
2.6: Structure and Function - Nucleic Acids
- Page ID
- 7813

Source: BiochemFFA_2_5.pdf. The entire textbook is available for free from the authors at http://biochem.science.oregonstate.edu/content/biochemistry-free-and-easy
The nucleic acids, DNA and RNA, may be thought of as the information molecules of the cell. In this section, we will examine the structures of DNA and RNA, and how these structures are related to the functions these molecules perform.

We will begin with DNA, which is the hereditary information in every cell, that is copied and passed on from generation to generation. The race to elucidate the structure of DNA was one of the greatest stories of 20th century science. Discovered in 1869 by Friedrich Miescher, DNA was identified as the genetic material in experiments in the 1940s led by Oswald Avery, Colin MacLeod, and Maclyn McCarty. X-ray diffraction work of Rosalind Franklin and the observations of Erwin Chargaff were combined by James Watson and Francis Crick to form a model of DNA that we are familiar with today. Their famous paper, in the April 25, 1953 issue of Nature, opened the modern era of molecular biology. Arguably, that one-page paper has had more scientific impact per word than any other research article ever published. Today, every high school biology student is familiar with the double helical structure of DNA and knows that G pairs with C and A with T.
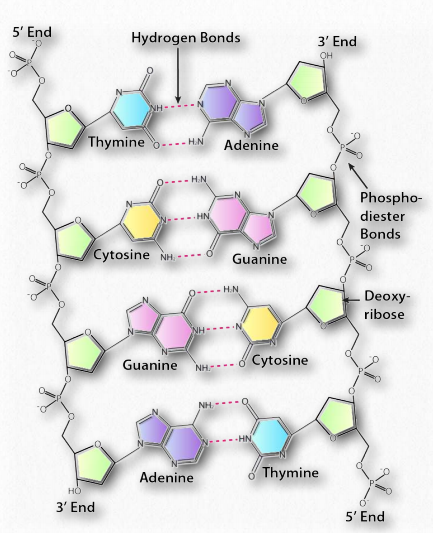
The double helix, made up of a pair of DNA strands, has at its core, bases joined by hydrogen bonds to form base pairs - adenine always paired with thymine, and guanine invariably paired with cytosine. Two hydrogen bonds are formed between adenine and thymine, but three hydrogen bonds hold together guanine and cytosine (Figure 2.127).
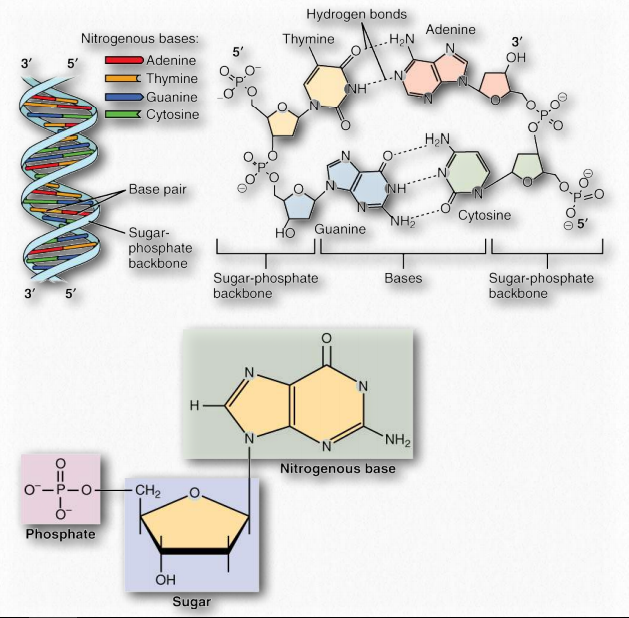
The complementary structure immediately suggested to Watson and Crick how DNA might be (and in fact, is) replicated and it further explains how information is DNA is transmitted to RNA for the synthesis of proteins. In addition to the hydrogen bonds between bases of each strand, the double helix is held together by hydrophobic interactions of the stacked, non-polar bases. Crucially, the sequence of the bases in DNA carry the information for making proteins. Read in groups of three, the sequence of the bases directly specifies the sequence of the amino acids in the encoded protein.
