
NB2.0-Test-Page
- Page ID
- 43295
Carbohydrates

Carbohydrates are one of the four main classes of macromolecules that make up all cells and are an essential part of our diet; grains, fruits, and vegetables are all natural sources. While we may be most familiar with the role carbohydrates play in nutrition, they also have a variety of other essential functions in humans, animals, plants, and bacteria. In this section, we will discuss and review basic concepts of carbohydrate structure and nomenclature, and a variety of functions they play in cells.
Molecular structures
In their simplest form, carbohydrates can be represented by the stoichiometric formula (CH2O
Nomenclature
One issue with carbohydrate chemistry is the nomenclature. Here are a few quick and simple rules:
- Simple carbohydrates, such as glucose, lactose, or dextrose, end with an "-ose."
Simple carbohydrates can be classified based on the number of carbon atoms in the molecule, as with triose (three carbons),pentose (five carbons), or hexose (six carbons).Simple carbohydrates can be classified based on the functional group found in the molecule,i.e ketose (contains a ketone) or aldose (contains an aldehyde).- Polysaccharides
are often organized by the number of sugar molecules in the chain, such as in a monosaccharide, disaccharide, or trisaccharide.
For a short video on carbohydrate classification, see the 10-minute Khan Academy video by clicking here.
Monosaccharides
Monosaccharides ("mono-" = one; "

Figure 1.
Glucose versus galactose
Galactose (part of
Fructose versus both glucose and galactose
In glucose and galactose, the carbonyl group is on the C1 carbon, forming an aldehyde group. In fructose, the carbonyl group is on the C2 carbon, forming a ketone group. The former sugars
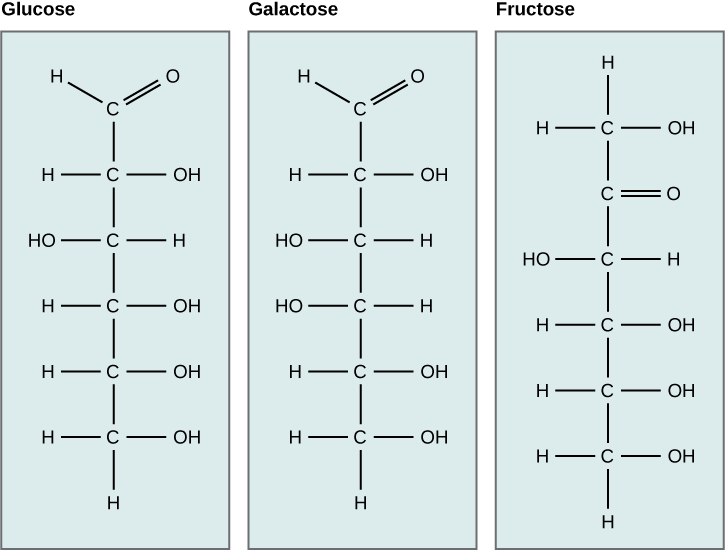
Figure 2. Glucose, galactose, and fructose are all hexoses. They are structural isomers, meaning they have the same chemical formula (C6H12O6) but a different arrangement of atoms.
