
1.4: Crash Course in Molecular Biology
- Page ID
- 40909

lecture1_transcript.html#CentralDogma DNA → RNA → Protein
The central dogma of molecular biology describes how genetic information is stored and interpreted in the cell: The genetic code of an organism is stored in DNA, which is transcribed into RNA, which is finally translated into protein. Proteins carry out the majority of cellular functions such as motility, DNA regulation, and replication.
Though the central dogma holds true in most situations, there are a number of notable exceptions to the model. For instance, retroviruses are able to generate DNA from RNA via reverse-transcription. In addition, some viruses are so primitive that they do not even have DNA, instead only using RNA to protein.
1.4.2 DNA
Did You Know?
The central dogma is sometimes incorrectly interpreted too strongly as meaning that DNA only stores immutable information from one generation to the next that remains identical within a generation, RNA is only used as a temporary information transfer medium, and proteins are the only molecule that can carry out complex actions.
Again, there are many exceptions to this interpretation, for example:
- Somatic mutations can alter the DNA within a generation, and different cells can have different DNA content.
- Some cells undergo programmed DNA alterations during maturation, resulting in different DNA content, most famously the B and T immunity while blood cells
- Epigenetic modifications of the DNA can be inherited from one generation to the next
- RNA can play many diverse roles in gene regulation, metabolic sensing, and enzymatic reac-
tions, functions that were previously thought to be reserved to proteins.
- Proteins themselves can undergo conformational changes that are epigenetically inherited no- tably prion states that were famously responsible for mad cow disease
DNA → RNA → Protein
DNA function
The DNA molecule stores the genetic information of an organism. DNA contains regions called genes, which encode for proteins to be produced. Other regions of the DNA contain regulatory elements, which partially influence the level of expression of each gene. Within the genetic code of DNA lies both the data about the proteins that need to be encoded, and the control circuitry, in the form of regulatory motifs.
DNA structure
DNA is composed of four nucleotides: A(adenine), C(cytosine),T (thymine), and G (guanine). A and G are purines, which have two rings, while C and T are pyrimidines, with one ring. A and T are connected by two hydrogen bonds, while C and G are connected by three bonds. Therefore, the A-T pairing is weaker than the C-G pairing. (For this reason, the genetic composition of bacteria that live in hot springs is 80% G-C). lecture1_transcript.html#Complementarity
The two DNA strands in the double helix are complementary, meaning that if there is an A on one strand, it will be bonded to a T on the other, and if there is a C on one strand, it will be bonded to a G on the other. The DNA strands also have directionality, which refers to the positions of the pentose ring where the phosphate backbone connects. This directionality convention comes from the fact that DNA and RNA polymerase synthesize in the 5’ to 3’ direction. With this in mind, we can say that that the DNA strands are anti-parallel, as the 5’ end of one strand is adjacent to the 3’ end of the other. As a result, DNA can be read both in the 3’ to 5’ direction and the 5’ to 3’ direction, and genes and other functional elements can be found in each. By convention, DNA is written from 5’ to 3’. The 5’ and 3’ directions refer to the positions on the pentose ring where the phosphate backbone connects.
Base pairing between nucleotides of DNA constitutes its primary and secondary structure. In addition to DNA’s secondary structure, there are several extra levels of structure that allow DNA to be tightly compacted and influence gene expression (Figure 3). The tertiary structure describes the twist in the DNA ladder that forms a helical shape. In the quaternary structure, DNA is tightly wound around small proteins called histones. These DNA-histone complexes are further wound into tighter structures seen in chromatin.
Before DNA can be replicated or transcribed into RNA, the chromatin structure must be locally “un- packed”. Thus, gene expression may be regulated by modifications to the chromatin structure, which make it easier or harder for the DNA to be unpacked. This regulation of gene expression via chromatin modification is an example of epigenetics.
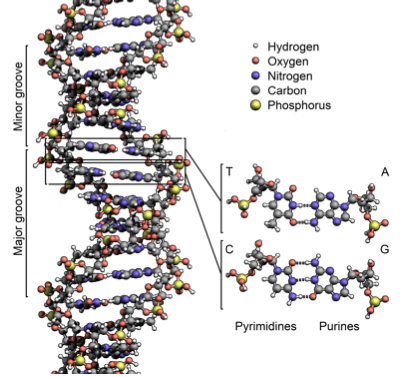
Figure 1.2: The double-helix structure of DNA. Nucleotides are in the center, and the sugar-phosphate backbone lies on the outside.
