
Winter_2024_Bis2A_Facciotti_Reading_21
- Page ID
- 122801
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Learning Objectives Associated with Winter_2024_Bis2A_Facciotti_Reading_21
GI.48 Compare the similarities and differences between prokaryotic and eukaryotic transcriptional regulatory components (the parts on the DNA and the proteins involved) and the mechanisms that are used for regulating transcription in each case. GI.39 Explain the key differences between bacterial and eukaryotic gene expression. Be sure to include in your explanation the role compartmentalization plays in these differences. GI.23 Describe how eukaryotic gene transcripts are processed before translation and the significance of this for generating functional diversity. ———ABOVE LARGELY ASSOCIATED WITH TRANSCRIPTION: SEE READING 20 ——— GI.19 Differentiate and convert between coding/noncoding, template/non-template strands. GI.20 Define, explain and correctly use the function and structure of an open reading frame (ORF). GI.24 Use a codon table to "translate" an RNA sequence and possible variants of the sequence into a protein sequence. GI.25 Explain what is meant by the genetic code being degenerate. GI.26 Diagram the process of translation. The diagram should include reactants (including the mRNA template and the tRNAs), the products, enzymes, and the sites on the mRNA template required for translation to take place. GI.30 Create a dynamic model of the chemical reaction responsible for protein synthesis and tell its energy story. Then compare this story to the one you prepared for the chemical reactions of DNA synthesis and RNA synthesis. GI.27 Draw a rough sketch of an aminoacyl tRNA synthetase, including its active site and other sites in the enzyme that bind to the reactants. GI.28 Describe the steps in the chemical reaction responsible for tRNA charging and lay out its energy story. GI.29 Discuss how the primary structure of a protein influences its target destination in the cell for both eukaryotic and bacterial organisms. |
Protein Synthesis

Introduction
The process of translation in biology is the decoding an mRNA message into a polypeptide product. Put another way, a message written in the chemical language of nucleotides is "translated" into the chemical language of amino acids. Amino acids are linearly strung together via covalent bonds (called peptide bonds) between amino and carboxyl termini of adjacent amino acids. The decoding and "linking" process is catalyzed by a ribonucleoprotein complex called the ribosomes and can result in chains of amino acids of lengths ranging from tens to over 1,000.
The resulting proteins are so important to the cell that their synthesis consumes more of a cell’s energy than any other metabolic process. Like DNA replication and transcription, translation is a complex molecular process that we can approach using both the Energy Story and Design Challenge rubrics. Describing the overall process, or steps, requires the accounting of the matter and energy before the process and after the process and a description of how that matter is transformed and energy transferred during the process. From a Design Challenge standpoint, we can - even before digging any further into what is or is not understood about translation - try to infer some basic questions that we will need to answer regarding this process.
Let us start by considering the basic problem. We have a strand of RNA (called mRNA) and a bunch of amino acids and we need to design a machine that will somehow:
(a) decode the chemical language of nucleotides into the language of amino acids,
(b) join amino acids in a very specific manner,
(c) complete this process with reasonable accuracy, and
(d) do this at a reasonable speed. Reasonable is defined by natural selection.
As before, we can identify subproblems.
(a) How does our molecular machine determine where and when to work?
(b) How does the molecular machine coordinate decoding and bond formations?
(c) Where does the energy for this process come from and how much?
(d) How does the machine know where to stop?
Other questions and functional problems/challenges will arise as we dig deeper.
The point, as always, is that even knowing no specifics about translation we can use our imaginations, curiosity and common sense to imagine some requirements for the process that we will need to learn more about. Understanding these questions as the context for what follows is key.
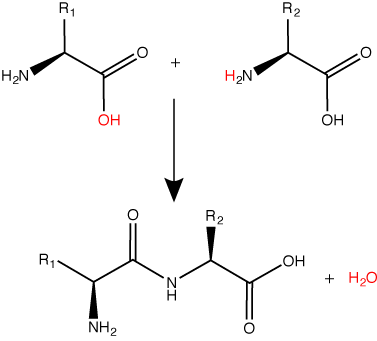
A peptide bond links the carboxyl end of one amino acid with the amino end of another, expelling one water molecule. The R1 and R2 designation refer to the side chain of the two amino acids. Attribution: Marc T. Facciotti (original work).