Linear versus ring form of the monosaccharides
Monosaccharides can exist as a linear chain or as ring-shaped molecules. In aqueous solutions, monosaccharides are usually found in ring form (Figure 3). Glucose in a ring form can have two different arrangements of the hydroxyl group (OH) around the anomeric carbon (C1 that becomes asymmetric in the process of ring formation). If the hydroxyl group is below C1 in the sugar,
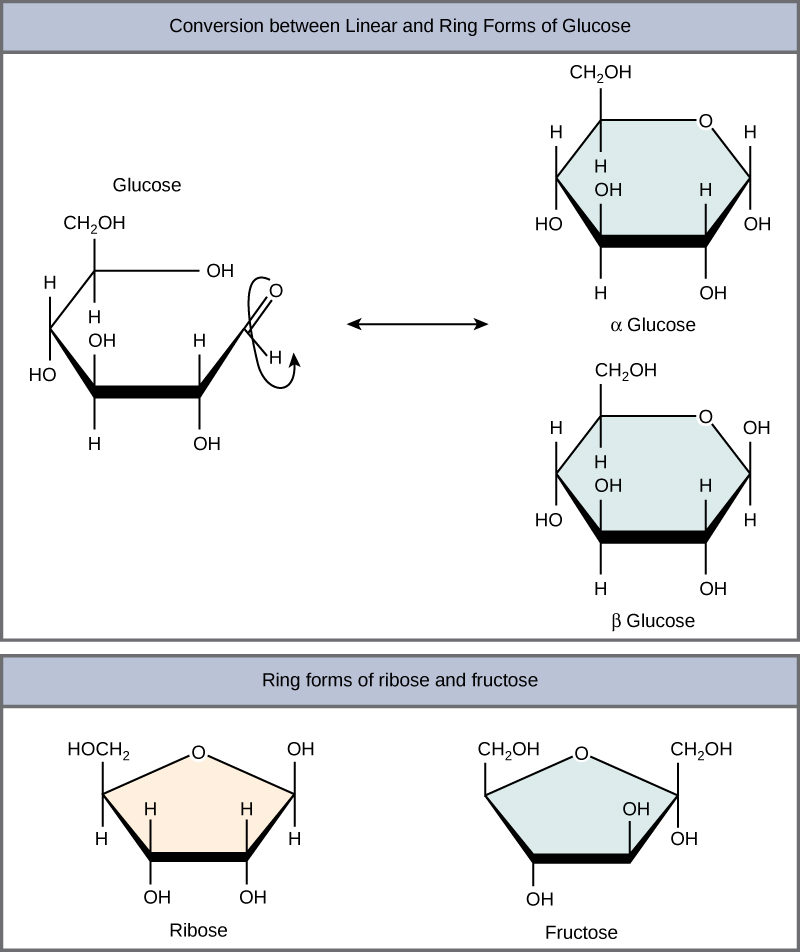
Figure 3. Five- and six-carbon monosaccharides exist in equilibrium between linear and ring form. When the ring forms, the side chain it closes on
Disaccharides
Disaccharides ("di-" = two) form when two monosaccharides undergo a dehydration reaction (also known as a condensation reaction or dehydration synthesis). During this process, the hydroxyl group of one monosaccharide combines with the hydrogen of another monosaccharide, releasing a molecule of water and forming a covalent bond. A covalent bond formed between a carbohydrate molecule and another molecule (in this case, between two monosaccharides) is known as a glycosidic bond. Glycosidic bonds (also called glycosidic linkages) can be of the alpha or the beta type.
