
Carbohydrates*#
( \newcommand{\kernel}{\mathrm{null}\,}\)
Carbohydrates
Most people are familiar with carbohydrates, especially when it comes to what we eat. Carbohydrates are an essential part of our diet; grains, fruits, and vegetables are all natural sources. More generally, carbohydrates are one of the four classes of macromolecules that compose all cells. While we may be most familiar with the role carbohydrates play in nutrition, they also have a variety of other essential functions in humans, animals, plants, and bacteria. In this section, we will discuss and review basic concepts of carbohydrate structure and nomenclature, as well as a variety of functions they play in cells.
Molecular structures
In their simplest form, carbohydrates can be represented by the stoichiometric formula (CH2O)n, where n is the number of carbons in the molecule. For simple carbohydrates, the ratio of carbon to hydrogen to oxygen in the molecule is 1:2:1. This formula also explains the origin of the term “carbohydrate”: the components are carbon (“carbo”) and the components of water (hence, “hydrate”). Simple carbohydrates are classified into three subtypes: monosaccharides, disaccharides, and polysaccharides, which will be discussed below. While simple carbohydrates fall nicely into this 1:2:1 ratio, carbohydrates can also be more complex, structurally. For example, many carbohydrates contain functional groups (remember them from our basic discussion about chemistry) besides the obvious hydroxyl. For example, carbohydrates can have phosphates or amino groups substituted at a variety of sites within the molecule. These additional groups can provide additional properties to the molecule and will alter its overall function. However, even with these types of substitutions, the basic overall structure of the carbohydrate is retained and easily identified.
Nomenclature
One issue with carbohydrate chemistry is the nomenclature. Here are a few quick and simple rules:
- Simple carbohydrates, such as glucose, lactose, or dextrose, end with an "...ose."
- Simple carbohydrates can be classified based on the number of carbon atoms in the molecule, as with triose (three carbons), pentose (five carbons), or hexose (six carbons).
- Simple carbohydrates can be classified based on the functional group found in the molecule, such as a ketose or aldose.
- Polysaccharides are often organized by the number of sugar molecules in the chain, such as in a monosaccharide, disaccharide, or trisaccharide.
For a short video on carbohydrate classification, see the 10-minute Khan Academy video by clicking here.
Monosaccharides
