
DNA Repair in Replication*#
- Page ID
- 8269

Replication design challenge: proofreading
When the cell begins the task of replicating the DNA, it does so in response to environmental signals that tell the cell it is time to divide. The ideal goal of DNA replication is to produce two identical copies of the double-stranded DNA template and to do it in an amount of time that does not pose an unduly high evolutionarily selective cost. This is a daunting task when you consider that there are ~6,500,000,000 base pairs in the human genome and ~4,500,000 base pairs in the genome of a typical E. coli strain and that Nature has determined that the cells must replicate within 24 hours and 20 minutes, respectively. In either case, many individual biochemical reactions need to take place.
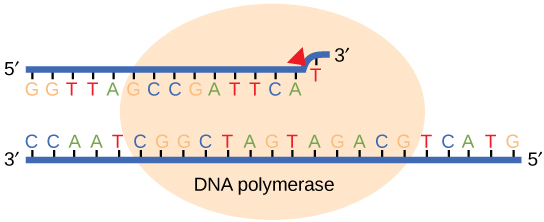
While ideally replication would happen with perfect fidelity, DNA replication, like all other biochemical processes, is imperfect—bases may be left out, extra bases may be added, or bases may be added that do not properly base-pair. In many organisms, many of the mistakes that occur during DNA replication are promptly corrected by DNA polymerase itself via a mechanism known as proofreading. In proofreading, the DNA polymerase "reads" each newly added base via sensing the presence or absence of small structural anomalies before adding the next base to the growing strand. In doing so, a correction can be made.
If the polymerase detects that a newly added base has paired correctly with the base in the template strand, the next nucleotide is added. If, however, a wrong nucleotide is added to the growing polymer, the misshaped double helix will cause the DNA polymerase to stall, and the newly made strand will be ejected from the polymerizing site on the polymerase and will enter into an exonuclease site. In this site, DNA polymerase is able to cleave off the last several nucleotides that were added to the polymer. Once the incorrect nucleotides have been removed, new ones will be added again. This proofreading capability comes with some trade-offs: using an error-correcting/more accurate polymerase requires time (the trade-off is speed of replication) and energy (always an important cost to consider). The slower you go, the more accurate you can be. Going too slow, however, may keep you from replicating as fast as your competition, so figuring out the balance is key.
Errors that are not corrected by proofreading become what are known as mutations.
Suggested discussion
Why would DNA replication need to be fast? Consider the environment the DNA is in, and compare that to the structure of DNA while being replicated.
Suggested discussion
What are the pros and cons of DNA polymerase's proofreading capabilities?
Replication mistakes and DNA repair
Although DNA replication is typically a highly accurate process, and proofreading DNA polymerases helps to keep the error rate low, mistakes still occur. In addition to errors of replication, environmental damage may also occur to the DNA. Such uncorrected errors of replication or environmental DNA damage may lead to serious consequences. Therefore, Nature has evolved several mechanisms for repairing damaged or incorrectly synthesized DNA.
Mismatch repair
Some errors are not corrected during replication but are instead corrected after replication is completed; this type of repair is known as a mismatch repair. Specific enzymes recognize the incorrectly added nucleotide and excise it, replacing it with the correct base. But, how do mismatch repair enzymes recognize which of the two bases is the incorrect one?
In E. coli, after replication, the nitrogenous base adenine acquires a methyl group; this means that directly after replication the parental DNA strand will have methyl groups, whereas the newly synthesized strand lacks them. Thus, mismatch repair enzymes are able to scan the DNA and remove the wrongly incorporated bases from the newly synthesized, non-methylated strand by using the methylated strand as the "correct" template from which to incorporate a new nucleotide. In eukaryotes, the mechanism is not as well understood, but it is believed to involve recognition of unsealed nicks in the new strand, as well as a short-term, continuing association of some of the replication proteins with the new daughter strand after replication has completed.
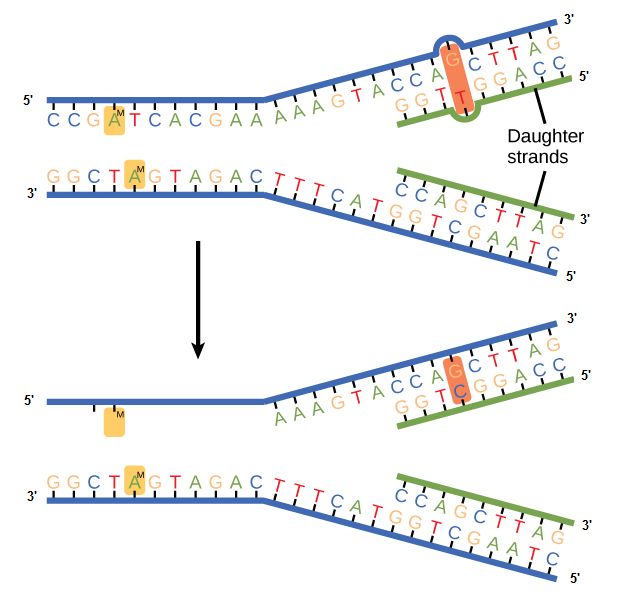
Figure 2. In mismatch repair, the incorrectly added base is detected after replication. The mismatch repair proteins detect this base and remove it from the newly synthesized strand by nuclease action. The gap is now filled with the correctly paired base.
Nucleotide excision repair
Nucleotide excision repair enzymes replace incorrect bases by making a cut on both the 3' and 5' ends of the incorrect base. The entire segment of DNA is removed and replaced with correctly paired nucleotides by the action of a DNA polymerase. Once the bases are filled in, the remaining gap is sealed with a phosphodiester linkage catalyzed by the enzyme DNA ligase. This repair mechanism is often employed when UV exposure causes the formation of pyrimidine dimers.
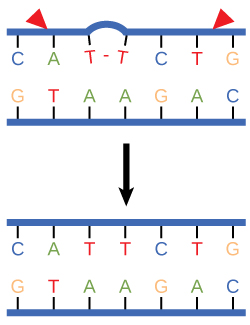
Figure 3. Nucleotide excision repairs thymine dimers. When exposed to UV, thymines lying adjacent to each other can form thymine dimers. In normal cells, they are excised and replaced.
Consequences of errors in replication, transcription, and translation
Something key to think about:
Cells have evolved a variety of ways to make sure DNA errors are both detected and corrected. We have already discussed several of them. But why did so many different mechanisms evolve? From proofreading by the various DNA-dependent DNA polymerases, to the complex repair systems. Such mechanisms did not evolve for errors in transcription or translation. If you are familiar with the processes of transcription and/or translation, think about what the consequences would be of an error in transcription. Would such an error affect the offspring? Would it be lethal to the cell? What about errors in translation? Ask the same questions about the process of translation. What would happen if the wrong amino acid is accidentally put into the growing polypeptide during translation? How do these contrast with DNA replication? If you are not familiar with transcription or translation, don't fret. We'll learn those soon and return to this question again.