
BioMolViz Theme: Ligands and Modifications (LM)
( \newcommand{\kernel}{\mathrm{null}\,}\)
Learning themes, goals, and objectives to promote biomolecular visualization literacy are articulated in a Biomolecular Visualization Framework created by BioMolViz. Here we present background and iCn3D molecular models that illustrate key learning goals (LM1, LM2) and objectives for the theme Ligands and Modifications (LM).
Ligands
First, what is a ligand in a biochemical sense? Let's define it as any smaller chemical species that binds reversibly to a larger chemical species. Students' first encounter with ligand binding often involves binding a small gaseous molecule, O2, to deoxymyoglobin or deoxyhemoglobin. Compared to most biochemical binding interactions, this is a special case since the ligand (O2) binds reversibly through a dative (covalent) bond. Other examples of ligand binding to heme proteins include O2 (ligand) binding through a dative bond to isolated heme, and heme (ligand) binding through noncovalent interactions to an apoheme protein like apomyoglobin and apohemoglobin.
In most cases in biochemistry, ligand binding occurs through noncovalent interactions. Some examples include the binding of a short ds-DNA oliogmer (ligand) to a DNA-binding protein, or a DNA-binding protein (in this case the ligand) binding to a larger DNA fragment. You can see that the designation of "ligand" is somewhat arbitrary. We'll try to use unambiguous examples in which the ligand binds to a biomacromolecule.
Many mechanisms have been used to explain the binding of ligands through noncovalent interactions to biomolecules. The first is a lock-and-key model in which the ligand had perfect shape and charge distribution complementarity to match a preformed site in a protein. A second is an induced-fit model in which ligand:biomacromolecule interactions are accompanied by changes in the conformation of the biomacromolecule to maximize binding interactions. In this model, conformational change follows the initial interaction. In a more nuanced third conformational selection model, the ligand binds initially to one of an ensemble of preexisting conformations, which is likely followed by conformational changes in the initially formed complex. The last model recognizes the inherent conformational flexibility of biomacromolecules such as proteins, especially ones that contain intrinsically disordered regions. The induced fit model is a special case of the conformation selection model.
Modified Building Blocks
Building blocks are monomeric subunits that link through covalent bonds to other building blocks to form longer polymers such as biomacromolecules. In biochemistry, polymers and their building blocks include proteins, made of amino acid building blocks/monomers, nucleic acids, made from (deoxy)nucleotides, and glycans, made from monosaccharides.
There are 20 conventional amino acid building blocks, 4 nucleotides, 4 deoxynucleotides, and many monosaccharides which form their respective polymers. The building blocks or monomers are often chemically altered by reactive modifying agents in reactions catalyzed by enzymes in vivo or, if the agents are reactive enough, in the absence of enzymes, such as in the oxidation of biomolecules by reactive oxygen species (ROS). Chemical modifications alter the properties of the building blocks and hence the overall structure and function of the modified polymer.
Modifications can be made to monomers before assembly into polymers, but they are usually made during or after polymer synthesis. Examples of modifications to growing or complete biopolymers include co-translational modifications (N-terminal acetylation) in about 80% of proteins, post-translational modifications of proteins, and epigenetic modifications of nucleic acids.
Building blocks and/or their biopolymers can be chemically altered in vitro by reactions with specific modifying agents to explore their effects on the structure and function of a biomolecule. Ligands that are made of multiple building blocks (for example peptides, oligonucleotides, and polysaccharides) can be synthesized in vitro from modified building blocks) to produce analogs with altered properties (such as higher affinity peptide inhibitors of an enzyme). This same approach can be used within cells using synthetic biology to introduce unnatural (noncanonical) amino acids into proteins.
Proteins
This description of modified building blocks encompasses many more variants than the common post-translational modifications of protein (such as acetylation and phosphorylation) normally encountered. In some modifications, large groups are attached to a building block in a polymer. Such modifications include glycosylation, ubiquitination, SUMOylation, and lipidation of proteins. These won't be discussed here.
The Protein Data Bank indicates if a protein or nucleic acid sequence has a modified monomer. Each modified monomer/building block is given a specific 3-character alphanumeric abbreviation. The figure below is an example for cytochrome C isozyme 1, which has a N-trimethyllysine (M3L) indicated by the green dot.


