
9.2: DNA Replication
- Page ID
- 16465

As we’ve seen, DNA strands have directionality, with a 5’ nucleotide-phosphate and a 3’ deoxyribose hydroxyl end. This is even true for circular bacterial chromosomes…, if the circle is broken! Because the strands of the double helix are antiparallel, the 5’ end of one strand aligns with the 3’end of the other at both ends of the double helix. The complementary pairing of bases in DNA means that the base sequence of one strand can be used as a template to make a new complementary strand. As we’ll see, this structure of DNA created some interesting dilemmas for understanding the biochemistry of replication. The puzzlement surrounding how replication proceeds begins with experiments that visualize replicating DNA.
A. Visualizing Replication and Replication Forks
Recall the phenomenon of bacterial conjugation allowed a demonstration bacterial chromosomes were circular. In 1963, John Cairns confirmed this fact by direct visualization of bacterial DNA. He cultured E. coli cells for long periods on 3Hthymidine (3H-T) to make all of their cellular DNA radioactive. He then disrupted the cells gently to minimize damage to the DNA. The DNA released was allowed to settle and adhere to membranes. A sensitive film was placed over the membrane and time was allowed for the radiation to expose the film. After Cairns developed the autoradiographs, he examined the results in the electron microscope. He saw tracks of silver grains in the autoradiographs (the same kind of silver grains that create an image on film in old-fashioned photography). Look at the two drawings of his autoradiographs on the next page.
Cairns measured the length of the “silver” tracks, which usually consisted of three possible closed loops, or circles. The circumferences of two of these circles were always equal, their length closely predicted by the DNA content of a single, nondividing cell. Cairns therefore interpreted these images to be bacterial DNA in the process of replication. Cairns’ autoradiographs and the measurements that led him to conclude that he was looking at images of bacterial circular chromosomes are illustrated below.

He arranged his autoradiograph images in a sequence (below) to make his point.
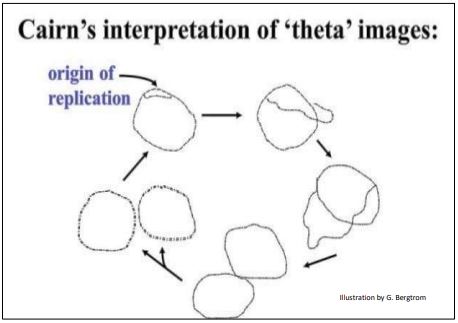
Because the replicating chromosomes looked (vaguely!) like the Greek letter \(\theta \), Cairns called them theta images. He inferred that replication starts at a single origin of replication on the bacterial chromosome, proceeding around the circle to completion.
Subsequent experiments by David Prescott demonstrated bidirectional replication…, that replication did indeed begin at an origin of replication, after which the double helix was unwound and replicated in both directions, away from the origins, forming two replication forks (illustrated below).
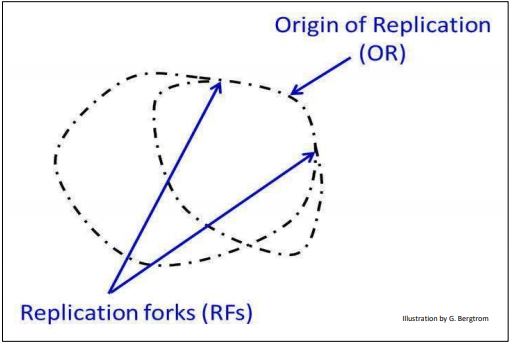
176 Semiconservative Bidrectional Replication From Two RFs
Bacterial cells can divide every hour (or even less); the rate of bacterial DNA synthesis is about 2 X 106 base pairs per hour. A typical eukaryotic cell nucleus contains thousands of times as much DNA as a bacterium, and typical eukaryotic cells double every 15-20 hours. Even a small chromosome can contain hundreds or thousands of times as much DNA as a bacterium. It appeared that eukaryotic cells could not afford to double their DNA at a bacterial rate of replication! Eukaryotes solved this problem not by evolving a faster biochemistry of replication, but by using multiple origins of replication from which DNA synthesis proceeds in both directions. This results in the creation of multiple replicons.
