
1.11: Nucleic Acids
- Page ID
- 24258

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)(Adapted from http://www.biologycorner.com/)
Part 1: DNA Structure
In 1953, James Watson and Francis Crick established the structure of deoxyribonucleic acid (DNA). The structure is a double helix, which is like a twisted ladder. The sides of the ladder are made of alternating sugar (deoxyribose) and phosphate molecules.
The rungs of the ladder are pairs of 4 types of nitrogen bases. Two of the bases are purines - adenine and guanine. The pyrimidines are thymine and cytosine. The bases are known by their coded letters A, G, T, C. These bases always bond in a certain way: adenine will only bond to thymine and guanine will only bond with cytosine. This is known as the base-pair rule. The bases can occur in any order along a strand of DNA. The order of these bases is unique and codes for specific genes.
The combination of a single base, a deoxyribose sugar, and a phosphate make up a nucleotide. DNA is actually a molecule of repeating nucleotides.
The two strands of DNA are held together loosely by hydrogen bonds. The strands are also antiparallel, meaning that they run parallel but in opposite directions. One strand will go in the 5’ → 3’ direction and one will go 3’ → 5’. The 5’ end has a phosphate group attached and the 3’ end does not.
Materials:
- DNA Puzzle Kits
Note
Before beginning this lab, please confirm that your kit contains the correct materials listed in the table below.
| Number | Component | Color |
| 24 | Phosphate | Yellow |
| 24 | Deoxyribose (Sugar) | Red |
| 12 | Ribose (Sugar) | Pale Pink |
| 4 | Adenine (Base) | Light Green |
| 4 | Thymine (Base) | Light Blue |
| 8 | Cytosine (Base) | Dark Blue |
| 8 | Guanine (Base) | Dark Green |
| 2 | Uracil (Base) | White |
| 2 | Alanine (Amino Acid) | Tan |
| 2 | Glycine (Amino Acid) | Brown |
| 2 | Alanine Activating Enzyme | Tan |
| 2 | Glycine Activating Enzyme | Brown |
| 2 | Alanine-specific tRNA | Tan |
| 2 | Glycine-specific tRNA | Brown |
| 1 | Ribosome Sheet | White Worksheet |
Procedure:
1. Using the materials in your kit, please assemble the longest complete DNA segment you can. In other words, all of the deoxyriboses should be used up! (You may use the photo below as a reference.)
Keep these factors in mind:
- DNA is a double-stranded molecule.
- The double helix is antiparallel.
- DNA includes deoxyribose and thymine.
- Base-pairing rules apply.
2. Once you have assembled your molecule, record it in the space below:
5’ 3’
3’ 5’
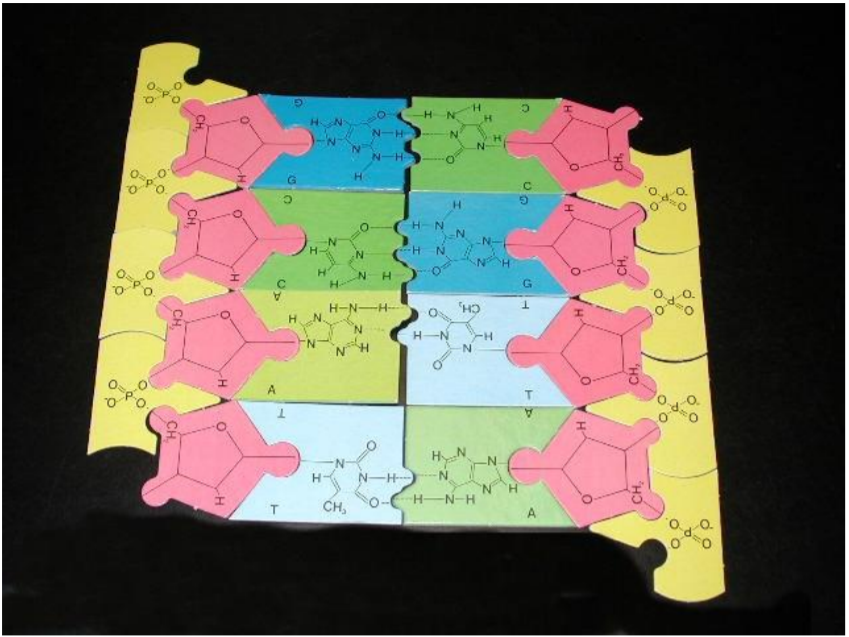
3. Disassemble your DNA molecule.
Part 2: DNA Replication
Replication is the process where DNA makes a copy of itself. Cells divide for an organism to grow or reproduce; every new cell needs a copy of the DNA or instructions to know how to be a cell. DNA replicates right before a cell divides.