Protein Synthesis Machinery
The components that go into the process
Many molecules and macromolecules contribute to the process of translation. While the exact composition of "the players" in the process may vary from species to species - for instance, ribosomes may comprise different numbers of rRNAs (ribosomal RNAs) and polypeptides depending on the organism - the general functions of the protein synthesis machinery are comparable from bacteria to human cells. We focus on these similarities. At a minimum, translation requires an mRNA template, amino acids, ribosomes, tRNAs, an energy source, and various additional accessory enzymes and small molecules.
Reminder: Amino acids
Let us recall that the basic structure of amino acids consists of a backbone composed of an amino group, a central carbon (called the α-carbon), and a carboxyl group. Attached to the α-carbon is a variable group that helps determine some chemical properties and reactivity of the amino acid.
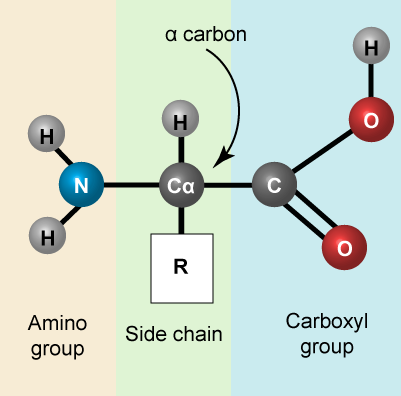
A generic amino acid. Attribution: Marc T. Facciotti (own work)

The 20 common amino acids. Attribution: Marc T. Facciotti (own work)
Ribosomes
A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. As we try thinking about energy accounting in the cell, we note that the ribosomes themselves do not come for "free". Even before an mRNA is translated, a cell must invest energy to build each of its ribosomes. In E. coli, there are between 10,000 and 70,000 ribosomes present in each cell.
Ribosomes exist in the cytoplasm in bacteria and archaea and in the cytoplasm and on the rough endoplasmic reticulum in eukaryotes. Mitochondria and chloroplasts also have their own ribosomes in the matrix and stroma, which look more similar to bacterial ribosomes (and have similar drug sensitivities), than the ribosomes just outside their outer membranes in the cytoplasm. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In E. coli, we describe the small subunit as 30S, and the large subunit as 50S. Mammalian ribosomes have a small 40S subunit and a large 60S subunit. The small subunit binds the mRNA template, whereas the large subunit sequentially binds tRNAs. Many ribosomes can simultaneously translate an individual mRNA molecule, each ribosome synthesizing protein in the same direction: reading the mRNA from 5' to 3' and synthesizing the polypeptide from the N terminus to the C terminus. The complete mRNA/poly-ribosome structure is called a polysome.
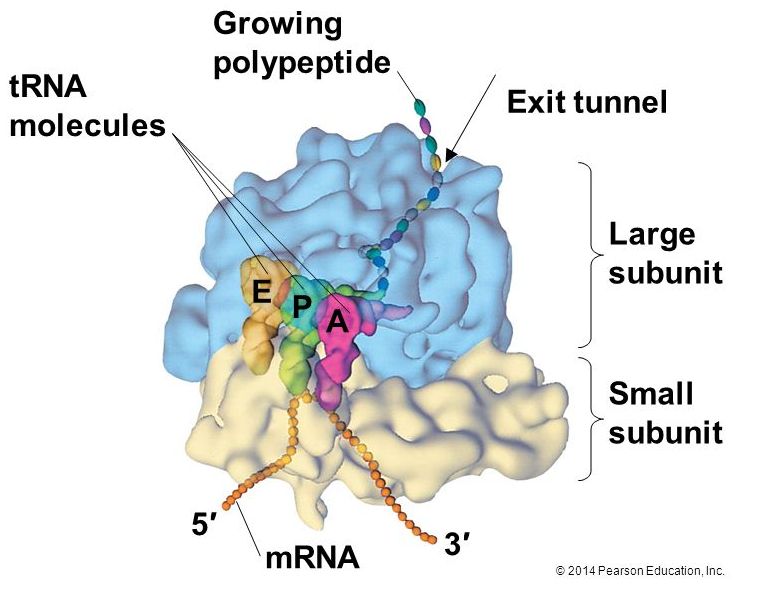
The protein synthesis machinery includes the large and small subunits of the ribosome, mRNA, and tRNA.
