
7.2: Analysis of STRs
- Page ID
- 72191
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Polymorphisms
The difference in nucleotide sequences between humans lies between 0.1-0.4%. This means that people are greater than 99% similar. But when you look at your classmates around the room, you can see that that small difference amounts to quite a bit of variation within our species. The bulk of these differences aren’t even within the coding sequences of genes but lie outside in regulatory regions that change the expression of those genes. Imagine if there were mutations to the coding sequences, this could be very deleterious to the well-being of the organism. We say that the coding sequences of genes that ultimately lead to proteins have selective pressure to remain the same. The areas outside of the coding sequences have a reduced and sometimes non-existent selection pressure. These areas are allowed to mutate in sequence and even expand or contract. Areas of changes or differences are called polymorphic (many forms). If you were to read a repetitive set of sequences and count the repetition, you’ would make mistakes and lose count. Likewise, DNA polymerase will make errors or stutter in areas of repetitiveness and produce polymorphic regions.
Tandem Repeats
A type of polymorphism occurs due to these repeats expanding and contracting in non-coding regions. These regions are called variable number tandem repeats (VNTRs)or sometimes short tandem repeats (STRs). Any region or location on a chromosome is referred to as locus (loci for plural). Scientists use polymorphic loci that are known to contain VNTRs/STRs in order to differentiate people based on their DNA. This is often used in forensic science or in maternity/paternity cases. Any variation of a locus is referred to as an allele. In standard genetics, we often think of an allele as a variation of a gene that would result in a difference in a physical manifestation of that gene. In the case of STRs, these alleles are simply a difference in the number of repeats. This means the length of DNA within this locus is either longer or shorter and gives rise to many different alleles. VNTRs are referred to as minisatellites while STRs are called microsatellites.
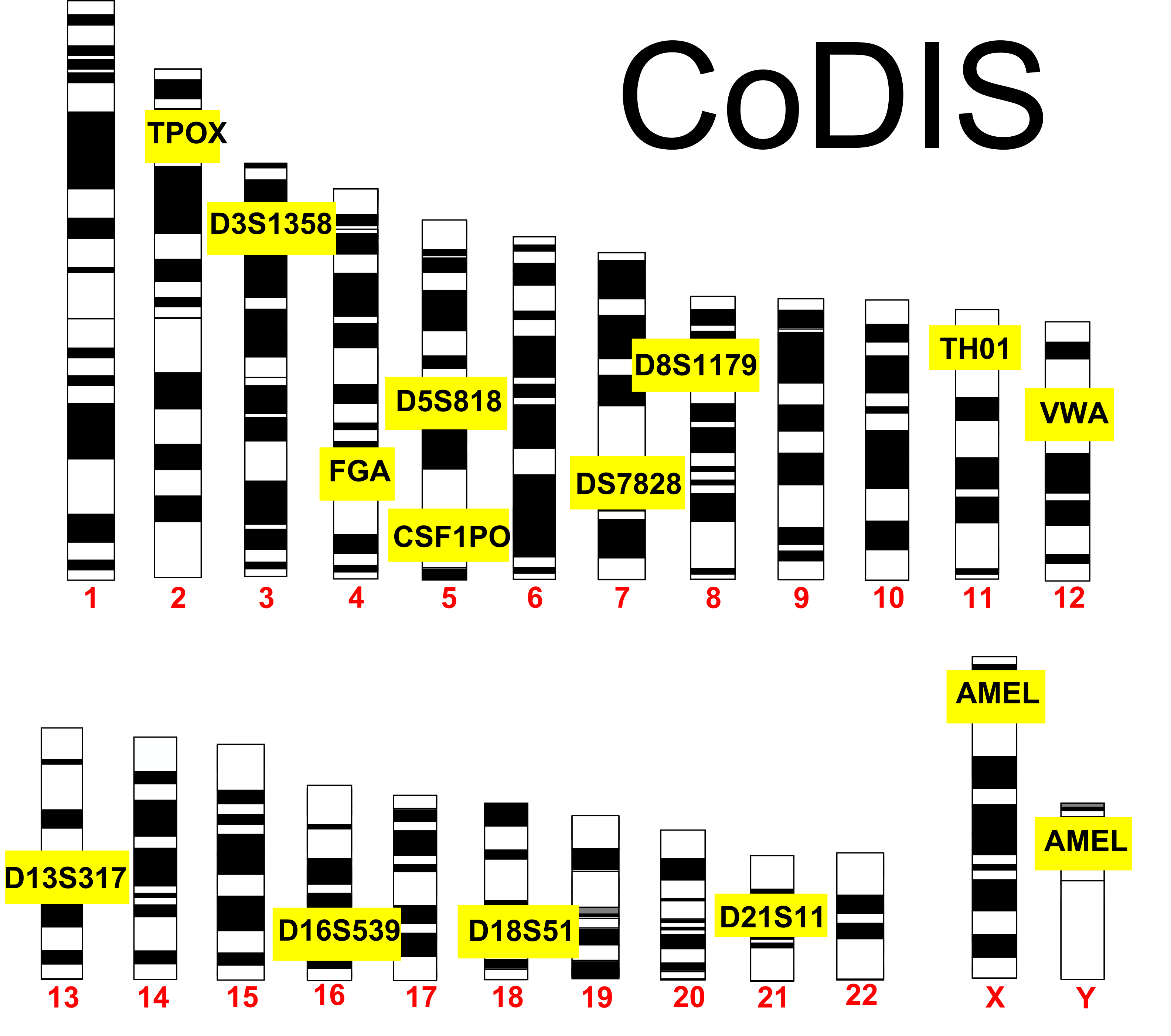
CoDIS
The FBI and local law enforcement agencies have developed a database called the Combined DNA Index System (CoDIS) that gathers data on a number of STRs. By establishing the number of repeats of a given locus, law enforcement officials can differentiate individuals based on the repeat length of these alleles. CoDIS uses a set of 20 loci that are tested together. As you would imagine, people are bound to have the same alleles of certain loci, especially if they were related. The use of 20 different loci makes it statistically improbable that 2 different people could be confused with each other. Think about this in terms of physical traits. As you increase the number of physical traits used to describe someone, you are less likely to confuse that person with someone else based on those combinations of traits. Using the CoDIS loci increases the stringency since there are many alleles for each locus. The twentieth locus in CoDIS (called AMEL) discriminates between male and female.
