
17.1: Details of Eukaryotic mRNA Processing
- Page ID
- 42842

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Eukaryotic mRNA primary transcripts undergo extensive processing, including splicing, capping and, polyadenylation. The steps described here are considered in order of (sometimes overlapping!) occurrence. We begin with splicing, an mRNA phenomenon.
A. Spliceosomal Introns
Bacterial gene coding regions are continuous. The discovery of eukaryotic split genes with introns and exons came as quite a surprise. Not only did it seem incongruous for evolution to have stuck irrelevant DNA in the middle of coding DNA, no one could have dreamt up such a thing! For their discovery of split genes, by Richard J. Roberts and Phillip A. Sharp shared the Nobel Prize for Physiology in 1993. In fact, all but a few eukaryotic genes are split, and some have one, two (or more than 30-50!) introns separating bits of coding DNA, the exons. Splicing is summarized below.
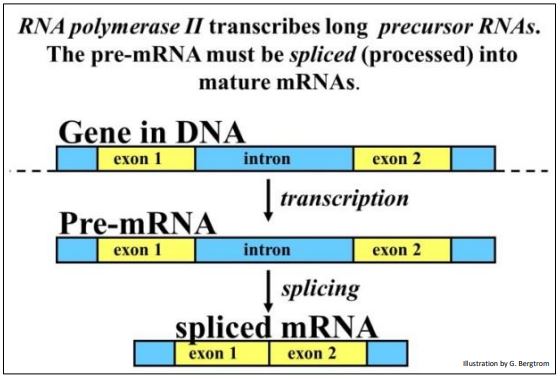
Splicing involves a number of small ribonuclear proteins (snRNPs). snRNPs are particles composed of RNA and proteins. They bind to specific sites in an mRNA and then direct a sequential series of cuts and ligations (the splicing) necessary to process the mRNAs.
The role of snRNPs in splicing pre-mRNAs is illustrated below.
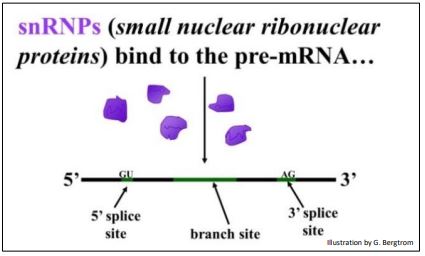
snRNP binding to a pair of splice sites flanking an intron in a pre-mRNA forms the spliceosome that completes the splicing, including removal of the lariat (the intermediate structure of the intron). The last step is to ligate exons into a continuous mRNA with all its codons intact and ready for translation. Spliceosome action is summarized below.
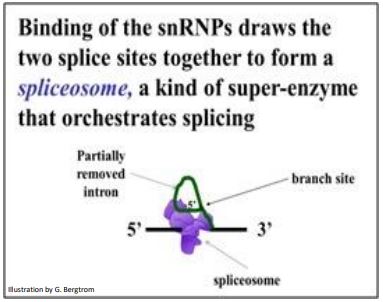
194 The Discovery of Split Genes
B. Specific Nuclear bodies and their associated proteins facilitate the assembly and function of the SnRNPs
Recall the organization of nuclei facilitated by nuclear bodies. Cajal bodies (CBs) and Gems are nuclear bodies that are similar in size and have related functions in assembling spliceosomal SnRNPs. Some splicing defects correlate with mutations in the coil protein that associate with Cajal bodies; others correlate with mutations in SMN proteins normally associated with Gems. An hypothesis was that CBs and Gems interact in SnRNP and spliceosome assembly…, but how? Consider the results of an experiment in which antibodies to coilin and the SMN protein were localized in undifferentiated and differentiated neuroblastoma cells.