Source: http://bio1151.nicerweb.com/Locked/m.../ribosome.html
tRNAs
tRNAs are structural RNA molecules that were transcribed from genes. Depending on the species, 40 to 60 types of tRNAs exist in the cytoplasm. Serving as adaptors, specific tRNAs bind to sequences on the mRNA template and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins.
Of the 64 possible mRNA codons—or triplet combinations of A, U, G, and C, three specify the termination of protein synthesis and 61 specify the addition of amino acids to the polypeptide chain. Of these 61, one codon (AUG) also encodes the initiation of translation. Each tRNA anticodon can base pair with one of the mRNA codons and add an amino acid or terminate translation, according to the genetic code. For instance, if the sequence CUA occurred on an mRNA template in the proper reading frame, it would bind a tRNA expressing the complementary sequence, GAU, which would be linked to the amino acid leucine.
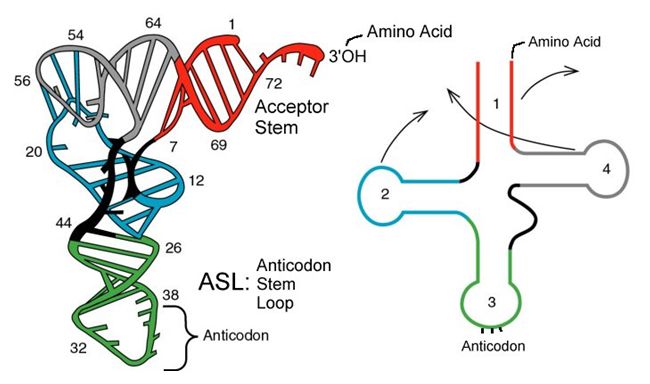
The folded secondary structure of a tRNA. The anticodon loop and amino acid acceptor stem are indicated.
Source: http://mol-biol4masters.masters.grkr...ansfer_RNA.htm
Aminoacyl tRNA Synthetases
The process of pre-tRNA synthesis by RNA polymerase III only creates the RNA portion of the adaptor molecule. The corresponding amino acid must be added later, once the tRNA is processed and exported to the cytoplasm. Through the process of tRNA “charging,” each tRNA molecule is linked to its correct amino acid by a group of enzymes called aminoacyl tRNA synthetases. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids; the exact number of aminoacyl tRNA synthetases varies by species. These enzymes first bind and hydrolyze ATP to catalyze a high-energy bond between an amino acid and adenosine monophosphate (AMP); they expel a pyrophosphate molecule in this reaction. The activated amino acid is then transferred to the tRNA, and AMP is released.
The Mechanism of Protein Synthesis
Like in transcription, we can divide protein synthesis into three phases: initiation, elongation, and termination. The process of translation is similar in bacteria, archaea and eukaryotes.
Translation Initiation
Generally, protein synthesis begins with the formation of an initiation complex. The small ribosomal subunit will bind to the mRNA at the ribosomal binding site. Soon after, the methionine-tRNA will bind to the AUG start codon (through complementary binding with its anticodon). This complex is then joined by large ribosomal subunit. This initiation complex then recruits the second tRNA and thus translation begins.
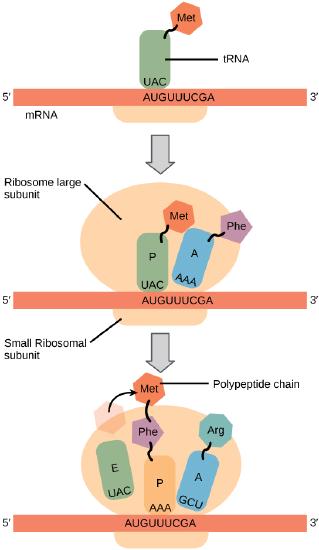
Translation begins when a tRNA anticodon recognizes a codon on the mRNA. The large ribosomal subunit joins the small subunit, and a second tRNA is recruited. As the mRNA moves relative to the ribosome, the polypeptide chain is formed. Entry of a release factor into the A site terminates translation and the components dissociate.