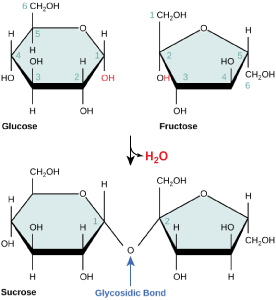
Figure 4. Sucrose
Common disaccharides include lactose, maltose, and sucrose (Figure 5). Lactose is a disaccharide
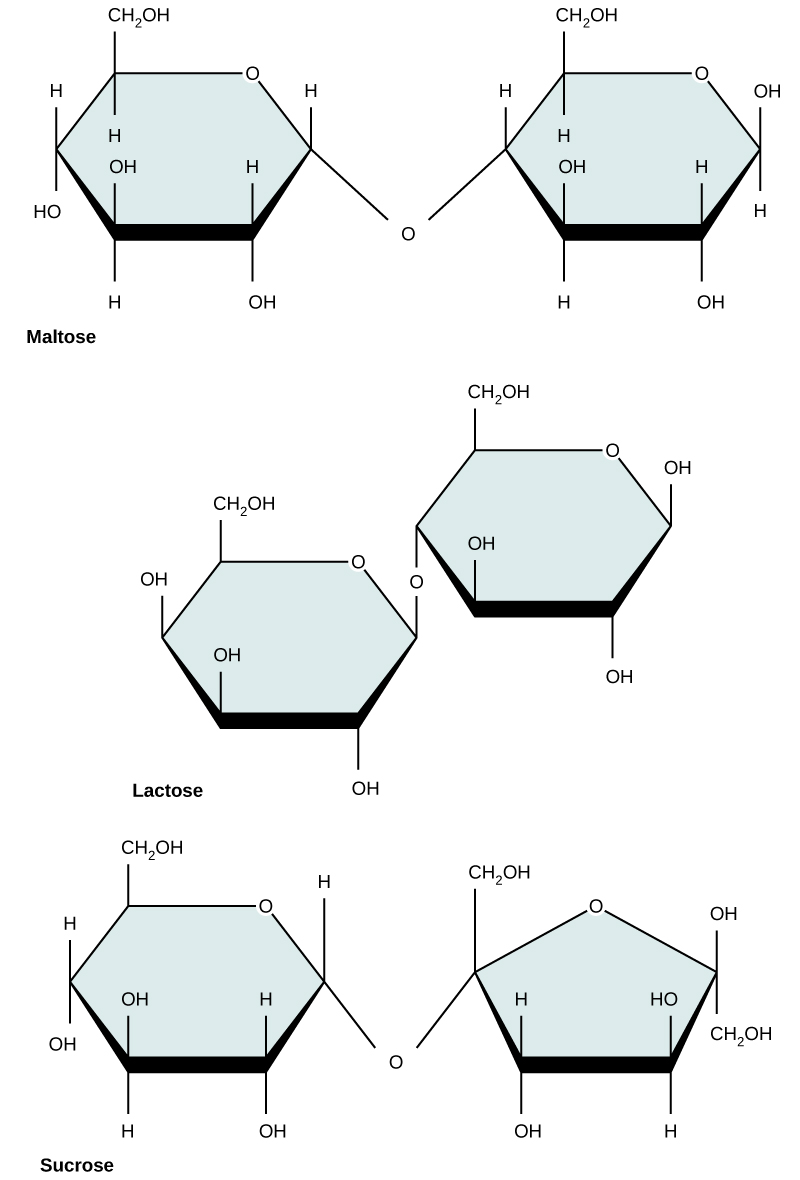
Figure 5. Common disaccharides include maltose (grain sugar), lactose (milk sugar), and sucrose (table sugar).
| Sucrose | Lactose | Maltose |
Polysaccharides
A long chain of monosaccharides linked by glycosidic bonds is known as a polysaccharide ("poly-" = many). The chain may
Starch is the stored form of
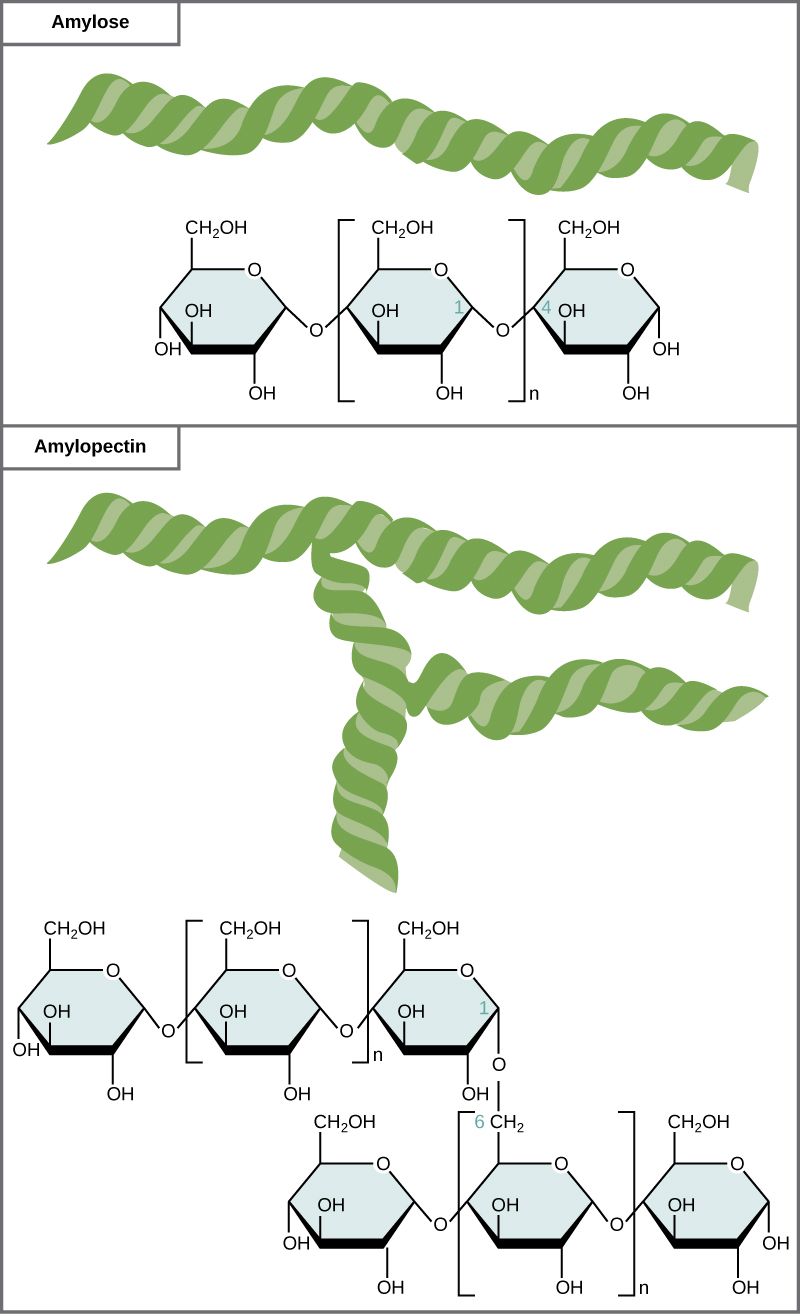
Figure 6. Amylose and amylopectin are two different
Glycogen
Glycogen is a common stored form of glucose in humans and other vertebrates. Glycogen is the animal equivalent of starch and is a highly branched molecule usually stored in liver and muscle cells. Whenever blood glucose levels decrease,
| Glycogen |
Cellulose
Cellulose is the most abundant natural biopolymer.
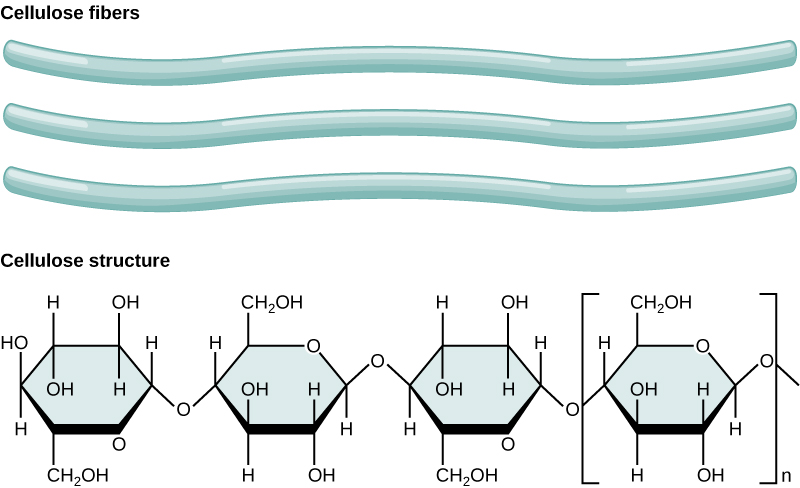
Figure 7. In cellulose,
Note:
Cellulose is not very soluble in water in its crystalline state;
As shown in the figure above, every other glucose monomer in cellulose
Interactions with carbohydrates
We have just discussed the various types and structures of carbohydrates found in biology. The next thing to address is how these compounds interact with other compounds. The answer to that is that it depends on the final structure of the carbohydrate. Because carbohydrates have many hydroxyl groups associated with the molecule, they are therefore excellent H-bond donors and acceptors. Monosaccharides can quickly and easily form H-bonds with water and are readily soluble. All of those H-bonds also make them quite "sticky". This is also true for many disaccharides and many short-chain polymers. Longer polymers may not be readily soluble.
Finally, the ability to form a variety of H-bonds allows polymers of carbohydrates or polysaccharides to form strong intramolecular and
The Role of Acid/Base Chemistry in General Biology

We have learned that the behavior of chemical functional groups depends on the composition, order, and properties of their constituent atoms. We will see that pH, a measure of the hydrogen ion concentration of the solution, can alter chemical properties of some key biological functional groups in ways that change how they interact with other molecules and thus their biological role.