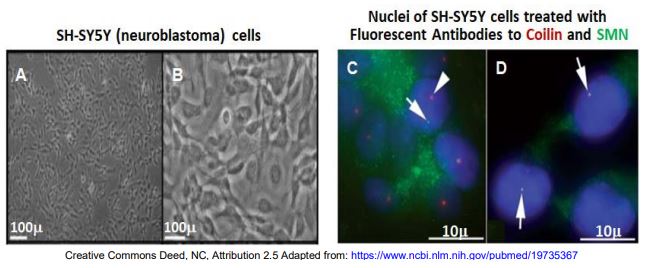
A and C are undifferentiated cells in culture; B and D are cells that were stimulated to differentiate. In the fluorescence micrographs at the right, arrows point to fluorescent nuclear bodies. The coilin protein is associated with CBs and SMN is found in Gems. Therefore, we expect that fluorescent antibodies to coilin (green) will localize to CBs and antibodies to SMN protein (red) will bind to Gems. This is what happens in the nuclei of undifferentiated cells (panel C). But in panel D, the two antibodies colocalize, suggesting that the CBs and Gems aggregate in the differentiated cells. This would explain the need for both functional coilin and SMN protein to produce functional SnRNPs. The CBs and Gems may be aggregating in differentiated cells due to an observed increase in expression of the SMN protein. This could lead to more active Gems more able to associate with the CBs.
This and similar experiments demonstrate that different nuclear bodies do have specific functions. They are not random structural artifacts, have evolved to organize nuclear activities in time and space in ways that are essential to the cell.
C. Group I and Group II Self-Splicing Introns
While Eukaryotic Spliceosomal introns are spliced using snRNPs as described above, Group I or Group II introns are removed by different mechanisms. Group I introns interrupt mRNA and tRNA genes in bacteria and in mitochondrial and chloroplast genes. They are occasionally found in bacteriophage genes, but rarely in nuclear genes, and then only in lower eukaryotes. Group I introns are self-splicing! Thus, they are ribozymes that do not require snRNPs or other proteins. Instead, they fold into a secondary stem-loop structure that positions catalytic nucleotides at appropriate splice sites, excise themselves, and re-ligate the exons. Group II introns in chloroplast and mitochondrial rRNA, mRNA, tRNA and some bacterial mRNAs can be quite long, form complex stem-loop tertiary structures, and self-splice, at least in a test tube! However, Group II introns encode proteins required for their own splicing in vivo. Like spliceosomal introns, they form a lariat structure at an A residue branch site. All this suggests that the mechanism of spliceosomal intron splicing evolved from that of Group II introns.
D. So, Why Splicing?
The puzzle implied by the question of course is why higher organisms have split genes in the first place. While the following discussion can apply to all splicing, it will reference mainly spliceosomal introns. Here are some answers to the question “Why splicing?”
- Introns in nuclear genes are typically longer (often much longer!) than exons. Since they are non-coding, they are large targets for mutation. In effect, noncoding DNA, including introns can buffer the ill effects of random mutations.
- You may recall that gene duplication on one chromosome (and loss of a copy from its homolog) arise from unequal recombination (non-homologous crossing over). It occurs when similar DNA sequences align during synapsis of meiosis. In an organism that inherits a chromosome with both gene copies, the duplicate can accumulate mutations as long as the other retains original function. The diverging gene then becomes part of a pool of selectable DNA, the grist of evolution, in the descendants of organisms that inherit the duplicated genes, increasing species diversity. Unequal recombination can also occur between similar sequences (e.g., in introns) in the same or different genes. Introns can also enable the sharing of exons between genes. After unequal recombination between introns flanking an exon, one gene will acquire another exon while the other will lose it. Once again, as long as an organism retains a copy of the participating genes with original function, the organism can make the required protein and survive. Meanwhile, the gene with the extra exon may produce the same protein, but one with a new structural domain and function. Like a complete duplicate gene, one with a new exon and added function is in the pool of selectable DNA. Thus, this phenomenon of exon shuffling increases species diversity! The evidence indicates that exon shuffling has occurred, creating proteins with different overall functions that nonetheless share at least one domain and one common function. An example discussed earlier involves calcium-binding proteins that regulate many cellular processes. Structurally related calcium (Ca++) binding domains are common to many otherwise structurally and functionally unrelated proteins. Consider exon shuffling in the unequal crossover (non-homologous recombination) illustrated below.
