
9.3: Eukaryotic Genes- An Introduction
- Page ID
- 40968

Within eukaryotic genomes, only a small fraction of the nucleotide content actually consists of protein coding genes (in humans, protein coding regions make up about 1%-1.5% of the entire genome). The rest of the DNA is classified as intergenic regions (See Figure 9.1) and contains things such as regulatory motifs, transposons, integrons and non-protein coding genes.2

Further, of the small fraction of the DNA that is transcribed into mRNA, not all of it is translated into protein. Certain regions known as introns, are removed or “spliced” out of the precursor mRNA. This now processed mRNA, containing only “exons” and some other additional modifications discussed in previous chapters, is translated into protein. (See Figure 9.2) The goal of computational gene identification is thus not only to pick out the few regions of the entire Eukaryotic genome that encode for proteins but also to parse those protein coding regions into identities of exon or intron so that the sequence of the synthesized protein can be known.
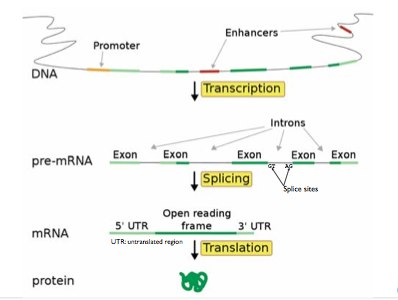
Figure 9.2: Intron/Exon Splicing
2"Intergenic region." http://en.Wikipedia.org/wiki/Intergenic region