
3.4: Protein Purification
- Page ID
- 14929


Introduction
Before a protein or other biological macromolecule can be rigorously studied from a structural and functional basis, it must be purified. The problems that can arise during protein purification become clear when one considers that a single protein has to be purified from a mixture of as many 10,000 other cellular or tissue proteins, each of which is made up of the same constituent amino acids. Proteins differ in size (how many amino acids), charge (how many positively and negatively charged amino acids), sequence, and presence of specific binding sites on the proteins. Any technique that could be used to purify protein must be based on these inherent differences. Once the protein is purified, it must be analyzed, typically by a spectral or electrophoretic technique.
Protein purification is a series of processes intended to isolate and purify a single protein or complex from cells, tissues, or whole organisms. Protein purification is vital for the characterization of the function, structure, and interactions of the protein of interest. Separation steps usually exploit differences in protein size, physical-chemical properties, binding affinity, and biological activity.
Protein purification is either preparative or analytical. Preparative purifications aim to produce a relatively large quantity of purified proteins for subsequent use. Examples include the preparation of commercial products such as enzymes (e.g. lactase), nutritional proteins (e.g. soy protein isolate), and certain biopharmaceuticals (e.g. insulin). Many steps and much quality control is required to remove other host proteins and other biomolecules, which pose a potential threat to the patient's health. Analytical purification produces a relatively small amount of a protein for a variety of research or analytical purposes, including identification, structural characterization, and studies of the protein's structure, post-translational modifications, and function.
The choice of a starting material is key to the design of a purification process. In plants or animals, a particular protein usually isn't distributed homogeneously throughout the body; different organs or tissues have higher or lower concentrations of the protein. The use of tissues or organs with the highest concentration decreases the volumes needed to produce a given amount of purified protein. If the protein is present in low abundance, or if it has a high value, scientists may use recombinant DNA technology to develop cells that will produce large quantities of the desired protein. These techniques will be discussed in greater detail in Chapter 5.
Sample Processing
If the protein of interest is not secreted by the organism into the surrounding solution, the first step of each purification process is the disruption of the cells containing the protein. Depending on how fragile the protein is, one of several techniques could be used including repeated freezing and thawing, sonication, homogenization by high pressure (French press), homogenization by grinding (bead mill), and permeabilization by detergents (e.g. Triton X-100) and/or enzymes (e.g. lysozyme). Finally, the cell debris can be removed by centrifugation so that the proteins and other soluble compounds remain in the supernatant.
Also proteases are released during cell lysis, which will start digesting the proteins in the solution. As the protein of interest may be sensitive to proteolysis, it is important to proceed quickly and conduct many steps at low temperatures to reduce unwanted proteolysis. Alternatively, one or more protease inhibitors can be added to the lysis buffer immediately before cell disruption. Sometimes it is also necessary to add DNase in order to reduce the viscosity of the cell lysate caused by a high DNA content.
Centrifugation
Centrifugation is a process that uses centrifugal force to separate mixtures of particles of varying masses or densities suspended in a liquid. When a vessel (typically a tube or bottle) containing a mixture of proteins or other particulate matter, such as bacterial cells, is rotated at high speeds, the inertia of each particle yields a force in the direction of the particle's velocity that is proportional to its mass. The tendency of a given particle to move through the liquid because of this force is offset by the resistance the liquid exerts on the particle. The net effect of "spinning" the sample in a centrifuge is that massive, small, and dense particles move outward faster than less massive particles or particles with more "drag" in the liquid. When suspensions of particles are "spun" in a centrifuge, a "pellet" may form at the bottom of the vessel that is enriched for the most massive particles with low drag in the liquid.
Non-compacted particles remain mostly in the liquid called "supernatant" and can be removed from the vessel thereby separating the supernatant from the pellet. The rate of centrifugation is determined by the angular acceleration applied to the sample, typically measured in comparison to the g. If samples are centrifuged long enough, the particles in the vessel will reach equilibrium wherein the particles accumulate specifically at a point in the vessel where their buoyant density is balanced with centrifugal force. Such an "equilibrium" centrifugation can allow extensive purification of a given particle.
In sucrose gradient centrifugation, a linear concentration gradient of sugar (typically sucrose, glycerol, or a silica-based density gradient media, like Percoll) is generated in a tube such that the highest concentration is on the bottom and the lowest on top. Percoll is a trademark owned by GE Healthcare companies. A protein sample is then layered on top of the gradient and spun at high speeds in an ultracentrifuge. This causes heavy macromolecules to migrate toward the bottom of the tube faster than lighter material. During centrifugation in the absence of sucrose, as particles move farther and farther from the center of rotation, they experience greater centrifugal forces (the further they move, the faster they move). However, the useful separation range within the vessel is restricted to a small observable window. A properly designed sucrose gradient will counteract the increasing centrifugal force so the particles move in close proportion to the time they have been in the centrifugal field. After separating the protein/particles, the gradient is then fractionated and collected. These are described in Figure \(\PageIndex{1}\).

Precipitation and Differential Solubilization
In bulk protein purification, a common first step to isolate proteins is precipitation using a salt such as ammonium sulfate (NH4)2SO4. Ammonium sulfate is often used as it is highly soluble in water, has relative freedom from temperature effects, and typically is not harmful to most proteins. Proteins are precipitated by (NH4)2SO4 in their native state, which is important if you need the protein for structure/function studies. Furthermore, ammonium sulfate can be removed by dialysis as described in Figure \(\PageIndex{2}\).
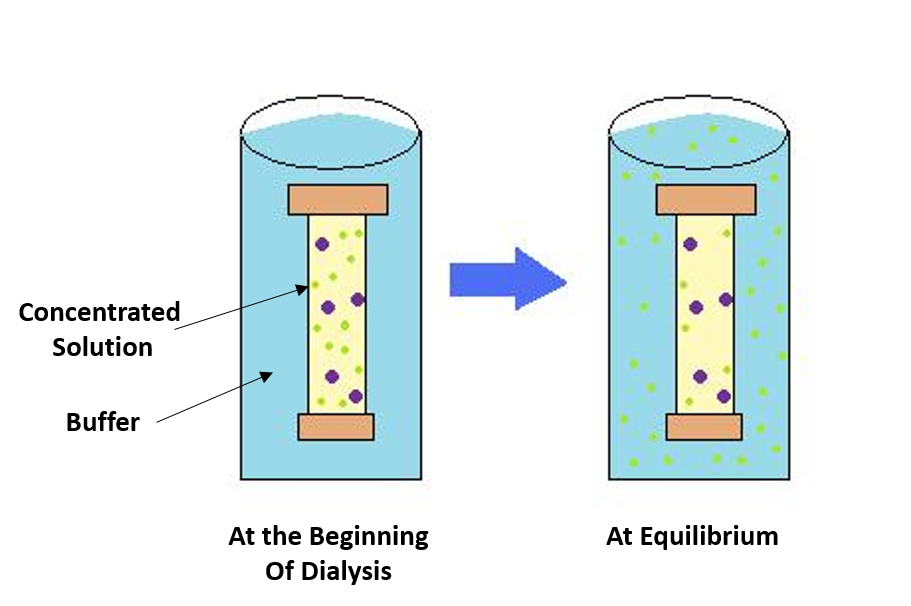
The process of dialysis separates dissolved molecules by their size. The biological sample is placed inside a closed membrane, where the protein of interest is too large to pass through the pores of the membrane, but through which smaller ions can easily pass. As the solution comes to equilibrium, the ions become evenly distributed throughout the entire solution, while the protein remains concentrated in the membrane. This reduces the overall salt concentration of the suspension.
The mechanism underlying salt precipitation is actually quite complicated. High concentrations of sodium chloride don't precipitate protein. Other salts like guanidinidum chloride unfold proteins and do not lead to precipitation. Salt ions interact with both the protein and solvent water in somewhat complicated ways (which we will explore later). For now, we will simply be satisfied with the empirical observation that ammonium sulfate is the salt of choice to precipitate and also concentrate proteins from a solution. One advantage of (NH4)2SO4 precipitation of protein from solution is that it can be performed inexpensively with very large volumes, so it is used early in many purification proteins. Different proteins precipitate at different (NH4)2SO4 concentrations, so differential precipitation is often used. (NH4)2SO4 concentrations are increased in a step-wise fashion until the protein of interest is precipitated.
Some proteins are not soluble in water. These include transmembrane proteins that span cell membranes and large fibrous proteins. Membrane proteins can be solubilized by the addition of detergents like sodium dodecyl sulfate (SDS), which unfolds the proteins, and octylglucoside or Triton X-100, which keeps the protein structure intact.
Chromatography
Chromatography is used in almost all protein purification methods and is the key that allows the separation of a given protein from the 1000s of different proteins in cells and tissues. The separation of proteins on a chromatography column depends on the type of column and chemical/physical properties of the molecule. There are four main types used of chromatographies used to separate proteins:
- size exclusion chromatography in which proteins can be separated according to their size/shape or molecular weight
- ion exchange chromatography in which proteins are separated by their charge/isoelectric point;
- hydrophobic interaction chromatography (similar to reverse phase columns for purifying organic molecules) in which they are separated based on their relative hydrophobicity
- affinity chromatography in which proteins are separated based on binding to a ligand covalently attached to a column bead.
For preparative protein purification, the purification protocol generally contains one or more chromatographic steps. The basic procedure in chromatography is to flow the solution containing the protein through a column packed with a chromatography resin selected to separate proteins based on a specific property of the protein. Different proteins interact differently with the column material, and can thus be separated by the time required to pass the column, or the conditions required to elute the protein from the column. Usually, proteins are detected as they are eluting from the column by measuring the absorbance at 280 nm, at which the aromatic amino acids absorb.
Size Exclusion Chromatography (also known as Gel Filtration Chromatography)
This method is used to separate proteins based on size and shape. The chromatography beads have tiny openings/pores into which proteins of a size less than the pore diameter, can enter. Large proteins that can't enter the pore flow around the beads and elute faster than small ones that enter the pores. They diffuse out of the pores and enter the rest of the moving solvent before getting "trapped" again for a short time in more pores. Eventually, they work their way through the column and elute at a volume much greater than proteins, which can't enter the pores. Thus, proteins will be separated based on their size as illustrated in Figure \(\PageIndex{3}\). The eluate is collected in sequential test tubes (or fractions). Note that the figure below shows the pores as actual channels that go through the bead. In actuality, the openings in resin beads should be considered to be pores, not channels.

