
8.3: Nucleic Acids - Comparison of DNA and RNA
- Page ID
- 102278


\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)-
Explain Chemical Modifications:
- Describe how intentional chemical modifications—such as methylation and hydroxymethylation—alter the structure and function of DNA and RNA, including their roles in regulating transcription and translation.
-
Distinguish Epigenetic Versus Epitranscriptomic Changes:
- Compare how DNA methylation (and histone modifications) contribute to epigenetic regulation, while analogous modifications in RNA contribute to the emerging field of epitranscriptomics.
-
Analyze Mutation Mechanisms:
- Explain how spontaneous chemical reactions, such as the hydrolytic deamination of cytosine, lead to point mutations and discuss the role of repair enzymes (e.g., uracil-DNA glycosylases) in maintaining genomic integrity.
-
Evaluate the Impact of Chemical Agents:
- Assess how external mutagens (like nitrous acid and alkylating agents) cause point mutations and structural rearrangements in DNA, and predict their potential consequences for genomic stability.
-
Compare Uracil and Thymine Roles:
- Discuss the chemical rationale behind using uracil in RNA and thymine in DNA, emphasizing the stabilizing effect of the methyl group in thymine to prevent erroneous repair of deaminated cytosine.
-
Examine Backbone Linkage Chemistry:
- Evaluate why DNA and RNA employ phosphodiester bonds instead of alternative linkages (e.g., carboxylic acid esters or amides) and how the chemical properties of these bonds contribute to the stability and overall structure of nucleic acids.
-
Understand Sugar Structure and Flexibility:
- Describe how the presence or absence of a 2'-OH group in ribose versus deoxyribose influences molecular stability, backbone flexibility, and the ability to form extended double-helical structures.
-
Interpret Sugar Puckering and Helical Conformations:
- Analyze the effects of ribose puckering (C3'-endo vs. C2'-endo) on the formation of A-RNA versus B-DNA helices, and explain how these conformational differences affect nucleic acid-protein interactions.
-
Differentiate Base Pairing Modes:
- Contrast Watson-Crick and Hoogsteen base pairing in DNA, discuss how their dynamic equilibrium is influenced by structural modifications, and understand the implications for protein recognition and damaged DNA repair.
-
Integrate Structure-Function Relationships:
- Synthesize the comparative structural features of DNA, RNA, and proteins to explain how these differences have been evolutionarily selected to optimize genetic information storage, replication fidelity, and catalytic activity.
These goals are intended to guide your study of how subtle chemical differences in nucleic acids impact their structure, stability, and biological functions, thereby deepening your understanding of molecular biology at a fundamental level.
Now that we understand the structures of DNA and the structures and various functions of RNA, we can more fully explore how their chemical similarities and differences contribute to different functions.
Chemical modifications of DNA and RNA
Post-translational modifications of proteins alter their structural/functional properties. Likewise, intentional chemical modifications of nucleic acid bases alter both their structures and potentially their transcriptional and translational status. Figure \(\PageIndex{1}\) shows common modifications of bases in DNA.

Likewise, RNA is chemically modified. Figure \(\PageIndex{2}\) shows common modifications of bases in RNA. Methylation and subsequent hydroxylation to hydroxymethyl are common to both DNA and RNA. Methylation of DNA often represses the transcription of the DNA into RNA. Hence, it has huge potential to alter gene transcription. Such changes to the DNA are called epigenetic modifications. These changes can also be passed down to future generations and affect a cell's phenotype. Histone proteins involved in DNA packing into nucleosomes can also be methylated and acetylated, altering the interaction of the DNA with the nucleosome core and further packing, again affecting transcription.

Chemical modification to RNA can also change the reading of the genome. The epitranscriptome refers to the collective chemical modifications to RNA, and its understanding is part of a new field, epitranscriptomics.