Structure
A DNA strand is a polymer of nucleoside monophosphates held together by phosphodiester bonds. Two such paired strands make up the DNA molecule, which is then twisted into a helix. In the most common Bform, the DNA helix has a repeat of 10.5 base pairs per turn, with sugars and phosphate forming the covalent phosphodiester “backbone” of the molecule and the adenine, guanine, cytosine, and thymine bases oriented in the middle where they form the now familiar base pairs that look like the rungs of a ladder.
Building blocks
The term nucleotide refers to the building blocks of both DNA (deoxyribonucleoside triphosphates, dNTPs) and RNA (ribonucleoside triphosphates, NTPs). In order to discuss this important group of molecules, it is necessary to define some terms.
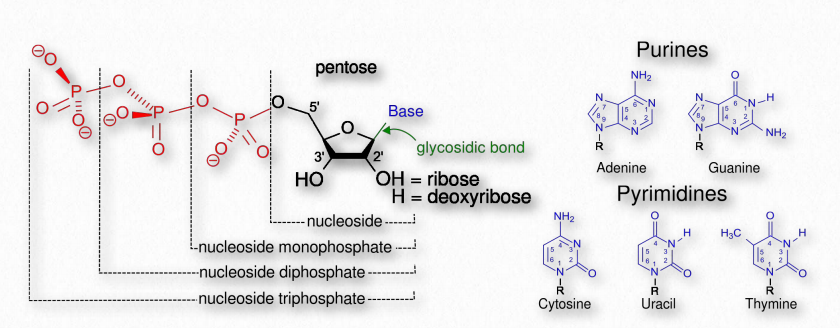
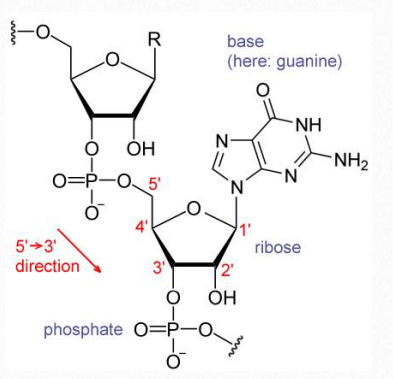
Nucleotides contain three primary structural components. These are a nitrogenous base, a pentose sugar, and at least one phosphate. Molecules that contain only a sugar and a nitrogenous base (no phosphate) are called nucleosides. The nitrogenous bases found in nucleic acids include adenine and guanine (called purines) and cytosine, uracil, or thymine (called pyrimidines). There are two sugars found in nucleotides - deoxyribose and ribose (Figure 2.128). By convention, the carbons on these sugars are labeled 1’ to 5’. (This is to distinguish the carbons on the sugars from those on the bases, which have their carbons simply labeled as 1, 2, 3, etc.) Deoxyribose differs from ribose at the 2’ position, with ribose having an OH group, where deoxyribose has H.
Nucleotides containing deoxyribose are called deoxyribonucleotides and are the forms found in DNA. Nucleotides containing ribose are called ribonucleotides and are found in RNA. Both DNA and RNA contain nucleotides with adenine, guanine, and cytosine, but with very minor exceptions, RNA contains uracil nucleotides, whereas DNA contains thymine nucleotides. When a base is attached to a sugar, the product, a nucleoside, gains a new name.
- uracil-containing = uridine (attached to ribose) / deoxyuridine (attached to deoxyribose)
- thymine-containing = ribothymidine (attached to ribose) / thymidine (attached to deoxyribose)
- cytosine-containing = cytidine (attached to ribose - Figure 2.129) / deoxycytidine (attached to deoxyribose)
- guanine-containing = guanosine (attached to ribose) / deoxyguanosine (attached to deoxyribose)
- adenine-containing = adenosine (attached to ribose) / deoxyadenosine (attached to deoxyribose)
Of these, deoxyuridine and ribothymidine are the least common. The addition of one or more phosphates to a nucleoside makes it a nucleotide. Nucleotides are often referred to as nucleoside phosphates, for this reason. The number of phosphates in the nucleotide is indicated by the appropriate prefixes (mono, di or tri).
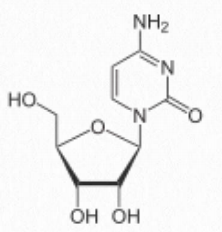
Thus, cytidine, for example, refers to a nucleoside (no phosphate), but cytidine monophosphate refers to a nucleotide (with one phosphate). Addition of second and third phosphates to a nucleoside monophosphate requires energy, due to the repulsion of negatively charged phosphates and this chemical energy is the basis of the high energy triphosphate nucleotides (such as ATP) that fuel cells.