Also known as gel filtration chromatography, is a low-resolution isolation method that involves the use of beads that have tiny “tunnels" in them that each have a precise size. The size is referred to as an “exclusion limit," which means that molecules above a certain molecular weight will not fit into the tunnels. Molecules with sizes larger than the exclusion limit do not enter the tunnels and pass through the column relatively quickly by making their way between the beads. Smaller molecules, which can enter the tunnels, do so, and thus, have a longer path that they take in passing through the column. Because of this, molecules larger than the exclusion limit will leave the column earlier, while smaller molecules that pass through the beads will elute from the column later. This method allows the separation of molecules by their size.
In any chromatography system, there is a mobile and stationary phase. For size exclusion chromatography, the stationary phase is usually a polymerized agarose or acrylamide bead, which contains pores of various sizes filled with the solvent. Let's pretend that the solvent (typically aqueous buffered solution) inside of the bead is trapped there and doesn't exchange with the solvent moving around the bead, so it would be part of the stationary phase. The mobile phase is the solvent used to elute the column which flows around the bead. The chromatography beads are often supplied in dried form, which must be swollen in the solvent before they are packed in the column. The actual volume of the agarose or acrylamide bead is very small compared to the volume of solution within their hydrated forms.
Size and shape effects in size exclusion chromatography
Size-size exclusion chromatography is so common, so we will explore it in greater detail
Several different column volumes can be defined as shown in Figure \(\PageIndex{4}\), where the packed chromatography beads are shown as circles.
Figure \(\PageIndex{4}\): Define volumes in size exclusion chromatography
If we consider the mass of the beads to offer a negligible amount to the volume of the bead, the actual volume in the bead is mostly from the trapped solution, which can be considered to be the "stationary" phase. The volume around the bead is called the void volume, Vo. It should be apparent the volume inside the bead is given by
\begin{equation}
V_i=V_t-V_o
\end{equation}
A solute elutes from the column in a broad peak. If the sample volume applied to the column is very small compared to Vt, the volume at which a solute elutes, \(V_e\), is considered to be the center of the elution peak. This is true when \(V_{sample} \gg V_e\).
If we view this chromatography as a partitioning of solute between the mobile and stationary phases (the basis of all chromatography), we might be interested in what fraction of the stationary phase, Vi, a solute might partition into. Such a ratio would be given by:
\begin{equation}
K=\frac{V_e-V_o}{V_t-V_o}
\end{equation}
where Vt-Vo (= Vinside) represents 100% of the stationary phase, where \(K\) is a distribution coefficient. Consider two cases:
- A very large solute compared to the pore size of the bead: In this case, Ve-Vo = 0 since Ve would be equal to Vo. (The solute wouldn't "see" any of the Vi.) In this case, K = 0. The solute would elute in the void volume of the column since it is too large to partition into the volume within the beads. All solutes of molecular weight greater than or equal to the smallest solute that can't enter the gel beads will all elute in the void volume. Hence solutes greater than this minimal size will co-elute from the column and not be separated. Vo is usually about 30-40% of the Vt.
- A very small solute compared to the pore size. In this case Ve-Vo = Vt - Vo, since Ve would be equal to Vt. The solute would "see" all of the solvent within the bead. In this case, K = 1. Similar to above, all solutes of MW equal to or less than the largest solute that can partition into the entire volume within a bead will co-elute at a volume near Vt.
Hence \(K\) is a partition coefficient, which varies from 0 - 1, and represents that fraction of Vi into which a solute could partition. This K is not exactly a partition coefficient, however, since the actual volume of the gel matrix is assumed to be zero above. The graph in Figure \(\PageIndex{5}\) shows typical Ve as a fraction of Vt for solutes of different sizes (x-axis is Ve/Vt).