Mutations
A mutation can arise from the chemical modification of bases. Uracil in RNA is a demethylated form of thymine in DNA. In RNA, AU base pairs replace AT base pairs. Why is there a need for uracil in RNA? The question could be rephrased as to why there is a need for thymine, with its extra methyl group, in DNA. It's useful to think about the consequences of replacing a single H in a molecule with a -CH3. Take HOH (i.e., water) as an example. Our bodies are over 60% water. We drink liters of water with a concentration of 55 M each day. Yet if we drink 0.07 L of methanol (CH3OH), half of us would die! Let's probe some consequences of the U (no -CH3) and T (with -CH3) changes in DNA. It can get confusing, but remember that the normal base pairs in DNA are AT, but AU base pairs also form (they are the norm in RNA). The -CH3 substituent on thymine does not affect its base pairing.
a. Spontaneous deamination of cytosine in DNA
Why are we now discussing cytosine in DNA? One reason is that the most common mutation in DNA is a C to T replacement. One way that happens is through the spontaneous hydrolytic deamination of cytosine in DNA to uracil, which we have presumed to be found only in RNA. The mechanism for this deamination and subsequent conversion of a GC to an AT base pair is shown in Figure \(\PageIndex{3}\). The inset box shows a simplified mechanism for spontaneous deamination.

Hence, a possible consequence of the deamination reaction is a GC to AT base pair mutation if the uracil in DNA is not removed before DNA replication. Fortunately, the enzyme uracil-DNA glycosylases can remove any uracils found in DNA, leaving an abasic site, which can be fixed with DNA repair enzymes.
We can now ask why T and not U in DNA. Pretend you are a DNA repair enzyme and see a UA base pair in DNA. How can you tell if the UA base pair is correct and intended to be there or if it should be a CG base pair that underwent deamination? The most common uracil-DNA glycosylases remove the uracil whether it is across from guanine, the correct base but which can not hydrogen bond with uracil (in the green oval in Figure \(\PageIndex{3}\)), or if it is across from adenine, the wrong base (in red oval), which is present after a round of replication. Evolution has addressed this problem by adding a methyl group to uracil to form thymine and using that base, which forms a base pair with adenine. Now, no decision on which base across from a uracil (guanine if the uracil arose from deamination) or across from a "uracil-like" thymine (adenine) is correct.
b. Other mutations
Since we are considering chemical modifications to DNA and mutations, giving a more expanded background on them is appropriate. In addition to mutations caused by spontaneous hydrolytic cytosine deamination, mutations can also arise by adding a wrong base during DNA replication, by chemical damage caused by radiation or chemical modifying agents. How many mistakes in replication are made? You would be ecstatic if you received a 99% on an examination. That's not good enough for DNA replication. In Cell Biology by the Numbers, they calculate it this way. Assume the replication /repair is so good that it takes 108 replications to make a mistake (an error rate of 10-8/BP). Assume also that there are 3 x 109 base pairs in the human genome. This leads to a mutation rate of 10-100 mutations/genome/generation or about 0.1-1 mutations/genome/replication. Not bad!
Figure \(\PageIndex{4}\) shows how common point mutations might randomly arise.

Chemical agents can also cause point mutations. Figure \(\PageIndex{5}\) shows point mutations arising from oxidative deaminations (not hydrolytic) by nitrous acid/nitrosamines and from alkylating agents.

Figure \(\PageIndex{6}\) shows a variety of alkylating agents with mutagenic potential.

Finally, large-scale changes in chromosome structure can also occur, as shown in Figure \(\PageIndex{7}\), usually with profound consequences.

Why DNA and RNA - A Chemical Perspective
Asking a "why" question (like above) in the sciences is inappropriate, as teleological questions are more philosophical or religious. Yet we will in this section, in part, to be in the company of Alexander Rich, who wrote a very cool article entitled "Why RNA and DNA have different Structures".