Monosaccharides (mono- = “one”; sacchar- = “sweet”) are simple sugars, the most common of which is glucose. In monosaccharides, the number of carbons usually ranges from three to seven. If the sugar has an aldehyde group (the functional group with the structure R-CHO), it is known as an aldose, and if it has a ketone group (the functional group with the structure RC(=O)R'), it is known as a ketose.
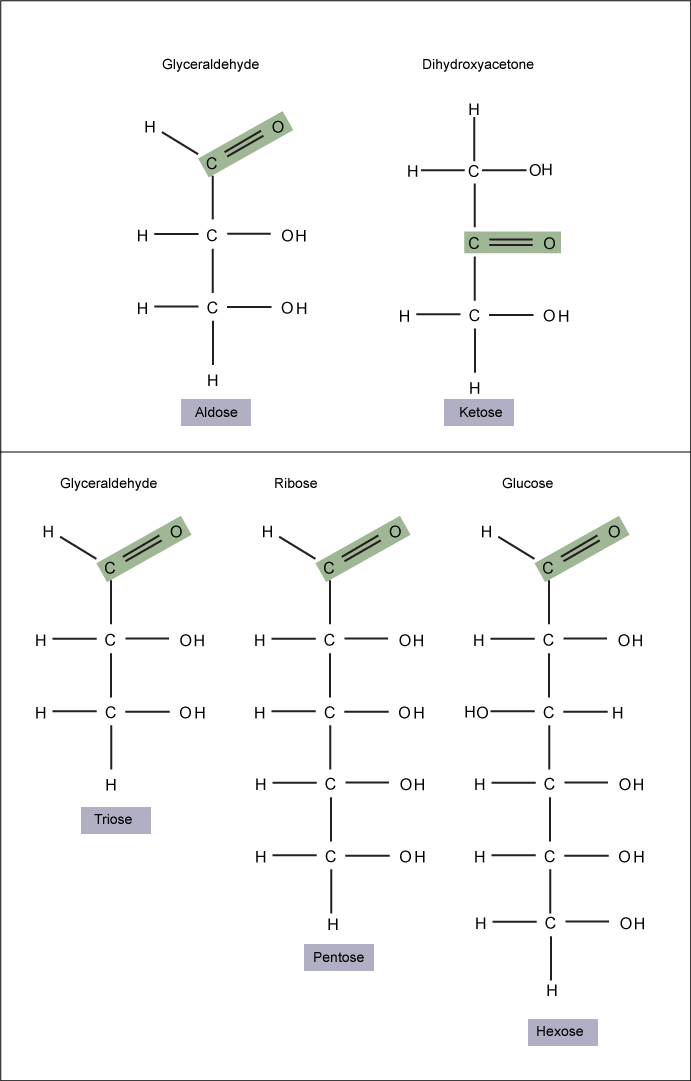
Figure 1. Monosaccharides are classified based on the position of their carbonyl group and the number of carbons in the backbone. Aldoses have a carbonyl group (indicated in green) at the end of the carbon chain, and ketoses have a carbonyl group in the middle of the carbon chain. Trioses, pentoses, and hexoses have three, five, and six carbons in their backbones, respectively. Attribution: Marc T. Facciotti (own work)
Glucose versus galactose
Galactose (part of lactose, or milk sugar) and glucose (found in sucrose, glucose disaccharride) are other common monosaccharides. The chemical formula for glucose and galactose is C6H12O6; both are hexoses, but the arrangements of the hydrogens and hydroxyl groups are different at position C4. Because of this small difference, they differ structurally and chemically (and are known as chemical isomers) because of the different arrangement of functional groups around the asymmetric carbon; both of these monosaccharides have more than one asymmetric carbon (compare the structures in the figure below).
Fructose versus both glucose and galactose
A second comparison can be made when looking at glucose, galactose, and fructose (the second carbohydrate that with glucose makes up the disaccharide sucrose, and is a common sugar found in fruit, hence the name). All three are hexoses; however, there is a major structural difference between glucose and galactose versus fructose: the carbon that contains the carbonyl (C=O). In glucose and galactose, it is on the C1 carbon, forming an aldehyde group; in fructose, it is on the C2 carbon, forming a ketone group. The former are called aldoses based on the aldehyde group that is formed; the latter are designated as ketoses based on the ketone group. Again, this difference gives fructose different chemical and structural properties from those of the aldoses, glucose, and galactose, although fructose, glucose, and galactose all have the same chemical composition: C6H12O6.
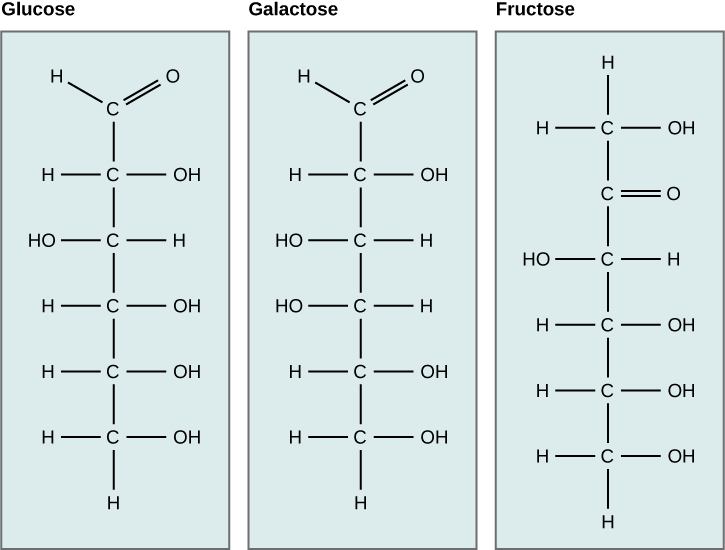
Figure 2. Glucose, galactose, and fructose are all hexoses. They are structural isomers, meaning they have the same chemical formula (C6H12O6) but a different arrangement of atoms.