Each replicon enlarges, eventually meeting other growing replicons on either side to replicate most of each linear chromosome, suggested in the illustration below.
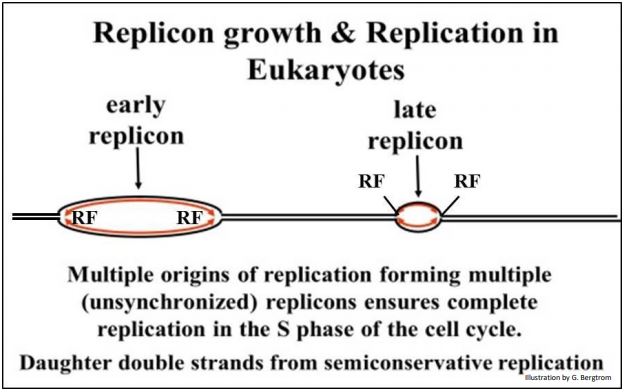
Before we consider the biochemical events at replication forks in detail, let's look at the role of DNA polymerase enzymes in the process.
B. DNA Polymerases Catalyze Replication
The first of these enzymes was discovered in E. coli by Arthur Kornberg, for which he received the 1959 Nobel Prize in Chemistry. Thomas Kornberg, one of Arthur’s sons later found two more of DNA polymerases! All DNA polymerases require a template strand against which to synthesize a new complementary strand. They all grow new DNA by adding to the 3’ end of the growing DNA chain in successive condensation reactions. And finally, all DNA polymerases also have the odd property that they can only add to a pre-existing strand of nucleic acid, raising the question of where the ‘preexisting’ strand comes from! DNA polymerases catalyze the formation of a phosphodiester linkage between the end of a growing strand and the incoming nucleotide complementary to the template strand. The energy for the formation of the phosphodiester linkage comes in part from the hydrolysis of two phosphates (pyrophosphate) from the incoming nucleotide during the reaction. While replication requires the participation of many nuclear proteins in both prokaryotes and eukaryotes, DNA polymerases perform the basic steps of replication, as shown in the illustration below.

178 DNA Polymerases & Their Activities
Although DNA polymerases replicate DNA with high fidelity with as few as one error per 107 nucleotides, mistakes do occur. The proofreading ability of some DNA polymerases corrects many of these mistakes. The polymerase can sense a mismatched base pair, slow down and then catalyze repeated hydrolyses of nucleotides until it reaches the mismatched base pair. This basic proofreading by DNA polymerase is shown below.

After mismatch repair, DNA polymerase resumes forward movement. Of course, not all mistakes are caught by this or other repair mechanisms (see DNA Repair, below). Mutations in the eukaryotic germ line cells that elude correction can cause genetic diseases. However, most are the mutations that fuel evolution. Without mutations in germ line cells (egg and sperm), there would be no mutations and no evolution, and without evolution, life itself would have reached a quick dead end! Other replication mistakes can generate mutations somatic cells. If these somatic mutations escape correction, they can have serious consequences, including the generation of tumors and cancers.
C. The Process of Replication
DNA replication is a sequence of repeated condensation (dehydration synthesis) reactions linking nucleotide monomers into a DNA polymer. Like all biological polymerizations, replication proceeds in three enzymatically catalyzed and coordinated steps: initiation, elongation and termination.
1. Initiation
As we have seen, DNA synthesis starts at one or more origins or replication. These are DNA sequences targeted by initiator proteins in E. coli (below).