Though ATP is the most common and best known cellular energy source, each of the four ribonucleotides plays important roles in providing energy. GTP, for example, is the energy source for protein synthesis (translation) as well as for a handful of metabolic reactions. A bond between UDP and glucose makes UDP-glucose, the building block for making glycogen. CDP is similarly linked to several different molecular building blocks important for glycerophospholipid synthesis (such as CDP-diacylglycerol).
The bulk of ATP made in cells is not from directly coupled biochemical metabolism, but rather by the combined processes of electron transport and oxidative phosphorylation in mitochondria and/or photophosphorylation that occurs in the chloroplasts of photosynthetic organisms. Triphosphate energy in ATP is transferred to the other nucleosides/nucleotides by action of enzymes called kinases. For example, nucleoside diphosphokinase (NDPK) catalyzes the following reaction
\[\ce{ATP + NDP <-> ADP + NTP}\]
where ‘N’ of “NDP” and “NTP corresponds to any base. Other kinases can put single phosphates onto nucleosides or onto nucleoside monophosphates using energy from ATP.
Deoxyribonucleotides
Individual deoxyribonucleotides are derived from corresponding ribonucleoside diphosphates via catalysis by the enzyme known as ribonucleotide reductase (RNR). The deoxyribonucleoside diphosphates are then converted to the corresponding triphosphates (dNTPs) by the addition of a phosphate group. Synthesis of nucleotides containing thymine is distinct from synthesis of all of the other nucleotides and will be discussed later.
Building DNA strands
Each DNA strand is built from dNTPs by the formation of a phosphodiester bond, catalyzed by DNA polymerase, between the 3’OH of one nucleotide and the 5’ phosphate of the next. The result of this directional growth of the strand is that the one end of the strand has a free 5’ phosphate and the other a free 3’ hydroxyl group (Figure 2.130). These are designated as the 5’ and 3’ ends of the strand.
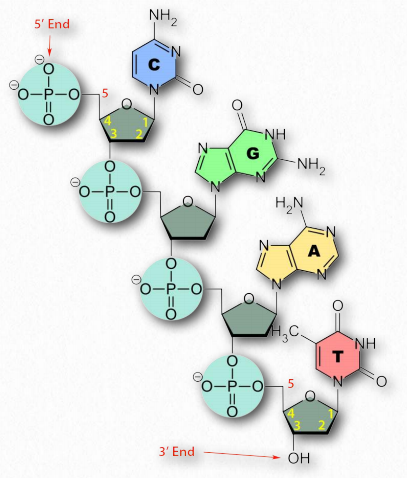
Figure 2.131 shows two strands of DNA (left and right). The strand on the left, from 5’ to 3’ reads T-C-G-A, whereas the strand on the right, reading from 5’ to 3’ is T-C-G-A. The strands in a double-stranded DNA are arranged in an anti-parallel fashion with the 5’ end of one strand across from the 3’ end of the other.
Hydrogen bonds
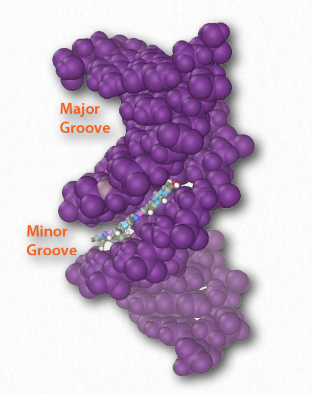
Hydrogen bonds between the base pairs hold a nucleic acid duplex together, with two hydrogen bonds per A-T pair (or per A-U pair in RNA) and three hydrogen bonds per G-C pair. The B-form of DNA has a prominent major groove and a minor groove tracing the path of the helix (Figure 2.132). Proteins, such as transcription factors bind in these grooves and access the hydrogen bonds of the base pairs to “read” the sequence therein.