Linear versus ring form of the carbohydrates
Monosaccharides can exist as a linear chain or as ring-shaped molecules; in aqueous solutions, they are usually found in ring forms (Figure 3). Glucose in a ring form can have two different arrangements of the hydroxyl group (OH) around the anomeric carbon (C1 that becomes asymmetric in the process of ring formation). If the hydroxyl group is below C1 in the sugar, it is said to be in the alpha (α) position, and if it is above the plane, it is said to be in the beta (β) position.
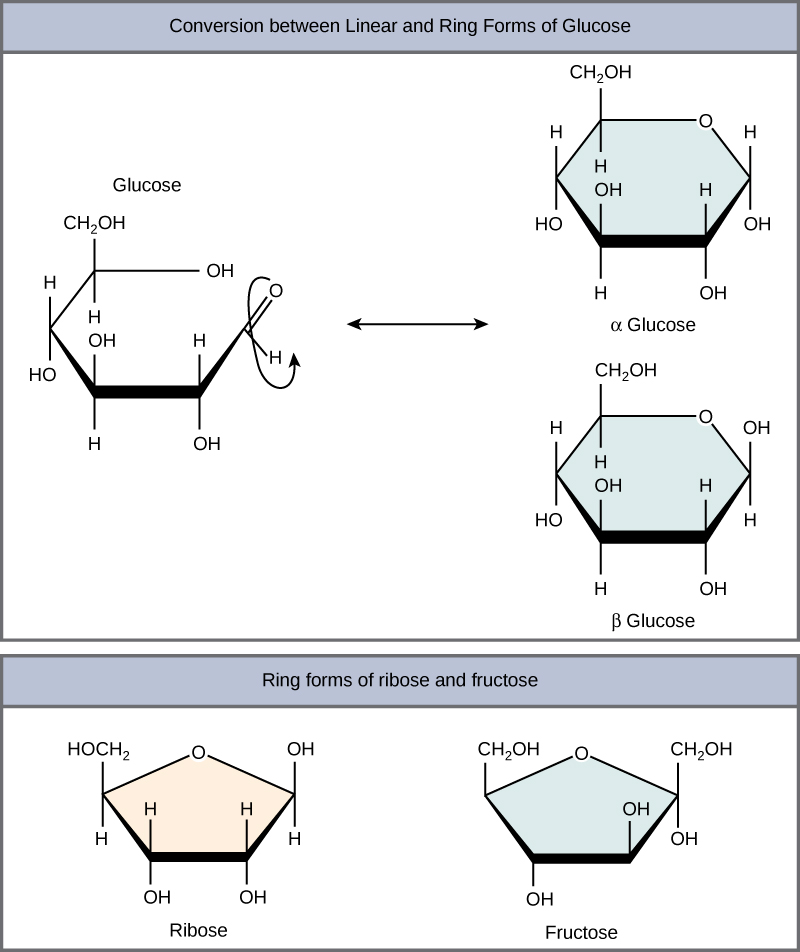
Figure 3. Five and six carbon monosaccharides exist in equilibrium between linear and ring forms. When the ring forms, the side chain it closes on is locked into an α or β position. Fructose and ribose also form rings, although they form five-membered rings as opposed to the six-membered ring of glucose.
Disaccharides
Disaccharides (di- = “two”) form when two monosaccharides undergo a dehydration reaction (also known as a condensation reaction or dehydration synthesis). During this process, the hydroxyl group of one monosaccharide combines with the hydrogen of another monosaccharide, releasing a molecule of water and forming a covalent bond. A covalent bond formed between a carbohydrate molecule and another molecule (in this case, between two monosaccharides) is known as a glycosidic bond. Glycosidic bonds (also called glycosidic linkages) can be of the alpha or the beta type.
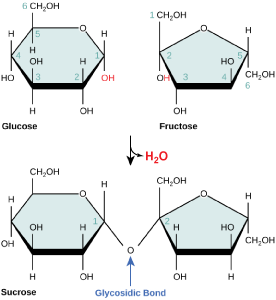
Figure 4. Sucrose is formed when a monomer of glucose and a monomer of fructose are joined in a dehydration reaction to form a glycosidic bond. In the process, a water molecule is lost. By convention, the carbon atoms in a monosaccharide are numbered from the terminal carbon closest to the carbonyl group. In sucrose, a glycosidic linkage is formed between the C1 carbon in glucose and the C2 carbon in fructose.
