2.34: Structures of Biological Molecules
- Page ID
- 86048
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In biological systems, the ligands in metal coordination complexes include small molecules like drugs, lipids, and amino acids. In addition, larger biomolecules like DNA, RNA, peptides/proteins, and carbohydrates also serve as ligands. These larger biomolecules are often polydentate chelators and they have structural constraints that influence the coordination geometry or number of ligands that bind to metals. In this section, we will start with the very basics of biomolecule structure.
In this section, you should focus on understanding the molecular structures of the biomolecules that make up cellular components (lipids, DNA, proteins, carbohydrates, and lipids) and how each of these biomolecules can act as a metal ligand.
The Cell
An Overview from a Chemist's Perspective
You have probably studied the cell many times, either in high school or in college biology classes. There are many websites available that review both prokaryotic (bacterial), archeal, and eukaryotic cells (see links at bottom). This tutorial is designed specifically from the viewpoint of chemistry. It explores four classes of biomolecules (lipids, proteins, nucleic acids, and carbohydrates) and describes in a simplified pictorial manner where they are found, made, and degraded in the cell (i.e. their history). It focuses on eukaryotic cells, which in contrast to simpler prokaryotic cells, have internal organelles surrounded by membranes that compartmentalize chemical reactions. First, a general overview of the cell is presented.
Let's think of a cell as a chemical factory that designs, imports, synthesizes, uses, exports, and degrades a variety of chemicals (in the case of the cell, these include lipids, proteins, nucleic acids, and carbohydrates). It also must determine or sense the amount of raw and finished chemicals it has available and respond to its own and external needs by ramping up or shutting off production.
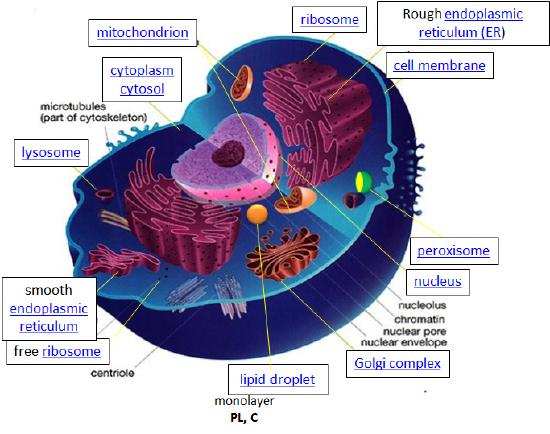
Design. The design for a cell mostly resides in the blueprint for the cell, the genetic code, which is comprised of the DNA in the cell nucleus and a small amount in the mitochondria. Of course, the DNA blueprint must be read out (transcribed) by protein enzymes which themselves were encoded by the DNA. The genetic code has the master plan that determines the sequence of all cellular proteins, which then catalyze almost all other activities in the cell, including catalysis, motility, architectural structure, etc. In contrast to DNA, RNA, and protein polymers, the length and sequence of a polysaccharide polymer is not driven by a template but rather by the enzymes that catalyze the polymerization.
Import/Export. Many of the chemical constituents of the cell arise not from direct synthesis but from import of both small and large molecules. The imported molecules must pass through the cell membrane and in some cases through additional membranes if they need to reside inside membrane-bound organelles. Molecules can move into the cell by passive diffusion across the membrane but usually, their movement is "facilitated" by a membrane receptor. Molecules can also move up a concentration gradient in a process called "active transport". Given the amphiphilic nature of the bilayer (polar head group exterior, nonpolar interior), you would expect that polar molecule like glucose would have difficulty in moving across the membrane. In fact, membrane transport proteins are involved in the movement of both nonpolar and polar molecules.
Transporters, carrier proteins, and permeases. These membrane proteins move specific ligand molecules across a membrane, typically down a concentration gradient.
Ion channels. These membrane proteins allow the flow of ions across membranes. Some are permanently open (nongated) while others are gated open or closed depending on the presence of ligands that bind the protein channel and the local environment of the protein in the membrane. Flow of ions through the channel proceeds in a thermodynamically favored direction, which depends on their concentration and voltage gradients across the membrane.
Pores. Some membranes (nuclear, mitochondria) assemble proteins (such as porins) to form large, but regulated pores. Porins are found in mitochondrial membranes while nucleoporins are found in the nuclear membrane. Small molecules can generally pass through these membrane pores while large one are selected based on their tendency to form transient intermolecular attractive forces with the pore proteins.
Endocytosis. Very large particles (for example, LDL or low-density lipoproteins or viruses) can enter a cell through a process called endocytosis. Initially, the LDL or virus binds to a receptor on the surface of the cell. This triggers a series of events which leads to the invagination of the cell membrane at that point. This eventually pinches off to form an endosomal vesicle which is surrounded by a protein called clathrin. "Early" endosomes can pick up new proteins and other constituents as well as shed them as they move and mature through the cell. During this maturation process, protein pumps in the endosome lead to a decrease in the endosomal pH which can lead to conformation changes in protein structure and shedding of proteins. Eventually, the "late" endosome reaches and fuses with the lysosome, an internal organelle that contains degradative enzymes. Undegraded components, like viral nucleic acids or cholesterol, are delivered to the cell. This transport can also go in the reverse direction and recycle receptors to the cell membrane. Likewise, vesicles pinched off from the Golgi complex can fuse with endosomes, with some components surviving the process to reenter the Golgi.
