
11.4: Genetic Information
- Page ID
- 43672
The genetic information of an organism is stored in DNA molecules. How can one kind of molecule contain all the instructions for making complicated living beings like ourselves? What component or feature of DNA can contain this information? It has to come from the nitrogen bases, because, as you already know, the backbone of all DNA molecules is the same. But there are only four bases found in DNA: G, A, C, and T. The sequence of these four bases can provide all the instructions needed to build any living organism. It might be hard to imagine that 4 different “letters” can communicate so much information. But think about the English language, which can represent a huge amount of information using just 26 letters. Even more profound is the binary code used to write computer programs. This code contains only ones and zeros, and think of all the things your computer can do. The DNA alphabet can encode very complex instructions using just four letters, though the messages end up being really long. For example, the E. coli bacterium carries its genetic instructions in a DNA molecule that contains more than five million nucleotides. The human genome (all the DNA of an organism) consists of around three billion nucleotides divided up between 23 paired DNA molecules, or chromosomes.
The information stored in the order of bases is organized into genes: each gene contains information for making a functional product. The genetic information is first copied to another nucleic acid polymer, RNA (ribonucleic acid), preserving the order of the nucleotide bases. Genes that contain instructions for making proteins are converted to messenger RNA (mRNA). Some specialized genes contain instructions for making functional RNA molecules that don’t make proteins. These RNA molecules function by affecting cellular processes directly; for example some of these RNA molecules regulate the expression of mRNA. Other genes produce RNA molecules that are required for protein synthesis, transfer RNA (tRNA), and ribosomal RNA (rRNA).
In order for DNA to function effectively at storing information, two key processes are required. First, information stored in the DNA molecule must be copied, with minimal errors, every time a cell divides. This ensures that both daughter cells inherit the complete set of genetic information from the parent cell. Second, the information stored in the DNA molecule must be translated, or expressed. In order for the stored information to be useful, cells must be able to access the instructions for making specific proteins, so the correct proteins are made in the right place at the right time.
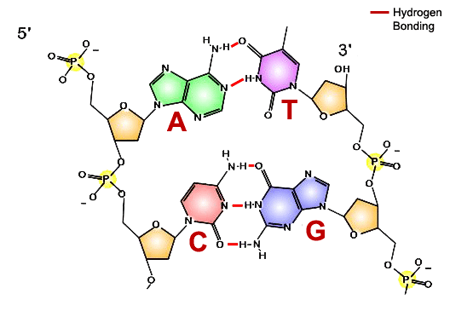
Both copying and reading the information stored in DNA relies on base pairing between two nucleic acid polymer strands. Recall that DNA structure is a double helix (see Figure 1).
The sugar deoxyribose with the phosphate group forms the scaffold or backbone of the molecule (highlighted in yellow in Figure 1). Bases point inward. Complementary bases form hydrogen bonds with each other within the double helix. See how the bigger bases (purines) pair with the smaller ones (pyrimidines). This keeps the width of the double helix constant. More specifically, A pairs with T and C pairs with G. As we discuss the function of DNA in subsequent sections, keep in mind that there is a chemical reason for specific pairing of bases.
To illustrate the connection between information in DNA and an observable characteristic of an organism, let’s consider a gene that provides the instructions for building the hormone insulin. Insulin is responsible for regulating blood sugar levels. The insulin gene contains instructions for assembling the protein insulin from individual amino acids. Changing the sequence of nucleotides in the DNA molecule can change the amino acids in the final protein, leading to protein malfunction. If insulin does not function correctly, it might be unable to bind to another protein (insulin receptor). On the organismal level of organization, this molecular event (change of DNA sequence) can lead to a disease state—in this case, diabetes.
Practice Questions
The order of nucleotides in a gene (in DNA) is the key to how information is stored. For example, consider these two words: stable and tables. Both words are built from the same letters (subunits), but the different order of these subunits results in very different meanings. In DNA, the information is stored in units of 3 letters. Use the following key to decode the encrypted message. This should help you to see how information can be stored in the linear order of nucleotides in DNA.
| ABC = a | DEF = d | GHI = e | JKL = f |
| MNO = h | PQR = i | STU = m | VWX = n |
| YZA = o | BCD = r | EFG = s | HIJ = t |
| KLM = w | NOP = j | QRS = p | TUV = y |
Encrypted Message: HIJMNOPQREFG – PQREFG – MNOYZAKLM – DEFVWXABC – EFGHIJYZABCDGHIEFG – PQRVWXJKLYZABCDSTUABCHIJPQRYZAVWX
[practice-area rows=”2″][/practice-area]
[reveal-answer q=”236947″]Show Answer[/reveal-answer]
[hidden-answer a=”236947″]This is how DNA stores information.
[/hidden-answer]
Where in the DNA is information stored?
- The shape of the DNA
- The sugar-phosphate backbone
- The sequence of bases
- The presence of two strands.
[reveal-answer q=”767717″]Show Answer[/reveal-answer]
[hidden-answer a=”767717″]Answer c. The sequence of the bases codes for the instructions for protein synthesis. The shape is DNA is not related to information storage. The sugar-phosphate backbone only acts as a scaffold. The presence of two strands is important for replication, but their information content is equivalent, as they are complementary to each other.
[/hidden-answer]
Which statement is correct?
- The sequence of DNA bases is arranged into chromosomes, most of which contain the instructions to build an amino acid.
- The sequence of DNA strands is arranged into chromosomes, most of which contain the instructions to build a protein.
- The sequence of DNA bases is arranged into genes, most of which contain the instructions to build a protein.
- The sequence of DNA phosphates is arranged into genes, most of which contain the instructions to build a cell.
[reveal-answer q=”363484″]Show Answer[/reveal-answer]
[hidden-answer a=”363484″]Answer c. The sequence of DNA bases is arranged into genes, most of which contain the instructions to build a protein. DNA stores information in the sequence of its bases. The information is grouped into genes. Protein is what is mainly coded.[/hidden-answer]
Contributors and Attributions
- Information Content of DNA. Provided by: Open Learning Initiative. Located at: https://oli.cmu.edu/jcourse/workbook/activity/page?context=434a5f7d80020ca600a650db8880db33. Project: Introduction to Biology (Open + Free). License: CC BY-NC-SA: Attribution-NonCommercial-ShareAlike