Common disaccharides include lactose, maltose, and sucrose (Figure 5). Lactose is a disaccharide consisting of the monomers glucose and galactose. It is found naturally in milk. Maltose, or malt/grain sugar, is a disaccharide formed by a dehydration reaction between two glucose molecules. The most common disaccharide is sucrose, or table sugar, which is composed of the monomers glucose and fructose.
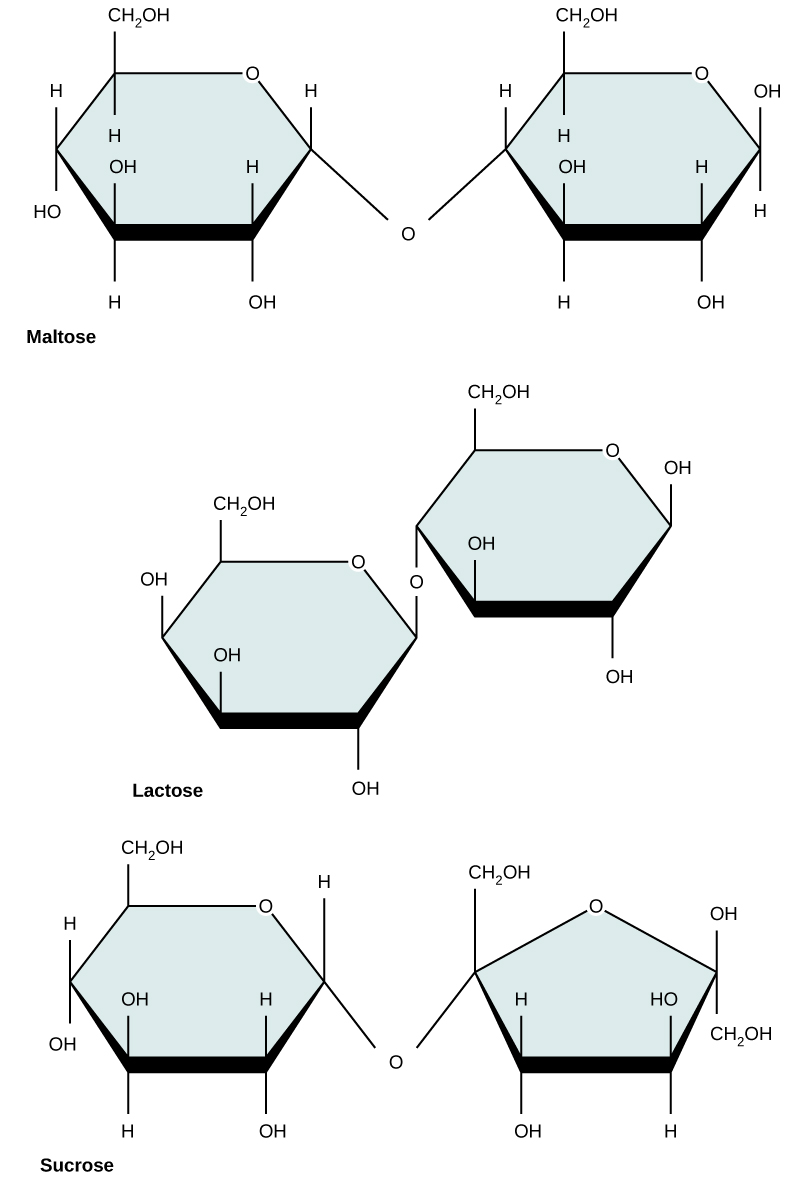
Figure 5. Common disaccharides include maltose (grain sugar), lactose (milk sugar), and sucrose (table sugar).