Synthesize/Degrade. Cells have to both synthesize and degrade small molecules as well as larger polymeric protein, carbohydrates, and nucleic acids. The anabolic (synthetic) and catabolic (degradative) pathways are often compartmentalized in time and space within a cell. For example, fatty acid synthesis is carried out in the cytoplasm but fatty acid oxidation is carried out in the mitochondria. Proteins are synthesized in the cytoplasm or completed in the endoplasmic reticulum (for membrane and exported proteins) while they are degraded in the lysosome or more importantly in a large multimolecular structure in the cell called the proteasome.
Let's consider some key characteristics of a cell before we get into the details.
Cells and their internal compartments have regulated concentrations of ions and hydronium ion.
As expected, the pH of the cytosol (the aqueous substance surrounding all the organelles within the cell) varies from about 7.0-7.4, depending on the metabolic state of the cell. Some organelles have proton transporters that can significantly alter the pH inside an organelle. For example, the pH inside the lysosome, a degradative organelle, is about 4.8. The collapse of the pH gradient across the inner mitochondrial membrane is sufficient to drive the thermodynamically unfavored synthesis of ATP.
Compared to the extracellular fluid, the concentration of potassium ion is higher inside the cell, while concentrations of sodium, chloride, and calcium ions are higher on the outside of the cell (see table below). These concentration gradients are maintained by ion transporters and channels and require energy expenditure ultimately in the form of ATP hydrolysis. Changes in these concentrations are integral to the signaling system used by the cell to sense and respond to changes in its external and internal environments.
Water is found in bulk form as well as bound to macromolecules like proteins and polysaccharides. These waters would be expected to have different properties. The table below shows approximate ion concentrations in the cell.
| Ion | Inside (mM) | Outside (mM) |
|---|---|---|
| Na+ | 140 | 5 |
| K+ | 12 | 140 |
| Cl- | 4 | 15 |
| Ca2+ | 1 uM | 2 |
Cells have an internal framework that provides architectural and internal structural support.
The "cytoskeletal" architecture of a (with molecular "cables"- and "girder-like" structures) is not dissimilar from a factory.

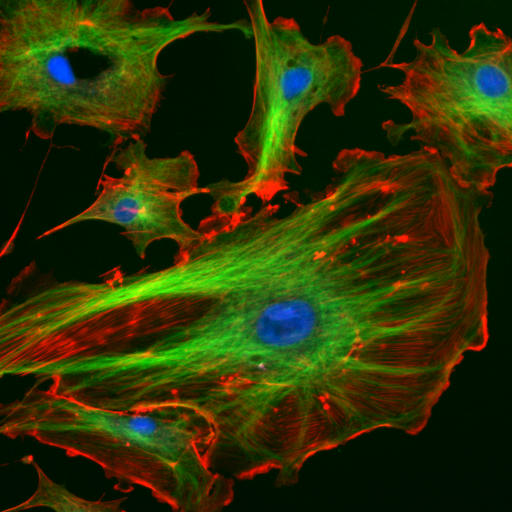
The internal framework or cytoskeleton of a cell, is composed of microfilaments, intermediate filaments, and microtubules. These are comprised of monomeric proteins which self assemble to form the internal architecture. Parts of the cytoskeleton can be seen in the photo above (taken from Wikipedia).
Microfilaments of actin monomers (which are stained with a red/orange fluorophore) and microtubules which offer more structural support made of tubulin monomers (stained green) along with the blue-stained nucleus, are shown in the image. Organelles are supported and organized by the cytoskeleton (primarily microtubules). Even the cell membrane is supported underneath the inner leaflet by actin (stained orange) and spectrin microfilaments. Motor proteins like myosin (that moves along actin microfilaments) and dynein and kinesin (that move along tubulin microtubules) carry cargo (vesicles, organelles) in a directional fashion. The cell is not a disorganized collection of molecules and organelles. Rather, it is highly organized for optimal chemical production, use, and degradation.
Cell have a variety of shapes. Some circulating immune cells must slip through the cells that line capillary walls to migrate to sites of infection. The same process occurs when tumor cells metastasize and escape to other sites in the body. In order to do so, the cell must drastically change shape, a response that requires dissociation of the cytoskeleton polymers into monomers which are available later for repolymerization.
The cell is an amazingly crowded place.
In chemistry labs, we typically work with dilute solutions of solute molecules in a solvent. You have probably heard that the body is comprised of 68% water, but the water concentration is obviously dependent on the cellular environment. Solute molecules like protein and carbohydrates are densely packed. Cells are so crowded that the space between larger molecules like protein is less than the size of protein. Studies have shown that the stability of a protein is increased in such condition, which would help keep the protein in the folded, native state. Another consequence of high concentrations is that it would promote the binding or self-aggregation of like molecules as well as dislike ones which from an equilibrium perspective would not occur in dilute solutions. Hence the study of biomolecules in dilute solutions in the lab may not reveal the actual complexities of interactions and activities of the same molecule in vivo. Recently investigators have added a neutral copolymer of sucrose and epichlorhydrine to cells in vitro. These particles induced organization of extracellular molecules secreted by cell, forming an organized extracellular "matrix" which induced the organization of the microfilaments on the inside of the cell as well as inducing changes in cell activity. In vitro enzyme activity of a key enzyme in glycolysis dramatically increases under crowded conditions. Another result of crowding may be the spatial and temporal association of key enzymes in specific metabolic pathways, allowing easier diffusion of substrates and products within the colocalized enzymes.