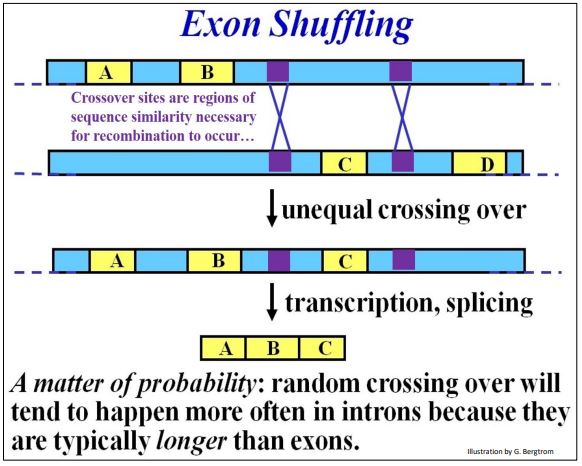
In this example, regions of strong similarity in different (non-homologous) introns in the same gene align during synapsis of meiosis. Unequal crossing over between the genes inserts exon C in one of the genes. The other gene loses the exon (not shown in the illustration). In sum, introns are buffers against deleterious mutations, and equally valuable, are potential targets for gene duplication and exon shuffling. This makes introns key players in creating genetic diversity, the hallmark of evolution.
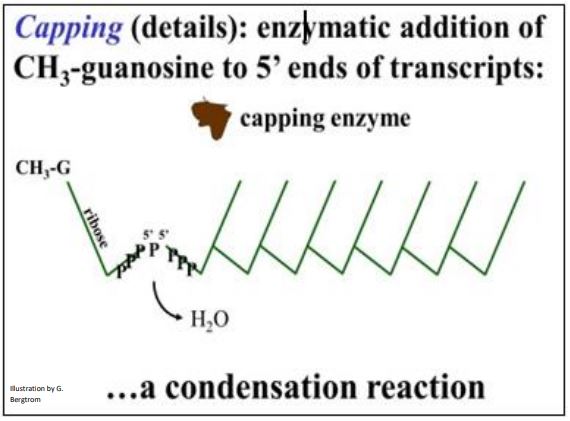
E. Capping
A methyl guanosine cap added 5’-to-5’ to an mRNA functions in part to help mRNAs leave the nucleus and associate with ribosomes. The cap is added to an exposed 5’ end, even as transcription and splicing are still in progress. A capping enzyme places a methylated guanosine residue at the 5’-end of the mature mRNA. The 5’ cap structure is shown below (check marks are 5’-3’ linked nucleotides).
F. Polyadenylation
After transcription termination, poly(A) polymerase catalyzes the addition of multiple AMP residues (several hundred in some cases) to the 3’ terminus by the enzyme. The enzyme binds to an AAUAA sequence near the 3’ end of an mRNA and begins to catalyze the addition of the adenosine monophosphates. The AAUAA poly(A) recognition site is indicated in red in the illustration of polyadenylation shown below.
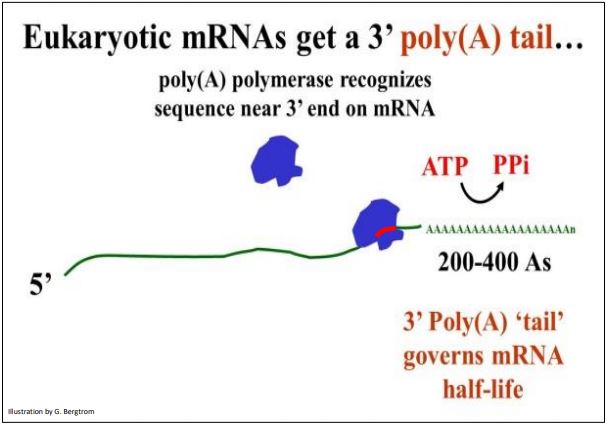
The result of polyadenylation is a 3’ poly (A) tail whose functions include assisting in the transit of mRNAs from the nucleus and regulating the half-life of mRNAs in the cytoplasm. The poly (A) tail shortens each time a ribosome completes translating the mRNA.