For example, some functional groups on the amino acid molecules that make up proteins can exist in different chemical states depending on the pH. We will learn that the chemical state of these functional groups in the context of a protein can have a profound effect on the shape of the protein or on its ability to carry out chemical reactions. As we move through the course we will see many examples of this type of chemistry in different contexts.
While some paradoxes to this rule can be found in the chemistry of concentrated solutions, in General Biology it is convenient to formally define pH as:
|
\[ pH = -\log_{10} [H^+]\]
|
In the equation above, the square brackets surrounding [H+] indicate concentration. If necessary, try a math review at wiki-logarithm or kahn-logarithm. Also see: definition-concentration or wiki-concentration.
Hydrogen ions are spontaneously generated in pure water by the dissociation (ionization) of a small percentage of water molecules into equal numbers of hydrogen (H+) ions and hydroxide (OH-) ions. The OH- that result from the ionization of water departs into the sea of water molecules interacting with other molecules through polar interactions, while the now "free" (unbonded) H+ ions produced by the ionization associates with water molecules (line two of the figure below) to create a new molecule called a hydronium ion, H3O+. At some point the hydroxide ion from line 1 in the figure below will rejoin with a proton and reform another water molecule.
While most H+ ions in solution really exist as H3O+ ions, we usually represent the H3O+ in figures or equations more simply as H+. Why? Because it is easier. Just keep in mind, when you see H+ referred to in the text, figures, or in equations, it usually represents H3O+.
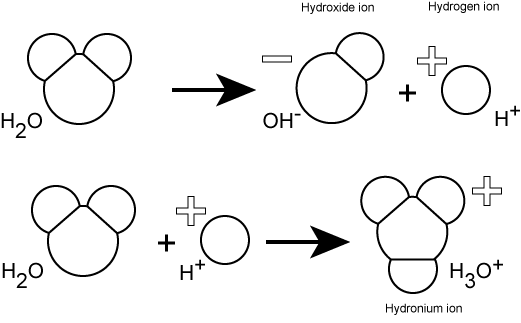
Figure 1: Water spontaneously dissociates into a proton and hydroxyl group. The proton will combine with a water molecule forming a hydronium ion.
Attribution: Marc T. Facciotti
The pH of a solution is a measure of the concentration of hydrogen ions in a solution (or the number of hydronium ions). The concentration of hydrogen ions determines how acidic or how basic a solution is.
The pH scale is logarithmic and ranges from 0 to 14 (Figure 2). We define pH=7.0 as neutral. We call anything with a pH below 7.0 acidic and any reported pH above 7.0 alkaline or basic. Extremes in pH in either direction from 7.0 are often considered inhospitable to life, although examples exist to the contrary. pH levels in the human body usually range between 6.8 and 7.4, except in the stomach where the pH is more acidic, typically between 1 and 2. Some microbial species like Sulfolobus acidocaldarius thrive in hyper acidic environments with pH < 3 while others like Natronomonas pharaonis have been found living in lakes with pH > 11. These organisms are classified as "extremophiles" for their abilities to thrive in extreme environments. Proteins from these organisms are sometimes used in industrial processes where their ability to withstand environmental stress is a valued property.
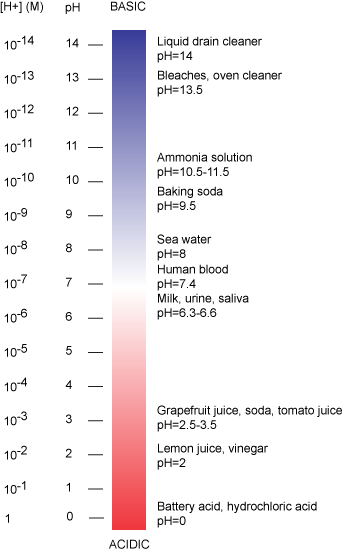
Figure 2: The pH scale ranging from acidic to basic with various biological compounds or substances that exist at that particular pH. Attribution: Marc T. Facciotti
For Additional Information
Watch this video for an expanded explanation of pH and its relationship to [H+] and the logarithmic scale.
Let's work out an example to see how the pH scale works.