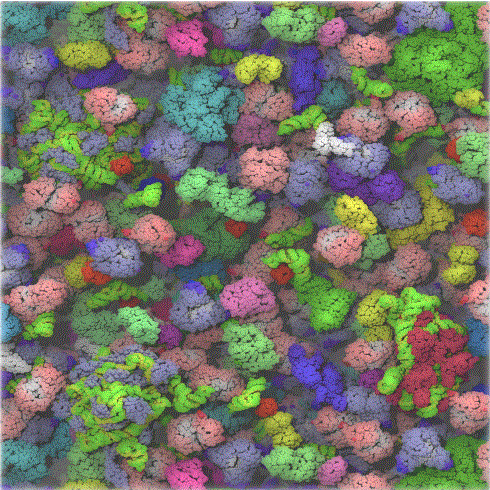
The computer simulation above used 50 different types of the most abundant macromolecules of the E. coli cytoplasm and 1008 individual molecules. Rendering of the cytoplasm model at the end of a dynamics simulation. RNA is shown as green and yellow. This figure was prepared with VMD.
Cell components undergo phase transitions to form substructures within the cell.
A perplexing question is how do substructures form within a cell. This includes not only the biogenesis of organelles like mitochondria but also smaller particle such as polysaacharide granules, lipid droplets, protein/RNA particles (including the ribosome) as well as the nucleolus of the cell nucleus. It might be easiest to consider this problem using two examples from the lipid world, lipid droplets and membrane rafts. You are very familiar with phase transitions that occur when a sparing soluble nonpolar liquid is added to water. At a high enough concentration, the solubility of the nonpolar liquid is exceeded and a phase transition occur as evidenced by the appearance of two separate liquid phases. The same process occurs when triglycerides coalesce into lipid droplets with proteins associated on their outside. Another example occurs within a cell membrane when lipids with saturated alkyl chains self associate with membrane cholesterol (which contains a rigid planar ring system) to form a lipid raft characterized by greater packing efficiency, rigidity, and thickness than other parts of the membrane. These lipid rafts often recruit protein involved in signaling processes within the cell membranes. This process of phase separation is also called liquid/liquid demixing as two "liquid-like" substances separate.
It appears that proteins that interact with RNA are composed of less diverse amino acid and have more flexible ("more liquid-like) structures allowing their preferential interaction with RNA to form large RNA-protein particles (like the ribosome and other RNA processing structures) in a fashion that mimics liquid/liquid demixing. All of these interactions are just manifestations of the various intermolecular forces that you studied in earlier chemistry classes.
Lipids
Lipids are small biological molecules that are soluble in organic solvents, such as chloroform/methanol, and are sparingly soluble in aqueous solutions. The simple classification of lipids belies the complexity of possible lipid structures as over 1000 different lipids are found in eukaryotic cells. This complexity has led to the development of a comprehensive classification system for lipids. In this system, lipids are given a very detailed, as well as all-encompassing definition: "hydrophobic or amphipathic small molecules that may originate entirely or in part by carbanion-based condensations of thioesters (fatty acyl, glycerolipids, glycerophospholipids, sphingolipds, saccharolipds, and polyketides) and/or by carbocation-based condensations of isoprene units (prenol lipids and sterol lipids)."
The following links will show you the "life" history of lipids in cells:
Proteins
Proteins are polymers of bifunctional alpha-amino acids each containing a different R group at the alpha carbon. Encoded by the DNA genome, proteins are involved in all cellular activities including recognition, catalysis, movement, and signaling.
The following links will show you the "life" history of proteins in cells:
Nucleic Acids
Nucleic acids are polymers of deoxyribonucleotides (DNA) or ribonucleotides (RNA). DNA contains the genetic code that when transcribed into RNA followed by translation of the RNA for around 22,000 protein. Only about 2% of the 3.2 billion base pairs of DNA encodes protein. The function of 80% of the remaining genome has recently been found to regulate the transcription of DNA, mostly through various types of RNA transcribed from the DNA.
The following links will show you the "life" history of nucleic acids in cells:
Carbohydrates
Carbohydrates are... this content is missing from the LibreTexts sourcebook.
The following links will show you the "life" history of carbohydrates in cells:
Lipids: Membranes and Fats
Lipids are molecules that are mostly nonpolar, but have some polar character. These molecules serve important biological functions, such as providing the principle component of membranes (phospholipid bilayers) and serving as energy storage (fat). The structures of a triglyceride and a phospholipid are shown above. Triglycerides are the things we commonly refer to as “fats” and “oils”. Phospholipids are similar to triglycerides with one important difference.
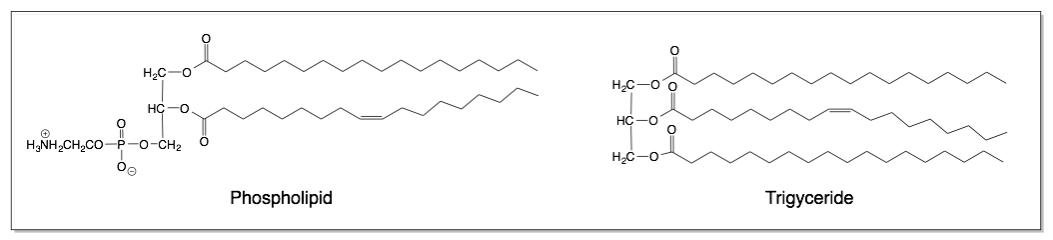
A skeletal structure of a phospholipid and a triglyceride are shown above. Notice the similarities and differences between the two structures. The phospholipid is similar to the triglyceride in that it contains fatty acid tails attached to a glycerol backbone. However, the phospholipid contains an organic phosphate zwiterion instead of a third fatty acid tail.
Triglycerides are completely insoluble in water. However, due to the ionic organic phosphate group, phospholipids demonstrate properties because the ionic group is attracted to water. Phospholipids have both a polar, hydrophilic end, and a nonpolar, hydrophobic end. Phospholipids are partially soluble in water, meaning that part of the molecule is attracted to water, and part of it is not. Phospholipids form important structures in water when the polar end faces water and the nonpolar end faces away from water. Below is a cartoon version of the phospholipid bilayer in 2D.