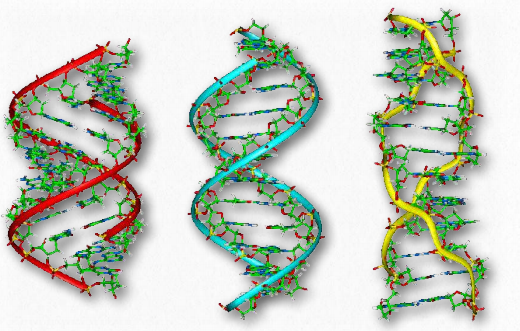
Other forms of DNA besides the B-form (Movie 2.5) are known (Figure 2.133). One of these, the A-form, was identified by Rosalind Franklin in the same issue of Nature as Watson and Crick’s paper. Though the A-form structure is a relatively minor form of DNA and resembles the B-form, it turns out to be important in the duplex form of RNA and in RNA-DNA hybrids. Both the A form and the B-form of DNA have the helix oriented in what is termed the right-handed form.
Movie 2.5 - B-form DNA duplex rotating in space Wikipedia
Z-DNA
The A-form and the B-form stand in contrast to another form of DNA, known as the Z-form. ZDNA, as it is known, has the same base-pairing rules as the B and A forms, but instead has the helices twisted in the opposite direction, making a left-handed helix (Figure 2.133). The Z-form has a sort of zig-zag shape, giving rise to the name Z-DNA.
In addition, the helix is rather stretched out compared to the A- and B-forms. Why are there different topological forms of DNA? The answer relates to both superhelical tension and sequence bias. Sequence bias means that certain sequences tend to favor the “flipping” of Bform DNA into other forms. ZDNA forms are favored by long stretches of alternating Gs and Cs. Superhelical tension is discussed below.
Superhelicity
Short stretches of linear DNA duplexes exist in the B-form and have 10.5 base pairs per turn. Double helices of DNA in the cell can vary in the number of base pairs per turn they contain. There are several reasons for this. For example, during DNA replication, strands of DNA at the site of replication get unwound at the rate of 6000 rpm by an enzyme called helicase. The effect of such local unwinding at one place in a DNA has the effect increasing the winding ahead of it. Unrelieved, such ‘tension’ in a DNA duplex can result in structural obstacles to replication.
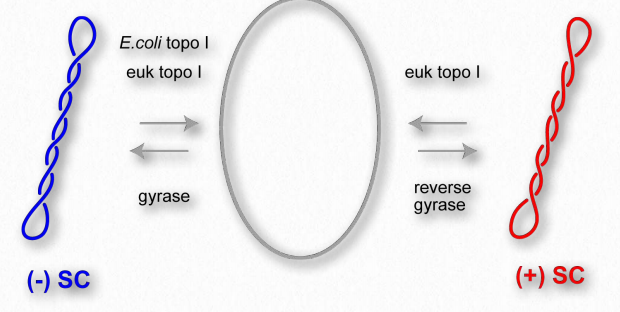
Such adjustments can occur in three ways. First, tension can provide the energy for ‘flipping’ DNA structure. Z-DNA can arise as a means of relieving the tension. Second, DNA can ‘supercoil’ to relieve the tension (Figures 2.134 & 2.135). In this method, the duplex crosses over itself repeatedly, much like a rubber band will coil up if one holds one section in place and twists another part of it. Third, enzymes called topoisomerases can act to relieve or, in some cases, increase the tension by adding or removing twists in the DNA.

Topological isomers
As noted, so-called “relaxed” DNA has 10.5 base pairs per turn. Each turn corresponds to one twist of the DNA. Using enzymes, it is possible to change the number of base pairs per turn. In either the case of increasing or decreasing the twists per turn, tension is introduced into the DNA structure. If the tension cannot be relieved, the DNA duplex will act to relieve the strain, as noted. This is most easily visualized for circular DNA, though long linear DNA (such as found in eukaryotic chromosomes) or DNAs constrained in other ways will exhibit the same behavior.