For reference: 1 mole (mol) of a substance (which can be atoms, molecules, ions, etc.), is defined as being equal to 6.02 x 1023 particles of the substance. Therefore, 1 mole of water is equal to 6.02 x 1023 water molecules.
Mathematically this can be written as:
1 mol= 6.02x1023 particles in a substance
1 mol H2O= 6.02x1023 water molecules
Example: The concentration of hydrogen ions dissociating from pure water is approximately 1 × 10-7 moles H+ ions per liter of water. The pH is calculated as the negative of the base 10 logarithm of this unit of concentration. The log10 of 1×10-7 is -7.0, and the negative of this number yields a pH of 7.0, which is also known as neutral pH.
Mathematically this can be represented as:
pH= -log10[H+]
pH= -log10[1×10-7]
pH= 7.0 (neutral pH)
The figure below provides another way to visualize the difference between acidic and basic solutions. While this figure is not a completely accurate representation of relative amounts of H+ and OH- at all values of pH - H+ and OH- concentrations don't really go to zero solution - it nevertheless captures the inverse relationship between proton and hydroxide ion concentrations by graphically illustrating how proton concentration decreases as pH increases while the hydroxide ion concentration simultaneously increases.
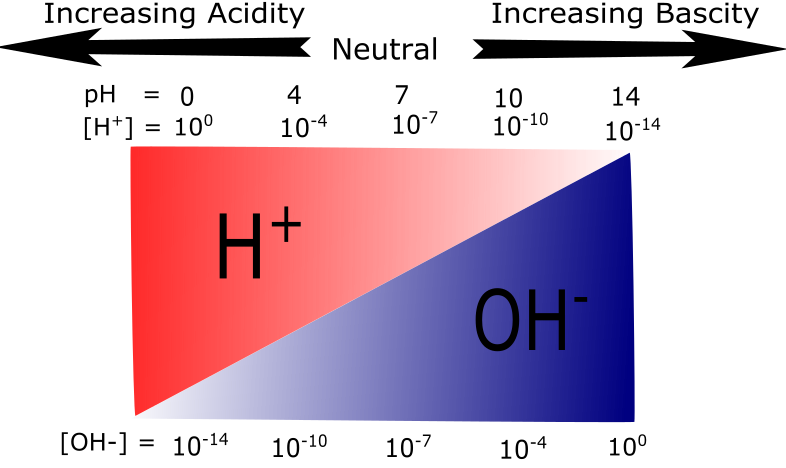
Figure 3: A graphical representation of acidity and basicity. This figure illustrates the relationship between H+ and OH- concentrations on the pH scale. At low pH values H+ ions are plentiful. As the pH increases the relative abundance of OH- ions increase while H+ abundance decreases.
Attribution: Mary O. Aina
This inverse relationship between pH and the concentration of protons confuses many students - take the time to convince yourself that you "get it." One way could be to predict whether different pH values are acidic or basic and then do the calculations to make sure. Start by trying these practice questions.
Knowledge Check Quiz
Acids and Bases
Acids and bases are molecules that can influence the pH of a solution. In General Biology it is often convenient to use the Brønsted-Lowry definition of acids and bases. Using this formalism we define:
Acids = molecules that can donate a proton to another molecule (including water to form a hydronium ion)
Bases = molecules that can accept a proton from another molecule
When protons from acidic molecules dissociate from their "parent" they increase the H+ concentration and thereby lower the pH of the solution. By contrast, when a base absorbs a "free" proton from a solution onto the "parent" molecule, the decrease in proton concentration in solution results in a shift to higher pH values.