DNA replication
The structure of DNA, with its weak hydrogen bonds between the bases in the center, allows the strands to easily be separated for the purpose of DNA replication (the capacity for DNA strands to be separated also allows for transcription, translation, recombination, and DNA repair, among others). This was noted by Watson and Crick as “It has not escaped our notice that the specific pairing that we have postulated immediately suggests a possible copying mechanism for the genetic material.” In the replication of DNA, the two complementary strands are separated, and each of the strands are used as templates for the construction of a new strand.
DNA polymerases attach to each of the strands at the origin of replication, reading each existing strand from the 3’ to 5’ direction and placing down complementary bases such that the new strand grows in the 5’ to 3’ direction. Because the new strand must grow from 5’ to 3’, one strand (the leading strand) can be copied continuously, while the other (the lagging strand) grows in pieces which are later glued together by DNA ligase. The end result is 2 double-stranded pieces of DNA, where each is composed of 1 old strand, and 1 new strand; for this reason, DNA replication is semiconservative.
Many organisms have their DNA broken into several chromosomes. Each chromosome contains two strands of DNA, which are complementary to each other but are read in opposite directions. Genes can occur on either strand of DNA. The DNA before a gene (in the 5’ region) is considered “upstream” whereas the DNA after a gene (in the 3’ region) is considered “downstream”.
1.4.3 Transcription
lecture1_transcript.html#Transcription
DNA → RNA → Protein
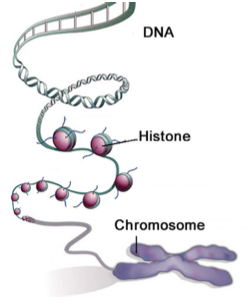
Source: Qiu, Jane. "Epigenetics: Unfinished Symphony." Nature 441, no. 7090 (2006): 143-45.
Figure 1.3: DNA is packed over several layers of organization into a compact chromosome
mRNA generation
Transcription is the process by which RNA is produced using a DNA template. The DNA is partially unwound to form a “bubble”, and RNA polymerase is recruited to the transcription start site (TSS) by regulatory protein complexes. RNA polymerase reads the DNA from the 3’ to 5’ direction and placing down complementary bases to form messenger RNA (mRNA). RNA uses the same nucleotides as DNA, except Uracil is used instead of Thymine.
Post-transcriptional modifications
mRNA in eukaryotes experience post-translational modifications, or processes that edit the mRNA strand further. Most notably, a process called splicing removes introns, intervening regions which don’t code for protein, so that only the coding regions, the exons, remain. Different regions of the primary transcript may be spliced out to lead to different protein products (alternative splicing). In this way, an enormous number of different molecules may be generated based on different splicing permutations.
In addition to splicing, both ends of the mRNA molecule are processed. The 5’ end is capped with a modified guanine nucleotide. At the 3’ end, roughly 250 adenine residues are added to form a poly(A) tail.
RNA
lecture1_transcript.html#RNA
DNA → RNA → Protein
RNA is produced when DNA is transcribed. It is structurally similar to DNA, with the following major differences:
1. The nucleotide uracil (U) is used instead of DNA’s thymine (T).
2. RNA contains ribose instead of deoxyribose (deoxyribose lacks the oxygen molecule on the 2’ position found in ribose).
3. RNA is single-stranded, whereas DNA is double-stranded.
RNA molecules are the intermediary step to code a protein. RNA molecules also have catalytic and regulatory functions. One example of catalytic function is in protein synthesis, where RNA is part of the ribosome.
There are many different types of RNA, including:
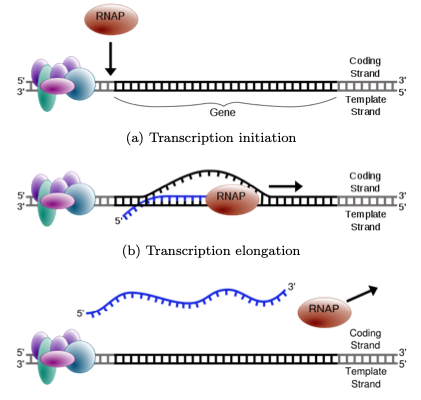
Figure 1.4: RNA is produced from a DNA template during transcription. A “bubble” is opened in the DNA, allowing the RNA polymerase to enter and place down bases complementary to the DNA.
(a) Transcription initiation
(b) Transcription elongation
(c) Transcription termination
- mRNA (messenger RNA) contains the information to make a protein and is translated into protein sequence.
- tRNA (transfer RNA) specifies codon-to-amino-acid translation. It contains a 3 base pair anti-codon complementary to a codon on the mRNA, and carries the amino acid corresponding to its anticodon attached to its 3’ end.