Large species that cannot enter the pores in the beads flow around it and elute in the void volume (V0) which is about 35-40% of Vt (red bell-shaped curve). Very small species can partition into both V0 and Vi so the elute near Vt (green bell-shaped curve). If a species adsorbs to the column bead through noncovalent interactions (such as hydrogen bonds or ion-ion interactions), it may elute after Vt (purple bell-shaped curve).
K depends on the size and shape of the solute. The size and shape of an object determine its flow properties in a fluid. Frictional resistance (itself a force, which acts in the opposite direction to the velocity, another vector quantity), can be shown to be proportional to the velocity.
\begin{equation}
F_f \propto v
\end{equation}
or
\begin{equation}
F_f=-f v
\end{equation}
where \(f\) is the frictional coefficient, which depends on the shape. Clearly, the bigger the object, the more frictional resistance to movement. For a sphere it can be shown that:
\begin{equation}
f=6 \pi \eta R_s
\end{equation}
where η is the viscosity (a measure of the resistance to flow of a liquid - water has a low viscosity, real maple syrup a high viscosity), and Rs (Stokes radius) is the radius of the hydrated sphere (the larger Rs, the larger the frictional coefficient, the larger the Ff which resists motion). For an irregularly shaped object, the Stokes radius is the radius of a sphere that would have the same frictional coefficient as the object. Hence the Rs for a protein molecule that was not spherical in shape would be much larger than the Rs for another protein molecule of identical molecular weight that was spherical. Hence the Ve and the K value for a solute on a gel filtration column would best be related to the Stokes radius, since Rs values take into account both size and shape.
If you separate two proteins of equal mass but one is highly elongated and the other is spherical, the elongated one, with a large RS, would elute first (assuming that both don't elute together in the void volume, V0.
Gel filtration can be used to determine the molecular weight of an unknown, spherical (globular) protein when compared to a standard curve generated from other globular proteins of known molecule weight. To ensure the protein have the same "effective" shape, the proteins are eluted under denaturing conditions to remove shape contributions to the elution order.
Separation on the basis of charge - Ion Exchange Chromatography
The chromatography resin in this type of chromatography consists of an agarose, acrylamide, or cellulose resin or bead which is derivatized to contain covalently linked positively or negatively charged groups. Proteins in the mobile phase will bind through electrostatic interactions to the charged group on the column. In a mixture of proteins, positively charged proteins will bind to a resin containing negatively charged groups, like the carboxymethyl group, CM (-OCH2COO-) or sulfopropyl, SP, (-OCH2CH2CH2SO3-) while the negatively charged proteins will pass through the column. The positively charged proteins can be eluted from the column with a mobile phase containing either a gradient of increasing salt concentration or a single higher salt concentration (isocratic elution). The most positively charged protein will be eluted last, at the highest salt concentration. Likewise, negatively charged proteins will bind to a resin containing positively charged groups, like the diethylaminoethyl group, DEAE (-OCH2CH2NH(C2H5)2+) or a quaternary ethyl amino group, QAE, and can be separated in an analogous fashion.
Ion exchange chromatography separates compounds according to the nature and degree of their ionic charge. The column to be used is selected according to its type and strength of charge. Anion exchange resins have a positive charge and are used to retain and separate negatively charged compounds (anions), while cation exchange resins have a negative charge and are used to separate positively charged molecules (cations).
Before the separation begins a buffer is pumped through the column to equilibrate the opposing charged ions. Upon injection of the sample, solute molecules will exchange with the buffer ions as each competes for the binding sites on the resin. The length of retention for each solute depends upon the strength of its charge. The most weakly charged compounds will elute first, followed by those with successively stronger charges. Because of the nature of the separating mechanism, pH, buffer type, buffer concentration, and temperature all play important roles in controlling the separation.
Figure \(\PageIndex{6}\) shows a cation exchange column. The beads (brown) contain negatively charged functional groups which can bind positive protein (blue) or concentrated regions of positive charge on a protein.

Before loading the column with protein, the negatively-charged beads would interact with positively charged counter cations (often Na+) from the column equilibration buffer. When the protein solution is introduced to the column, the positively charged protein will exchange with the bound Na+ ions (hence the name cation exchanger). Conversely, an anion exchanger consists of positively charged beads, which exchange bound anions. Proteins bounds through ion-ion interactions can be eluted by increasing the Na+ concentration in the eluting solution either in a stepwise or gradient fashion. Ion exchange chromatography is a very powerful tool for use in protein purification and is frequently used in both analytical and preparative separations.
Affinity Chromatography
In this technique, the chromatography resin is derivatized with a group that binds to a specific site on a given protein of interest. It may be a group that binds to the active site of an enzyme (such as benzamidine-agarose which is used for the purification of trypsin) or an antibody, which recognizes a specific amino acid sequence (an epitope) on a protein. For example, an antibody can be made to a specific peptide from albumin, the antibody covalently linked to agarose, and the antibody-agarose column then used to purify albumin specifically. This is a powerful technique since antibodies can be made that will bind selectively to a single protein. Knowing only the DNA sequence of a protein which has never been previously isolated, the amino acid sequence of the unknown protein can be derived from the DNA sequence. A 10-12 amino acid peptide from that protein can be synthesized in the lab (seethe last section below), and an antibody raised against the peptide. The antibody will most likely bind to the unknown protein as well as to the peptide, and hence could be used to purify the protein.
These features of affinity chromatography are illustrated in Figure \(\PageIndex{7}\).

In this example in Figure \(\PageIndex{7}\), protein P1 has affinity for ligand Z and will bind to the column while proteins P2 and P3 will pass through the column. Protein P1 can then be eluted from the column using high concentrations of free ligand Z.
In vitro peptide synthesis for antibody production
When making anti-peptide antibodies that recognized target proteins, or to study an isolated peptide by itself, it is more difficult to isolate and purify a peptide from its original protein than to synthesize it in the lab using solid-phase synthesis. We describe this technique below.
Peptides are chemically synthesized by the condensation reaction of the carboxyl group of one amino acid to the amino group of another. Two chemical challenges must be addressed. The formation of an amide bond between the carboxylic acid of one amino acid and the amine of the other is thermodynamically unfavorable, so the carboxyl end must be activated typically by the reaction of the incoming amino acid with a reagent such as dicyclocarbodiimide. Secondly, reactive functional groups on the side chains and the amine of the carboxyl group-activated amino acid must be protected from unwanted reactions. Chemical peptide synthesis most commonly starts at the carboxyl end of the peptide (C-terminus), and proceeds toward the amino-terminus (N-terminus). Protein biosynthesis in living organisms occurs in the opposite direction. Chemical synthesis facilitates the production of peptides, which incorporate unnatural amino acids, peptide/protein backbone modification, and the synthesis of D-amino acids.
The established method for the production of synthetic peptides in the lab is known as solid-phase peptide synthesis (SPPS). Pioneered by Robert Bruce Merrifield, SPPS allows the rapid assembly of a peptide chain through successive reactions of amino acid derivatives on an insoluble porous support. The solid support consists of small, polymeric resin beads functionalized with reactive groups (such as amine or hydroxyl groups) that link to the nascent peptide chain. Since the peptide remains covalently attached to the support throughout the synthesis, excess reagents and side products can be removed by washing and filtration. This approach circumvents the comparatively time-consuming isolation of the product peptide from the solution after each reaction step, which would be required when using conventional solution-phase synthesis.
Each amino acid to be coupled to the peptide chain N-terminus must be protected on its N-terminus and side chain using appropriate protecting groups such as t-Boc (t-butyloxycarbonyl-, acid-labile) or flourenylmethyloxycarbonyl (Fmoc, base-labile), depending on the side chain and the protection strategy used (see below).
The general SPPS procedure involves repeated cycles of alternate N-terminal deprotections and coupling reactions. The resin can be washed between each step to remove side products. The mechanism for the solid phase synthesis of a dipeptide is shown in Figure \(\PageIndex{8}\).

A. Deprotection of AA1: The first amino acid is coupled to the resin or purchased pre-coupled. The amine terminus contacting an FMOC group is deprotected with piperidine. The hydrogen abstracted from the FMOC is acidic as its negatively charged conjugated base is aromatic, since the negative charge on that C becomes sp2 hybridized to create the aromatic anion. The weak base piperidine is used to avoid side reactions.
B. Activation of AA2: The carboxyl group of AA2 reacts with a carbodiimide, which is attacked by the carboxylate of AA2 leading to the formation of an isourea derivative. This can react with a second nucleophilic catalyst (which is regenerated in step C), hydrobenzotriazole (HBT), to form the activated HBT ester and the very stable urea derivative.
C. Coupling Reaction: The activated AA2 now reacts with the amine of solid phase N-terminal deprotected AA1 to form the peptide bond.
This cycle repeats until the desired sequence has been synthesized. At the end of the synthesis, the crude peptide is cleaved from the solid support while simultaneously removing all protecting groups using a reagent strong acid like trifluoroacetic acid. The crude peptide can be precipitated from a non-polar solvent like diethyl ether in order to remove organic soluble by-products and then purified using reversed-phase HPLC. The purification process, especially of longer peptides can be challenging, because small amounts of several byproducts, which are very similar to the product, have to be removed. For this reason, so-called continuous chromatography processes such as MCSGP are increasingly being used in commercial settings to maximize the yield without sacrificing purity levels.
SPPS is limited by reaction yields, and typically peptides and proteins in the range of 70 amino acids are pushing the limits of synthetic accessibility. Synthetic difficulty also is sequence-dependent; typically aggregation-prone sequences such as amyloids are difficult to make. Longer lengths can be accessed by using ligation approaches such as native chemical ligation, where two shorter fully deprotected synthetic peptides can be joined together in solution.
Increasingly, proteins made in cells can be engineered through manipulation of the protein's gene to contain a molecular tag, which can either be a small peptide or a protein, for which antibodies are commercially available. The tag is expressed at either the N- or C-terminal end of the target so as to not interfere with the folding of the expressed target protein. Examples of peptide tags include the His (sequence HHHHHH), FLAG (sequence DYKDDDDK) and HA (YPYDVPDYA) tags. The HA tags derives from the influenza hemagglutinin protein. A small protein such as the green Fluorescent Protein - GFP) can also be used as a tag. The resulting fusion protein of GFP connected to the target protein can also allow the target protein to be localized and followed by confocal fluorescence microscopy within cell. Chromatography resins with covalently attached antibodies to the His, FLAG, HA peptide tags, and GFP are commercially available as affinity chromatography resins as shown in the right-hand side of Figure \(\PageIndex{9}\): below.