DNA replication is semi-conservative. That means that when it makes a copy, one half of the old strand is always kept in the new strand. This helps reduce the number of copy errors.
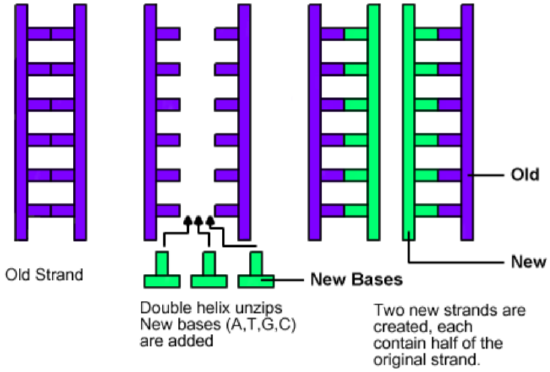
There are a few enzymes involved in DNA replication: RNA primase adds a short segment of RNA to start the new strand. DNA helicase opens up the double helix by breaking hydrogen bonds that hold complementary strands together. A DNA polymerase adds the new nucleotides onto the 3’ end of the growing strand. DNA ligase connects Okazaki fragments on the lagging strand into a continuous molecule.
For simplicity’s sake, an RNA primer will not be used during this activity and the action of the lagging strand will not be modeled.
1. Assemble a new DNA molecule with the following sequence: 5’ GCAT 3’
3’ CGTA 5’
Note
Make sure that your molecule is laid out on the bench exactly as written!
2. Use your hands to mimic the action of DNA helicase (separate the two strands).
3. Build daughter strands using the original molecule as a template.
4. Disassemble your DNA molecules.
Part 3: Transcription
DNA remains in the nucleus, but in order for it to get its instructions translated into proteins, it must send its message to the ribosomes, where proteins are synthesized. The chemical used to carry this message is Messenger RNA (mRNA). 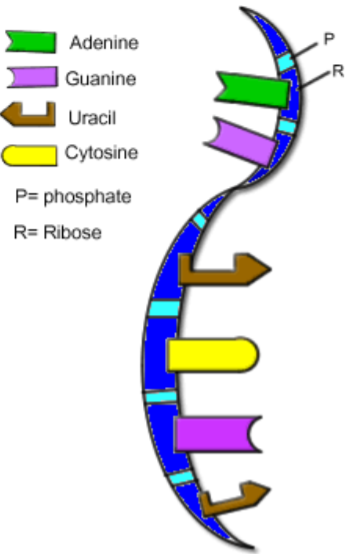
RNA = ribonucleic acid (see figure at right.)
RNA is similar to DNA except:
- RNA is usually single-stranded
- Uracil replaces thymine
- Ribose replaces deoxyribose
During transcription, RNA is made from DNA and proteins are made from the message on the RNA via translation.
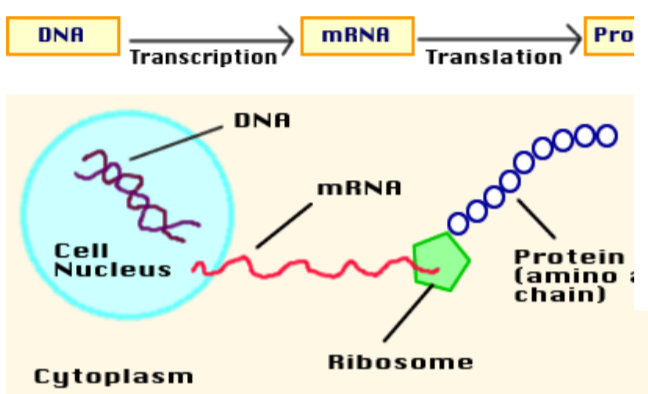
Transcription is similar to DNA replication in that the original DNA molecule is used as a template. RNA polymerase is an enzyme that is able to open up the double helix and add nucleotides onto the new strand of RNA.
1. Assemble half of a new DNA molecule with the following sequence: 3’ CGTCCACGT 5’
Make sure that your molecule is laid out on the bench exactly as written!
Note
We only need one strand as the template since mRNA is single-stranded.
2. Using this as your template, make an RNA copy of this molecule.
Remember:
a. RNA uses ribose
b. RNA uses uracil
3. Record your mRNA molecule:
5’ 3’
4. Leave the complete mRNA molecule alone, it will be used in the next section.
Part 4: Translation
Translation occurs in the cytoplasm, specifically on the ribosomes. The mRNA made in the nucleus travels out to the ribosome to carry the message of the DNA. Here at the ribosome, that message will be translated into an amino acid sequence. The RNA strand threads through the ribosome like a tape measure and the amino acids are assembled.
