
4.23: 2020_Spring_Bis2a_Facciotti_Lecture_23
- Page ID
- 27865
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)
Learning objectives associated with 2020_Spring_Bis2a_Facciotti_Lecture_23
|
Protein Synthesis

Introduction
The process of translation in biology is the decoding
The resulting proteins are so important to the cell that their synthesis consumes more of a cell’s energy than any other metabolic process. Like DNA replication and transcription, translation is a complex molecular process that we can approach using both the Energy Story and Design Challenge rubrics. Describing the overall process, or steps, requires the accounting of the matter and energy before the process and after the process and a description of how that matter
Let us start by considering the basic problem. We have a strand of RNA (called
(a) decode the chemical language of nucleotides into the language of amino acids,
(b) join amino acids in a very specific manner,
(c) complete this process with reasonable accuracy, and
(d) do this at a reasonable speed. Reasonable
As before, we can identify subproblems.
(a) How does our molecular machine determine where and when to work?
(b) How does the molecular machine coordinate decoding and bond formations?
(c) Where does the energy for this process come from and how much?
(d) How does the machine know where to stop?
Other questions and functional problems/challenges will arise as we dig deeper.
The point, as always, is that even knowing no specifics about translation we can use our imaginations, curiosity and common sense to imagine some requirements for the process that we will need to learn more about. Understanding these questions as the context for what follows is key.
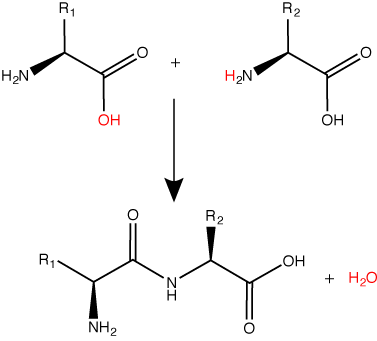
A peptide bond links the carboxyl end of one amino acid with the amino end of another, expelling one water molecule. The R1 and R2 designation refer to the side chain of the two amino acids.
Attribution:
Protein Synthesis Machinery
The components that go into the process
Many molecules and macromolecules contribute to the process of translation. While the exact composition of "the players" in the process may vary from species to species - for instance, ribosomes may comprise different numbers of
Reminder: Amino acids
Let us recall that the basic structure of amino acids
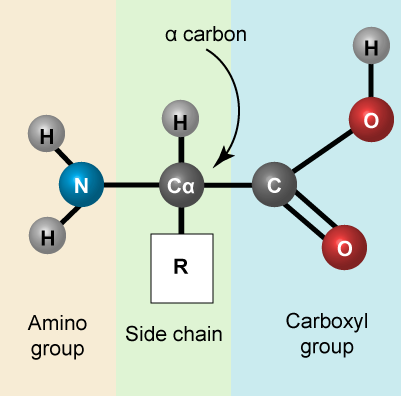

The 20 common amino acids.
Attribution:
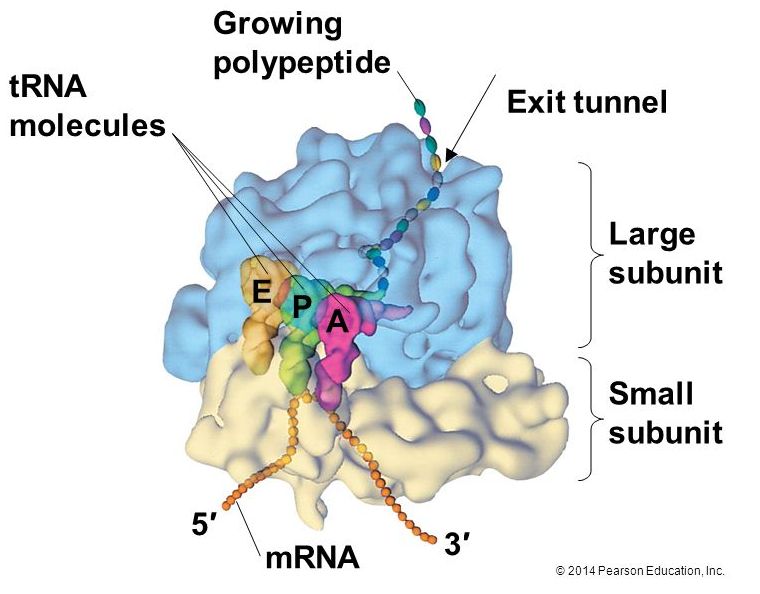
Ribosomes
A ribosome is a complex macromolecule composed of structural and catalytic