Generically we can represent acids and bases as follows:
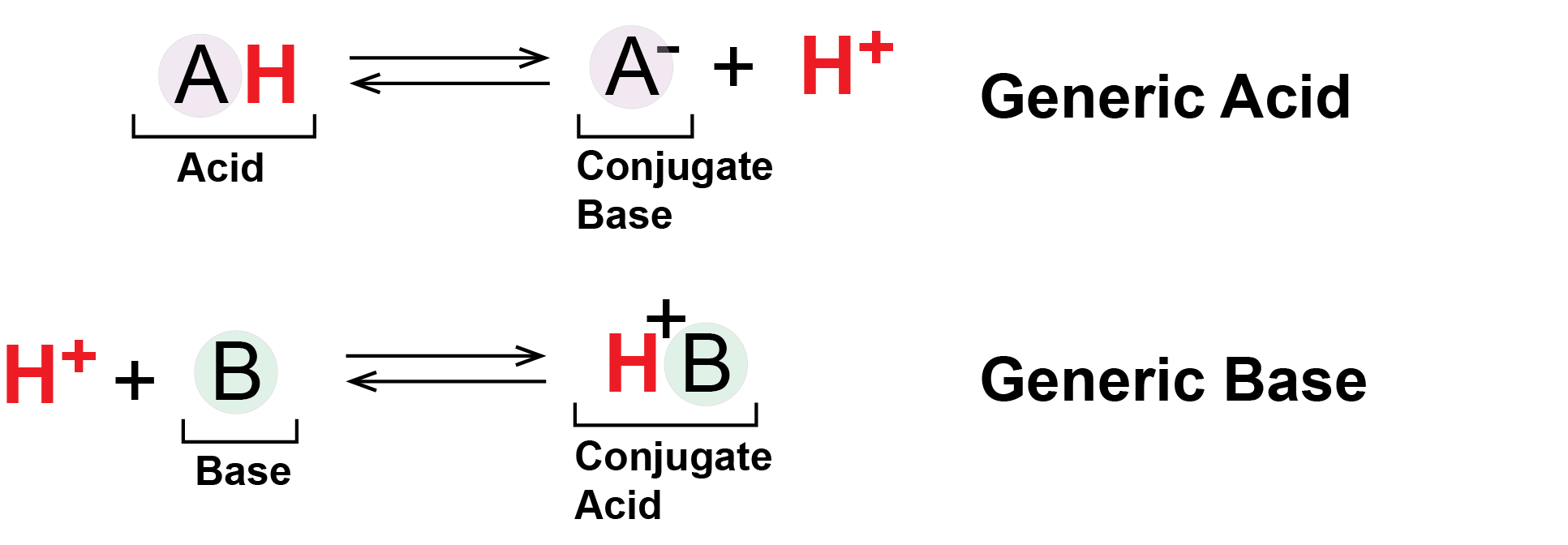
Figure 4: Generic Acids and Bases. This figure shows the behavior of Brønsted-Lowry acids and bases. The acid (A in a light purple circle) starts in a protonated form bound to an H+ ion, drawn as a red H. The acid deprotonates, shedding its H+ into solution or to another molecule. Meanwhile the base (B in a light green circle) begins deprotonated and absorbs a proton (red H+) from solution or other molecule.
Attribution: Marc T. Facciotti
In the figure above, the molecule A- - the deprotonated form of the acid AH - can also be referred to as the conjugate base of the acid AH. Likewise the molecule BH+ - the protonated form of the base B - can be referred to as the conjugate acid of the base B.
We call acids that completely dissociate into A- and H+ ions at equilibrium strong acids. These reactions are characterized by an equilibrium position that lies far to the right (favoring product formation) and their chemical equations are therefore often draw with a single arrow separating reactants and products. By contrast, acids that do NOT completely dissociate into A- and H+ ions at equilibrium are weak acids. Depending on the pH it is common to find both protonated and deprotonated forms of the acid (or both the acid and it's conjugate base) in solution at the same time. The chemical equations representing these reactions are therefore usually depicted with double arrows, indicating that the protonation/deprotonation of A-/AH, respectively, is reversible.
Two important examples of weak acids/bases in biology are the carboxyl and amino functional groups. At physiological pH values (around pH = 7) the carboxyl group tends to behave as an acid by donating it's proton to solution or other molecules. Under the same conditions, the amino group tends to act as a base, absorbing protons from solution or other molecules. As we will soon see, these and other protonation/deprotonation reactions are critically play key roles in many biological processes.