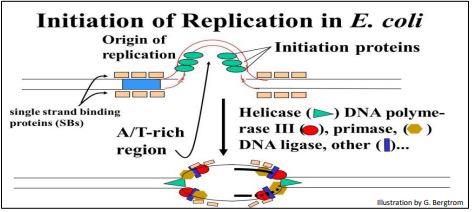
After breaking hydrogen bonds at the origin of replication, the DNA double helix is progressively unzipped in both directions (i.e., by bidirectional replication). The separated DNA strands serve as templates for new DNA synthesis. Sequences at replication origins that bind to initiation proteins tend to be rich in adenine and thymine bases. This is because A-T base pairs have two hydrogen (H-) bonds that require less energy to break than the three H-bonds holding G-C pairs together. Once initiation proteins loosen H-bonds at a replication origin, DNA helicase uses the energy of ATP hydrolysis to unwind the double helix. DNA polymerase III is the main enzyme that then elongates new DNA. Once initiated, a replication bubble (replicon) forms as repeated cycles of elongation proceed at opposite replication forks.
179 Replication Initiation in E. coli
Recalling that new nucleotides can only be added to the free 3' hydroxyl group of a pre-existing nucleic acid strand. Since no known DNA polymerase can start synthesizing new DNA strands from scratch, this is a problem! The action of DNA polymerases therefore requires a primer, a nucleic acid strand to which to add nucleotides. The questions were…, what is the primer and where does it come from? Since RNA polymerases (enzymes that catalyze RNA synthesis) are the only nucleotide polymerase that can grow a new nucleic acid strand against a DNA template from scratch (i.e., from the first base), it was suggested that RNA might be the primer, After synthesis of a short RNA primer, new deoxynucleotides would be added to its 3’ end by DNA polymerase. The discovery of short stretches of RNA nucleotides at the 5’ end of Okazaki fragments confirmed the notion of RNA primers. We now know that cells use primase, a special RNA polymerase active during replication, to make those RNA primers against DNA templates before a DNA polymerase can grow the DNA strands at replication forks. As we will see now, the requirement for RNA primers is nowhere more in evidence in events at a replication fork.
2. Elongation
Looking at elongation at one replication fork (below), we see another problem:
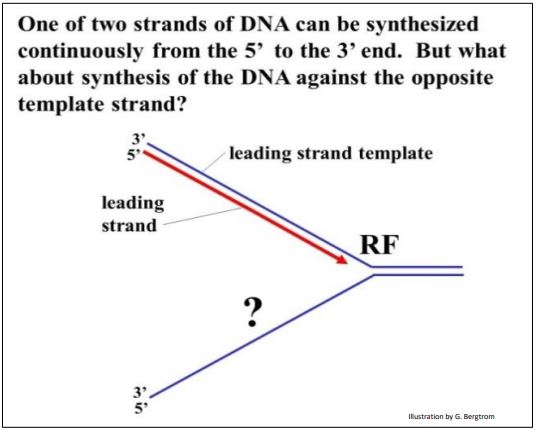
One of the two new DNA strands can grow continuously towards the replication fork as the double helix unwinds. But what about the other strand? Either this other strand must grow in pieces in the opposite direction, or it must wait to begin synthesis until the double helix is fully unwound. If one strand of DNA must be replicated in fragments, then those fragments would have to be stitched (i.e., ligated) together. The problem is illustrated below.
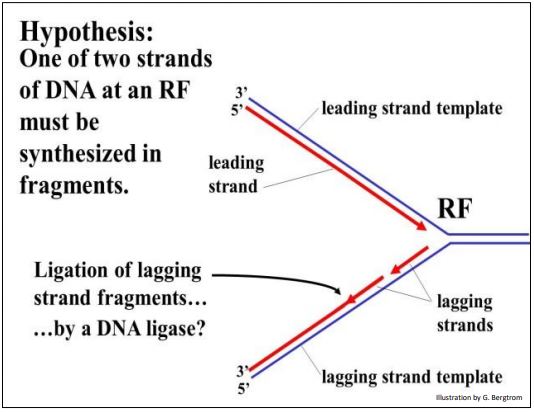
According to this hypothesis, a new leading strand of DNA is lengthened continuously by sequential addition of nucleotides to its 3’ end against its leading strand template. The other strand however, would be made in pieces that would be joined in phosphodiester linkages in a subsequent reaction. Because of the extra step and presumably extra time it takes to make and join these new DNA fragments, this new DNA is called the lagging strand, making its template the lagging strand template.