Parameters
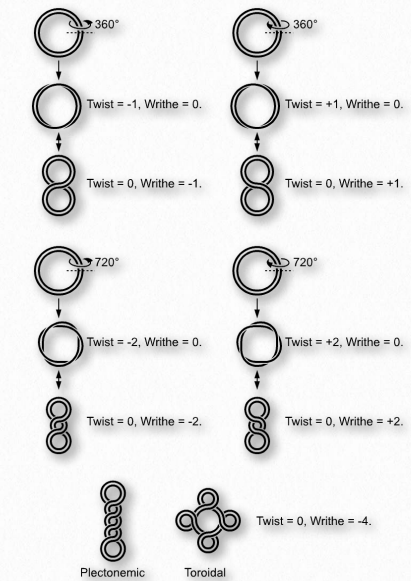
To understand topologies, we introduce the concepts of ‘writhe’ and ‘linking number’. First, imagine either opening a closed circle of DNA and either removing one twist or adding one twist and then re-forming the circle. Since the strands have no free ends, they cannot relieve the induced tension by re-adding or removing the twists at their ends, respectively. Instead, the tension is relieved by “superhelices” that form with crossing of the double strands over each other (figure 8 structures in Figure 2.136). Though it is not apparent to visualize, each crossing of the double strands in this way allows twists to be increased or decreased correspondingly. Thus, superhelicity allows the double helix to reassume 10.5 base pairs per turn by adding or subtracting twists as necessary and replacing them with writhes.
We write the equation L= T + W where T is the number of twists in a DNA, W is the number of writhes, and L is the linking number. The linking number is therefore the sum of the twists and writhes. Interestingly, inside of cells, DNAs typically are in a supercoiled form. Supercoiling affects the size of the DNA (compacts it) and also the expression of genes within the DNA, some having enhanced expression and some having reduced expression when supercoiling is present. Enzymes called topoisomerases alter the superhelical density of DNAs and play roles in DNA replication, transcription, and control of gene expression. They work by making cuts in one strand (Type I topoisomerases) or both strands (Type II topoisomerases) and then add or subtract twists as appropriate to the target DNA. After that process is complete, the topoisomerase re-ligates the nick/cut it had made in the DNA in the first step.
Topoisomerases may be the targets of antibiotics. The family of antibiotics known as fluoroquinolones work by interfering with the action of bacterial type II topoisomerases. Ciprofloxacin also preferentially targets bacterial type II topoisomerases. Other topoisomerase inhibitors target eukaryotic topoisomerases and are used in anti-cancer treatments.
RNA
The structure of RNA (Figure 2.137) is very similar to that of a single strand of DNA. Built of ribonucleotides, joined together by the same sort of phosphodiester bonds as in DNA, RNA uses uracil in place of thymine. In cells, RNA is assembled by RNA polymerases, which copy a DNA template in the much same way that DNA polymerases replicate a parental strand. During the synthesis of RNA, uracil is used across from an adenine in the DNA template. The building of messenger RNAs by copying a DNA template is a crucial step in the transfer of the information in DNA to a form that directs the synthesis of protein. Additionally, ribosomal and transfer RNAs serve important roles in “reading” the information in the mRNA codons and in polypeptide synthesis. RNAs are also known to play important roles in the regulation of gene expression.
RNA world
The discovery, in 1990, that RNAs could play a role in catalysis, a function once thought to be solely the domain of proteins, was followed by the discovery of many more so-called ribozymes- RNAs that functioned as enzymes. This suggested the answer to a long-standing chicken or egg puzzle - if DNA encodes proteins, but the replication of DNA requires proteins, how did a replicating system come into being? This problem could be solved if the first replicator was RNA, a molecule that can both encode information and carry out catalysis. This idea, called the “RNA world” hypothesis, suggests that DNA as genetic material and proteins as catalysts arose later, and eventually prevailed because of the advantages they offer. The lack of a 2’OH on deoxyribose makes DNA more stable than RNA. The double-stranded structure of DNA also provides an elegant way to easily replicate it. RNA catalysts, however, remain, as remnants of that early world. In fact, the formation of peptide bonds, essential for the synthesis of proteins, is catalyzed by RNA.