- rRNA (ribosomal RBA) forms the core of the ribosome, the organelle responsible for the translation of mRNA to protein.
- snRNA (small nuclear RNA) is involved in splicing (removing introns from) pre- mRNA, as well as other functions.
Other functional kinds of RNA exist and are still being discovered. Though proteins are generally thought to carry out essential cellular functions, RNA molecules can have complex three-dimensional structures and perform diverse functions in the cell.
According to the “RNA world” hypothesis, early life was based entirely on RNA. RNA served as both the information repository (like DNA today) and the functional workhorse (like protein today) in early organisms. Protein is thought to have arisen afterwards via ribosomes, and DNA is thought to have arisen last, via reverse transcription.
Translation
lecture1_transcript.html#Translation
DNA → RNA → Protein
Translation
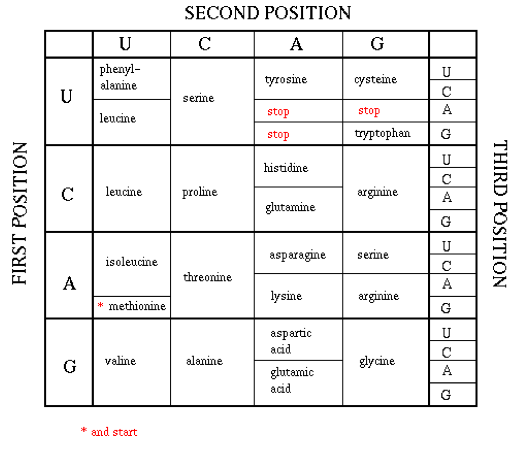
Unlike transcription, in which the nucleotides remained the means of encoding information in both DNA and RNA, when RNA is translated into protein, the primary structure of the protein is determined by the sequence of amino acids of which it is composed. Since there are 20 amino acids and only 4 nucleotides, 3-nucleotides sequences in mRNA, known as codons, encode for each of the 20 amino acids.
Each of the 64 possible 3-sequences of nucleotides (codon) uniquely specifies either a particular amino acid, or is a stop codon that terminates protein translation (the start codon also encodes methionine). Since there are 64 possible codon sequences, the code is degenerate, and some amino acids are specified by multiple encodings. Most of the degeneracy occurs in the 3rd codon position.
Post-translational modifications
Like mRNA, protein also undergo further modifications that affect its structure and function. One type of post-translational modification (PTM) involves introducing new functional groups to the amino acids. Most notably, phosphorylation is the process by which a phosphate group is added onto an amino acid which can activate or deactivate the protein entirely. Another type of PTM is cleavage of peptide bonds. For example, the hormone insulin is cleaved twice following the formation of disulfide bonds within the original protein.
Protein
DNA → RNA → Protein
Protein is the molecule responsible for carrying out most of the tasks of the cell, and can have many functions, such as enzymatic, contractile, transport, immune system, signal and receptor to name a few. Like RNA and DNA, proteins are polymers made from repetitive subunits. Instead of nucleotides, however, proteins are composed of amino acids.
Each amino acid has special properties of size, charge, shape, and acidity. As such, additional structure emerges beyond simply the sequence of amino acids (the primary structure), as a result of interactions between the amino acids. As such, the three-dimensional shape, and thus the function, of a protein is determined by its sequence. However, determining the shape of a protein from its sequence is an unsolved problem in computational biology.
Regulation: from Molecules to Life
lecture1_transcript.html#Regulation
Not all genes are expressed at the same time in a cell. For example, cells would waste energy if they produced lactose transporter in the absence of lactose. It is important for a cell to know which genes it should expresses and when. A regulatory network is involved to control expression level of genes in a specific circumstance.
Transcription is one of the steps at which protein levels can be regulated. The promoter region, a segment of DNA found upstream (past the 5’ end) of genes, functions in transcriptional regulation. The promoter region contains motifs that are recognized by proteins called transcription factors. When bound, transcription factors can recruit RNA polymerase, leading to gene transcription. However, transcription factors can also participate in complex regulatory interactions. There can be multiple binding sites in a promotor, which can act as a logic gate for gene activation. Regulation in eukaryokes can be extremely complex, with gene expression affected not only by the nearby promoter region, but also by distant enhancers and repressors.
We can use probabilistic models to identify genes that are regulated by a given transcription factor. For example, given the set of motifs known to bind a given transcription factor, we can compute the probability that a candidate motif also binds the transcription factor (see the notes for precept #1). Comparative sequence analysis can also be used to identify regulatory motifs, since regulatory motifs show characteristic patterns of evolutionary conservation.