Bacterial vs Eukaryotic initiation
In E. coli mRNA, a sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (AGGAGG), interacts with a rRNA molecule. This interaction anchors the 30S ribosomal subunit at the correct location on the mRNA template. Stop for a moment to appreciate the repetition of a mechanism you've encountered before. Here, getting a protein complex to associate - in proper register - with a nucleic acid polymer is accomplished by aligning two antiparallel strands of complementary nucleotides with one another. We also saw this in the function of telomerase.
Instead of binding at the Shine-Dalgarno sequence, the eukaryotic initiation complex recognizes the 7-methylguanosine cap at the 5' end of the mRNA. A cap-binding protein (CBP) assists the movement of the ribosome to the 5' cap. Once at the cap, the initiation complex tracks along the mRNA in the 5' to 3' direction, searching for the AUG start codon. Many eukaryotic mRNAs are translated from the first AUG, but this is not always the case. According to Kozak’s rules, the nucleotides around the AUG indicate whether it is the correct start codon. Kozak’s rules state that the following consensus sequence must appear around the AUG of vertebrate genes: 5'-gccRccAUGG-3'. The R (for purine) indicates a site that can be A or G, but cannot be C or U. Essentially, the closer the sequence is to this consensus, the higher the efficiency of translation.
Possible NB Discussion  Point
Point
Compare and contrast the initiation of translation with that of transcription — in what ways are these processes similar and in what ways do they differ?
Translation Elongation
During translation elongation, the mRNA template provides specificity. As the ribosome moves along the mRNA, each mRNA codon comes into 'view', and specific binding with the corresponding charged tRNA anticodon is ensured. If mRNA were not present in the elongation complex, the ribosome would bind tRNAs nonspecifically. Note again the use of base pairing between two antiparallel strands of complementary nucleotides to bring and keep our molecular machine in register and in this case also to accomplish the job of "translating" between the language of nucleotides and amino acids.
The large ribosomal subunit comprises three compartments: the A site binds incoming charged tRNAs (tRNAs with their attached specific amino acids), the P site binds charged tRNAs carrying amino acids that have formed bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA, and the E site which releases dissociated tRNAs so they can be recharged with another free amino acid.
Elongation proceeds with charged tRNAs entering the A site and then shifting to the P site followed by the E site with each single-codon “step” of the ribosome. Ribosomal steps are induced by conformational changes that advance the ribosome by three bases in the 3' direction. The energy for each step of the ribosome is donated by an elongation factor that hydrolyzes GTP. Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. The formation of each peptide bond is catalyzed by peptidyl transferase, an RNA-based enzyme that is integrated into the 50S ribosomal subunit. The energy for each peptide bond formation is derived from GTP hydrolysis, which is catalyzed by a separate elongation factor. The amino acid bound to the P-site tRNA is also linked to the growing polypeptide chain. As the ribosome steps across the mRNA, the former P-site tRNA enters the E site, detaches from the amino acid, and is expelled. The ribosome moves along the mRNA, one codon at a time, catalyzing each process that occurs in the three sites. With each step, a charged tRNA enters the complex, the polypeptide becomes one amino acid longer, and an uncharged tRNA departs. Amazingly, this process occurs rapidly in the cell, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino acid polypeptide could be translated in just 10 seconds.
Possible NB Discussion Point
Tetracycline is an antibiotic on the World Health Organization’s List of Essential Medicines. It mitigates infections by blocking the A site on the bacterial ribosome. Another antibiotic, chloramphenicol, blocks peptidyl transfer. Describe the immediate and long-term effects of these two antibiotics. What other strategies can you think of to battle infection specifically at the level of translation?