Secondary structure
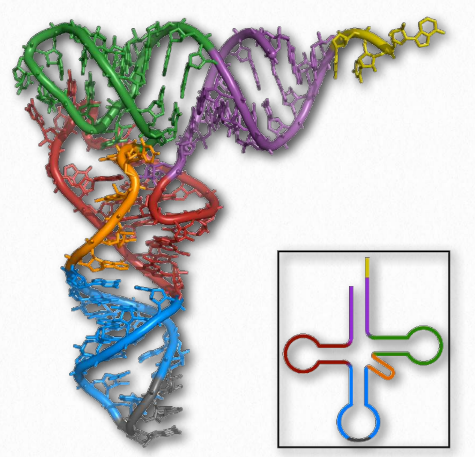
With respect to structure, RNAs are more varied than their DNA cousin. Created by copying regions of DNA, cellular RNAs are synthesized as single strands, but they often have self-complementary regions leading to “foldbacks” containing duplex regions. These are most easily visualized in the ribosomal RNAs (rRNAs) and transfer RNAs (tRNAs) (Figure 2.138), though other RNAs, including messenger RNAs (mRNAs), small nuclear RNAs (snRNAs), microRNAs (Figure 2.139), and small interfering RNAs (siRNAs) may each have double helical regions as well.

Base pairing
Base pairing in RNA is slightly different than DNA. This is due to the presence of the base uracil in RNA in place of thymine in DNA. Like thymine, uracil forms base pairs with adenine, but unlike thymine, uracil can, to a limited extent, also base pair with guanine, giving rise to many more possibilities for pairing within a single strand of RNA.
These additional base pairing possibilities mean that RNA has many ways it can fold upon itself that single-stranded DNA cannot. Folding, of course, is critical for protein function, and we now know that, like proteins, some RNAs in their folded form can catalyze reactions just like enzymes. Such RNAs are referred to as ribozymes. It is for this reason scientists think that RNA was the first genetic material, because it could not only carry information, but also catalyze reactions. Such a scheme might allow certain RNAs to make copies of themselves, which would, in turn, make more copies of themselves, providing a positive selection.
Stability
RNA is less chemically stable than DNA. The presence of the 2’ hydroxyl on ribose makes RNA much more prone to hydrolysis than DNA, which has a hydrogen instead of a hydroxyl. Further, RNA has uracil instead of thymine. It turns out that cytosine is the least chemically stable base in nucleic acids. It can spontaneously deaminate and in turn is converted to a uracil. This reaction occurs in both DNA and RNA, but since DNA normally has thymine instead of uracil, the presence of uracil in DNA indicates that deamination of cytosine has occurred and that the uracil needs to be replaced with a cytosine. Such an event occurring in RNA would be essentially undetectable, since uracil is a normal component of RNA. Mutations in RNA have much fewer consequences than mutations in DNA because they are not passed between cells in division.
Catalysis
RNA structure, like protein structure, has importance, in some cases, for catalytic function. Like random coils in proteins that give rise to tertiary structure, single-stranded regions of RNA that link duplex regions give these molecules a tertiary structure, as well. Catalytic RNAs, called ribozymes, catalyze important cellular reactions, including the formation of peptide bonds in ribosomes (Figure 2.114). DNA, which is usually present in cells in strictly duplex forms (no tertiary structure, per se), is not known to be involved in catalysis.
RNA structures are important for reasons other than catalysis. The 3D arrangement of tRNAs is necessary for enzymes that attach amino acids to them to do so properly. Further, small RNAs called siRNAs found in the nucleus of cells appear to play roles in both gene regulation and in cellular defenses against viruses. The key to the mechanisms of these actions is the formation of short foldback RNA structures that are recognized by cellular proteins and then chopped into smaller units. One strand is copied and used to base pair with specific mRNAs to prevent the synthesis of proteins from them.
Denaturing nucleic acids
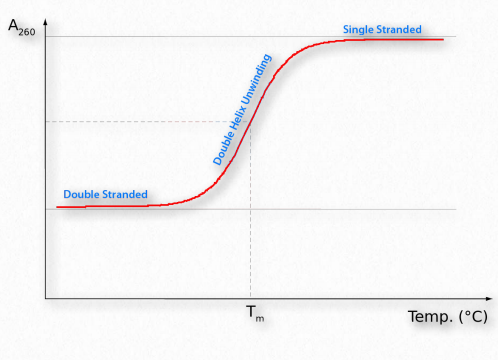
Like proteins, nucleic acids can be denatured. Forces holding duplexes together include hydrogen bonds between the bases of each strand that, like the hydrogen bonds in proteins, can be broken with heat or urea. (Another important stabilizing force for DNA arises from the stacking interactions between the bases in a strand.) Single strands absorb light at 260 nm more strongly than double strands. This is known as the hyperchromic effect (Figure 2.141)and is a consequence of the disruption of interactions among the stacked bases. The changes in absorbance allow one to easily follow the course of DNA denaturation. Denatured duplexes can readily renature when the temperature is lowered below the “melting temperature” or Tm, the temperature at which half of the DNA strands are in duplex form. Under such conditions, the two strands can re-form hydrogen bonds between the complementary sequences, returning the duplex to its original state. For DNA, strand separation and rehybridization are important for the technique known as the polymerase chain reaction (PCR). Strand separation of DNA duplexes is accomplished in the method by heating them to boiling. Hybridization is an important aspect of the method that requires single stranded primers to “find” matching sequences on the template DNA and form a duplex. Considerations for efficient hybridization (also called annealing) include temperature, salt concentration, strand concentration, and magnesium ion levels (for more on PCR, see HERE).