The lac operon in E. coli and other bacteria is an example of a simple regulatory circuit. In bacteria, genes with related functions are often located next to each other, controlled by the same regulatory region, and transcribed together; this group of genes is called an operon. The lac operon functions in the metabolism of the sugar lactose, which can be used as an energy source. However, the bacteria prefer to use glucose as an energy source, so if there is glucose present in the environment the bacteria do not want to make the proteins that are encoded by the lac operon. Therefore, transcription of the lac operon is regulated by an elegant circuit in which transcription occurs only if there is lactose but not glucose present in the environment.
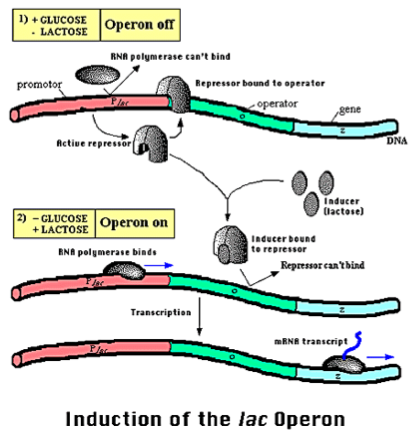
Figure 1.6: Operon Lac illustrates a simple biological regulatory system. In the presence of glucose, genes to lactose metabolism are turn out because glucose inactives an activator protein. In the absence of lactose, a repressor protein also turns out the operon. Lactose metabolism genes are expressed only in the presence of lactose and absence of glucose.
Figure 1.7: Metabolic pathways and regulation can be studied by Computational biology. Models are made from genome scale information and used to predict metabolic function and to metabolic engineering. An example of biological engineering is modifying bacteria genome to overproduce artemesenin, an antibiotic used to treat malaria.
Metabolism
lecture1_transcript.html#
Live organisms are made from self-organizing building blocks. Energy source is necessary for organize blocks. The basic mechanism involved in building blocks is degrading small molecules to get energy to build big molecules. The process of degrading molecules to release energy is called catabolism and the process of using energy to assemble more complex molecules is called anabolism. Anabolism and catabolism are both metabolic processes. Metabolism regulates the flow of mass and energy in order to keep an organism in a state of low entropy.
Enzymes are a critical component of metabolic reactions. The vast majority of (but not all!) enzymes are proteins. Many biologically critical reactions have high activation energies, so that the uncatalyzed reaction would happen extremely slowly or not at all. Enzymes speed up these reactions, so that they can happen at a rate that is sustainable for the cell. In living cells, reactions are organized into metabolic pathways. A reaction may have many steps, with the products of one step serving as the substrate for the next. Also, metabolic reactions often require an investment of energy (notably as a molecule called ATP), and energy released by one reaction may be captured by a later reaction in the pathway. Metabolic pathways are also important for the regulation of metabolic reactionsif any step is inhibited, subsequent steps may lack the substrate or the energy that they need to proceed. Often, regulatory checkpoints appear early in metabolic pathways, since if the reaction needs to be stopped, it is obviously better to stop it before much energy has been invested.
Systems Biology
lecture1_transcript.html#SystemsBiology
Systems biology strives to explore and explain the behavior that emerges from the complex interactions among the components of a biological system. One interesting recent paper in systems biology is “Metabolic gene regulation in a dynamically changing environment” (Bennett et al., 2008). This work makes the assumption that yeast is a linear, time invariant system, and runs a signal (glucose) through the system to observe the response. A periodic response to low-frequency fluctuations in glucose level is observed, but there is little response to high-frequency fluctuations in glucose level. Thus, this study finds that yeast acts as a low-pass filter for fluctuations in glucose level.
Synthetic Biology
lecture1_transcript.html#SyntheticBiology
Not only can we use computational approaches to model and analyze biological data collected from cells, but we can also design cells that implement specific logic circuits to carry out novel functions. The task of designing novel biological systems is known as synthetic biology.
A particularly notable success of synthetic biology is the improvement of artemesenin production. Arteme- senin is a drug used to treat malaria. However, artemisinin was quite expensive to produce. Recently, a strain of yeast has been engineered to synthesize a precursor to artemisinic acid at half of the previous cost.
Model organisms and human biology
Diverse model organisms exist for all aspects of human biology. Importance of using model organisms at appropriate level of complexity.
Note: In this particular book, we’ll focus on human biology, and we’ll use examples from baker’s yeast Saccharomyces cerevisiae, the fruitfly Drosophila melanogaster, the nematode worm Coenorhabditis elegans, and the house mouse Mus musculus. We’ll deal with bacterial evolution only in the context of metagenomics of the human microbiome.