Nucleic Acid Building Block/Monomer Modification
Many students in biochemistry courses are more likely to learn the structures of amino acid monomers, which vary at just the alpha-carbon, than the more complicated structures of the 5 heterocyclic bases (AGCTU and sometimes I for inosine) with varying ring substituents. Hence it can be more difficult for students to identify often subtle chemical modifications of these 5 bases. Nucleic acid bases are modified post-DNA replication or post-RNA transcription. Base modifications can affect base pairing and binding interactions with proteins, altering the readout and packing of the DNA and RNA. Each of the 4 DNA bases can be modified with cytosine modification being the most common. 5-methylcytosine (5mC), for example, is a common, very stable epigenetic modification that is well studied. Other common modified bases include 5-hydroxymethylcytosine (5hmC), 5-formyl cytosine (5fC), and 5-carboxyl cytosine (5caC). N6-methyladenine (6mA) is mostly found in bacteria as well as N4-methylcytosine (4mC). A chemical reaction, deamination, converts adenosine to inosine (I). There are upwards of 150 different modifications of RNA bases, with m6A/N6A (from 0.1 to 0.4% of As) in eukaryotes being most prevalent with possible trace levels found in bacteria. As with modified amino acids, each has a 3-character alphanumeric abbreviation. Here are some databases for post-translation and DNA/RNA base modifications.
The figure below shows some common modifications of A, C, and U, with their common abbreviations.

Here is a link to a downloadable Excel spreadsheet with over 100 protein monomer modifications and 20 nucleic acid base modifications. Each has a link to an iCn3D molecular model showing the modified residues in a target protein or nucleic acid.
Glycans
Monosaccharides and their modified versions form straight and branched glycan polymers that can also be covalently attached to proteins through amino acid side chains like serine and asparagine. No template strand provides the "instructions" for the sequence of a glycan. Rather, the enzymes processing the growing glycan determine its final sequence. The PDB does not list amino acids (like Asn) attached to a glycan as a "modified" monomer. The name of each glycan monomer is given a 3-character code in the Protein Data Bank. However, monomers are not defined as modified versions of a simple monosaccharide such as glucose or mannose. Hence the term modified monomer (either in the PDB or in the BioMolViz learning themes) does not strictly apply to glycans. However, identifying different monomers and their linkages in a glycan polymer is an important skill. This is likely more difficult for students than identifying amino acid and nucleotide monomers, given the similarities of all carbohydrate monomers, their large number of hydroxy groups, and the large range of possible modifications of the monomers (including methylation, deoxygenation, amination, acetamidation, sulfation, etc).
The figure below shows an interactive iCn3D model of the adhesion domain of human CH2 with its N-glycan (1GYA).
.png?revision=1&size=bestfit&width=416&height=322)
 Figure: Adhesion domain of human CH2 with its N-glycan (1GYA). (Copyright; author via source).
Figure: Adhesion domain of human CH2 with its N-glycan (1GYA). (Copyright; author via source).
Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/icn3d/share.html?QH4VsmshZDWRx6P56
The individual monomers of the glycan attachment are shown with translucent colored geometric shapes representing the monomers. The monomers are labeled NAG (β-N-acetylglucosamine), MAN (α-D-mannose) and BMA (β-D-mannose). The figure below shows their SNFG cartoon representation where the blue square is NAG and the green circle is mannose.

BioMolViz Learning Themes
LM1.01 Students can use the annotation associated with a pdb file to identify and locate ligands and modified building blocks in a given biomolecule. (Amateur)
LM1.02 Students can visually identify non‐protein chemical components in a given rendered structure. (Amateur)
LM1.03 Students can distinguish between nucleic acid and ligands (e.g. metal ions) in a given nucleic acid superstructure. (Amateur)
LM1.04 Students can explain how a ligand in a given rendered structure associates with the biomolecule (i.e., covalent interaction with residue X). (Amateur)
LM1.05 Students can locate/identify ligands and modified building blocks in unannotated structures and describe their role. (Expert)
LM2.01 Students can look at a given rendered structure and describe how the presence of a specific ligand or modified building block alters the structure of that biomolecule. (Amateur)
LM2.02 Students can explain how the removal of a particular ligand or modified building block would alter the structure of a given biomolecule. (Expert)
LM2.03 Students can use molecular visualization tools to predict how a specified ligand or modified building block contributes to the function of a given protein. (Amateur)
LM2.04 Students can predict how a ligand or modified building block contributes to the function of a protein for which the structure has been newly solved. (Expert)
Note that some learning objectives require students to use and search the PDB for information about ligands and modifications and use visualization tools such as iCn3D. To that end, instructions for using the PDB to search for ligands and modifications, and for modeling with iCn3D are provided.
Examples of small ligands bound to a macromolecule
1. Metal Ions
Example: Ca2+ binding to calmodulin (apoCAM without Ca2+ and holoCAM with Ca2+)
This example is chosen to illustrate the huge effect on the structure of the protein on binding calcium ions. Click on the figures below to see interactive iCn3D structures.
| iCn3D structure (click on image) |
|
apoCAM X. Levis, AA 20-31 |
|
human holoCAM, AA 20-31 with Ca2+ not displayed |
|
human holoCAM, AA 20-31 WITH Ca2+ displayed |