Affinity reagents other than antibodies can be attached to the beads, as shown in the left-hand side of Figure \(\PageIndex{9}\). Two, in particular, are Ni-Nitrilotriacetic acid (Ni-NTA) and the short peptide glutathione (γ-gluatmylcysteinylglycine). They also bind tagged proteins. The Ni-Nitrilotriacetic binds the His tag by chelation of the nickel ion with the 6 histidine imidazole groups on the His-tagged protein. (Note that His tags can also be bound to anti-His tag antibody beads.) Glutathione binds a protein tag, Glutathione-S-Transferase (GST) linked in a fusion protein to the target.
The His tag, which is probably the most widely used, binds strongly to divalent metal ions such as nickel and cobalt. The protein can be passed through a column containing Ni-nitrilotriacetic. All untagged proteins pass through the column. The protein can be eluted with imidazole, which competes with the imidazole side chain on the His tag for binding to the column, or by a decrease in pH (typically to 4.5), which decreases the affinity of the tag for the resin. While this procedure is generally used for the purification of recombinant proteins with an engineered affinity tag (such as a 6xHis tag), it can also be used for natural proteins with an inherent affinity for divalent cations.
Hydrophobic Interaction Chromatography (HIC)
HIC media is similar to reverse phase chromatography in which a matrix like silica (very polar with exposed OH groups) is derivatized with ester or ether links from the silica surface hydroxyl OHs to nonpolar molecules, usually containing 8 or 18 carbons in the acyl or alkyl chain. Proteins with exposed hydrophobic groups would preferentially bind to the bead. The interactions of the protein with the derivatized beads are increased by adding high concentrations of salt to the aqueous solution, making water effectively more polar. This would shift the equilibrium towards binding of the surface-exposed nonpolar region on the protein to the nonpolar C8 or C18 chains. The ionic strength of the buffer is then reduced to elute proteins in order of increasing hydrophobicity, as shown in Figure \(\PageIndex{10}\).

The column matrix, shown in blue has a hydrophobic ligand covalently attached. In high salt conditions, proteins will bind to the matrix with differing affinity, with more hydrophobic proteins (shown in yellow) binding more tightly than more hydrophilic proteins (shown in green) When the salt concentration is decreased, proteins that are more hydrophilic will be released first, followed more hydrophobic proteins.
High Performance Liquid Chromatography (HPLC) and Fast Protein Liquid Chromatography (FPLC)
High performance liquid chromatography or high pressure liquid chromatography (HPLC) is a form of chromatography applying high pressure to drive the solutes through the column faster than using gravity-forced flow of solvent through the column. The packing beads are small and very closely packed which allows less diffusion and greatly increased resolution. Because of the close packing of the small beads, no flow would occur with an external pump. The most common form of HPLC is "reversed phase" HPLC, where the column packing material is hydrophobic. The proteins are eluted by a gradient of water and increasing amounts of an organic solvent, such as acetonitrile. The proteins elute according to their hydrophobicity. After purification by HPLC, the protein is in a solution that only contains volatile compounds, and can easily be lyophilized (freeze-dried). HPLC purification frequently results in the denaturation of the purified proteins and is thus not applicable to proteins that do not spontaneously refold.
Due to the drawbacks of HPLC, an alternative technique using lower pressure was developed and is called Fast protein liquid chromatography (FPLC). In FPLC, the mobile phase is an aqueous solution, or "buffer". The buffer flow rate is controlled by a positive-displacement pump and is normally kept constant, while the composition of the buffer can be varied by drawing fluids in different proportions from two or more external reservoirs. The stationary phase is a resin composed of beads, usually of cross-linked agarose, packed into a cylindrical glass or plastic column. FPLC resins are available in a wide range of bead sizes and surface ligands depending on the application.
In the most common FPLC purification systems as shown in Figure \(\PageIndex{11}\), an ion exchange resin is typically chosen.
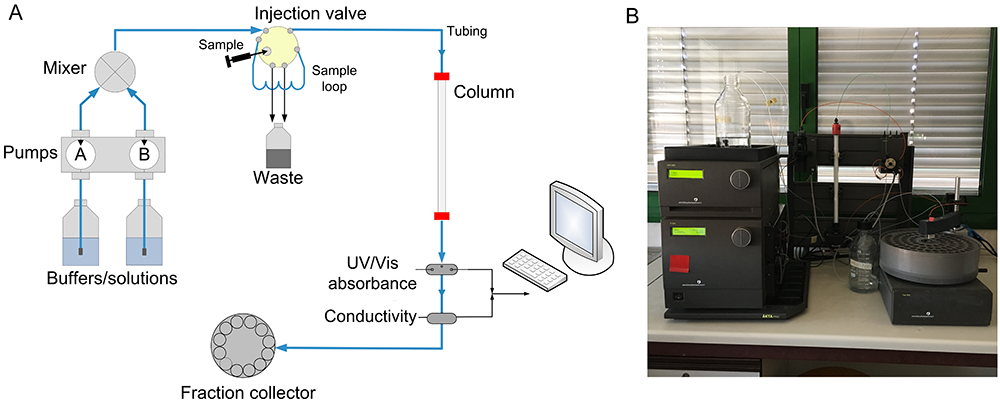
A mixture containing one or more proteins of interest is dissolved in 100% buffer A and pumped into the column. The proteins of interest bind to the resin while other components are carried out in the buffer. The total flow rate of the buffer is kept constant; however, the proportion of Buffer B (the "elution" buffer) is gradually increased from 0% to 100% according to a programmed change in concentration (the "gradient"). Buffer B contains high concentrations of the exchanger ion. Thus as the concentration of Buffer B gradually increases, bound proteins will dissociate depending on their ionic interactions with the column matrix and appear in the eluant. The eluant passes through two detectors which measures salt concentration (by conductivity) and protein concentration (by absorption of ultraviolet light at a wavelength of 280 nm). As each protein is eluted it appears in the eluant as a "peak" in protein concentration and can be collected for further use.
Purification Scheme
During the protein purification process it is necessary to have a quantitative system to determine, the total amount and concentration of total and target protein at each step, the biological activity of the target protein, and its overall purity. This will help guide and optimize the purification method being developed. Ineffective separation techniques can be disregarded and other techniques that give higher yield or that retain biological activity of the protein can be adopted.
Thus, each step in the purification scheme is quantitatively evaluated for the following parameters: total protein, total activity, specific activity, yield, and purification level. Each of these parameters will be defined within the protocol given below.
Pretend you are a researcher that wants to isolate a novel, unknown protein from a bacterial culture. You grow 500 ml of the bacteria overnight at 37oC and harvest the bacteria by centrifugation. You remove the culture broth and retain the bacterial pellet. You then lyse the bacteria using freeze/thaw in 10 mL of reaction buffer. You then centrifuge the lysed bacteria to remove the insoluble materials and retain the supernatant that contains the soluble proteins. Your protein of interest has a biological activity that you can measure using a simple assay that causes a color change in the reaction mixture, as illustrated in Figure \(\PageIndex{12}\). You also note that this reaction rate increases with increasing concentrations of your protein supernatant.