Given that RNA expresses catalytic activities and can carry genetic information (some viruses have ds and ss RNA as their genome), it has been suggested that early life might have been based on RNA. DNA would evolve later as a more secure carrier of genetic information. Inspecting the chemical properties of DNA, RNA, and proteins shows them to have attributes needed for their expressed function. Let's examine each for structural features that might be important for function.
a. Why does DNA lack a 2' OH group (found in RNA), which has been replaced with hydrogen? This required the evolutionary creation of a new enzyme, ribonucleotide reductase, to catalyze the replacement of the OH in a ribonucleotide monomer to form the deoxyribonucleotide form. One possible explanation is offered in the figure below. DNA, the main carrier of genetic information, must be an extremely stable molecule. An OH present on C'2 could act as a nucleophile and attack the proximal P in the phosphodiester bond, leading to a nucleophilic substitution reaction and potential cleavage of the bond. RNA, an intermediary molecule whose concentration (at least as mRNA) should rise and fall based on the need for a potential transcript, should be more labile to such hydrolysis. Figure \(\PageIndex{8}\) shows a possible reaction diagram for the internal cleavage of RNA. (The reaction would probably proceed with no actual intermediate, but just a transition state.

b. Why do both DNA and RNA contain a phosphodiester link between adjacent monomers instead of more "traditional" links such as carboxylic acid esters, amides, or anhydrides? One possible explanation is given below. Nucleophilic attack on the sp3 hybridized P in a phosphodiester is much more difficult than for a more open sp2 hybridized carboxylic acid derivative. In addition, the negative charge on the O in the phosphodiester link would decrease the likelihood of a nucleophilic attack. The negative charges on both strands in ds-DNA probably help keep the strands separated, allowing the traditional base pairing and double-stranded helical structure to be observed. The cleavage of the phosphodiester link in DNA and a hypothetical ester link is shown in Figure \(\PageIndex{9}\). Again, the reaction of the phosphodiester shows a pentavalent intermediate, but most likely, the reaction proceeds directly from the transition state.

c. Why is DNA found as a repetitive double-stranded helix, but RNA is usually found as a single-stranded molecule that can form complicated tertiary structures with some dsRNA motifs?
Another reason for the absence of the 2' OH in DNA is that it allows the deoxyribose ring in DNA to pucker just the right way to allow extended ds-DNA helices (B type). The pucker in deoxyribose and ribose can be visualized by visualizing a single plane in the sugar ring defined by the ring atoms C1', O, and C4'. If a ring atom points in the same direction as the C4'-C5' bond, the ring atom is defined as endo. If it points in the opposite direction, it is defined as exo. In the most common form of double-stranded DNA, B-DNA, the iconic extended double helix, C2' is in the endo form. It can also adopt the C3' endo form, forming another less common helix, a more open ds-A helix. In contrast, steric interference prevents ribose in RNA from adopting the 2'endo conformation. It allows only the 3'endo form, precluding the occurrences of extended ds-B-RNA helices but allowing more open, A-type helices.