Interactions with carbohydrates
We have just discussed the various types and structures of carbohydrates found in biology. The next thing to address is how these compounds interact with other compounds. The answer to that is that it depends on the final structure of the carbohydrate. Because carbohydrates have many hydroxyl groups associated with the molecule, they are therefore excellent H-bond donors and acceptors . Monosaccharides can quickly and easily form H-bonds with water and are readily soluble. All of those H-bonds also make them quite "sticky." This also true for many disaccharides and many short-chain polymers. Longer polymers may not be so readily soluble.
Finally, the ability to form a variety of H-bonds allows polymers of carbohydrates or polysaccharides to form strong intramolecular and intermolocular bonds. In a polymer, because there are so many H-bonds, this can provide a lot of strength to the molecule or molecular complex, especially if the polymers interact. Just think of cellulose, a polymer of glucose, if you have any doubts.
Polysaccharides
A long chain of monosaccharides linked by glycosidic bonds is known as a polysaccharide (poly- = “many”). The chain may be branched or unbranched, and it may contain different types of monosaccharides. The molecular weight may be 100,000 daltons or more, depending on the number of monomers joined. Starch, glycogen, cellulose, and chitin are primary examples of polysaccharides.
Starch is the stored form of sugars in plants and is made up of a mixture of amylose and amylopectin (both polymers of glucose). Plants are able to synthesize glucose, and the excess glucose, beyond the plant’s immediate energy needs, is stored as starch in different plant parts, including roots and seeds. The starch in the seeds provides food for the embryo as it germinates and can also act as a source of food for humans and animals. The starch that is consumed by humans is broken down by enzymes, such as salivary amylases, into smaller molecules, such as maltose and glucose. The cells can then absorb the glucose.
Starch is made up of glucose monomers that are joined by 1-4 or 1-6 glycosidic bonds; the numbers 1-4 and 1-6 refer to the carbon number of the two residues that have joined to form the bond. As illustrated in Figure 6, amylose is starch formed by unbranched chains of glucose monomers (only 1-4 linkages), whereas amylopectin is a branched polysaccharide (1-6 linkages at the branch points).

Figure 6. Amylose and amylopectin are two different forms of starch. Amylose is composed of unbranched chains of glucose monomers connected by 1-4 glycosidic linkages. Amylopectin is composed of branched chains of glucose monomers connected by 1-4 and 1-6 glycosidic linkages. Because of the way the subunits are joined, the glucose chains have a helical structure. Glycogen (not shown) is similar in structure to amylopectin but more highly branched.
Glycogen is the storage form of glucose in humans and other vertebrates and is made up of monomers of glucose. Glycogen is the animal equivalent of starch and is a highly branched molecule usually stored in liver and muscle cells. Whenever blood glucose levels decrease, glycogen is broken down to release glucose in a process known as glycogenolysis.
Cellulose is the most abundant natural biopolymer. The cell wall of plants is mostly made of cellulose; this provides structural support to the cell. Wood and paper are mostly cellulosic in nature. Cellulose is made up of glucose monomers that are linked by β 1-4 glycosidic bonds.

Figure 7. In cellulose, glucose monomers are linked in unbranched chains by β 1-4 glycosidic linkages. Because of the way the glucose subunits are joined, every glucose monomer is flipped relative to the next one, resulting in a linear, fibrous structure.
Note: possible discussion
Cellulose is not very soluble in water when it is in a crystalline state; this can be approximated by the stacked cellulose fiber depiction above. Can you suggest a reason for why (based on the types of interactions) it might be so insoluble?
As shown in the figure above, every other glucose monomer in cellulose is flipped over, and the monomers are packed tightly as extended, long chains. This gives cellulose its rigidity and high tensile strength—which is so important to plant cells. While the β 1-4 linkage cannot be broken down by human digestive enzymes, herbivores such as cows, koalas, buffalos, and horses are able, with the help of the specialized flora in their stomach, to digest plant material that is rich in cellulose and use it as a food source. In these animals, certain species of bacteria and protists reside in the rumen (part of the digestive system of herbivores) and secrete the enzyme cellulase. The appendix of grazing animals also contains bacteria that digest cellulose, giving it an important role in the digestive systems of ruminants. Cellulases can break down cellulose into glucose monomers that can be used as an energy source by the animal. Termites are also able to break down cellulose because of the presence of other organisms in their bodies that secrete cellulases.