Crime Scene Investigation
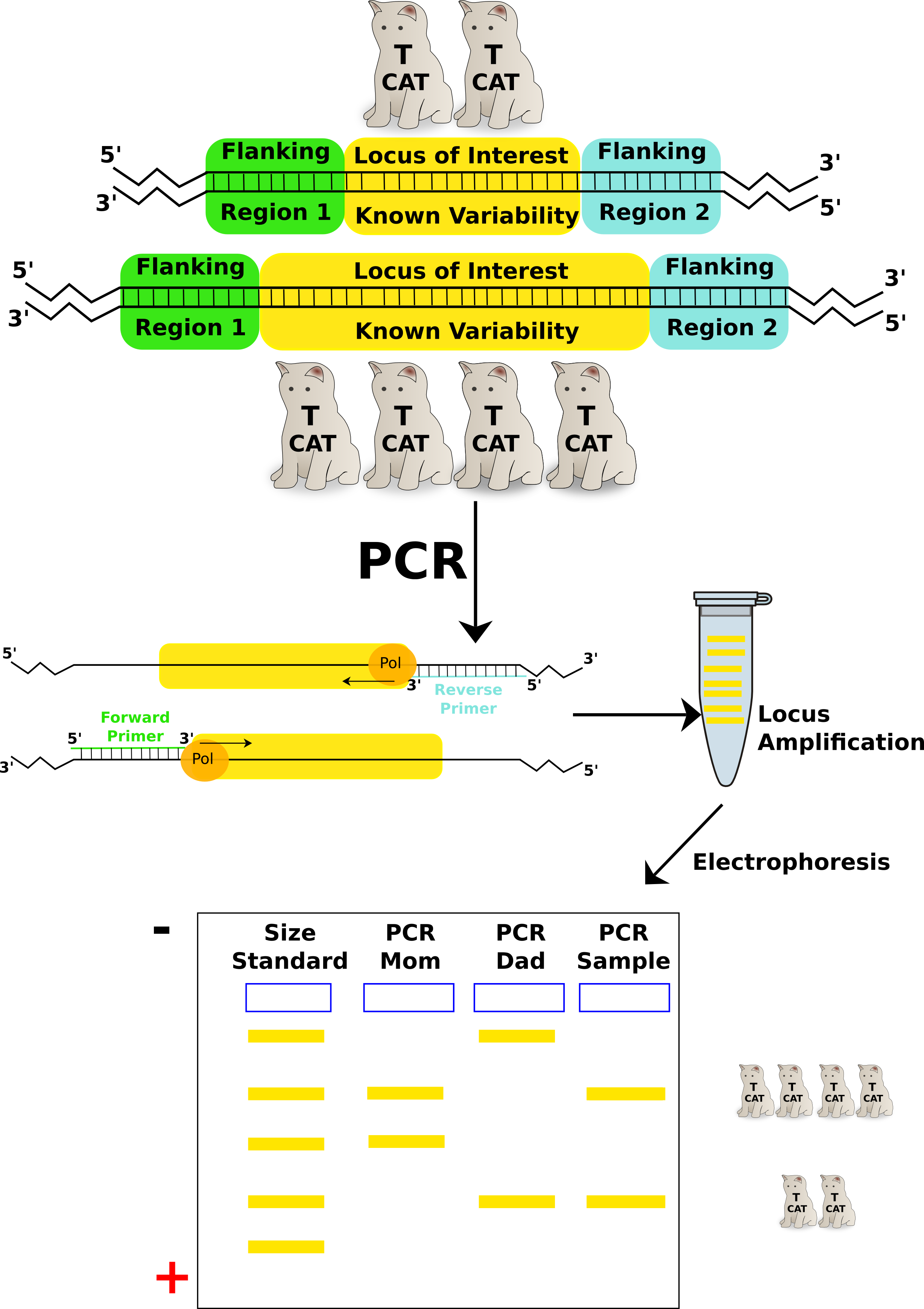
This lab uses a CoDIS locus called TH01. TH01 is a locus on chromosome 11 that has a repeating sequence of TCAT. There are reported to be between 3-14 repeats in this locus. With the exception of X and Y in a male, all chromosomes have a homologous partner. Therefore, each individual will have 2 alleles for each CoDIS locus.