DNA packaging
DNA is easily the largest macromolecule in a cell. The single chromosome in small bacterial cells, for example, can have a molecular weight of over 1 billion Daltons. If one were to take all of the DNA of human chromosomes from a single cell and lay them end to end, they would be over 7 feet long. Such an enormous molecule demands careful packaging to fit within the confines of a nucleus (eukaryotes) or a tiny cell (bacteria). The chromatin system of eukaryotes is the best known, but bacteria, too, have a system for compacting DNA.
DNA in Bacteria
In bacteria, there is no nucleus for the DNA. Instead, DNA is contained in a structure called a nucleoid (Figure 2.142). It contains about 60% DNA with much of the remainder comprised of RNAs and transcription factors. Bacteria do not have histone proteins that DNA wrap around, but they do have proteins that help organize the DNA in the cell - mostly by making looping structures.
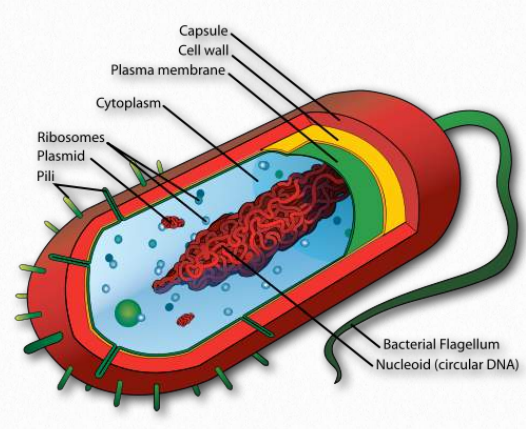
These proteins are known as Nucleoid Associated Proteins and include ones named HU, H-NS, Fis, CbpA, and Dps. Of these, HU most resembles eukaryotic histone H2B and binds to DNA non-specifically. The proteins associate with the DNA and can also cluster, which may be the origin of the loops. It is likely these proteins play a role in helping to regulate transcription and respond to DNA damage. They may also be involved in recombination.
Eukaryotes
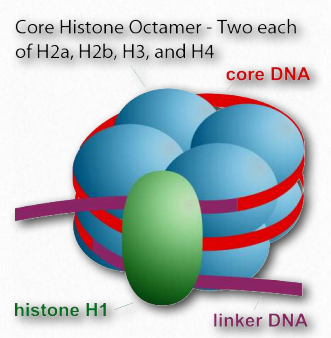
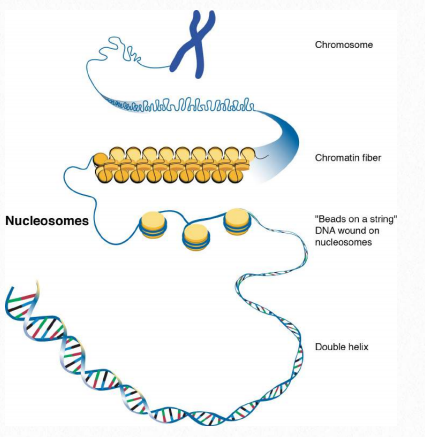
The method eukaryotes use for compacting DNA in the nucleus is considerably different, and with good reason - eukaryotic DNAs are typically much larger than prokaryotic DNAs, but must fit into a nucleus that is not much bigger than a prokaryotic cell. Human DNA, for example, is about 1000 times longer than c DNA. The strategy employed in eukaryotic cells is that of spooling - DNA is coiled around positively charged proteins called histones. These proteins, whose sequence is very similar in cells as diverse as yeast and humans, come in four types, dubbed H1, H2a, H2b, H3, and H4. A sixth type, referred to as H5 is actually an isoform of H1 and is rare. Two each of H2a, H2b, H3, and H4 are found in the core structure of what is called the fundamental unit of chromatin - the nucleosome (Figure 2.143).