Figure \(\PageIndex{10}\) shows another comparison between the A-RNA and B-DNA double helices and the C'3 and C'2 endo forms of the ribose
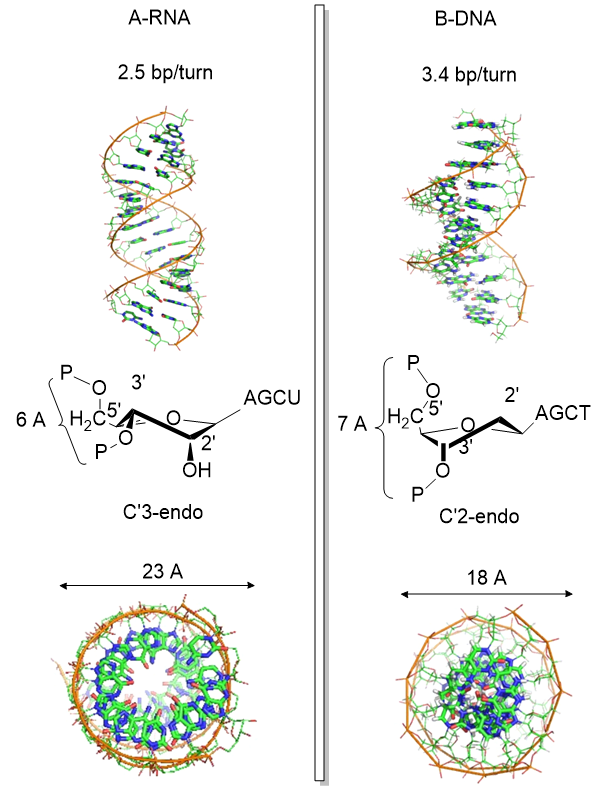
Figure \(\PageIndex{5}\) shows interactive iCn3D models of the pentoses in a strand of A-RNA (413D), double-stranded, left, and B-DNA (1BNA), double-stranded, right.
| C'3-endo ribose, A-RNA (413D, double stranded) | C'2 endo ribose, B-DNA (1BNA, double stranded) |
|
Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...KPueqrBADczh26 |
Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...BEn5nqsCQG2JH6 |
.png?revision=1)
d. What about the molecular dynamics of A-RNA and B-DNA?
The information above suggests that the sugar ring of DNA is conformationally more flexible than the ribose ring of RNA. This can be inferred from the observation that dsDNA can adopt B and A forms, which requires a switch from the 2' endo in the B form to the 3'endo form in the A form. The smaller H on the 2'C would offer less steric interference with such flexibility. The rigidity in ribose is associated with a smaller 5'O to 3'O distance in RNA, leading to a compression of the nucleotides into a helix with a smaller number of base pairs/turn.
The increased flexibility in DNA allows rotation around the C1'-N glycosidic bond connecting the deoxyribose and base in DNA, allowing different orientations of AT and GC base pairs with each other. The normal "anti" orientation allows "Watson-Crick" (WC) base pairing between AT and GC base pairs, while the altered rotation allows "Hoogsteen" (Hoog) base pairs. Figure \(\PageIndex{11}\) shows the different orientations for an AT base pair.

The Watson-Crick (WC) and Hoogsteen (HG) base pairs in B-DNA are in a dynamic equilibrium, with the equilibrium greatly favoring the WC form, as indicated by the arrows in the figure above. In a DNA:protein complex, the WC ↔ HG equilibrium can favor the WG form for AT and GC+ forms (in the latter, the C is protonated) when those base pairs are also involved in protein recognition. They can also occur more frequently in damaged DNA. In contrast, molecular dynamics studies show that the HG base pairs A-U and GC+ are strongly disfavored in ds A-RNA.
One type of DNA damage is methylation on N1-adenosine and N1-guanosine. This modification prevents normal Watson-Crick base pairing, but for DNA, these modified bases can still engage in Hoogsteen base pairing, preserving the overall structure of dsDNA and its ability to carry genetic information stably. This same methylation occurs normally in post-transcriptionally modified RNA. Hence, N1 adenosine and N1 guanosine methylation prevent any base pairing in the modified RNA. These properties make DNA a better carrier of molecular information and offer another way to regulate RNA's structural and functional properties.