At a crime scene, criminals don’t often leave massive amounts of tissue behind. Scant evidence in the form of a few cells found within bodily fluids or stray hairs can be enough to use as DNA evidence. DNA is extracted from these few cells and amplified by PCR using the specific primers that flank the STRs used in CoDIS.
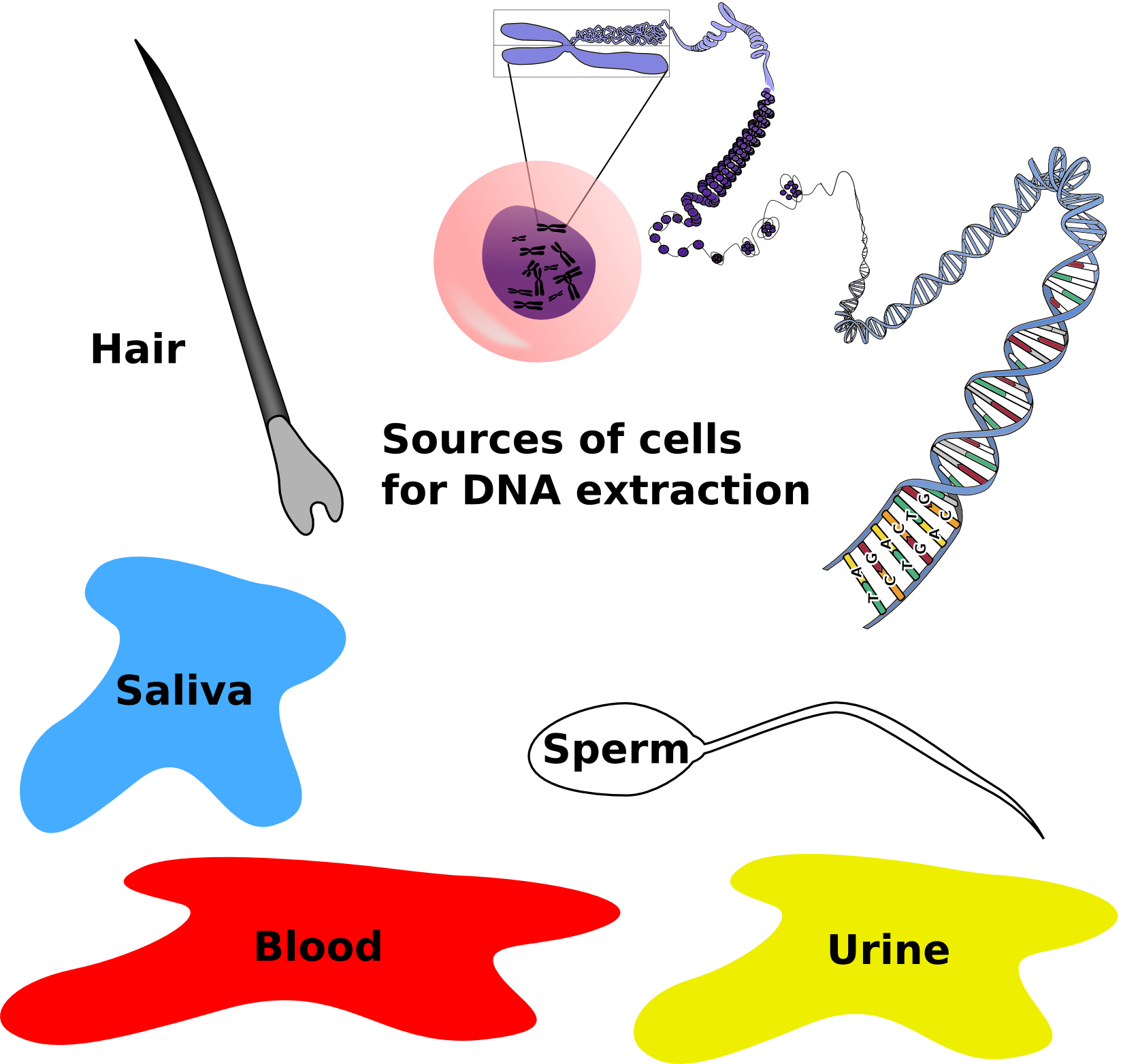
Amplified DNA will be separated by gel electrophoresis and analyzed. Size reference standards and samples from the crime scene and the putative suspects would be analyzed together. In a paternity test, samples from the mother, the child, and the suspected father would be analyzed in the same manner. A simple cheek swab will supply enough cells for this test.
External Resources
- Flash animation walking through what an STR is: http://www.dnalc.org/view/15981-DNA-variations.html