The image below shows the change in conformation in the first Ca+2 site (D20-E31, 1CFD, Xenopus laevis) on binding Ca+2 (D20-E31, 1CLL, human). In this image, the two Ca2+ sites (not the entire protein sequences) were aligned using Pymol. Carbon atoms are shown in cyan and the green sphere is Ca+2. Other atoms are shown with normal CPK colors.
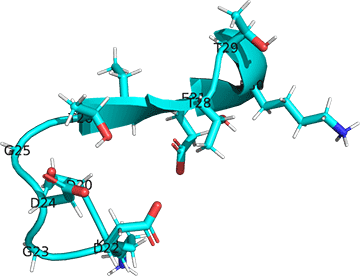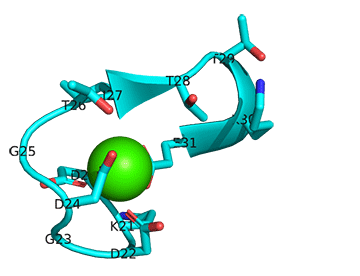
Figure: Conformational changes in the first Ca+2 site (D20-E31, 1CFD, Xenopus laevis) on binding Ca+2 (D20-E31, 1CLL, human).
Note the different orientations of the carboxylate side chains as they move to interact with the Ca2+ ions.
The next image below shows the conformational change in the cartoon representation of apo-CAM (cyan, 1CFD, Xenopus laevis) on binding four Ca+2 ions to form holo-CAM (magenta, 1CLL, human). The amino acid sequences of calmodulins from both species are identical. Both chains were aligned and displayed with Pymol.
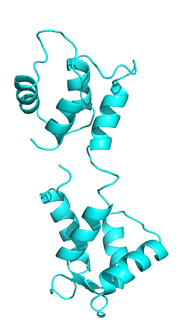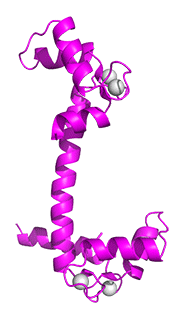
Figure: Conformational changes in the cartoon representation of apo-CAM (cyan, 1CFD, Xenopus laevis) on binding four Ca+2 ions (magenta, 1CLL, human).
In the holo-form, a fully-formed central helix connects to the two lobes of a "dumbbell-shaped" structure.
Example: Zn2+ binding to a protein
Conduct a PDB search as shown in the figure below. Note that one of search terms is not a protein but DNA. This was done knowing that the Zn2+ion binds to a DNA-binding transcription factor with "Zn finger" motifs. At the top of the PDB page, select Advanced search.

Then make the selections shown below within the dropdown menus.

Select 4GZN - ZFP57 zinc fingers in complex with methylated DNA. Click the image below to see an interactive iCn3D model which shows an interaction of Zn2+ with a DNA-binding protein. The model also shows a divalent cation (Ca2+) interacting with the DNA helix as well as a 5-methyldeoxycytosine (5MC) base.

Search the PDB for other metal complexes including:
- Na+ binding to thrombin
- Fe2+ binding to a protein
- FeS cluster in a protein
- Zn, Cu or Cd binding to metallothioneins
2. Small molecule/molecular ion
Here are some type of small molecule/molecular ion binding
- Enzyme - Cofactor: NAD
- Enzyme - Cofactor: FAD
- Enzyme - Substrate:
- Enzyme - Substrate:
- Enzyme - Inhibitor:
- Enzyme - Allosteric Modulator
- Receptor - Neurotransmitter
- Receptor - Hormone
- Receptor - Allosteric modulator
Let's choose one example
Example: CBD (cannabinol) binding to a target protein (its receptor)
To an advanced search as shown in the figure below.

Select 6U88 from the list which shows the cannabidiol (CBD)-bound to a full-length rat transient receptor potential cation channel subfamily V member 2 (TRPV2) in nanodiscs.
Let's display it in two ways.
1. Full protein structure with one CBD (labeled POT in the structure) in spacefill. Click on structure for the full iCn3D model.