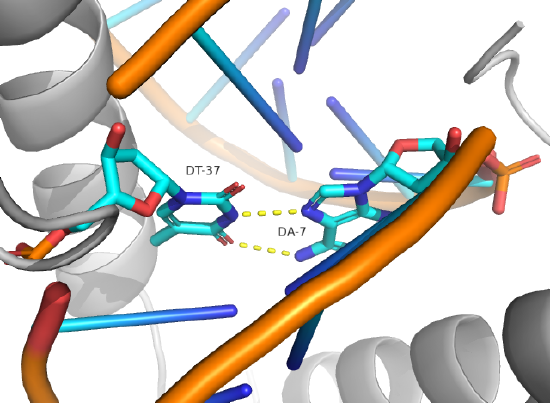
Hoogsteen base pairs can be found in distorted dsDNA structures (caused by protein:DNA interactions) and normal B-DNA. Figure \(\PageIndex{12}\) shows a Hoogsteen base pair between dA7 and dT37 in the MAT α 2 homeodomain:DNA complex (pdb 1K61). Note that the dA base in the Hoogsteen base pair is rotated syn (with respect to the deoxyribose ring) instead of the usual anti, allowing the Hoogsteen base pair.
A Structural Comparison
Now, let's review the structures adopted by the three major macromolecules: DNA, RNA, and proteins. DNA predominantly adopts the classic ds-BDNA structure, although it is wound around nucleosomes and "supercoiled" in eukaryotic cells since it must be packed into the nucleus. Prokaryotic DNA is typically packed into a more amorphous nuclear region, the nucleoid, through interactions with other proteins that also facilitate supercoiling. It is, in effect, a dynamic molecular condensate.
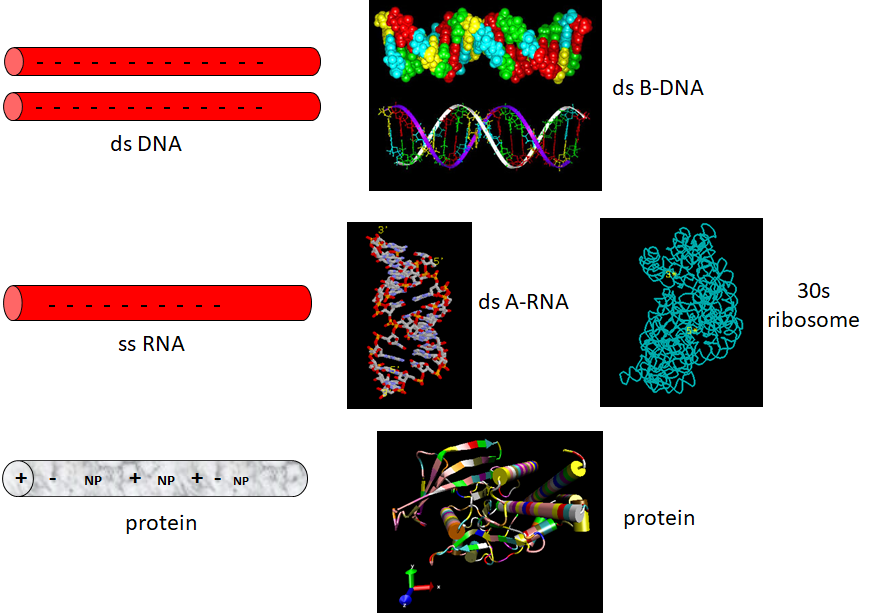
The extended ds-BDNA helical form arises partly from the significant electrostatic repulsions of two strands of this polyanion (even in counter-ions). Given its high charge density, it is unsurprising that it forms complexes with positive proteins and does not adopt complex tertiary structures. RNA, conversely, can not form long B-type double-stranded helices (due to steric constraints of the 2'OH and the resulting 3'endo ribose pucker). Rather, it can adopt complex tertiary conformations (albeit with significant counter-ion binding to stabilize the structure) and, in doing so, can form regions of secondary structure (ds-A RNA) in the form of stem/hairpin forms. Proteins, with their combination of polar charged, polar uncharged, and nonpolar side chains, offer little electrostatic hindrance in adopting secondary and tertiary structures. RNA and proteins can adopt tertiary structures with potential binding and catalytic sites, making them ideal catalysts for chemical reactions. Given its four-nucleotide alphabet, RNA can also carry genetic information, making it an ideal candidate for the first evolved macromolecules enabling the development of life. Proteins with abundant organic functionalities eventually supplanted RNA as a better choice for life's catalyst. DNA, with its greater stability, would supplant RNA as the choice for the primary carrier of genetic information (Figure \(\PageIndex{13}\)):
A final note on the simplicity of the dsDNA structure. A mutation causing a single base pair change in DNA does not change the iconic ds-stranded DNA structure. If it did, DNA would not be a reliable molecule to store and read out the genetic blueprint. In contrast, a single mutation in the DNA leading to a single amino acid substitution may lead to a protein with altered structure and function. This could be deleterious or even fatal to the organism. On the other hand, the new protein structure might have new functionalities that allow adaptation to new environments or allow new types of reactions. Evolution would favor the latter.