At this point, you can measure your baseline concentrations for the first purification level (bacterial lysis and removal of insoluble proteins and other cellular debris by centrifugation).
Total Protein is calculated by measuring the concentration in a fraction of the sample, and then multiplying that by the total volume of your sample. In this case, you are starting with 10 mL of supernatant. In a typical assay to measure protein concentration, you will use 50 - 200 μL of sample to determine the protein concentration. For example, if you calculate that there is 7.5 μg/μL in your initial assay, you would need to convert that value into mg/mL and then multiply it by 10 mL for a total of 75 mg of protein in 10 mL of supernatant (Table 3.1)
Total Activity is measured as the enzyme activity within the assay, multiplied by the total volume of the sample. For example, in the initial sample, you might use 5 to 50 μL of sample in your biological reaction (Figure 3.10). If you calculated the activity in your assay to be 2.5 units/μL, this would be equivalent to 2,500 units/mL or 25,000 units/10 mL of supernatant. Note that, the enzyme unit, or international unit for the enzyme (symbol U, sometimes also IU) described the enzyme's catalytic activity. 1 U (μmol/min) is defined as the amount of the enzyme that catalyzes the conversion of one micromole of substrate per minute under the specified conditions of the assay method.
Specific Activity is measured by dividing the Total Activity by the Total Protein. In our example, 25,000 units divided by 75 mg of protein = 333.3 units/mg.
Yield is a measure of the biological activity retained in the sample after each purification step. The amount in the first step is set to be 100%. All subsequent yield steps will be evaluated using the first purification step. It is calculated by dividing the total activity of the current step, by the total activity of the first step and then multiplying by 100.
Purification level evaluates the purity of the protein of interest by dividing the specific activity calculated after each purification step by the specific activity of the first purification step. Thus, the first step always has a value of 1. A typical purification analysis scheme is shown in Table \(\PageIndex{1}\) below.
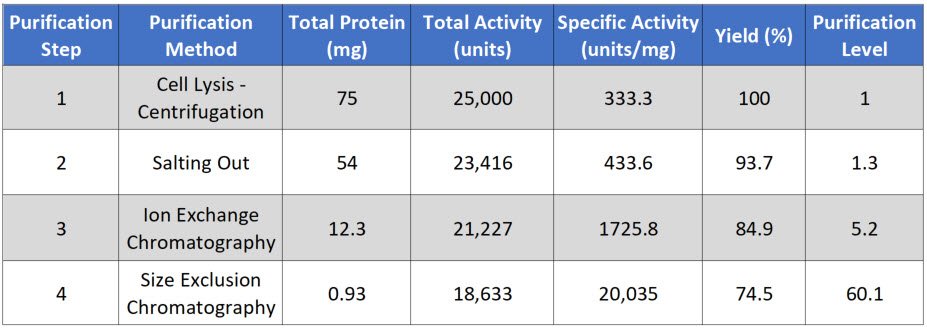
Table \(\PageIndex{1}\): A typical purification analysis scheme.
Note that after each purification step, the Total Protein goes down, as you are separating the target protein away from other proteins in the mixture. Total Activity also goes down with each purification step, as some of your protein of interest is also lost at each purification step, because (1) some protein will stick to the test tubes and glassware, (2) some protein won't bind with 100% efficiency to your column matrix, (3) some protein may bind too tightly to be removed from the column matrix during elution, and (4) some protein may be denatured or degraded during the purification process.
The amount of your protein of interest that is retained is represented within the overall percent yield for each purification step. If the percent yield is too low alternative purification methods should be explored.
Note that in a good protein purification scheme that the specific activity should go up substantially with each level of purification as the amount of your protein of interest makes up a greater percentage of the total protein within that fraction. If the specific activity only increases modestly within a purification step, or if it decreases during a purification step, this could indicate that (1) your protein of interest is being substantially lost at that step, (2) your protein of interest is being denatured or degraded and is no longer biologically active, or (3) that a required cofactor or binding protein is being reduced at that purification step. Additional experiments may need to be conducted to determine which of the causes predominate, so that steps can be taken to reduce protein inactivation. For example, many proteins are temperature sensitive and will degrade or denature at room temperature. Completing purification steps on ice can often reduce degradation.
Overall, the fold increase in purification level should increase exponentially during the purification process. Note that in our example, if after 4 steps of purification our proteins is close to 95% pure, this would indicate that our protein of interest makes up approximately 1.24% of the total protein within the sample.
Electrophoresis: Separation and Analysis
In column chromatography, flow through the column is driven by hydrostatic pressure causing flow from higher regions of higher pressure at the top of the column reservoir to lower pressure (drops eluting from the bottom of the column). Ultimately the hydrostatic pressure (in columns not driven by mechanical pumps) derives from the gravitational force. However, proteins are also charged particles and can be moved by an external electric field instead of a gravitational field. Electrophoresis is the movement of charged particles in an electric field. As we will show below, the movement of a charged protein within a static matrix in the presence of an external electric field depends on both size and shape. Electrophoresis can be used for both analytical and preparative separations of proteins. The most common uses are for analytical separations.
Theory
What determines how a protein moves in an electric field? Consider the simple case of a charged particle (+Q) moving in an electric field (E) in a nonconducting medium, such as water. If the particle is moving at a constant velocity toward the cathode (- electrode where cations go), the net force Ftot on the particle is 0 (since F=ma, and the acceleration (a) of the particle is 0 at constant velocity). Two forces are exerted on the particle, one FE, the force exerted on the charged particle by the field, which is in the direction of the motion (toward the cathode), and the other, Ff, the frictional force on the charged particle, which retards its motion toward the cathode, and hence is in the direction opposite to the motion (toward the anode (+) electrode). This is shown in the Figure \(\PageIndex{13}\):