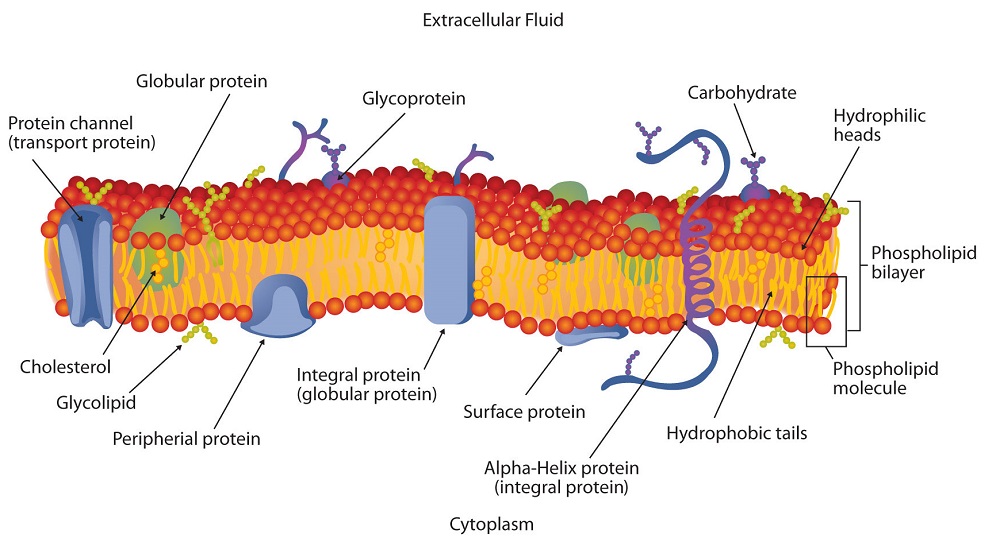
Phospholipid bilayers separate aqueous compartments in cells. They act as semipermeable membranes that allow only very small or nonpolar molecules through. Membranes also contain small molecules (ex cholesterol, coenzymeQ) and proteins, which can be embedded in the bilayer or can span from one side of the membrane to the other.
Lipid Bilayer Membrane
Every cell is enclosed by a membrane which gives structure to the cell and allows for the passage of nutrients and wastes into and out of the cell. The purpose of the bilayer membrane is to separate the cell contents from the outside environment. The outside of the cell is mostly water and the inside of the cell is mostly water. The cell membrane may be coated with other molecules such as carbohydrates and proteins, which serve as receptor sites for other messenger molecules. Interaction with the cell membrane allows for molecular communication signals to pass from outside to inside of the cell.
Introduction
Cell membranes are composed of two classes of molecules: lipids and proteins. The proteins serve as enzymes, carry molecules, and provide the membrane with distinctive functional properties. Details of proteins and enzyme structures are given elsewhere. The lipids provide the structural integrity for the cell. The lipids found in the membrane consist of two parts: hydrophilic (water-soluble) and hydrophobic (water-insoluble). The hydrophobic portion of the lipids is the non-polar long hydrocarbon chains of two fatty acids. The fatty acids are present as esters bonded to glycerol. The third-OH group on glycerol is ester bonded to phosphate hence the term phospholipid. The phosphate ester portion of the molecule is polar or even ionic and hence is water-soluble. A simple interaction of several phospholipids is shown in the graphic on the left.
There are two common phospholipids found in the bilayer:
- Lecithin contains the amino alcohol, choline.
- Cephalins contain the amino alcohols serine or ethanolamine.
The arrangement of phospholipids in cell membranes has been deduced by X-Ray diffraction data. The phospholipids are arranged as a bilayer (two molecules thick). The phospholipids are stacked with the non-polar hydrocarbon chains pointed inward while the polar ends act as the external surface as shown in the graphic below. The structure of the bilayer is another application of the solubility principle of "likes dissolve likes".
Most of the fatty acids in the membrane are unsaturated because this allows the membrane to be more flexible (cis bonds are bent) to allow certain molecules through the membrane. However, the interaction of the hydrophobic inside of the layer acts as a barrier for ionic and polar molecules from entering the inside of the cell. In animal cells cholesterol is inserted between the non-polar chains, and makes up about 20% of the molecules of the membrane. This helps to make the membrane more rigid and adds strength.
Carbohydrates
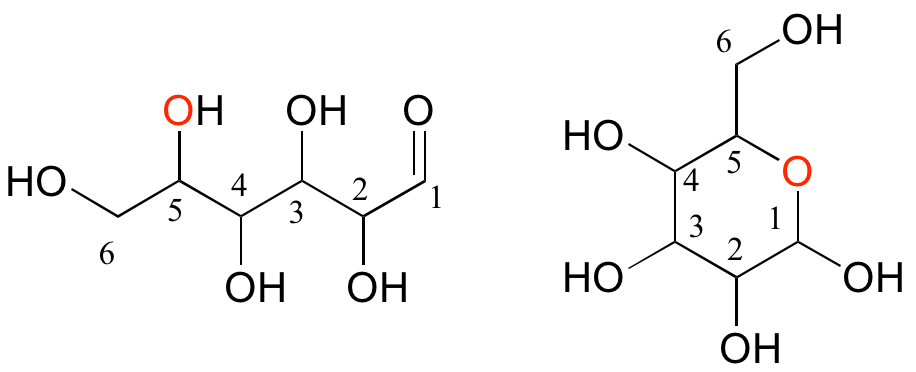
The term 'carbohydrate', which literally means 'hydrated carbons', broadly refers to monosaccharides, disaccharides, oligosaccharides (shorter polymers), and polysaccharides (longer polymers).