Summary
This chapter examines how subtle chemical variations and modifications in nucleic acids—DNA and RNA—lead to distinct structural and functional outcomes that are essential for life. Designed for junior and senior biochemistry majors, the chapter integrates concepts from chemical modifications and mutation mechanisms to explain why DNA and RNA serve different roles in the cell.
Chemical Modifications and Regulation:
Both DNA and RNA undergo intentional chemical modifications that can alter their physical structure and influence gene expression. In DNA, common modifications such as methylation (and subsequent hydroxymethylation) are central to epigenetic regulation. These modifications can repress transcription and are heritable, impacting cell phenotype over generations. RNA modifications, collectively referred to as the epitranscriptome, similarly affect RNA stability, processing, and translation, highlighting the dynamic regulatory potential of these molecules.
Mutation Mechanisms and DNA Repair:
The chapter discusses how chemical modifications can also lead to mutations. For example, the spontaneous hydrolytic deamination of cytosine to uracil in DNA represents a major source of point mutations, potentially converting GC to AT base pairs if not corrected. DNA repair enzymes, such as uracil-DNA glycosylases, play a critical role in identifying and excising these aberrant bases. Additionally, errors during DNA replication and damage induced by chemical agents (e.g., nitrous acid, alkylating agents) contribute to mutations ranging from single base changes to large-scale chromosomal rearrangements.
Structural Basis for Functional Differences:
A significant portion of the chapter is devoted to understanding why DNA and RNA, despite their chemical similarities, adopt very different structures and fulfill distinct roles:
- Sugar Chemistry and Backbone Stability:
DNA’s deoxyribose lacks a 2'-OH group, making it more chemically stable and less prone to self-cleavage compared to RNA, which contains ribose with a reactive 2'-OH. This difference is crucial for DNA’s role as a long-term, reliable repository of genetic information, whereas RNA’s inherent lability suits its function in transient information transfer and catalysis. - Phosphodiester Linkages:
Both nucleic acids use phosphodiester bonds to link nucleotides. The inherent chemical resistance of these bonds to nucleophilic attack—enhanced by their negative charge—contributes to the overall stability of the DNA double helix and the more dynamic secondary and tertiary structures found in RNA. - Sugar Puckering and Helical Forms:
The conformational flexibility of the sugar ring is a key determinant of nucleic acid structure. In DNA, the deoxyribose can adopt different puckers (C2'-endo for B-DNA, C3'-endo for A-DNA), which influences the overall helix geometry. In contrast, the ribose in RNA is more restricted, favoring the C3'-endo conformation, which precludes extended double-stranded helices and promotes the formation of complex tertiary structures. - Base Pairing Dynamics:
The chapter also explores the equilibrium between Watson-Crick and Hoogsteen base pairing in DNA. Although Watson-Crick pairing predominates in stable B-DNA, dynamic shifts to Hoogsteen pairings can occur—particularly in protein-DNA complexes or damaged regions—affecting recognition and repair mechanisms. In RNA, such alternative pairing is less common due to structural constraints imposed by the ribose.