Therefore:
\begin{equation}
\mathrm{F}_{\text {tot }}=\mathrm{F}_{\mathrm{E}}+\mathrm{F}_{\mathrm{f}}
\end{equation}
where FE, the electrical force, is
\begin{equation}
\mathrm{F}_{\mathrm{E}}=\mathrm{QE}
\end{equation}
and
Ff, the frictional force, is
\begin{equation}
\mathrm{F}_{\mathrm{f}}=-\mathrm{fv}
\end{equation}
In the last equation, v is the velocity of the particle, and f is a constant called the frictional coefficient. This equation shows that the force Ff hindering motion toward the cathode is proportional to the velocity of the particle. This is intuitive since one would expect the higher the velocity, the greater the Ff which would hinder the motion. The frictional coefficient depends on the size and shape of the molecule. The larger the molecule, the larger the frictional coefficient (i.e. more resistance to the motion of the molecule). It can be shown that the frictional coefficient for a spherical particle is given by
\begin{equation}
\mathrm{f}=6 \pi \eta \mathrm{R}_{\mathrm{S}}
\end{equation}
where η is the viscosity (a measure of the resistance to flow of a liquid - water has a low viscosity, real maple syrup a high viscosity), and Rs (Stokes radius) is the radius of the hydrated sphere (the larger Rs, the larger the frictional coefficient, the larger the Ff which resists motion toward the cathode). This equation should be intuitive from your experiences. From (1), (2), and (3), Fe = Ff , or
\begin{equation}
\mathrm{QE}=\mathrm{fv}
\end{equation}
Hence v/E = Q/f = U = the electrophoretic mobility, or
\begin{equation}
\mathrm{U}=\frac{\mathrm{V}}{\mathrm{E}}=\frac{\mathrm{Q}}{6 \pi \eta \mathrm{R}_{\mathrm{S}}}
\end{equation}
Therefore, the electrophoretic mobility U is proportional to the charge density (charge/size, Q/Rs) of the particle, not just the size as is the case for spherical proteins in size exclusion chromatography. Macromolecules of different charge density can thus be separated by electrophoresis. This discussion deals with the simplest case, since in reality there are counter ions in the solution (from salts) which would form a cloud around the charged macromolecule, and partially shield the charged particle from the electric field E.
Modern day electrophoresis is conducted in solid gels (such as polyacrylamide), which are formed from liquid acrylamide solutions after the addition of a polymerizing agent. The solid gel is porous to solute and solvent molecules and serves as a medium for electrophoresis while helping to eliminate convection forces in the liquid which interfere with the separation. Electrophoretic experiments have been conducted on the space station in weightless conditions in order to prevent such perturbations.
One complication that affects this idealized description of electrophoresis in polyacrylamide gels is that the gels have pores through which the macromolecules move. Think of the protein moving under an electric force through a "spider web-like" matrix. As in gel chromatography, the smaller molecules can pass through the pores more readily than larger molecules, so there is an additional sieving mechanism that contributes to the effective mobility (Also, the gel could alter the local effective electric field). The sieving effect of the gel actually increases the resolving power of this technique.
It has been determined that the actual electrophoretic mobility of the protein, U, is a function of the mobility of the protein in a concentrated sucrose solution (Uo) and T, the total concentration of the acrylamide in the polymerized gel. The higher the concentration of acrylamide in the unpolymerized gel solution, the smaller the size of the pores in the polymerized gel. An equation showing the relationship between U, Uo, and T is shown below:
\begin{equation}
\log \mathrm{U}=\log \mathrm{U}_{0}-\mathrm{K}_{\mathrm{r}} \mathrm{T}
\end{equation}
where Kr is the slope of a plot of log U vs T for a given protein. Since Kr is a function of the radius of the molecule, it is possible to determine the molecular weight of a protein molecule by performing several electrophoretic separations in gels of different acrylamide concentrations (T), and extrapolating results to T = 0, hence eliminating pore size effects. Problems arise, however, if the proteins are not spheroid in shape
Is there any way to obtain molecular weight information, in addition to purity determination, on a single gel? What would result if two different proteins, each with the same molecular weight and total net charge, but different shapes, were run on a single acrylamide gel? The one having the more elongated shape (large Stokes radius) would have lower electrophoretic mobility (U = Q/6πηRs). A larger Rs would also cause the protein to enter the pores at a slower rate. Hence both electrophoretic mobility and sieving effects would cause this protein to run anomalously slow and have a higher apparent molecular weight. Also ,imagine two globular proteins of different sizes but with compensatory charge differences which might allow the two proteins to migrate at the same speed in the gel.
An astute reader might quickly recognize a problem with the separation of proteins by electrophoresis in a gel. Some proteins are negatively charged (pH > pI), some would be neutral (pH=pI) and the rest would be positive (pH < pI). Only some proteins would enter the gel and move to the electrode at the bottom of the gel. Luckily there is a way to eliminate both charge and shape effects in the electrophoresis of proteins and that is to run the gel under denaturing conditions when all proteins have the same charge density. The denaturant of choice for electrophoresis is usually sodium dodecyl sulfate (SDS), which is an ionic detergent with the structure CH3(CH2)10CH2OSO3- (a single chain amphiphile). This detergent binds to and denatures most proteins, with about 1.4 g SDS binding/g of protein (about 1 SDS/2 amino acids). Since there is 1 negative charge/SDS, the binding of SDS masks any of the charges on the protein, and gives all proteins an overall large negative charge. Additionally, SDS-proteins complexes have been shown to generally have an elongated cylindrical-like shape. Since the amount of SDS bound per unit mass of protein is constant, the overall charge density on all proteins is similar, so the electrophoretic mobility is only determined by sieving effects.
SDS also eliminates shape differences in the proteins as a variable, since all proteins have the same general rod-like shape. (The use of SDS is analogous to the use of 8M urea in the gel chromatographic separation of proteins to determine molecular weights). Mobility becomes only a function of the molecular weight of the protein, and not its shape. The molecular weight of an unknown protein can be determined by comparing the protein's position on an SDS polyacrylamide gel with a series of known molecular weight standards from which a linear plot of the ln Mr vs Rf can be used to calculate unknown molecular weights. This is similar to the analysis in gel chromatography, where ln Mr is a linear function of Kavg, the distribution coefficient, when the gel is run under denaturing conditions. However, some proteins run anomalously on such gels (due to incomplete or excess binding SDS), so alternative techniques of molecular weight determination should be used in conjunction with this technique.
Proteins are usually heated in SDS to 100oC for 3 minutes, in the presence of a reducing agent such as β-mercaptoethanol (βME), to completely denature the protein to a rod-shaped protein. Apparent molecular weight can be obtained under non-reducing conditions (without βME), but these should be considered just estimates. Running proteins both in the presence and absence of the reducing agent can provide important information on the subunit structure of a protein. A multimeric protein whose subunits are held together by disulfide bonds can be resolved into its individual components when the reducing agent is added. If the subunits are held together by noncovalent intermolecular attractions, the proteins will run identically under the denaturing conditions (SDS), which will eliminate subunit interactions, in the presence or absence of b-ME. To determine the subunit composition of a protein held together by noncovalent interactions, the electrophoresis should be performed in the absence of denaturing agents.
Electrode nomenclature might be confusing to some of you. As mentioned above, cations move towards the cathode (where reduction occurs), so the cathode must be negative. Likewise, anion move towards the anode (where oxidation occurs), so the anode must be positive. This is the opposite of what you might remember from introductory science courses when you discussed primarily galvanic cells. In galvanic cells, an electrical current is generated from a spontaneous set of redox half-reactions. In electrophoresis, electrolytic cells are used, in which reactions such as the electrolysis of water (2H2O(l) → 2H2 (g) + O2(g)) or the productions of Cl2(g) and Mg(s) from the aqueous electrolyte MgCl2(aq) occur. Those who have done electrophoresis will have seen robust bubble production from the electrodes arising from the electrolysis (a redox reaction) of water (2H2O →2H2(g) + O2(g)). In electrolytic cells, a power supply must supply the current to drive the nonspontaneous (unfavored thermodynamically) reactions, such as outlined above. These differences are illustrated in Figure \(\PageIndex{14}\).
 Figure \(\PageIndex{14}\): Galvanic vs electrolytic cells
Figure \(\PageIndex{14}\): Galvanic vs electrolytic cells
Polyacrylamide Gel Electrophoresis - PAGE
Electrophoresis is performed in a porous, yet solid medium, to eliminate any problems associated with convection currents. Such media are formed from the solidification of a liquid solution of agarose (used mostly for electrophoresis of DNA fragments and very large proteins) or the polymerization of a solution of acrylamide. Polymerization of acrylamide is initiated by the additions of ammonium persulfate in the presence of tetramethylenediamine (TEMED), along with a dimer of acrylamide (N,N'-methylene-bis(acrylamide) connected covalently between the amide nitrogens of the acrylamides by a methylene group. The structures of these compounds are shown in Figure \(\PageIndex{15}\).

The free radical polymerization of the acrylamide is initiated by the addition of ammonium persulfate, which on dissolving in water, forms free radicals, as shown above
The radical initiates polymerization of the acrylamide, as shown below. The TEMED, through its ability to exist as a free radical, acts as an additional catalyst for polymerization. A rigid gel is only formed, however, when N,N'-methylene-bis(acrylamide is added to the mixture during the polymerization, which cross-links adjacent acrylamide polymers as shown in Figure \(\PageIndex{16}\).

