy
\begin{equation}
\mathrm{E}_{\text {bending }}=\Sigma_{\text {angles }} k_{\Theta}\left(\Theta-\Theta_0\right)^2
\end{equation}
Figure \(\PageIndex{32}\) illustrates bond bending

Figure \(\PageIndex{3229}\): Bond bending
The bending energy equation is also based on Hooke's law. The kΘ parameter controls the stiffness of the angle spring, while the Θ0 is the equilibrium angle. As above, the graph of E vs theta is expected to be a parabola as shown in Figure \(\PageIndex{33}\) below for a system when the lowest energy is at θ=45

Figure \(\PageIndex{33}\): Ebending vs r when lowest energy is at θ=45.
Torsion Energy
\begin{equation}
E_{\text {torsion }}=\Sigma_{\text {torsions }} A[1+\cos (\text { ntau }-\Theta)]
\end{equation}
Figure \(\PageIndex{34}\) illustrates torsion angle rotation

Figure \(\PageIndex{34}\): Torsion angle rotation
The torsion energy is modeled by a periodic function, much as you have seen with energy plots associated with Newman projections sighting down the central C-C bond in butane, for example. Two different torsion energy functions are shown in Figure \(\PageIndex{35}\) below.

Figure \(\PageIndex{35}\): Torsion energy vs tau for A=1, n=1, phi=0 (blue) and A=1, n=2,phi=90 (orange).
Non-Bonded Interaction Energy
The non-bonded energy is calculated for all possible pairs of nonbonded atoms, i and j:
Enonbonding = Σi Σj [ -Bij/rij6 +A ij/rij12 ] + Σi Σj (qi qj) / rij
\begin{equation}
E_{\text {nonbonding }}=\Sigma_i \Sigma_j\left[-B_{i j} / r_{i j}^6+A_{i j} / r_{i j}^{12}\right]+\Sigma_i \Sigma_j\left(q_i q_j\right) / r_{i j} \mid
\end{equation}
The first term represents van der Waals interactions while the second term represents Coloumbic electrostatic interactions. Figure \(\PageIndex{36}\) illustrated nonbonded interactions.

Figure \(\PageIndex{36}\): Nonbonded interactions
You should remember that induced dipole-induced dipole interactions are short-range and occur among all atoms. The 6-12 energy equation based on the Lennard-Jones' potential, shows a negative (attractive) term proportional to -1/r6 and a repulsive term proportional to +1/r12. Figure \(\PageIndex{37}\) below shows a graph of the attractive, repulsive, and summation of the energy terms in the Lennard Jones potential.