The Genetic Code
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and uracil (U). Translation of the mRNA template converts nucleotide-based genetic information into a protein product. Protein sequences consist of 20 commonly occurring amino acids; therefore, we can say that the protein alphabet consists of 20 letters. We define each amino acid by a three-nucleotide sequence called the triplet codon. The relationship between a nucleotide codon and its corresponding amino acid is called the genetic code. Given the different numbers of “letters” in the mRNA and protein “alphabets,” means that there are a total of 64 (4 × 4 × 4) possible codons; therefore, an amino acid (20 total) must be encoded for by more than one codon.
Three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5' end of the mRNA. The genetic code is universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all life on Earth shares a common origin.
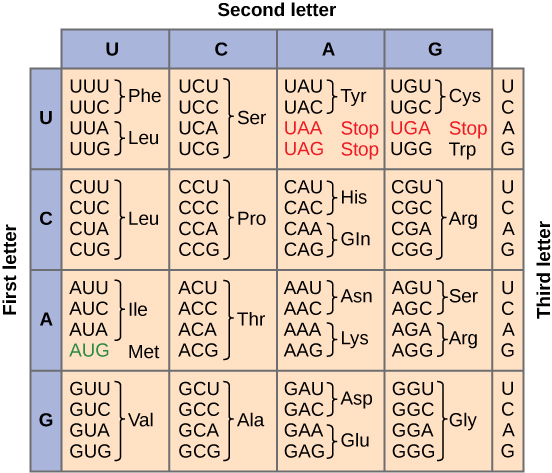
This figure shows the genetic code for translating each nucleotide triplet, or codon, in mRNA into an amino acid or a termination signal in a nascent protein. (credit: modification of work by NIH)
Redundant, not Ambiguous
The information in the genetic code is redundant. Multiple codons code for the same amino acid. For example, using the chart above, you can find 4 different codons that code for Valine, likewise, there are two codons that code for Leucine, etc. But the code is not ambiguous, meaning, that if you were given a codon you would know definitively which amino acid it is coding for, a codon will only code for a specific amino acid. For example, GUU will always code for Valine, and AUG will always code for Methionine. This is important, you will be asked to translate an mRNA into a protein using a codon chart like the one shown above.
Translation Termination
Termination of translation occurs when a stop codon (UAA, UAG, or UGA) is encountered. When the ribosome encounters the stop codon no tRNA enters the A site. Instead, a protein known as a release factor binds to the complex. This interaction destabilizes the translation machinery, causing the release of the polypeptide and the dissociation of the ribosome subunits from the mRNA. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.
Coupling between Transcription and Translation
As discussed previously, bacteria and archaea need not transport their RNA transcripts between a membrane bound nucleous and the cytoplasm. The RNA polymerase is therefore transcribing RNA directly into the cytoplasm. Here ribosomes can bind to the RNA and begin the process of translation, sometimes while transcription is still occurring. The coupling of these two processes, and even mRNA degradation, is facilitated not only because transcription and translation happen in the same compartment but also because both of the processes happen in the same direction - synthesis of the RNA transcript happens in the 5' to 3' direction and translation reads the transcript in the 5' to 3' direction. This "coupling" of transcription with translation occurs in both bacteria and archaea and is, in fact, essential for proper gene expression sometimes.
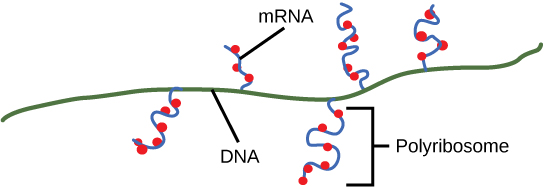
Multiple polymerases can transcribe a single bacterial gene while numerous ribosomes concurrently translate the mRNA transcripts into polypeptides. In this way, a specific protein can rapidly reach a high concentration in the bacterial cell.
Protein Sorting
In the context of a protein synthesis Design Challenge we can also raise the question/problem of how proteins get to where they are supposed to go. We know that some proteins are destined for the plasma membrane, others in eukaryotic cells need to be directed to various organelles, some proteins, like hormones or nutrient scavenging proteins, are intended to be secreted by cells while others may need to be directed to parts of the cytosol to serve structural roles. How does this happen?