Reiji Okazaki and his colleagues were studying mutants of T4 phage that grew slowly in their E. coli host cells. They graphed the growth rates of wild-type and mutant T4 phage and demonstrated that slow growth was due to a deficient DNA ligase enzyme, already known to catalyze the circularization of linear phage DNA molecules being replicated in infected host cells. The graph below summarizes their results.
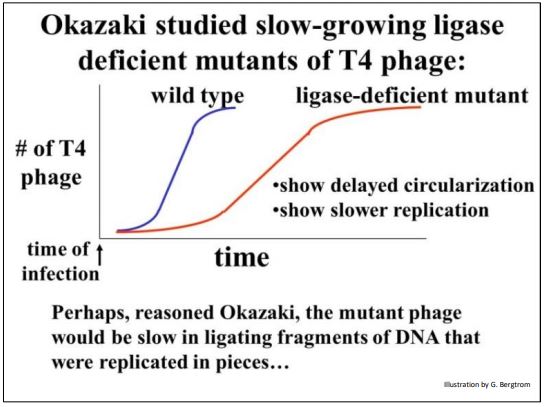
Okazaki’s hypothesis was that the deficient DNA ligase in the mutant phage not only slowed down circularization of replicating T4 phage DNA, but would also be slow at joining phage DNA fragments replicated against at least one of the two template DNA strands. When the hypothesis was tested, the Okazakis found that short DNA fragments did indeed accumulate in E. coli cells infected with ligasedeficient mutants, but not in cells infected with wild type phage. The lagging strand fragments are now called Okazaki fragments.
180 Okazaki Experiments & Fragments - Solving a Problem at an RF
181 Okazaki Fragments are Made Beginning with RNA Primers
You can check out Okazaki’s original research at this link.
Each Okazaki fragment would have to begin with a 5’ RNA primer, creating yet another dilemma! The RNA primer must be replaced with deoxynucleotides before stitching the fragments together. This in fact happens, and the process illustrated below
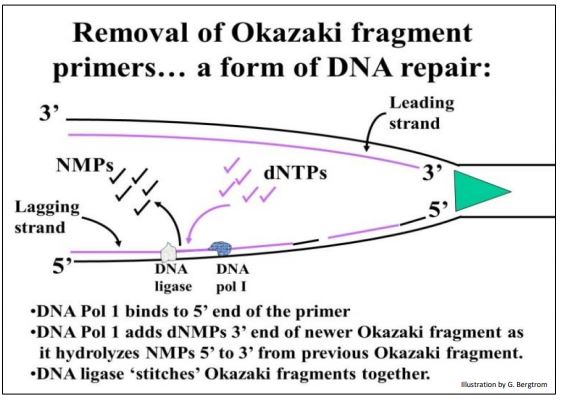
Removal of RNA primer nucleotides from Okazali fragments requires the action of DNA polymerase I, an enzyme that can also catalyze hydrolysis of the phosphodiester bonds between the RNA (or DNA) nucleotides from the 5’-end of a nucleic acid strand. Flap Endonuclease 1 (FEN 1) also plays a role in removing ‘flaps’ of nucleic acid from the 5’ ends of the fragments often displaced by polymerase as it replaces the replication primer. At the same time as the RNA nucleotides are removed, DNA polymerase I catalyzes their replacement by the appropriate deoxynucleotides. Finally, when a fragment is entirely DNA, DNA ligase links it to the rest of the already assembled lagging strand DNA. Because of its 5’ exonuclease activity (not found in other DNA polymerases), DNA polymerase 1 also plays unique roles in DNA repair (discussed further below). As Cairn’s suggested and others demonstrated, replication proceeds in two directions from the origin to form a replicon with its two replication forks (RFs). Each RF has a primase associated with replication of Okazaki fragments along lagging strand templates.