Monosaccharides (commonly called 'sugars') are four- to six-carbon molecules with multiple alcohol groups and a single aldehyde or ketone group. Many monosaccharides exist in aqueous solution as a rapid equilibrium between an open chain and one or more cyclic forms. Two forms of a six-carbon monosaccharide are shown below.
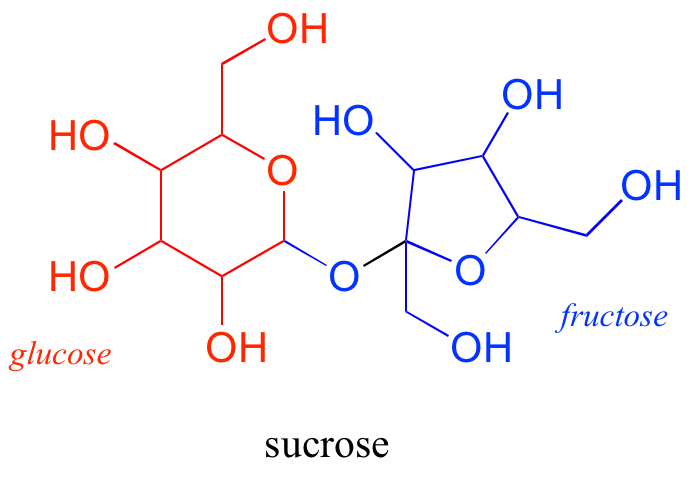
Disaccharides are two monosaccharides linked together: for example, sucrose, or table sugar, is a disaccharide of glucose and fructose.
Oligosaccharides and polysaccharides are longer polymers of monosaccharides. Cellulose is a polysaccharide of repeating glucose monomers. As a major component of the cell walls of plants, cellulose is the most abundant organic molecule on the planet. A two-glucose stretch of a cellulose polymer is shown below.
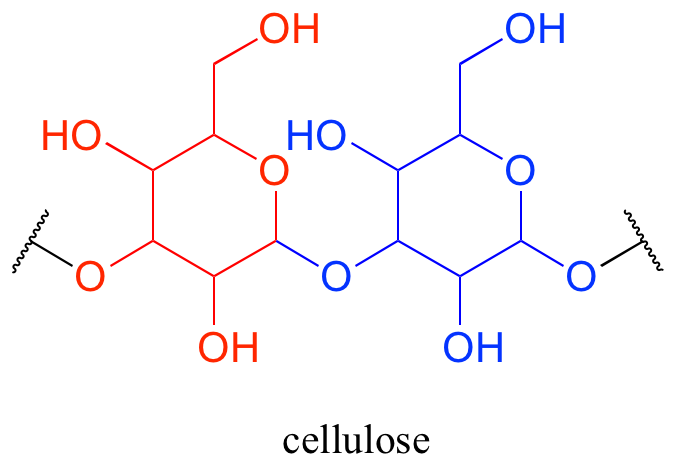
The linking group in carbohydrates is not one that we have covered in this section — in organic chemistry, this group is called an acetal, while biochemists usually use the term glycosidic bond when talking about carbohydrates.
The possibilities for carbohydrate structures are vast, depending on which monomers are used (there are many monosaccharides in addition to glucose and fructose), which carbons are linked, and other geometric factors which we will learn about later. Multiple linking (branching) is also common, so many carbohydrates are not simply linear chains. In addition, carbohydrate chains are often attached to proteins and/or lipids, especially on the surface of cells. All in all, carbohydrates are an immensely rich and diverse subfield of biological chemistry.