Since we have uncovered various mechanisms, the details of this process are not easily summarized in a brief paragraph or two. However, we can mention some key elements common to all mechanisms. First, is the need for a specific "tag" that can provide some molecular information about where the protein of interest is destined for. This tag usually takes the form of a short string of amino acids - a so-called signal peptide - that can encode information about where the protein should end up. The second required component of the protein sorting machinery must be a system to read and sort the proteins. In bacterial and archaeal systems this usually consists of proteins that can identify the signal peptide during translation, bind to it, and direct the synthesis of the nascent protein to the plasma membrane. In eukaryotic systems, the sorting is by necessity more complex, and involves a rather elaborate set of mechanisms of signal recognition, protein modification, and trafficking of vesicles between organelles or the membrane. These biochemical steps are initiated in the endoplasmic reticulum and further "refined" in the Golgi apparatus where proteins are modified and packaged into vesicles bound for various parts of the cell.
Some specific mechanisms may be discussed by your instructor in class. The key for all students it so appreciate the problem and to have a general idea of the high-level requirements that cells have adopted to solve them.
Post-translational Protein Modification
After translation individual amino acids may be chemically modified. These modifications add chemical variation and new properties that are rooted in the chemistries of the functional groups that are being added. Common modifications include phosphate groups, methyl, acetate, and amide groups. Some proteins, typically targeted to membranes, will be lipidated - a lipid will be added. Other proteins will be glycosylated - a sugar will be added. Another common post-translational modification is cleavage or linking of parts of the protein itself. Signal-peptides may be cleaved, parts may be excised from the middle of the protein, or new covalent linkages may be made between cysteine or other amino acid side chains. Enzymes will catalyze nearly all modifications and all change modifications the functional behavior of the protein.
Section Summary
mRNA is used to synthesize proteins by the process of translation. The genetic code is the correspondence between the three-nucleotide mRNA codon and an amino acid. The genetic code is “translated” by the tRNA molecules, which associate a specific codon with a specific amino acid. The genetic code is degenerate because 64 triplet codons in mRNA specify only 20 amino acids and three stop codons. This means that more than one codon corresponds to an amino acid. Almost every species on the planet uses the same genetic code.
The players in translation include the mRNA template, ribosomes, tRNAs, and various enzymatic factors. The small ribosomal subunit binds to the mRNA template. Translation begins at the starting AUG on the mRNA. The formation of bonds occurs between sequential amino acids specified by the mRNA template according to the genetic code. The ribosome accepts charged tRNAs, and as it steps along the mRNA, it catalyzes bonding between the new amino acid and the end of the growing polypeptide. The entire mRNA is translated in three-nucleotide “steps” of the ribosome. When a stop codon is encountered, a release factor binds and dissociates the components and frees the new protein.
POST PRACTICE GUIDE
General Practice
3. Why: The expression of genes to proteins requires multiple steps and a number of genetically encoded “parts” that help direct the process (i.e. promoters, terminators, ribosome binding site etc.). In addition, like all other processes, translation needs to start somewhere. Nature has evolved a couple of mechanisms for the ribosome to assemble in the “right” place for the initiation of translation. The bacterial mechanism is pretty clever, using RNA-RNA base pairing to align the ribosome with a transcript. Practice learning this model to get a longer-term understanding of translation.
How to practice: Translation of bacterial mRNA: In order for sites to end up in a bacterial mRNA molecule, they need to be encoded in the DNA. Otherwise, how could they be present in the mRNA? Therefore, the ribosome binding site and the codons (start, stop and all the codons in between) must be present in the DNA and transcribed to end up in the mRNA. The lining up of the mRNA molecule in the ribosome results in the placement of the AUG in the correct position for translation to begin.
a) Draw a sketch of a bacterial gene that encodes a protein. Then draw the mRNA for the gene. Then draw the protein.
b) Repeat this exercise for a bacterial operon, which is composed of three genes. How many promoters should there be? How many ribosome binding sites, etc?