As Cairn’s suggested and others demonstrated, replication proceeds in two directions from the origin to form a replicon with its two replication forks (RFs). Each RF has a primase associated with replication of Okazaki fragments along lagging strand templates.
The requirement for primases at replication forks is shown below.
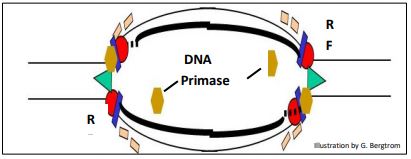
Now we can ask what happens when replicons reach the ends of linear chromosomes in eukaryotes.
3. Termination
In prokaryotes, replication is complete when two replication forks meet after replicating their portion of the circular DNA molecule. In eukaryotes, many replicons fuse to become larger replicons, eventually reaching the ends of the chromosomes…, where there is yet another problem (below)!
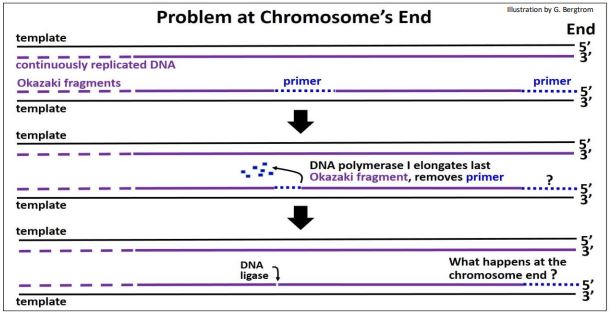
When a replicon nears the end of a chromosome (i.e. a double-stranded DNA molecule), the strand synthesized continuously stops when it reaches the 5’ end of its template DNA. In theory, synthesis of a last Okazaki fragment can be primed from the 3’ end of the lagging template strand. The illustration above implies removal of a primer from the penultimate Okazaki fragment and DNA polymerase catalyzed replacement with DNA nucleotides. But what about the last Okazaki fragment? Would its primer be hydrolyzed? Moreover, without a free 3’ end to add to, how are those RNA nucleotides replaced with DNA nucleotides? The problem here is that every time a cell replicates, one strand of new DNA (likely both) would get shorter and shorter. Of course, this would not do…, and does not happen! Eukaryotic replication undergoes a termination process involving extending the length of one of the two strands by the enzyme telomerase. The action of telomerase is summarized in the illustration below
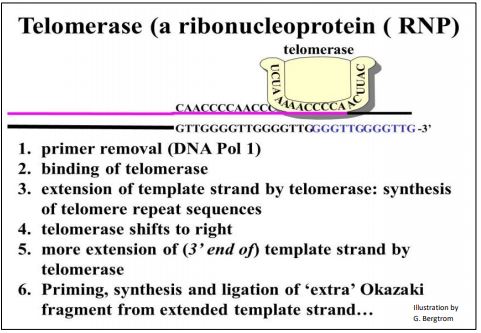
Telomerase consists of several proteins and an RNA. From the drawing,, the RNA component serves as a template for 5’-> 3’ extension of the problematic DNA strand. The protein with the requisite reverse transcriptase activity is called Telomerase Reverse Transcriptase, or TERT. The Telomerase RNA Component is called TERC. Carol Greider, Jack Szostak and Elizabeth Blackburn shared the 2009 Nobel Prize in Physiology or Medicine for discovering telomerase.
183 Telomerase Replication Prevents Chromosome Shorteninghttps://youtu.be/M4dmfrxGKKU
One of the more interesting recent observations was that differentiated, nondividing cells no longer produce the telomerase enzyme. On the other hand, the telomerase genes are active in normal dividing cells (e.g., stem cells) and cancer cells, which contain abundant telomerase.
