
8.10: Sanger Sequencing of DNA
- Page ID
- 24787

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Radioactive Chain Termination
The polymerization of nucleic acids occurs in a 5′ → 3′ direction. The 5′ position has a phosphate group while the 3′ position of the hexose has a hydroxyl group. Polymerization depends on these 2 functional groups in order for a dehydration synthesis reaction to occur and extend the sugar-phosphate backbone of the nucleic acid. In the 1970s, Fred Sanger’s group discovered a fundamentally new method of ‘reading’ the linear DNA sequence using special bases called chain terminators or dideoxynucleotides. The absence of a hydroxyl group at the 3′ position blocks the polymerization, resulting in termination. This method is still in use today and is called "Sanger dideoxynucleotide chain-termination method". This method originally used a radioactively labeled primer to initiate the sequencing reaction. Four reactions take place where each reaction is intentionally “poisoned” with a dideoxy chain terminator. For example, one reaction will have all 4 dNTPs (deoxynucleotide triphosphates) with the addition to a small amount of ddATP (dideoxyadenosine triphosphate). This reaction will result in a series of premature terminations of the polymerization specifically at different locations where an Adenine would be incorporated.

dATP is a natural monomer used in the polymerization of DNA. The 3′-OH is the attachment point of the next subsequent nucleotide.
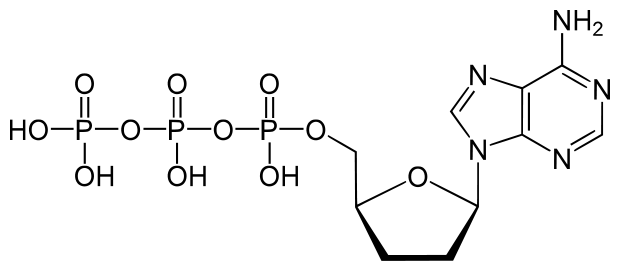
The lack of a 3′-OH in this molecule of ddATP makes it a chain terminator that will prohibit the addition of another nucleotide to the DNA polymer.
The product of these 4 separate sequencing reactions is run on a large polyacrylamide sequencing gels. The smallest fragments run through the gel the fastest and create a ladder-like pattern. This can be visualized through the use of an x-ray film that is sensitive to the radioactivity. Each lane of the gel corresponds to one of the four chain-terminating reactions. The bases are read sequentially from the bottom up and reveal the sequence of the DNA.
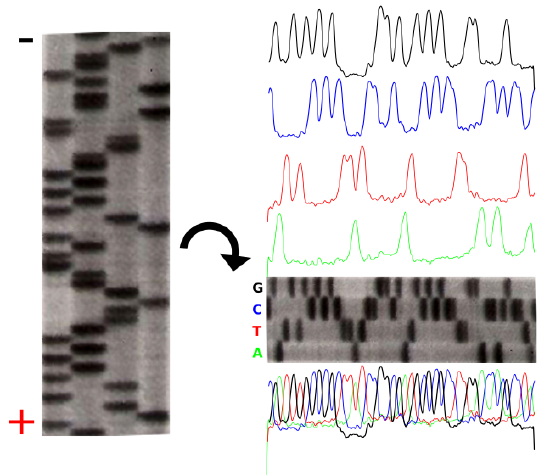
The sequencing gel can be manually scored. The profiles of each lane have been created using ImageJ to illustrate the banding pattern and subsequent sequence.
Credit: John Schmidt & Jeremy Seto (CC-BY-SA 3.0)
Fluorescent Chain Termination and Capillary Electrophoresis

Credit: Estevezj (CC-BY-SA 3.0)
Radioactivity is dangerous and undesirable to work with so chain terminators with fluorescent tags were developed. This method synthesizes a series of DNA strands that are specifically fluorescent at the termination that is passed through a capillary electrophoresis system. As the fragments of DNA pass a laser and detector, the different fluorescent signal attributed to each ddNTP is identified and generates a chromatogram to represent the sequence. Fluorescent Chain Terminators are now used in reactions and run through a small capillary. The smallest fragments run through first and are detected to reveal a chromatogram.
Fluorescent Chromatograms are used to score the nucleotide chain termination. The amplitude of each peak corresponds to the strength or certainty of the nucleotide call. Chromatogram files are usually provided alongside the sequence file with the extension *.ab1 while the sequence files are provided as a text file in the fasta format. More about these files can be found here. The ab1 files are extremely important to analyze when there are ambiguity or sequencing errors. These ab1 files can also be used to ascribe a quality score on the base call.
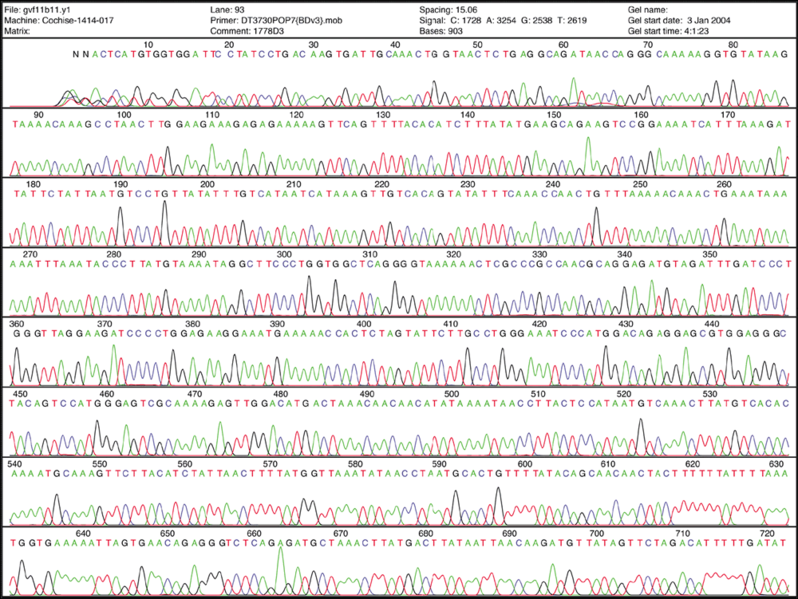
When there is too much ambiguity in the signal because of multiple peaks, you will often find an N in place of one of the 4 nucleotides (A, T, C, and G).
This video (source: www.yourgenome.org CC-BY) illustrates the mechanism of fluorescent chain termination and capillary electrophoresis.
Sequencing Genomes
Credit: Jeremy Seto (CC-BY-NC-SA 3.0)
Traditional sequencing of genomes was a long and tedious process that cloned fragments of genomic DNA into plasmids to generate a genomic DNA library (gDNA). These plasmids were individually sequenced using Sanger sequencing methodology and computational was performed to identify overlapping pieces, like a jigsaw puzzle. This assembly would result in a draft scaffold.
The video below is taken from yourgenome.org (CC-BY) and illustrates the sequencing of the human genome through the shotgun sequencing approach.