
7.1: Case Study: Genetic Similarities and Differences
- Page ID
- 22484

Case Study: Abnormal Cell Division
Like the little children in Figure \(\PageIndex{1}\), seven-year-old Kim is battling leukemia, a type of cancer that affects blood cells. Leukemia usually starts in the bone marrow, where blood cells are produced. It causes the production of abnormal blood cells, most commonly white blood cells, but it can affect other types of blood cells depending on the type of leukemia. The abnormal blood cells replace the patient’s normal blood cells over time. This can lead to symptoms such as fatigue, frequent infections, and easy bruising or bleeding. Leukemia can be fatal, but fortunately, there are some treatment options available that can prolong life and even may cure the disease.

Kim has undergone chemotherapy to kill the cancerous cells, but his doctors have told his parents that it is not enough. Kim needs a bone marrow transplant in order to replace his abnormal bone marrow with healthy bone marrow. His family members are eager to donate bone marrow to him, but first, they must be tested to see if they are a compatible match.
Unlike blood transfusions where it is relatively easy to find a compatible blood donor, bone marrow transplants require much more specific matching between donor and recipient. They must share several of the same types of proteins, called human leukocyte antigens (HLAs), on the surface of their cells. One type of HLA protein is illustrated in Figure \(\PageIndex{2}\). Different people have different types of HLA proteins, or markers, depending on their specific genes. Typically, eight to ten HLA markers are tested and compared in the potential bone marrow donor and recipient. At least six or seven of these HLA markers need to be identical between them in order for a match to be made.
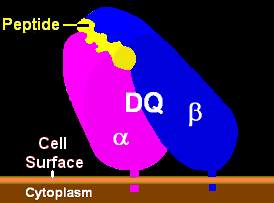
If the match is not good, the patient’s body could reject the bone marrow transplant, or, conversely, the transplanted bone marrow could produce immune cells that attack the patient’s body. A good match between donor and recipient is critical for bone marrow donation to be safe and effective.
A full sibling frequently provides the best match for bone marrow donation because they share many of the same genes from their parents. Kim’s sister is tested, but unfortunately, she is not a match for him. This is not all that surprising since there is only about a 25% chance that a sibling will be an identical HLA match. His parents and other family members are also tested, but none of them is a match either. Kim must join the 70% of patients that need to look outside of their families for a bone marrow donor.
Read the rest of this chapter to learn more about how cells originate from cells. Why one damaged cell gives rise to more damaged cells which can lead to diseases like cancer. You will also learn why not every cell becomes cancerous and why cancerous cells divide uncontrollably. You will also learn why two siblings are not exact copies of each other.
Chapter Overview: Cell Reproduction
In this chapter, you will learn about:
- The phases of the cell cycle and how cells divide through mitosis.
- How cancer can result from an unregulated cell division due to a mutation.
- Sexual reproduction.
- Differences and similarities between sexual and asexual reproduction.
As you read the chapter, think about the following questions:
- How cancer originates?
- Why every person doesn't have cancer?
- How chemotherapy kills cancerous cells?
- Why Kim's sister and other family members do not have exactly the same HLA markers?
Attributions
- Pediatric patients by National Cancer Institute, public domain via Wikimedia Commons
- HLA-DQ by Pdeitiker, public domain via Wikimedia Commons
- Text adapted from Human Biology by CK-12 licensed CC BY-NC 3.0