The red dots represent the outer leaflet of the billayer, and the blue the inner leaflet.
Instructions to duplicate the iCn3D model:
- Load 6U88
- Analysis, Seq. and Annotations
- Choose the Details tab and uncheck conserved domains
- Choose the first POT (the PDB abbreviation for CBD) with the mouse in the analysis window
- Selection, Save Selection, name it POT1
- Style, Chemical, Sphere
- Style, Background, Transparent
2. Protein atoms within 5 Angstroms (Å) of POT with hydrogen bonding interactions. Click on structure for the full iCn3D model.

Instructions to duplicate the iCn3D model:
- Analysis, Seq. and Annotations
- Choose the Details tab, uncheck conserved domains
- Select the first POT in the list with the mouse in the analysis window
- Selection, Save Selection, name it POT1
- Select, By Distance, choose 5 Angstroms
- Select, Save Selection, name it Ang5
- In the Select Sets window, choose (click followed by control-click) POT1 and Ang5
- Analysis, Interactions, choose POT1 for Set 1 and Ang5 for set 2
- Display Interactions
- Select, Save Selection, name it Interwith5Ang
- In the Select Sets window, choose all three (POT1, Ang5 and Interwith5Ang)
- Style, Protein, Sticks
- View, View Selection
- Style, Background, Transparent
Modified monomers - searching and modeling
Use the images below to search the PDB for modified monomers such as a phospho-Ser, Thr, etc.
Method A: from advanced search
First, open Advanced Search

Next under Chemical Attributes select RESID Modification

Then perform the search as shown below.

Method B: from the top PDB search bar
Search with a 3-character alphanumeric code for modified amino acids and (deoxy)nucleotides from this Excel spreadsheet with over 100 protein monomer modifications and 20 nucleic acid base modifications. The search example below is for SME (METHIONINE SULFOXIDE).
First, input the 3-character code in the main search bar on top of the initial PDB web page, and follow the prompts that result, as shown in the image below.

The figure below shows the search results.

Now, select the link from "is present in a polymer sequence" (with 43 entries). Then pick one to explore the modified residue.
The PDB search algorithm is robust and as you learn it, you can combine search terms. Here is just one example.
Example: Find structures with SEP (phosphoserine)

Example: Search PDB file for a modified monomer (PCA - pyroglutamic acid) using the Excel spreadsheet.
Find the PDB file 1A39 (HUMICOLA INSOLENS ENDOCELLULASE EGI S37W, P39W DOUBLE-MUTANT) in the first tab of the Excel Spread sheet. It contains a PCA (pyroglutamic acid), a modified GLN.
- Go to the PDB and search for 1A39
- use the scroll bar on PDB page in Sequence Annotations to find MODIFIED MONOMER
- one found at AA 1; hover over the green dot to see it's a modified Gln

Visualize with iCn3D
- Load 1A39 in iCn3d
- Analysis, Seq. & Annotations; Click Details tab, uncheck the Conserved Domain box
- Click 1A39_A link;
- Select, Save Selection, name it AChain
- Color, Unicolor, Gray, Light Gray
- Select, Toggle Highlights
- Use mouse to select amino acid X
- Select, Save Selection, name it X
- Style, Protein, Stick (since this is cyclic amino acid; for just modified side chains, choose Style, Side Chain, Stick)
- Color, Atom
- Analysis, Label, Per Residue & Number
- Analysis, Label Scale, 4 (label is the 3 letter code for pyroglutamic acid, PCA1
- Style, Background, Transparent
- File, Share Link, Short Link:
Here is short link for a rendered version of the modified monomer in the protein: https://structure.ncbi.nlm.nih.gov/i...ksads3ZX6tPez9
Specialized Search Example
Find all proteins with just one tryptophan
- Go to the PDB website (rcsb.org).
- Click on "Advanced Search" in the top menu.
- In the Advanced Search interface, you'll need to set up two search criteria:
a. To search for proteins containing tryptophan:- In the "Choose a Query Type" dropdown, select "Chemical Components."
- In the "Chemical Component Query" section, type "TRP" (the three-letter code for tryptophan) in the "Chemical ID(s)" field.
- Click "Add a New Query" at the bottom of the page.
- In the new query section, choose "Sequence Features" from the dropdown.
- In the "Sequence Feature Query" section, select "Number of Residues."
- Set the operator to "equals" and enter "1" in the value field.
- In the "Of Type" dropdown, select "TRP (tryptophan)."

- Combine these queries:
- In the "Combine Queries" section at the top, select "and" to ensure both conditions are met.
- Click "Submit Query" to run the search.
This search should return all protein structures in the PDB that contain exactly one tryptophan residue.
Keep in mind that this search might also include structures where only part of a protein is crystallized or where the full sequence is not present in the structure. If you need to refine your results further, you may want to add additional criteria or examine the results manually.