Figure \(\PageIndex{37}\): Lennard Jones potential vs r
The A and B parameters control the depth and position (interatomic distance) of the potential energy well for a given pair of non-bonded interacting atoms (e.g. C:C, O:C, etc.). In effect, A determins the degree of stickiness of the van der Waals attraction, and B determines the degree of hardness of the atoms (e.g. marshmallow-like, billiard ball-like, etc.).
The B parameter is related to the "stickiness" of the interactions and is related to the polarization of the atoms. B can be obtained from atomic polarizability measurements, or it can be calculated quantum mechanically. The A parameter is empirically derived to fit nonbonded contacts between atoms in crystal structures.
Summary Interactions
Some programs assign charges using rules or templates, especially for macromolecules. In some force fields, the torsional potential is calibrated to a particular charge calculation method (rarely made known to the user). The use of a different method can invalidate the force-field consistency. Sometimes, an additional bonded interaction term, improper dihedrals, is added as illustrated below. The potential for that is given by the following equation:
Eimproper = Σangles kω (ω - ωo)2
\begin{equation}
E_{\text {improper }}=\Sigma \text { angles } k \omega\left(\omega-\omega_0\right)^2
\end{equation}
Molecular Dynamics
This section comes directly from the NIH tutorial:
"In the broadest sense, MD is concerned with molecular motion. Motion is inherent to all chemical processes. Simple vibrations, like bond stretching, and angle bending, give rise to IR spectra. Chemical reactions, hormone-receptor binding, and other complex processes are associated with many kinds of intra- and intermolecular motions.
The driving force for chemical processes is described by thermodynamics. The mechanism by which chemical processes occurs is described by kinetics. Thermodynamics dictates the energetic relationships between different chemical states, whereas the sequence or rate of events that occur as molecules transform between their various possible states is described by kinetics.
Conformational transitions and local vibrations are the usual subjects of molecular dynamics studies. MD alters the intermolecular degrees of freedom in a step-wise fashion, analogous to energy minimization. The individual steps in energy minimization are merely directed at establishing a downhill direction to a minimum. The steps in MD, on the other hand, meaningfully represent the changes in atomic position, ri, over time (i.e. velocity).
Newton's equation (Fi = miai) is used in the MD formalism to simulate atomic motion. The rate and direction of motion (velocity) are governed by the forces that the atoms of the system exert on each other as described by Newton's equation. In practice, the atoms are assigned initial velocities that conform to the total kinetic energy of the system, which in turn, is dictated by the desired simulation temperature. This is carried out by slowly heating the system (initially at absolute zero) and then allowing the energy to equilibrate among the constituent atoms. The basic ingredients of MD are the calculation of the force on each atom, and from that information, the position of each atom through a s specified period of time (typically on the order of picoseconds = 10-12 seconds).
The force on an atom can be calculated from the change in energy between its current position and its position a small distance away. This can be recognized as the derivative of the energy with respect to the change in the atom's position: -dE/dri = Fi.
Energies can be calculated using either MM or quantum mechanics methods. MM energies are limited to applications that do not involve drastic changes in electronic structure such as bond-making/breaking. Quantum mechanical energies can be used to study dynamic processes involving chemical changes. The latter technique is extremely novel and of limited availability.
Knowledge of the atomic forces and masses can then be used to solve for the positions of each atom along a series of extremely small time steps (on the order of femtoseconds). The resulting series of snapshots of structural changes over time is called a trajectory. The use of this method to compute trajectories can be more easily seen when Newton's equation is expressed in the following form
-dE/dri = mia= md2ri/dt2
\begin{equation}
-d E / d r_i=m_i a=m d^2 r_i / d t^2
\end{equation}
In practice, trajectories are not directly obtained from Newton's equation due to the lack of an analytical solution. First, the atomic accelerations are computed from the forces and masses. The velocities are next calculated from the accelerations based on the following relationship:
ai = dvi/dt. Lastly, the positions are calculated from the velocities: vi = dri/dt. A trajectory between two states can be subdivided into a series of sub-states separated by a small time step, delta t (e.g. 1 fs).
The initial atomic positions at time t are used to predict the atomic positions at time t = delta t. The positions at t = delta t are used to predict the positions at t = 2Δt, and so on.
The leapfrog method is a common numerical approach to calculating trajectories based on Newton's equation. The method derives its name from the fact that the velocity and position information successively alternate at ½ time step intervals. MD has no defined point of termination other than the amount of time that can be practically covered.
Here is a molecular dynamics simulation of a small protein module (NTL9) folding.
MD simulations can be used to obtain theoretical values for ΔG and Keq values for conformational changes, binding of small ligands, and changes in protonation states for side chains. This process is based on the idea that the conformations sampled in silico MD simulations reflect those found in vitro (i.e. they are part of the thermodynamically expected and available conformations available to the molecules during normal conformational shifts). This is called the Ergodic Hypothesis. Given the short time spans for MD simulations (limited by computer power) this hypothesis can't apply to the dynamic results unless the sample conformations are close in energy without a large activation energy barrier between them. If it is then the following equation could apply:
\begin{equation}
\begin{aligned}
& \Delta G^0=-R T \ln K_{\text {eq }} \\
& \Delta G^0=-R T \ln P_2 / P_1=-R T \operatorname{ln} f_2 / f_1
\end{aligned}
\end{equation}
where
Pn is the probability of being in a given state and fn is the fraction in a given state.