Nucleic Acids: DNA and RNA
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) are polymers composed of monomers called nucleotides. An RNA nucleotide consists of a five-carbon sugar phosphate linked to one of four nucleic acid bases: guanine (G), cytosine (C), adenine (A) and uracil (U).
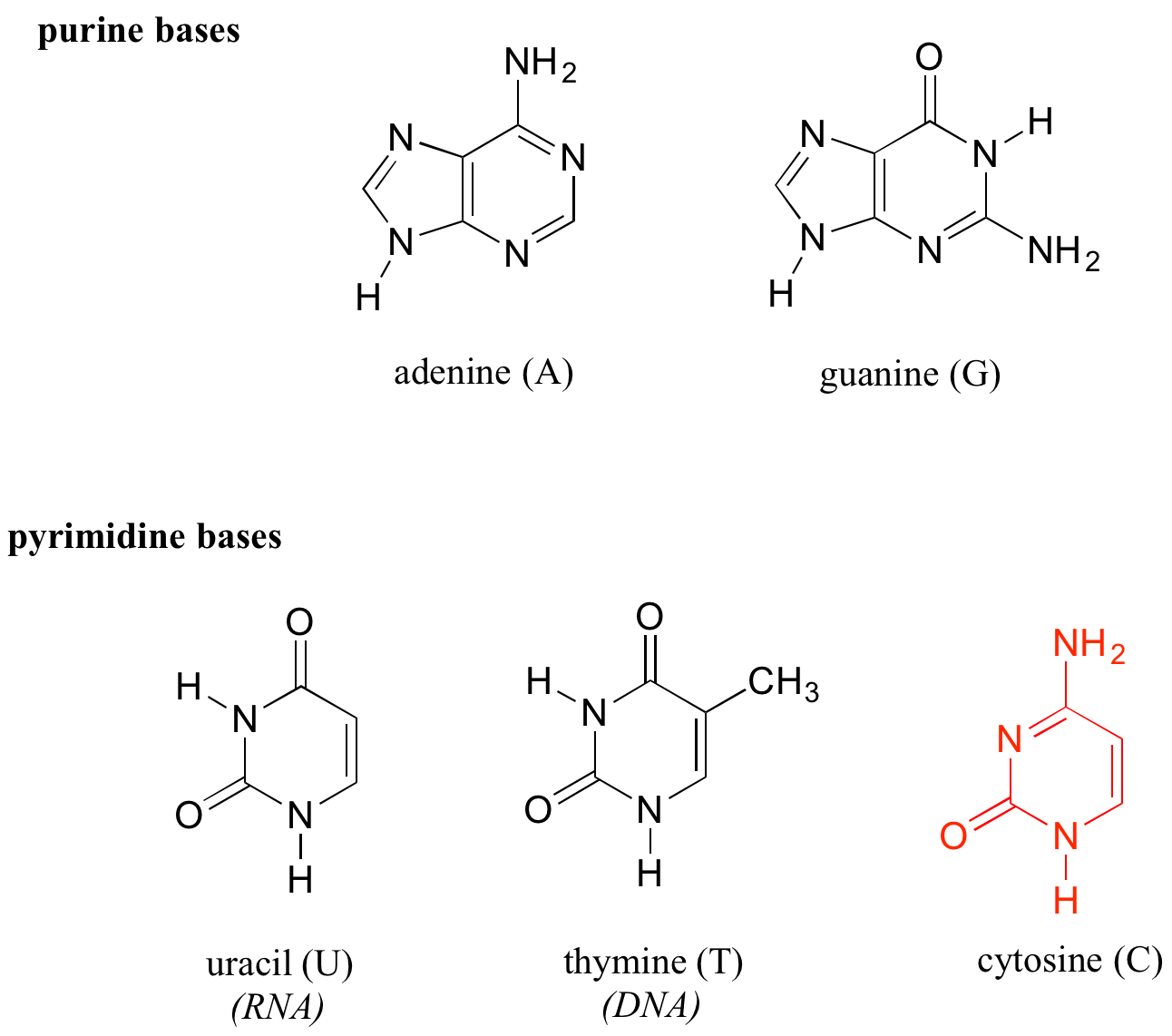
In a DNA nucleototide, the sugar is missing the hydroxyl group at the 2' position, and the thymine base (T) is used instead of uracil. The conventional numbering system used for DNA and RNA is shown here for reference — the prime (') symbol is used to distinguish the sugar carbon numbers from the base carbon numbers.
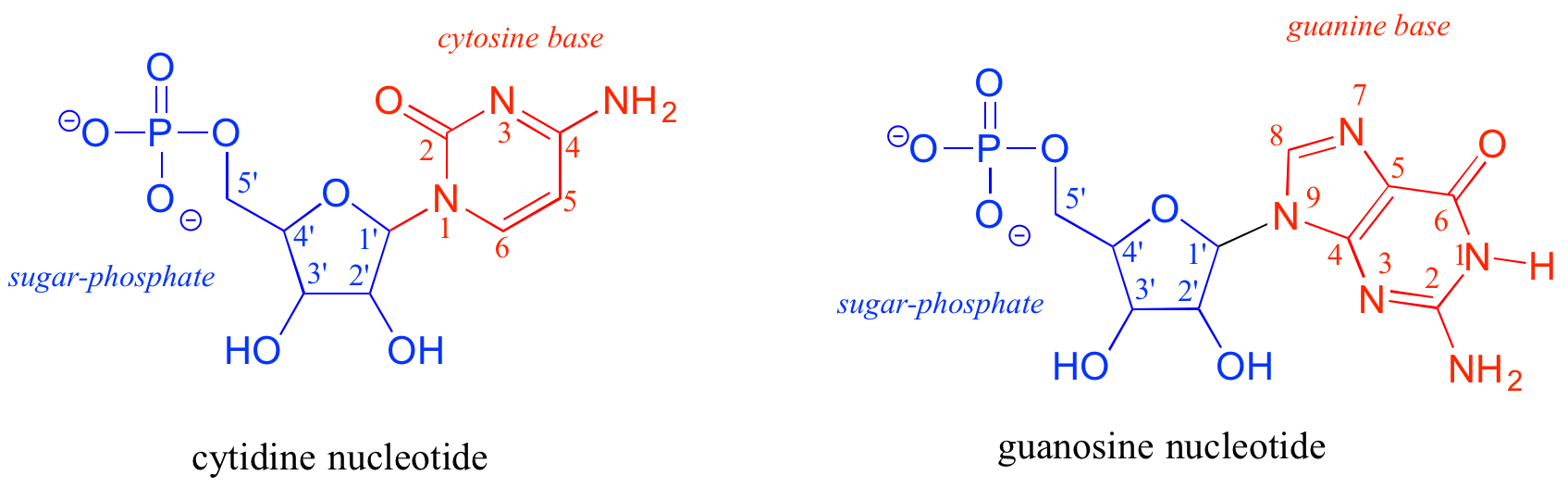
The two 'hooks' on the RNA or DNA monomer are the 5' phosphate and the 3' hydroxyl on the sugar, which in DNA polymer synthesis are linked by a 'phosphate diester' group. By convention, DNA and RNA sequences are written in 5' to 3' direction.

Amino Acids and Proteins
Proteins are polymers of amino acids, linked by amide groups known as peptide bonds. An amino acid can be thought of as having two components: a 'backbone', or 'main chain', composed of an ammonium group, an 'alpha-carbon', and a carboxylate, and a variable 'side chain' (in green below) bonded to the alpha-carbon.