Important to the process of translation is another type of RNA called Transfer RNA (tRNA) which carries the amino acids to the site of protein synthesis on the ribosome.
A tRNA molecule has two important areas: the anticodon and the amino acid. The anticodon matches the codon on the RNA strand. Codons are sets of three bases that code for a single amino acid.
Connected to the top of the tRNA molecule is the amino acid. There are twenty amino acids that can combine together to form proteins of all kinds, these are the proteins that are used in life processes. Each tRNA has different amino acids, which are linked together like boxcars on a train during the process of translation. 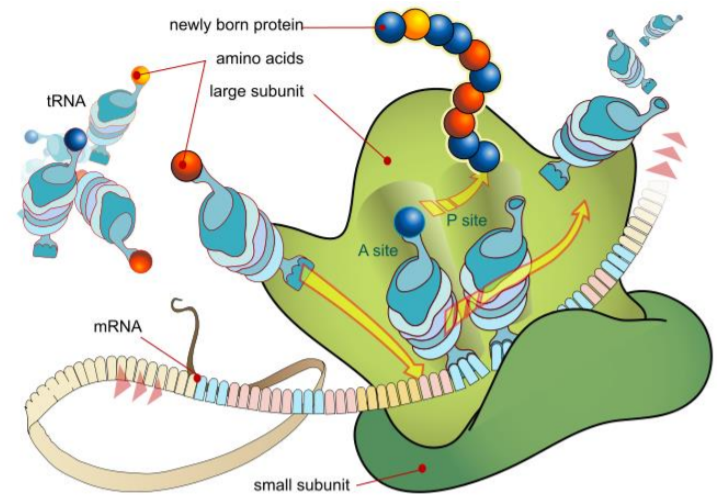
The process of translation: there are 2 tRNA binding sites on the ribosome: P and A. To initiate translation, a tRNA that matches the start codon (AUG) enters the P site. The tRNA that matches the next codon enters into the A site and the amino acid from the tRNA in the P site is attached to the amino acid on the tRNA in the A site. Translocation occurs next; both tRNAs shift over. The tRNA that was in the P site exits the ribosome while the tRNA that was in the A site moves into the P site. Now, the A site is available to bind a tRNA that matches the next codon. This process continues until one of the stop codons enters the A site.
- Place the mRNA molecule from the previous section onto the ribosome sheet. For simplicity sake, we are not going to start at a start codon during this exercise.
- Align the first codon (5’) into the P site of the ribosome and the second codon into the A site.
- Attach the appropriate tRNA and amino acids.
- Detach the amino acid from the tRNA in the P site and attach it to the amino acid on the tRNA in the A site.
- Slide the entire complex (mRNA and attached tRNAs) over and allow the first tRNA to exit.
- Repeat this process until you reach the end of the mRNA. Record your amino acid sequence below.
Part 5: Coding Practice
1. Use this sequence of DNA to answer the following former test questions:
5’-- TTAATGGGACAGCTTGTGTAGAGG --3’
a. What is the complementary strand of DNA?
b. Using the complementary strand of DNA (your answer from part a) as the template strand, what is the transcribed mRNA sequence?
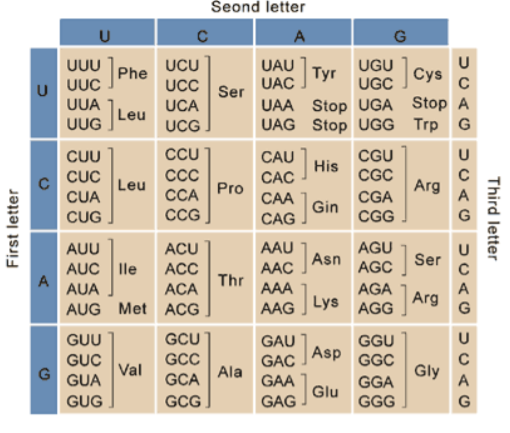
c. What is the amino acid sequence translated from the strand of mRNA synthesized in part b (use the genetic code below)?
Remember:
i. Start codon!
ii. Stop codon!
Additional Images from:
http://www.descrittiva.it/calip/dna/dna03.jpg
http://history.nih.gov/exhibits/nire...S5_cracked.htm.
https://commons.wikimedia.org/wiki/F...File:Ribosome_ mRNA_translation_en.svg