The amount of bisacrylamide added during polymerization controls the degree of cross-linking, and hence the pore size of the polymerized gel. The effect of pore size is OPPOSITE to that in gel chromatography. In both cases, large proteins have a difficult time entering the pore. In gel chromatography, large proteins partition preferentially into the mobile liquid phase (the void volume) and are eluted most QUICKLY from the column. In electrophoresis, large proteins, which can not readily enter the pores in the gel, are not as easily transported by the electric field through the gel, and elute most SLOWLY. Pore size can not be controlled as accurately as in the manufacture of gel chromatography resins.
How do proteins migrate through the gel? A viscous protein solution is layered on the top of the gel in a small well molded into the gel during the polymerization process. The bottom and top parts of the gel are inserted into reservoirs containing a buffered solution and the appropriate electrode. The electric field is applied and the proteins migrate through the hydrated gel. The nature of the buffer solution in the reservoir and in the polymerized gel is important. The components of the buffer must not bind to the proteins to be separated. Additionally, for native (non-denatured gels), the pH of the medium must be such that the proteins have the appropriate charge, so they will migrate in the expected direction.
There are many variations of electrophoresis commonly used. Gels can be polymerized in tubes, or slabs, and in the presence or absence of denaturing agents. Additionally, a given slab might consist of two separate slabs polymerized one on top one other, each with a different acrylamide concentration and pH values. The top part is the stacking gel, te bottom is called the running gel. Other gels have a continuous gradient of acrylamide concentrations (from low at the top to high at the bottom). Most commercially available precast gels use continuous acrylamide concentration gradients. Figure \(\PageIndex{17}\) shows a gel placed in an electrophoresis chamber.
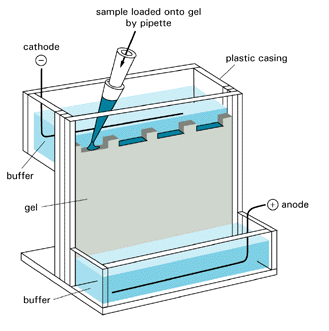
Whether the gel has a continuous gradient or is discontinuous, the top part of the gel is a low concentration acrylamide (2-4%), often in a Tris HCl buffer solution (pH 6.5) usually 2 pH units below that used in the running gel. The lower part of the gel 8-15% acrylamide, depending on the choice of gel, which is selected based on the molecular weight of the proteins to be separated. The upper buffer reservoir contains Tris-buffered with a weak acid such as glycine (pKa2 = 9.6) to the same pH as the running gel.
Protein electrophorese quickly through the local concentration stacking gel and at the top of continuous gradient gels, and effectively "stack" as they hit the interface between the stacking and running gels, or before they enter too far into the continuous gradient gel. This increases the compactness of the proteins before they enter the "running" section of the gel and increases resolution.
For discontinuous gels, how does this stacking process work? When the electrophoresis is started, glycine ions from the upper reservoir (at pH 8.7) enter the stacking gel since at that pH they have an average partial negative charge. The stacking gel buffer ions continue moving in the stacking gel, but when the glycine ions enter the pH 6.5 of the stacking gel, they become zwitterions with a net charge of zero, and hence stop their motion toward the anode. The electrical resistance in the stacking gel then increases since the number of ions moving through the stacking gel decreases. To maintain constant current throughout the circuit, there will be a localized increase in the voltage in the stacking gel (from Ohms Law, V=iR). This will cause the proteins to migrate quickly and all stack in a single, very thin disc right behind the Cl- ions in the stacking gel (which are in front because they have the highest charge density and electrophoretic mobility of any ion in the stacking gel). The proteins will not pass the Cl- ions since if they did, they would immediately slow down since they would no longer be in an area of diminished charged carriers and higher voltage. At the stacking gel/running gel interface, the proteins can not all migrate at the same speed, due to sieving effects of the more concentrated gel, and hence will be separated in the running gel. The glycine eventually enters the running gel, assumes its fully charged state at that pH (8.7), will pass the proteins, and restore the deficiency in charge that occurred in the stacking gel.
Detection of proteins in the gel:
Most proteins do not absorb at visible wavelengths of light, and hence will not be visible during the course of electrophoresis. To ensure that the proteins are not eluted from the gel into the lower buffer reservoir, a small molecular weight, anionic dye, bromophenol blue is added to the protein before it is placed on the gel. The electrophoresis is halted when the dye reaches the bottom of the gel. The gel assembly is removed from the electrophoresis chamber, the glass plates separated, and the gel washed into a series of solutions with the goal of rendering the banded proteins visible to the eye.
- Coomassie Brililant Blue dye: This is the most common stain used in labs. It is dissolved in a methanol/acetic acid solution so it generates significant waste. Proteins bind this dye, with a concomitant spectral shift in the absorbance properties of the bound dye. The methanol and acetic acid in the dye solution also help to "fix" the proteins in the gel, and prevent their diffusion into the solution. After the gel is stained, the background stain in the gel is removed with acetic acid/methanol, leaving the blue-colored protein bands. Some proteins will not be stained with Coomassie blue.
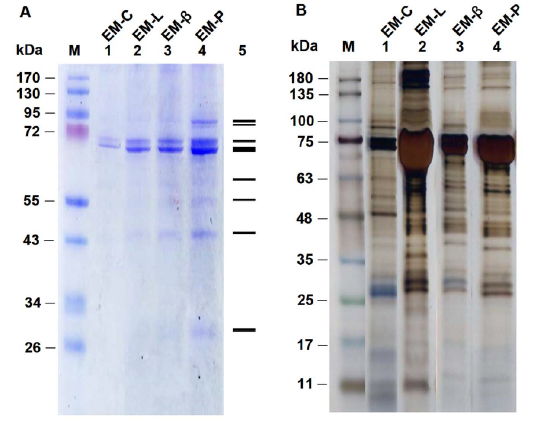
- Silver staining: This involves the reduction of Ag(I) to elemental silver and its deposition by protein in the appropriate reaction solutions, much as in a photographic process. (Remember in the BCA assay, peptide bonds reduce Cu(II) to Cu(I), which is chelated to BCA.) A developer and fixer solution is required. This technique is 10-50 X more sensitive than Coomassie Blue staining. Figure \(\PageIndex{18}\) shows gels stained with Coomasie Blue (A)and silver staining (B).
- Pre-electrophoresis fluorescent or radioactive modification of the proteins. These allow even greater sensitivity. After the electrophoresis of a radiolabeled protein, the gel can be dried and overlaid with X-ray film for periods as long as months, if necessary, to allow sufficient exposure of the film by a low concentration protein. This visualization technique is called autoradiography.
Variations on polyacrylamide gel electrophoresis:
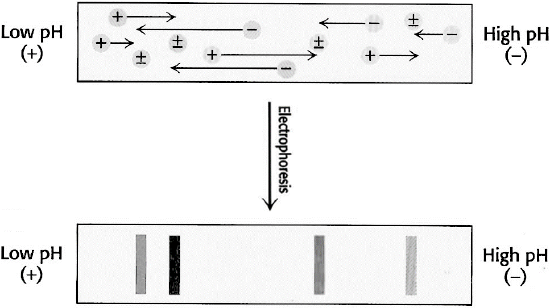
Isoelectric focusing: In this technique, a pH gradient is set up within the polyacrylamide gel or strip. This is accomplished by pre-electrophoresing a series of low molecular weight molecules containing amino and carboxyl groups called ampholytes, each with a different isoelectric point. When subjected to an electric field, the most negative of the species will concentrate at the anode, while the most positive will concentrate toward the cathode. The remaining ampholytes will migrate in-between, with the net effect being that the ampholytes migrate to their isoelectric point and set up a linear pH gradient in the gel.
Proteins initially in regions with a pH below its isoelectric point are positively charged and migrate toward the cathode, while those that are in media with pH lower than its pI will be negatively charged and migrate towards the anode as shown below in Figure \(\PageIndex{19}\). The migration will lead to a region where the pH coincides with its pI. There the protein will have a zero net charge and stop. Thus amphoteric molecules are located in narrow bands where the pI coincides with the pH. In this technique the point of application is not critical as molecules will always move to their pI region. The stable pH gradient between the electrodes is achieved using a mixture of low molecular weight ampholytes whose pIs covers a preset range of pH.
2D electrophoresis: Two-dimensional gel electrophoresis (2-DE) is based on separating a mixture of proteins according to two molecular properties, one in each dimension. The most used is based on a first dimension separation by isoelectric focusing (IEF) and a second dimension according to molecular weight by SDS-PAGE. A conditioning step is applied to proteins separated by IEF prior to the second-dimension run. This process reduces disulfide bonds and alkylates the resultant sulfhydryl groups of the cysteine residues. Concurrently, proteins are coated with SDS for separation on the basis of molecular weight. After the IEF, the tube or strip is placed across the top of a slab gel and subjected to SDS-polyacrylamide gel electrophoresis in a direction 90o from the initial isoelectric focusing experiment. If the proteins were derived from cells labeled with 35Met, representing unique proteins can be obtained from a given cell population. Figure \(\PageIndex{20}\) shows a 2D electrophoresis gel.
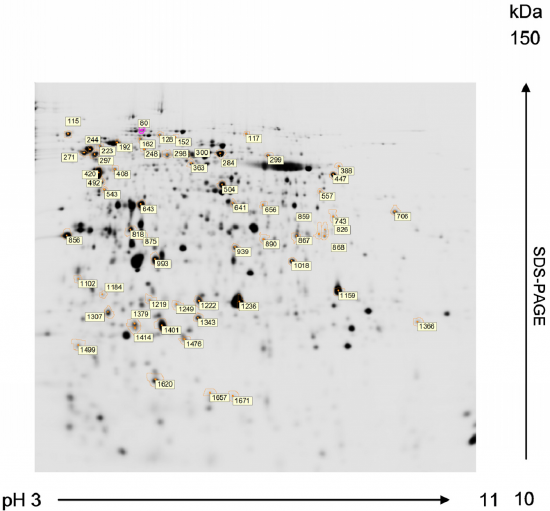
In Figure \(\PageIndex{20}\), proteins of Chlamydomonas reinhardtii are resolved by 2-DE from preparative gels stained with MALDI-MS compatible silver reagent for peptide mass fingerprinting analysis. First dimension: isoelectric focusing in a 3-11 pH gradient. Second dimension: SDS-PAGE in a 12% acrylamide (2.6% crosslinking) gel (1.0 mm thick). Numbered spots marked with a circle correspond to proteins compared to be subsequently identified by MALDI-TOF MS. The MALDI-TOF MS analysis of protein sequences is discussed in more detail in section 3.3 below.
One of the biggest problems in 2-DE is the analysis and comparison of complex mixtures of proteins. Currently there are databases capable of comparing two-dimensional gel patterns. These systems allow automatic comparison of spots for the precise identification of those needed in the quantitative analysis. Once interesting proteins are identified, the proteins can be excised from gels, destained, and digested to prepare for their identification by mass spectrometry. This technique is known as peptide mass fingerprinting. The ability to precisely determine molecular weight by matrix-assisted laser desorption/ionization time of flight mass spectrometry (MALDI-TOF MS) and to search databases for peptide mass matches has made high-throughput protein identification possible. Proteins not identified by MALDI- TOF can be identified by sequence tagging or de novo sequencing using the Q-TOF electrospray LC-MS-MS.
Western blotting: After a standard SDS-slab electrophoresis experiment is run, the gel is overlaid with a piece of nitrocellulose membrane. The sandwich of gel and filter paper is placed back into an electrophoresis chamber, such that the proteins migrate from the gel into the nitrocellulose, where they irreversibly bind. This is illustrated in the figure below. Note however that in the absence of staining, the protein bands in either the PAGE gel or Western blot would not be visible. Standards (lane 5) would be visible if they were labeled with chromophores, as shown in Figure \(\PageIndex{21}\).