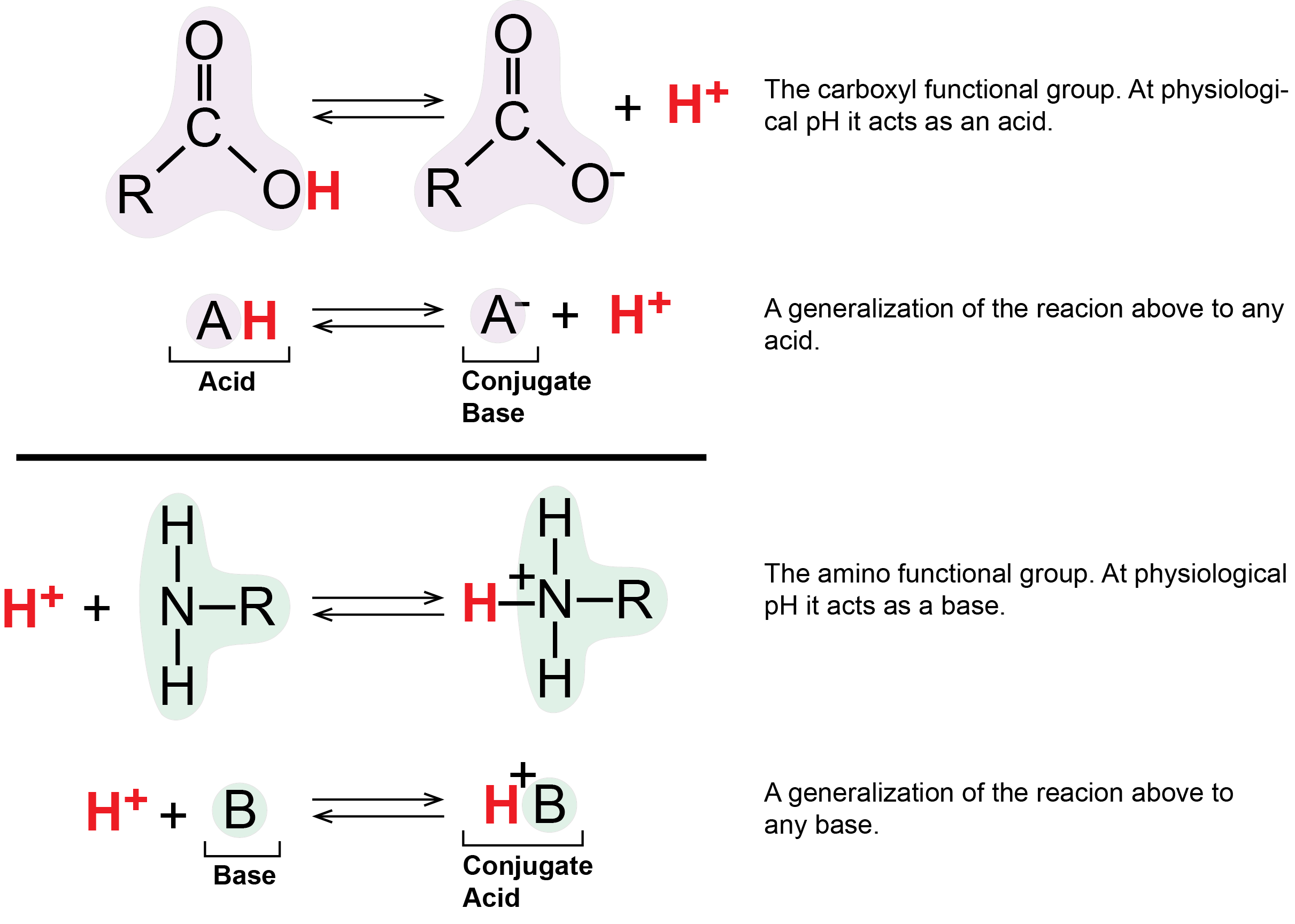
Figure 5: The carboxylic acid group acts as an acid by releasing a proton. This can increase the number of protons in solution and thus decrease the pH. The amino group acts as a base by accepting hydrogen ions, which can decrease the number of hydrogen ions in solutions, thus increasing the pH.
Attribution: Marc T. Facciotti (original work)
Additional pH resources
Here are some additional links on pH and pKa to help learn the material. Note that there is an additional module devoted to pKa.
ChemLibreText Links
- Determining and calculating pH
- pH and pKa
- This has an expanded discussion about pH that is a bit more detailed than how we present the concept.
Khan Academy Links
Simulations
- Acid-base simulation. -------
- ----------embed this in document---------