
7.1: DNA Structure
- Page ID
- 16128

As you can see in Figure1, the nucleotides only vary slightly, and only in the nitrogenous base. In the case of DNA, those bases are adenine, guanine, cytosine, and thymine. Note the similarity of the shapes of adenine and guanine, and also the similarity between cytosine and thymine. A and G are classified as purines, while C and T are classified as pyrimidines. As long as we’re naming things, notice “deoxyribose” and “ribose”. As the name implies, deoxyribose is just a ribose without an oxygen. More specifically, where there is a hydroxyl group attached to the 2-carbon of ribose, there is only a hydrogen attached to the 2-carbon of deoxyribose. That is the only difference between the two sugars.
In randomly constructing a single strand of nucleic acid in vitro, there are no particular rules regarding the ordering of the nucleotides with respect to their bases. The identities of their nitrogenous bases are irrelevant because the nucleotides are attached by phosphodiester bonds through the phosphate group and the pentose. It is therefore often referred to as the sugar-phosphate backbone. If we break down the word “phosphodiester”, we see that it quite handily describes the connection: the sugars are connected by two ester bonds ( —O—) with a phosphorous in between. One of the ideas that often confuses students is the directionality of this bond, and therefore, of nucleic acids in general. For example, when we talk about DNA polymerase, the enzyme that catalyzes the addition of nucleotides in living cells, we say that it works in a 5-prime (5’) to 3-prime (3’) direction. This may seem like arcane molecular-biologist-speak, but it is actually very simple. Take another look at two of the nucleotides joined together by the phosphodiester bond (Figure \(\PageIndex{1}\), bottom left). An adenine nucleotide is joined to a cytosine nucleotide. The phosphodiester bond will always link the 5-carbon of one deoxyribose (or ribose in RNA) to the 3-carbon of the next sugar. This also means that on one end of a chain of linked nucleotides, there will be a free 5’ phosphate (-PO4) group, and on the other end, a free 3’ hydroxyl (-OH). These define the directionality of a strand of DNA or RNA.

DNA is normally found as a double-stranded molecule in the cell whereas RNA is mostly single-stranded. It is important to understand though, that under the appropriate conditions, DNA could be made single-stranded, and RNA can be double-stranded. In fact, the molecules are so similar that it is even possible to create double-stranded hybrid molecules with one strand of DNA and one of RNA. Interestingly, RNA-RNA double helices and RNA-DNA double helices are actually slightly more stable than the more conventional DNA-DNA double helix.
The basis of the double-stranded nature of DNA, and in fact the basis of nucleic acids as the medium for storage and transfer of genetic information, is base-pairing. Base-pairing refers to the formation of hydrogen bonds between adenines and thymines, and between guanines and cytosines. These pairs are significantly more stable than any association formed with the other possible bases. Furthermore, when these base-pair associations form in the context of two strands of nucleic acids, their spacing is also uniform and highly stable. You may recall that hydrogen bonds are relatively weak bonds. However, in the context of DNA, the hydrogen bonding is what makes DNA extremely stable and therefore well suited as a long-term storage medium for genetic information. Since even in simple prokaryotes, DNA double helices are at least thousands of nucleotides long, this means that there are several thousand hydrogen bonds holding the two strands together. Although any individual nucleotide-to-nucleotide hydrogen bonding interaction could easily be temporarily disrupted by a slight increase in temperature, or a miniscule change in the ionic strength of the solution, a full double-helix of DNA requires very high temperatures (generally over 90oC) to completely denature the double helix into individual strands.
Because there is an exact one-to-one pairing of nucleotides, it turns out that the two strands are essentially backup copies of each other - a safety net in the event that nucleotides are lost from one strand. In fact, even if parts of both strands are damaged, as long as the other strand is intact in the area of damage, then the essential information is still there in the complementary sequence of the opposite strand and can be written into place. Keep in mind though, that while one strand of DNA can thus act as a “backup” of the other, the two strands are not identical - they are complementary. An interesting consequence of this system of complementary and antiparallel strands is that the two strands can each carry unique information.
Bi-directional gene pairs are two genes on opposite strands of DNA, but sharing a promoter, which lies in between them. Since DNA can only be made in one direction, 5’ to 3’, this bi-directional promoter, often a CpG island (see next chapter), thus sends the RNA polymerase for each gene in opposite physical directions. This has been shown for a number of genes involved in cancers (breast, ovarian), and is a mechanism for coordinating the expression of networks of gene products.
The strands of a DNA double-helix are antiparallel. This means that if we looked at a double-helix of DNA from left to right, one strand would be constructed in the 5’ to 3’ direction, while the complementary strand is constructed in the 3’ to 5’ direction. This is important to the function of enzymes that create and repair DNA, as we will be discussing soon. In Figure \(\PageIndex{1}\), the left strand is 5’ to 3’ from top to bottom, and the other is 5’ to 3’ from bottom to top.
From a physical standpoint, DNA molecules are negatively charged (all those phosphates), and normally a double-helix with a right-handed twist. In this normal (also called the “B” conformation) state, one full twist of the molecule encompasses 11 base pairs, with 0.34 nm between each nucleotide base. Each of the nitrogenous bases are planar, and when paired with the complementary base, forms a at planar “rung” on the “ladder” of DNA. These are perpendicular to the longitudinal axis of the DNA. Most of the free-floating DNA in a cell, and most DNA in any aqueous solution of near-physiological osmolarity and pH, is found in this B conformation. However, other conformations have been found, usually under very specific environmental circumstances. A compressed conformation, A-DNA, was observed as an artifact of in vitro crystallization, with slightly more bases per turn, shorter turn length, and base-pairs that are not perpendicular to the longitudinal axis. Another, Z-DNA, appears to form transiently in GC-rich stretches of DNA in which, interestingly, the DNA twists the opposite direction.