Octamer
The core of 8 proteins is called an octamer. The stretch of DNA wrapped around the octamer totals about 147 base pairs and makes 1 2/3 turns around it. This complex is referred to as a core particle (Figure 2.144). A linker region of about 50-80 base pairs separate core particles. The term nucleosome then refers to a a core particle plus a linker region (Figure 2.143). Histone H1 sits near the junction of the incoming DNA and the histone core. It is often referred to as the linker histone. In the absence of H1, non-condensed nucleosomes resemble “beads on a string” when viewed in an electron microscope.
Histones

Histone proteins are similar in structure and are rich in basic amino acids, such as lysine and arginine (Figure 2.145). These amino acids are positively charged at physiological pH, with enables them to form tight ionic bonds with the negatively charged phosphate backbone of DNA.
For DNA, compression comes at different levels (Figure 2.146). The first level is at the nucleosomal level. Nucleosomes are stacked and coiled into higher order structures. 10 nm fibers are the simplest higher order structure (beads on a string) and they grow in complexity. 30 nm fibers consist of stacked nucleosomes and they are packed tightly. Higher level packing produces the metaphase chromosome found in meiosis and mitosis.
The chromatin complex is a logistical concern for the processes of DNA replication and (particularly) gene expression where specific regions of DNA must be transcribed. Altering chromatin structure is therefore an essential function for transcriptional activation in eukaryotes. One strategy involves adding acetyl groups to the positively charged lysine side chains to “loosen their grip” on the negatively charged DNA, thus allowing greater access of proteins involved in activating transcription to gain access to the DNA. The mechanisms involved in eukaryotic gene expression are
Ames test
The Ames test (Figure 2.147) is an analytical method that allows one to determine whether a compound causes mutations in DNA (is mutagenic) or not. The test is named for Dr. Bruce Ames, a UC Berkeley emeritus professor who was instrumental in creating it. In the procedure, a single base pair of a selectable marker of an organism is mutated in a plasmid to render it nonfunctional. In the example, a strain of Salmonella is created that lacks the ability to grow in the absence of histidine. Without histidine, the organism will not grow, but if that one base in the plasmid’s histidine gene gets changed back to its original base, a functional gene will be made and the organism will be able to grow without histidine.
A culture of the bacterium lacking the functional gene is grown with the supply of histidine it requires. It is split into two vials. To one of the vials, a compound that one wants to test the mutagenicity of is added. To the other vial, nothing is added. The bacteria in each vial are spread onto plates lacking histidine. In the absence of mutation, no bacteria will grow. The more colonies of bacteria that grow, the more mutation happened. Note that even the vial without the possible mutagenic compound will have a few colonies grow, as a result of mutations unlinked to the potential mutagen.
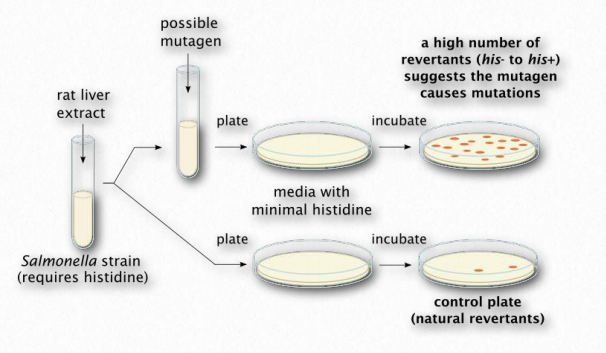
Mutation happens in all cells at a low level. If the plate with the cells from the vial with the compound has more colonies than the cells from the control vial (no compound), then that would be evidence that the compound causes more mutations than would normally occur and it is therefore a mutagen. On the other hand, if there was no significant difference in the number of colonies on each plate, then that would suggest it is not mutagenic. The test is not perfect - it identifies about 90% of known mutagens - but its simplicity and inexpensive design make it an excellent choice for an initial screen of a compound.