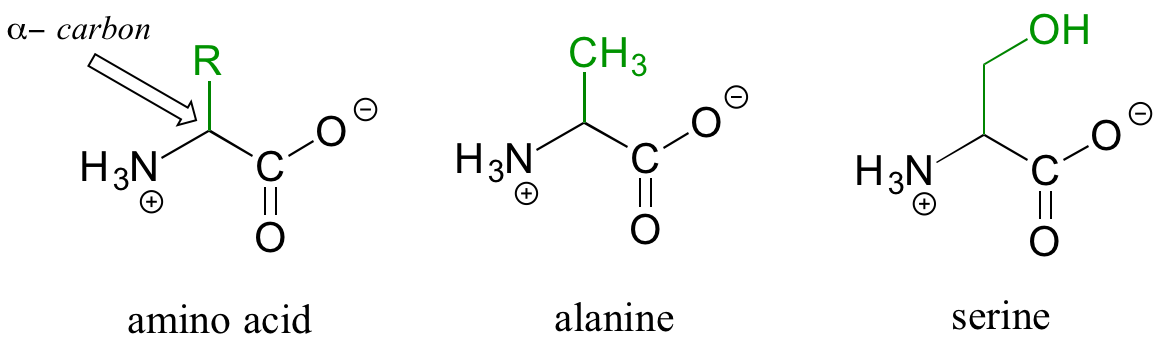
There are twenty different side chains in naturally occurring amino acids, and it is the identity of the side chain that determines the identity of the amino acid: for example, if the side chain is a -CH3 group, the amino acid is alanine, and if the side chain is a -CH2OH group, the amino acid is serine. Many amino acid side chains contain a functional group (the side chain of serine, for example, contains a primary alcohol), while others, like alanine, lack a functional group, and contain only a simple alkane.
The two 'hooks' on an amino acid monomer are the amine and carboxylate groups. Proteins (polymers of ~50 amino acids or more) and peptides (shorter polymers) are formed when the amino group of one amino acid monomer reacts with the carboxylate carbon of another amino acid to form an amide linkage, which in protein terminology is a peptide bond. Which amino acids are linked, and in what order — the protein sequence — is what distinguishes one protein from another, and is coded for by an organism's DNA. Protein sequences are written in the amino terminal (N-terminal) to carboxylate terminal (C-terminal) direction, with either three-letter or single-letter abbreviations for the amino acids. Below is a four amino acid peptide with the sequence "cysteine - histidine - glutamate - methionine". Using the single-letter code, the sequence is abbreviated CHEM.
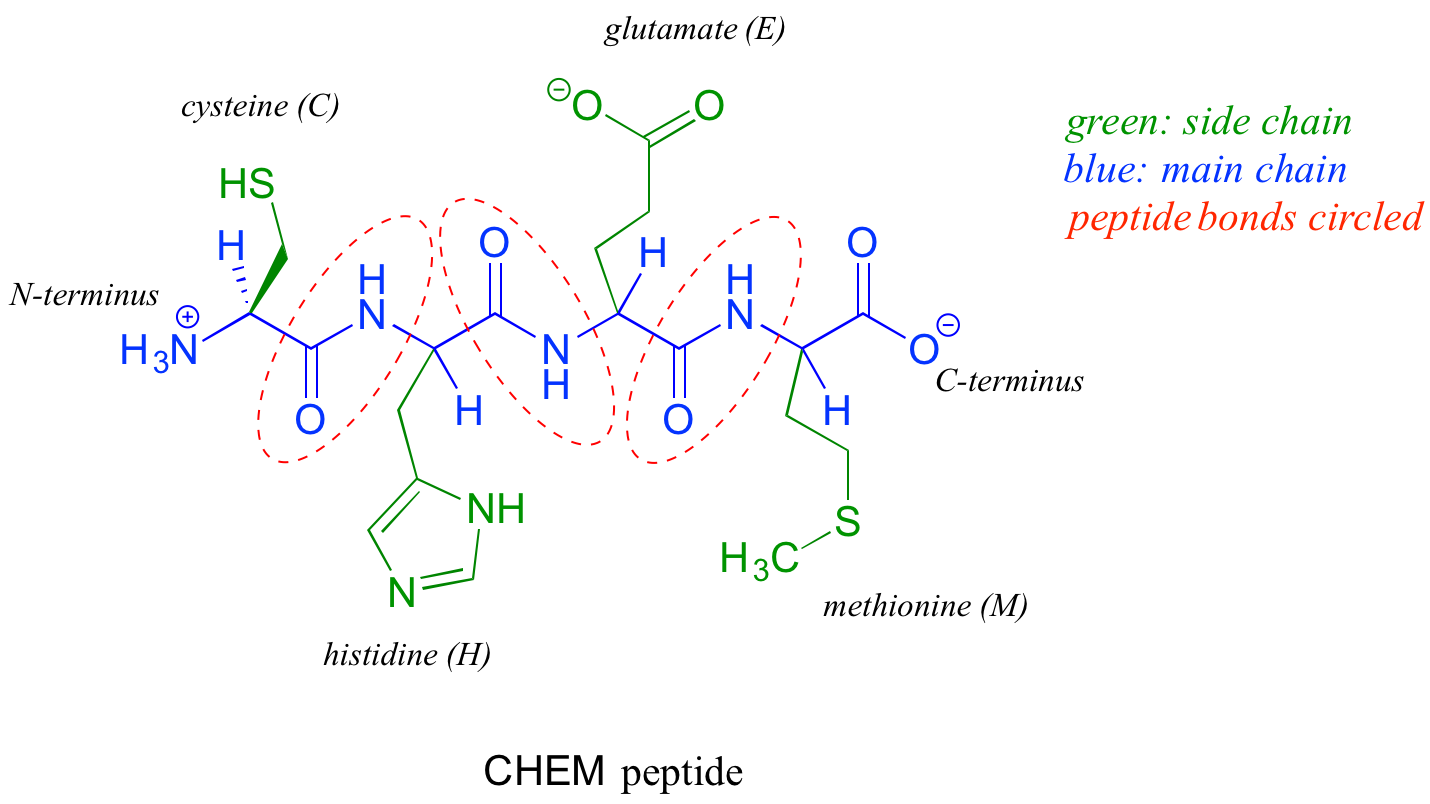
When an amino acid is incorporated into a protein it loses a molecule of water and what remains is called a residue of the original amino acid. Thus we might refer to the 'glutamate residue' at position 3 of the CHEM peptide above.