It has been suggested that both the A and Z forms of DNA are, in fact, physiologically relevant. There is evidence to suggest that the A form may occur in RNA-DNA hybrid double helices as well as when DNA is complexed to some enzymes. The Z conformation may occur in response to methylation of the DNA. Furthermore, the “normal” B-DNA conformation is something of a idealized structure based on being fully hydrated, as is certainly very likely inside a cell. However, that hydration state is constantly changing, albeit minutely, so the DNA conformation will often vary slightly from the B-conformation parameters in Figure \(\PageIndex{2}\).
In prokaryotes, the DNA is found in the cytoplasm (rather obvious since there is no other choice in those simple organisms), while in eukaryotes, the DNA is found inside the nucleus. Despite the differences in their locations, the level of protection from external forces, and most of all, their sizes, both prokaryotic and eukaryotic DNA is packaged with proteins that help to organize and stabilize the overall chromosome structure. Relatively little is understood with regard to prokaryotic chromosomal packaging although there are structural similarities between some of the proteins found in prokaryotic and eukaryotic chromosomes. Therefore, most introductory cell biology courses stick to eukaryotic chromosomal packaging.

Naked DNA, whether prokaryotic or eukaryotic, is an extremely thin strand of material, roughly 11 nm in diameter. However, given the size of eukaryotic genomes, if the DNA was stored that way inside the nucleus, it would become unmanageably tangled. Picture a bucket into which you have tossed a hundred meters of yarn without any attempt whatsoever to organize it by coiling it or bunching it. Now consider whether you would be able to reach into that bucket pull on one strand, and expect to pull up only one strand, or if instead you are likely to pull up at least a small tangle of yarn. The cell does essentially what you would do with the yarn to keep it organized: it is packaged neatly into smaller, manageable skeins. In the case of DNA, each chromosome is looped around a histone complex to form the first order of chromosomal organization: the nucleosome.
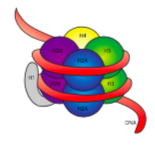
The 30-nm fiber is held together by two sets of interactions. First, the linker histone, H1, brings the nucleosomes together into an approximate 30-nm structure. This structure is then stabilized by disulfide bonds that form between the H2A histone of one nucleosome and the H4 histone of its neighbor.
Histones are a family of basic (positively-charged) proteins. They all function primarily in organizing DNA, and the nucleosome is formed when DNA wraps (a little over 2 times) around a core of eight histones - two each of H2A, H2B, H3, and H4. The number and position of the positive charges (mostly from lysines and arginines) are crucial to their ability to tightly bind DNA, which as previously pointed out, is very negatively charged. That “opposites attract” idea is not just a dating tip from the advice columns.

Upon examination of the 3D structure of the histone core complex, we see that while relatively uncharged protein interaction domains hold the histones together in the center, the positively charged residues are found around the outside of the complex, available to interact with the negatively charged phosphates of DNA.
In a later chapter, we will discuss how enzymes read the DNA to transcribe its information onto smaller, more manageable pieces of RNA. For now, we only need to be aware that at any given time, much of the DNA is packaged tightly away, while some parts of the DNA are not. Because the parts that are available for use can vary depending on what is happening to/in the cell at any given time, the packaging of DNA must be dynamic. There must be a mechanism to quickly loosen the binding of DNA to histones when that DNA is needed for gene expression, and to tighten the binding when it is not. As it turns out, this process involves acetylation and deacetylation of the histones.

Histone Acetyltransferases (HATs) are enzymes that place an acetyl group on a lysine of a histone protein. The acetyl groups are negatively charged, and the acetylation not only adds a negatively charged group, it also removes the positive charge from the lysine. This has the effect of not only neutralizing a point of attraction between the protein and the DNA, but even slightly repelling it (with like charges). On the other side of the mechanism, Histone Deactylases (HDACs) are enzymes that remove the acetylation, and thereby restore the interaction between histone protein and DNA. Since these are such important enzymes, it stands to reason that they are not allowed to operate willy-nilly on any available histone, and in fact, they are often found in a complex with other proteins that control and coordinate their activation with other processes such as activation of transcription.