If a cell lysate was applied to a lane of a PAGE gel, after staining with any technique, the bands would appear as overlapping smears on the stained gel. What makes Western blots so useful is that specific bands can be specifically visualized (stained) on the nitrocellulose membrane by using a detection system linked to an antibody that recognizes just a specific target protein. This is illustrated in Figure \(\PageIndex{22}\).

3D electrophoresis: To detect specific proteins in a 2D electrophoresis experiment, a 3rd dimension of separation, a Western blot, could be performed on the PAGE gel and the nitrocellulose stained with an antibody specific to a target protein. That is illustrated in Figure \(\PageIndex{23}\).

Part A, isoelectric focusing, is followed by a PAGE gel (B). The red dots represent proteins that have undergone a post-translational modification in which a phosphate group has been added to tyrosine side chains (for example). Western blotting is performed in panel C and staining in panel D. The left blot in D uses an antibody that recognizes phosphorylated tyrosine side chains on protein. The right blot is D is sometimes called a Far Western blot. If the protein on the nitrocelluose membrane retains some 3D native structure or can be induced to refold, it can be probed on the blot by a protein that binds to the native form of the protein on the blot. In the example shown in panel D above, the p-Tyr-protein target on the nitrocellulose membrane recognizes a fusion protein of PTP-GST. GST is a protein tag for detection. PTP is a protein tyrosine phosphatase, an enzyme that hydrolyzes p-Tyr on specific phosphorylated target proteins.
References
Molnar, C. and Gair, J. (2013) Antibodies. Chapter in Concepts in Biology, Published by B.C. Open Textbook Project. Available at: https://opentextbc.ca/biology/chapter/23-3-antibodies/
The Human Atlas Project. (2019) Methods. Available at: https://www.proteinatlas.org/learn/method
Uhlén M et al, 2015. Tissue-based map of the human proteome. Science
PubMed: 25613900 DOI: 10.1126/science.1260419
Thul PJ et al, 2017. A subcellular map of the human proteome. Science.
PubMed: 28495876 DOI: 10.1126/science.aal3321
Uhlen M et al, 2017. A pathology atlas of the human cancer transcriptome. Science.
PubMed: 28818916 DOI: 10.1126/science.aan2507
Ahern, K. and Rajagopal, I. (2019) Biochemistry Free and Easy. Published by Libretexts. Available at: https://bio.libretexts.org/Bookshelves/Biochemistry/Book%3A_Biochemistry_Free_and_Easy_(Ahern_and_Rajagopal)/09%3A_Techniques/9.04%3A_Gel_Exclusion_Chromatography.
Magdeldin, S. (2012) Gel Electrophoresis - Principles and Basics. Published by InTech under Creative Commons Attribution 3.0. Available at: https://pdfs.semanticscholar.org/4b93/70ac3946cec6e12c369679c4178a5ef38e61.pdf
Structural Biochemistry/Proteins/X-ray Crystallography. (2018, November 19). Wikibooks, The Free Textbook Project. Retrieved 15:40, August 17, 2019 from en.wikibooks.org/w/index.php?title=Structural_Biochemistry/Proteins/X-ray_Crystallography&oldid=3488057.
UCD: Biophysics 200A (2019) "NMR Spectroscopy vs X-ray Crystallography", Chapter published in Current Techniques in Biophysics. Published by Libretexts and available at: https://phys.libretexts.org/Courses/University_of_California_Davis/UCD%3A_Biophysics_200A_-_Current_Techniques_in_Biophysics/NMR_Spectroscopy_vs._X-ray_Crystallography
Wikipedia contributors. (2019, June 27). Protein purification. In Wikipedia, The Free Encyclopedia. Retrieved 23:32, July 28, 2019, from en.Wikipedia.org/w/index.php?title=Protein_purification&oldid=903657925
Wikipedia contributors. (2019, February 15). Fast protein liquid chromatography. In Wikipedia, The Free Encyclopedia. Retrieved 17:14, August 15, 2019, from en.Wikipedia.org/w/index.php?title=Fast_protein_liquid_chromatography&oldid=883530035
Wikipedia contributors. (2019, July 9). Protein mass spectrometry. In Wikipedia, The Free Encyclopedia. Retrieved 15:27, August 16, 2019, from en.Wikipedia.org/w/index.php?title=Protein_mass_spectrometry&oldid=905547289
Wikipedia contributors. (2019, July 8). Peptide synthesis. In Wikipedia, The Free Encyclopedia. Retrieved 06:13, August 17, 2019, from en.Wikipedia.org/w/index.php?title=Peptide_synthesis&oldid=905401648