This exercise helps you practice learning objectives: Learning goals from previous lecture on transcriptional unit structure.; GI.20 Define, explain and correctly use the function and structure of an open reading frame (ORF). (Bacterial)
4. Why: Same rationale as #3.
How to practice: Translation of eukaryotic mRNA: The initiation of translation occurs by a slightly different mechanism in eukaryotes than in bacteria. The 5’ cap of the eukaryotic mRNA is recognized by the ribosome. The ribosome binds the mRNA and scans until it finds the first AUG codon. This is how it decides where to begin translation.
a) Draw a sketch of a eukaryotic gene that encodes a protein. Then draw the pre- mRNA and the mature mRNA for the gene. Then draw the protein.
b) Consider how the eukaryotic ribosome finds the AUG to begin translation. Would this method work on a polycistronic mRNA?
This exercise helps you practice learning objectives: GI.20 Define, explain and correctly use the function and structure of an open reading frame (ORF). (Eukaryotic)
5. Why: The process of protein synthesis is just about the most expensive thing the cell does. Given Nature’s tendency to find ways of minimizing “costs” (it’s usually evolutionarily advantageous) it’s interesting to consider parts of the process that may seem expensive and ask what the trade-offs/benefits might be from the standpoint of natural selection. Thinking about this kind of thing can help us latch on to the core concepts more robustly and build long-term knowledge.
How to practice: Most cells need to invest a lot of energy in making 20 (at least) aminoacyl tRNA synthases. While there are clear costs to making so many of these enzymes, explain some of the potential benefits of expending all of this energy or any costs that are avoided by making this multitude of enzymes.
This exercise helps you practice learning objectives: GI.28 Describe the steps in the chemical reaction responsible for tRNA charging and lay out its energy story.; GI.27 Draw a rough sketch of an aminoacyl tRNA synthetase, including its active site and other sites in the enzyme that bind to the reactants.
6. Why: One of the core mechanisms of translation involves the translation (for lack of a better word) of the genetic code from nucleotide language to amino acid language. This happens using a code (codons) and a key that reads that code (tRNAs). It’s the site where translation happens!
How to practice: Examine the following figure depicting the interaction between mRNA and a tRNA.

a. Write in the orientation of the tRNA base pairs based on the given orientation of the mRNA.
b. Draw an arrow indicating the movement of the ribosome on the mRNA
This exercise helps you practice learning objectives: GI.26 Diagram the process of translation. The diagram should include reactants (including the mRNA template and the tRNAs), the products, enzymes, and the sites on the mRNA template required for translation to take place.
7. Why: More practice on how the code is deciphered.
How to practice: Check out the following interactive website. It allows you to make an mRNA and then use a codon usage table to make a protein. It is very simple, but you might find it helpful. <http://learn.genetics.utah.edu/content/molecules/transcribe/>
This exercise helps you practice learning objectives: GI.24 Use a codon table to "translate" an RNA sequence and possible variants of the sequence into a protein sequence.
8. Why: More practice on how the code is deciphered, but now asking you to link it back one more step to the DNA sequence.
How to practice: Given the following sense strand of DNA sequence, transcribe it into mRNA, showing the orientation of the mRNA [i.e. 3' and 5' ends]. Then translate this sequence into protein [indicating amino and carboxy termini, be sure to check for an open reading frame as well.]
5’-GGGATCGATGCCCCTTAAAGAGTTTACATATTGCTGGAGGCGTTAACCCCGGA-3’
This exercise helps you practice learning objectives: GI.19 Differentiate and convert between coding/noncoding, template/non-template strands.; GI.20 Define, explain and correctly use the function and structure of an open reading frame (ORF).; GI.24 Use a codon table to "translate" an RNA sequence and possible variants of the sequence into a protein sequence.
9. Why: Same as exercise 8 with a few more details. This takes practice.
How to practice: You have just sequenced a short segment of DNA. You wish to analyze this DNA sequence to determine whether it could encode a protein.
5’-TCAATGTAACGCGCTACCCGGAGCTCTGGGCCCAAATTTCATCCACT-3’
a) Find the longest open reading frame (ORF). Remember, there are six possibilities.
b) Label which strand on the DNA will be the sense strand, and which will be antisense when this DNA is transcribed.
c) Transcribe this ORF into mRNA, indicating the 5' and 3' ends.
d) Translate this mRNA into amino acids, indicating the amino (N) and carboxy (C) termini.