Ribosomes exist in the cytoplasm in bacteria and archaea and in the cytoplasm and on the rough endoplasmic reticulum in eukaryotes. Mitochondria and chloroplasts also have their own ribosomes in the matrix and stroma, which look more similar to bacterial ribosomes (and have similar drug sensitivities), than the ribosomes just outside their outer membranes in the cytoplasm. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In
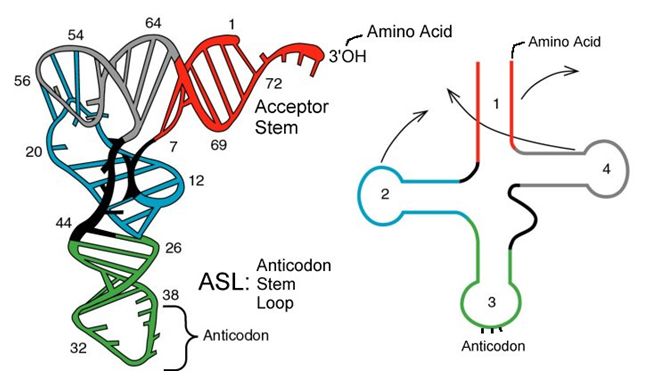
tRNAs
Of the 64 possible
Aminoacyl tRNA Synthetases
The process of pre-
The Mechanism of Protein Synthesis
Like in transcription, we can divide protein synthesis into three phases: initiation, elongation, and termination. The process of translation is similar in bacteria,
Translation Initiation
Bacterial vs Eukaryotic initiation
In
Instead of binding at the Shine-Dalgarno sequence, the eukaryotic initiation complex recognizes the 7-
Possible NB Discussion  Point
Point
Compare and contrast the initiation of translation with that of transcription — in what ways are these processes similar and in what ways do they differ?
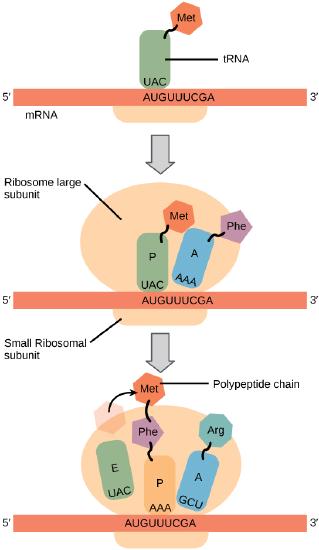
Translation Elongation
During translation elongation, the
The large ribosomal subunit comprises three compartments:
Elongation proceeds with charged
Possible NB Discussion Point
Tetracycline is an antibiotic on the World Health Organization’s List of Essential Medicines. It mitigates infections by blocking the A site on the bacterial ribosome. Another antibiotic, chloramphenicol, blocks peptidyl transfer. Describe the immediate and long-term effects of these two antibiotics. What other strategies can you think of to battle infection specifically at the level of translation?
The Genetic Code
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (
Three of the 64 codons
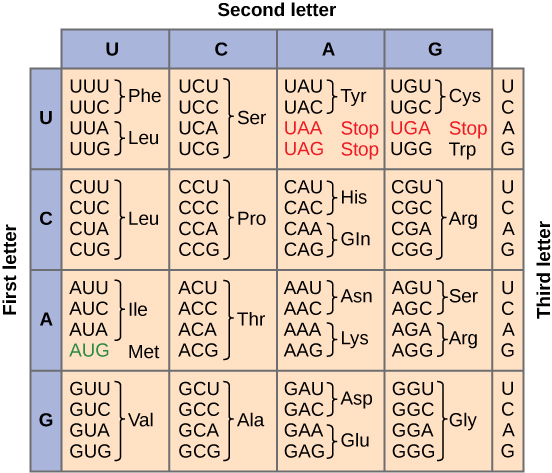
Redundant, not Ambiguous
The information in the genetic code is redundant. Multiple codons code for the same amino acid. For example, using the chart above, you can find 4 different codons that code for Valine, likewise, there are two codons that code for Leucine, etc. But the code is not ambiguous, meaning, that if
Translation Termination
Termination of translation occurs when a stop codon (UAA, UAG, or UGA)
Coupling between Transcription and Translation
As discussed previously, bacteria and archaea need not transport their RNA transcripts between a membrane bound
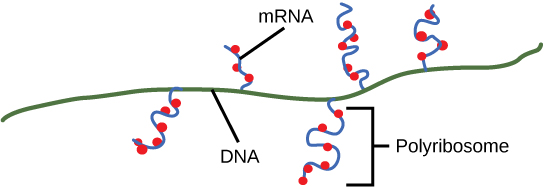
Protein Sorting
In
Since we have uncovered various mechanisms, the details of this process
Post-translational Protein Modification
After
Section Summary
The players in translation include the