4. Is Replication Processive?
Drawings of replicons and replication forks suggest separate events on each DNA strand. Yet events at replication forks seem to be coordinated. Replication may be processive, meaning both new DNA strands are replicated in the same direction at the same time, smoothing out the process. How might this be possible? The drawing below shows lagging strand template DNA bending, so that it faces in the same direction as the leading strand at the replication fork.
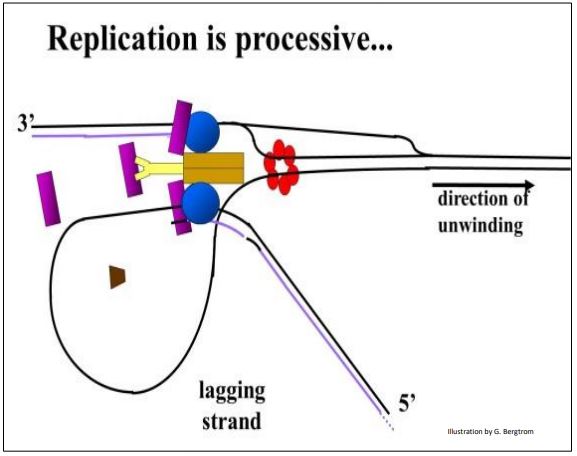
The replisome structure cartooned at the replication fork consists of clamp proteins, primase, helicase, DNA polymerase and single-stranded binding proteins among others.
Newer techniques of visualizing replication by real-time fluorescence videography call the processive model into question, suggesting that the replication process is anything but smooth! Are lagging and leading strand replication not in fact coordinated? Alternatively, is the jerky movement of DNA elongation in the video an artifact, so that the model of smooth, coordinated replication integrated at a replisome still valid? Or is coordination defined and achieved in some other way? Check out the video yourself in the article here.
5. One More Problem with Replication
Cairns recorded many images of E.coli of the sort shown below.

The coiled, twisted appearance of the replicating circles were interpreted to be a natural consequence of trying to pull apart helically intertwined strands of DNA… or intertwined strands of any material! As the strands continued to unwind, the DNA should twist into a supercoil of DNA. Increased DNA unwinding would cause the phosphodiester bonds in the DNA to rupture, fragmenting the DNA. Obviously, this does not happen. Experiments were devised to demonstrate supercoiling, and to test hypotheses explaining how cells relax the supercoils during replication. Testing these hypotheses revealed the topoisomerase enzymes. These enzymes bind and hold on to DNA, catalyze hydrolysis of phosphodiester bonds, control unwinding of the double helix, and finally catalyze the re-formation of the phosphodiester linkages. It is important to note that the topoisomerases are not part of a replisome, but can act far from a replication fork, probably responding to the tensions in overwound DNA. Recall that topoisomerases comprise much of the protein lying along eukaryotic chromatin.
185 Topoisomerases Relieve Supercoiling During Replication
We have considered most of the molecular players in replication. Below is a list of the key replication proteins and their functions (from here).
| Enzyme | Function in DNA Replication |
| DNA Helicase | Also known as helix destabilizing enzyme. Unwinds the DNA double helix at the Replication Fork. |
| DNA Polymerase |
Builds a new duplex DNA strand by adding nucleotides in the 5' to 3' direction. Also performs proof-reading and error correction. |
| DNA clamp | A protein which prevents DNA polymerase III from dissociating from the DNA parent strand. |
| Single-Strand Binding (SSB) Proteins | Bind to ssDNA and preven the DNA double helix from re-annealing after DNA helicase unwinds it thus maintaining the strand separation. |
| Topoisomerase | Relaxes the DNA from its super-coiled nature. |
| DNA Gyrase | Relieves strain of unwinding by DNA helicase; this is a specific type of topoisomerase |
| DNA Ligase | Re-anneals the semi-conservative strands and joins Okazaki Fragments of the lagging strand |
| Primase | Provides a starting point of RNA (or DNA) for DNA polymerase to begin synthesis of the new DNA strand. |
| Telomerase | Lengthens telomeric DNA by adding repetitive nucleotide sequences to the ends of eukaryotic chromosomes. |