Once a protein polymer is constructed, it in many cases folds up very specifically into a three-dimensional structure, which often includes one or more 'binding pockets' in which other molecules can be bound. It is this shape of this folded structure, and the precise arrangement of the functional groups within the structure (especially in the area of the binding pocket) that determines the function of the protein.
Enzymes are proteins that catalyze biochemical reactions. One or more reacting molecules — often called substrates — become bound in the active site pocket of an enzyme, where the actual reaction takes place. Receptors are proteins that bind specifically to one or more molecules — referred to as ligands — to initiate a biochemical process. For example, we saw in the introduction to this chapter that the TrpVI receptor in mammalian tissues binds capsaicin (from hot chili peppers) in its binding pocket and initiates a heat/pain signal which is sent to the brain.
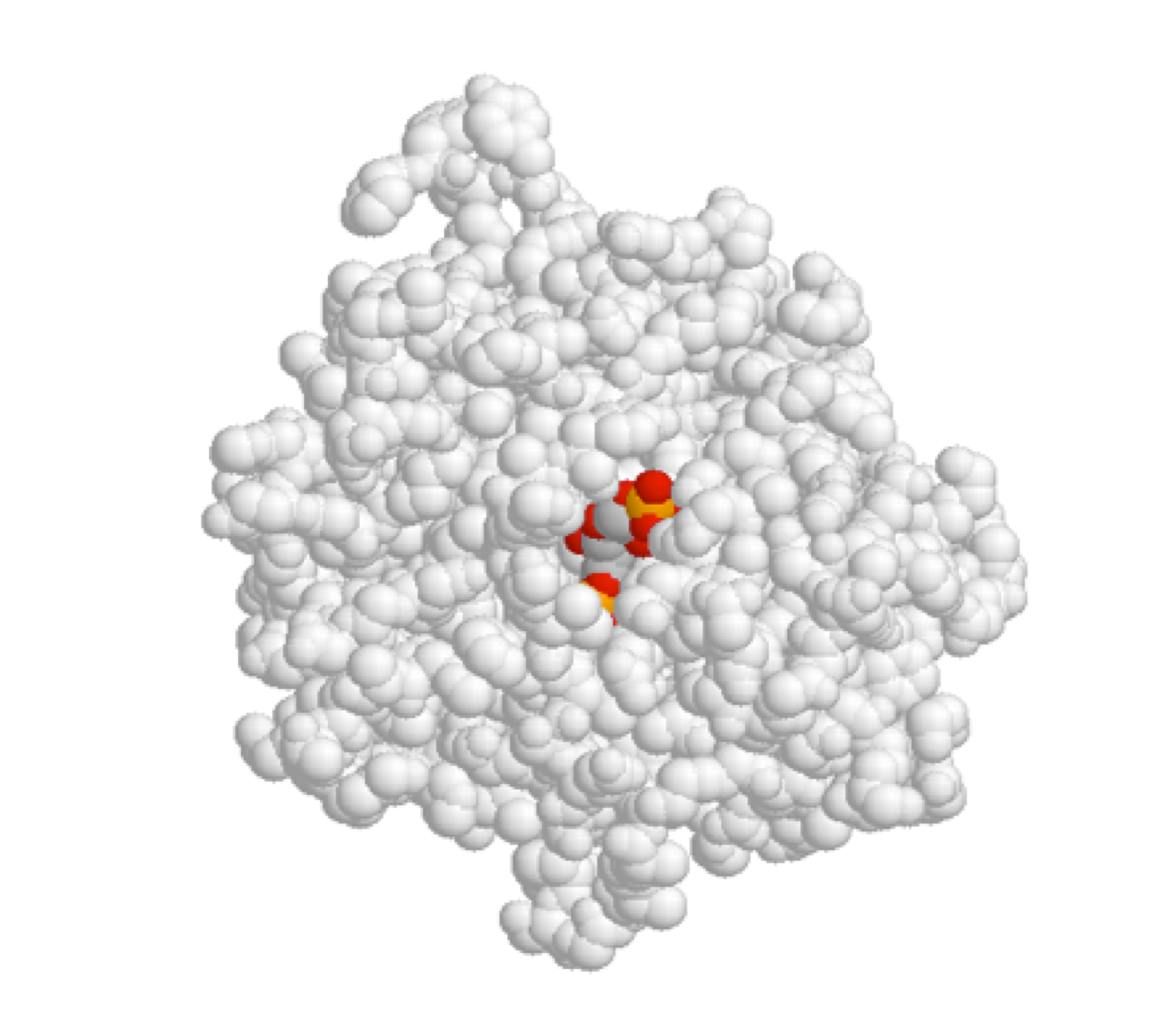
Shown below is an image of the glycolytic enzyme fructose-1,6-bisphosphate aldolase (in gray), with the substrate molecule bound inside the active site pocket.