You will note that none of the potential energy functions use quantum mechanical parameters. This is due, in part, to the complexity of the systems studied. This is beginning to change as more effort is devoted to understanding quantum mechanical aspects of complex bonded systems. New advances in even simple systems can illustrate this point. Take for example ethane. The conformational analysis of this simple molecule is discussed in all organic chemistry books. Plots of energy vs dihedral angle (viewing the molecule down the C-C bond and measuring the angle between C-H bonds on adjacent C atoms) oscillates every 120o. The E is at a maximum when the dihedral angle is 0, 120, 240 and 360o, each representing the eclipsed conformation. It reaches minimums at the staggered (gauche) conformations at 60, 180, and 270o. Why is the eclipsed form higher in energy than the staggered form? All organic books would state that there is greater steric repulsion (of the electron clouds) in the eclipsed forms, which raises their energy compared to the staggered forms? However, Pophristic shows that to be incorrect. For the correct answer, you must turn to quantum mechanics and the phenomena of hyperconjugation. The staggered conformation is energetically favored not since it is less sterically restricted, but since its is a lower energy form due to resonance like stabilization of the σ CH molecular orbitals. There is greater correct phase overlap of σ CH and s* CH molecular orbitals on the adjacent Cs when they are in the staggered conformation than in the eclipsed form.
Proteome Analysis
The proteome is the entire set of proteins that are produced or modified by an organism or system. Proteomics has enabled the identification of ever-increasing numbers of protein. This varies with time and distinct requirements, or stresses, that a cell or organism undergoes. Proteomics is an interdisciplinary domain that has benefited greatly from the genetic information of various genome projects, including the Human Genome Project. It covers the exploration of proteomes from the overall level of protein composition, structure, and activity. It is an important component of functional genomics.
After genomics and transcriptomics, proteomics is the next step in the study of biological systems. It is more complicated than genomics because an organism's genome is more or less constant, whereas proteomes differ from cell to cell and from time to time. Distinct genes are expressed in different cell types, which means that even the basic set of proteins that are produced in a cell needs to be identified.
In the past, this phenomenon was assessed by RNA analysis, but it was found to lack correlation with protein content. Now it is known that mRNA is not always translated into protein, and the amount of protein produced for a given amount of mRNA depends on the gene it is transcribed from and on the current physiological state of the cell. Proteomics confirms the presence of the protein and provides a direct measure of the quantity present.
A cell may make different sets of proteins at different times or under different conditions, for example during development, cellular differentiation, cell cycle, or carcinogenesis. Further increasing proteome complexity, as mentioned, most proteins are able to undergo a wide range of post-translational modifications.
Therefore, a proteomics study may become complex very quickly, even if the topic of study is restricted. In more ambitious settings, such as when a biomarker for a specific cancer subtype is sought, the proteomics scientist might elect to study multiple blood serum samples from multiple cancer patients to minimize confounding factors and account for experimental noise. Furthermore, many proteins undergo post-translational modifications such as phosphorylation. Many of these post-translational modifications are critical to the protein's function. Thus, complicated experimental designs are sometimes necessary to account for the dynamic complexity of the proteome.
References
Molnar, C. and Gair, J. (2013) Antibodies. Chapter in Concepts in Biology, Published by B.C. Open Textbook Project. Available at: https://opentextbc.ca/biology/chapter/23-3-antibodies/
The Human Atlas Project. (2019) Methods. Available at: https://www.proteinatlas.org/learn/method
Uhlén M et al, 2015. Tissue-based map of the human proteome. Science
PubMed: 25613900 DOI: 10.1126/science.1260419
Thul PJ et al, 2017. A subcellular map of the human proteome. Science.
PubMed: 28495876 DOI: 10.1126/science.aal3321
Uhlen M et al, 2017. A pathology atlas of the human cancer transcriptome. Science.
PubMed: 28818916 DOI: 10.1126/science.aan2507
Ahern, K. and Rajagopal, I. (2019) Biochemistry Free and Easy. Published by Libretexts. Available at: https://bio.libretexts.org/Bookshelves/Biochemistry/Book%3A_Biochemistry_Free_and_Easy_(Ahern_and_Rajagopal)/09%3A_Techniques/9.04%3A_Gel_Exclusion_Chromatography.
Magdeldin, S. (2012) Gel Electrophoresis - Principles and Basics. Published by InTech under Creative Commons Attribution 3.0. Available at: https://pdfs.semanticscholar.org/4b93/70ac3946cec6e12c369679c4178a5ef38e61.pdf
Structural Biochemistry/Proteins/X-ray Crystallography. (2018, November 19). Wikibooks, The Free Textbook Project. Retrieved 15:40, August 17, 2019 from en.wikibooks.org/w/index.php?title=Structural_Biochemistry/Proteins/X-ray_Crystallography&oldid=3488057.
UCD: Biophysics 200A (2019) "NMR Spectroscopy vs X-ray Crystallography", Chapter published in Current Techniques in Biophysics. Published by Libretexts and available at: https://phys.libretexts.org/Courses/University_of_California_Davis/UCD%3A_Biophysics_200A_-_Current_Techniques_in_Biophysics/NMR_Spectroscopy_vs._X-ray_Crystallography
Wikipedia contributors. (2019, June 27). Protein purification. In Wikipedia, The Free Encyclopedia. Retrieved 23:32, July 28, 2019, from en.Wikipedia.org/w/index.php?title=Protein_purification&oldid=903657925
Wikipedia contributors. (2019, February 15). Fast protein liquid chromatography. In Wikipedia, The Free Encyclopedia. Retrieved 17:14, August 15, 2019, from en.Wikipedia.org/w/index.php?title=Fast_protein_liquid_chromatography&oldid=883530035
Wikipedia contributors. (2019, July 9). Protein mass spectrometry. In Wikipedia, The Free Encyclopedia. Retrieved 15:27, August 16, 2019, from en.Wikipedia.org/w/index.php?title=Protein_mass_spectrometry&oldid=905547289
Wikipedia contributors. (2019, July 8). Peptide synthesis. In Wikipedia, The Free Encyclopedia. Retrieved 06:13, August 17, 2019, from en.Wikipedia.org/w/index.php?title=Peptide_synthesis&oldid=905401648
Mass Spectral Analysis