Comparative Structural Overview:
In a broader context, the chapter compares the structural attributes of DNA, RNA, and proteins. DNA’s robust double-helical structure, which is maintained despite mutations, underscores its reliability as a genetic archive. RNA’s versatility in folding into complex structures enables it to perform catalytic and regulatory roles, while proteins, with their diverse side chains, are well-suited to function as dynamic catalysts and structural components. This comparison reinforces the evolutionary specialization of these macromolecules for their respective biological roles.
In summary, the chapter provides a comprehensive exploration of how chemical modifications and intrinsic structural features govern the stability, function, and evolutionary utility of DNA and RNA. Understanding these principles is fundamental for appreciating the molecular basis of gene regulation, mutation, and the overall maintenance of genetic integrity in biological systems.
References
Börner, R., Kowerko, D., Miserachs, H.G., Shaffer, M., and Sigel, R.K.O. (2016) Metal ion induced heterogeneity in RNA folding studied by smFRET. Coordination Chemistry Reviews 327 DOI: 10.1016/j.ccr.2016.06.002 Available at: https://www.researchgate.net/publication/303846502_Metal_ion_induced_heterogeneity_in_RNA_folding_studied_by_smFRET
Hardison, R. (2019) B-Form, A-Form, and Z-Form of DNA. Chapter in: R. Hardison’s Working with Molecular Genetics. Published by LibreTexts. Available at: https://bio.libretexts.org/Bookshelves/Genetics/Book%3A_Working_with_Molecular_Genetics_(Hardison)/Unit_I%3A_Genes%2C_Nucleic_Acids%2C_Genomes_and_Chromosomes/2%3A_Structures_of_Nucleic_Acids/2.5%3A_B-Form%2C_A-Form%2C_and_Z-Form_of_DNA
Lenglet, G., David-Cordonnier, M-H., (2010) DNA-destabilizing agents as an alternative approach for targeting DNA: Mechanisms of action and cellular consequences. Journal of Nucleic Acids 2010, Article ID: 290935, DOI: 10.4061/2010/290935 Available at: https://www.hindawi.com/journals/jna/2010/290935/
Mechanobiology Institute (2018) What are chromosomes and chromosome territories? Produced by the National University of Singapore. Available at: https://www.mechanobio.info/genome-regulation/what-are-chromosomes-and-chromosome-territories/
National Human Genome Research Institute (2019) The Human Genome Project. National Institutes of Health. Available at: https://www.genome.gov/human-genome-project
Wikipedia contributors. (2019, July 8). DNA. In Wikipedia, The Free Encyclopedia. Retrieved 02:41, July 22, 2019, from https://en.Wikipedia.org/w/index.php?title=DNA&oldid=905364161
Wikipedia contributors. (2019, July 22). Chromosome. In Wikipedia, The Free Encyclopedia. Retrieved 15:18, July 23, 2019, from en.Wikipedia.org/w/index.php?title=Chromosome&oldid=907355235
Wikilectures. Prokaryotic Chromosomes (2017) In MediaWiki, Available at: https://www.wikilectures.eu/w/Prokaryotic_Chromosomes
Wikipedia contributors. (2019, May 15). DNA supercoil. In Wikipedia, The Free Encyclopedia. Retrieved 19:40, July 25, 2019, from en.Wikipedia.org/w/index.php?title=DNA_supercoil&oldid=897160342
Wikipedia contributors. (2019, July 23). Histone. In Wikipedia, The Free Encyclopedia. Retrieved 16:19, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Histone&oldid=907472227
Wikipedia contributors. (2019, July 17). Nucleosome. In Wikipedia, The Free Encyclopedia. Retrieved 17:17, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Nucleosome&oldid=906654745
Wikipedia contributors. (2019, July 26). Human genome. In Wikipedia, The Free Encyclopedia. Retrieved 06:12, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Human_genome&oldid=908031878
Wikipedia contributors. (2019, July 19). Gene structure. In Wikipedia, The Free Encyclopedia. Retrieved 06:16, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Gene_structure&oldid=906938498