This exercise helps you practice learning objectives: GI.19 Differentiate and convert between coding/noncoding, template/non-template strands.; GI.20 Define, explain and correctly use the function and structure of an open reading frame (ORF).; GI.24 Use a codon table to "translate" an RNA sequence and possible variants of the sequence into a protein sequence.
10. Why: In eukaryotes, proteins, once synthesized, need to be sent to the appropriate location in the cell. Think back to earlier in the course when we discussed the benefits of making compartments in big cells and the kinds of costs that this ‘invention’ would impose or need new solutions for. Figuring out how to send proteins to the right place is one of those.
How to practice: Signal sequences (see reading) in polypeptides direct them to their appropriate destinations inside or outside the cell. In addition, many proteins are modified as they go through the ER and Golgi apparatus. How do signal sequences determine where a protein will go? What are some of the post-translational modifications that occur on proteins and where do these modifications take place? What are some of the ways in which post-translational modification alter protein structure and function? (This is knowledge extension for those interested - you may need to do a bit of Googling).
This exercise helps you practice learning objectives: GI.29 Discuss how the primary structure of a protein influences its target destination in the cell for both eukaryotic and bacterial organisms.
11. Continue to fill in the table below.
|
PROCESS |
REPLICATION |
TRANSCRIPTION |
TRANSLATION |
|
TEMPLATE
|
|
|
|
|
RESULTING POLYMER
|
|
|
|
|
MONOMERS USED
|
|
|
|
|
ENZYME(S)
|
|
|
|
|
ENERGY (+ΔG OR –ΔG)
|
|
|
|
|
ENERGY SOURCE
|
|
|
|
|
SITE TO ORIENT THE ENZYME
|
|
|
|
|
DIRECTION TO ADD MONOMERS
|
|
|
|
|
REQUIREMENTS TO CREATE THE FIRST BOND |
|
|
|
|
WHERE TO END THE PROCESS
|
|
|
|
|
HOW IMPORTANT IS FIDELITY/ACCURACY? WHY?
|
|
|
|
Practice Exam Questions
Question Q21.1
Q21.1 In bacteria, the site on the mRNA that binds to the ribosome has a sequence that is complementary to the end of the 16S rRNA present in the small subunit of the ribosome. The sequence of the 16S rRNA is sequence 5’- CCUCCU-3’. Based on this information, which of the following sequences could act as a ribosome binding site?
A. 5’- GGAGGA-3’.
B. 5’- AGGAGG-3’.
C. 5’- CCTCCT-3’
D. 5’- TCCTCC-3’
E. 5’- UCCUCC-3’
Question Q21.2
Q21.2 In a certain mutant strain of bacteria, the enzyme leucyl-tRNA synthase mistakenly attaches isoleucine to leucyl-tRNA 10% of the time instead of attaching leucine. These bacteria will synthesize:
A. proteins in which leucine is inserted at some positions normally occupied by isoleucine.
B. proteins in which isoleucine is inserted at some positions normally occupied by leucine.
C. no abnormal proteins, because the ribosomal translation machinery will recognize the
inappropriately activated tRNAs and exclude them from the translation process.
D. no proteins, because the inappropriately activated tRNAs will block translation.
Question Q21.3.
Q21.3 ._________ is the process of removing the __________ from pre-mRNA and joining the remaining __________ together to form a ‘mature’ mRNA molecule.
A. splicing, introns, exons
B. transcription, introns, exons
C. splicing, exons, introns
D. transcription, exons, introns
Question Q21.4
Q21.4 A mutation occurs such that a spliceosome cannot remove one of the introns in the mRNA. What effect will this have?
A. Transcription will terminate early and the mRNA will not be made.
B. The mRNA will fold into an improper shape and therefore will not be able to catalyze its
reaction.
C. The resulting mRNA will be shipped from the nucleus to the cytoplasm where it will be
translated by a ribosome.
D. The gene will no longer be transcribed by the cell.