
1.5.2: Summarizing data--Descriptive statistics
- Page ID
- 75929
How do you summarize data?
Data is summarized in two main ways: summary calculations and summary visualizations
Calculations: What types of measures are used?
To be able to interpret patterns in the data, raw data must first be manipulated and summarized into two categories of measurements: Measures of central tendency and measures of variability. These two categories of measurements encapsulate the first step of scientific inquiry, descriptive statistics.
Measures of central tendency (center) – Provides information of how data cluster around some single middle value. While there are several ways to measure central tendency, the two measures most often used in Ecology are the mean and the median:
- Mean (average) – Sum of all individual values \(({\Sigma}x_{i})\) divided by total number of values in sample/population \({(n)}\). This is the most commonly used measure of central tendency under symmetrical (normal) distribution. It is sensitive to outliers. The sample mean is usually denoted \(\bar{x}\).
- Median – The middle value when the data set is ordered in sequential rank. This is commonly used when data is skewed and is resistant to outliers. Notice that if there is an even number of values, the median is calculated by adding the middle two values, and dividing by 2 :
for an odd number of values, ranked smallest to largest: 1, 3, 3, 6, 7, 8, 9. The median is 6.
for an even number of values, ranked smallest to largest: 1, 2, 3, 4, 5, 6, 7, 9. The median is \((4+5) \div 2 \ = 4.5\).
- Mode – The most frequently occurring value in the sample. This is less often used in Ecology.
Measures of variability (spread) – Describes how spread out or dispersed the data are. There are two main measures of spread used in biological inquiry:
- Range – Quantifies the distance between the largest and smallest data values.
- Standard deviation – Quantifies the variation or dispersion from the average of a dataset. A low standard deviation indicates that the data tends to be very close to the mean; a high standard deviation indicates that the data points are spread out over a large range of values. This calculation is sensitive to outliers. The standard deviation of a sample is denoted with a lower case s and is calculated as follows:
\[s=\sqrt{\frac{\left(x_{i}-\bar{x}\right)^{2}}{n-1}}\]
Notice that the numerator in the formula for the standard deviation includes the term \((x_{i}-\bar{x})\) which measures how far each individual value \((x_{i})\) is from the sample mean \(\bar{x}\). If the data are highly dispersed/variable, some of these values will be larger, and hence the standard deviation will be large.
- Standard error (SE) – Quantifies how different the sample mean (the average of the data values you have) is likely to be from the mean for the whole population mean (i.e., what you are trying to estimate). It tells you how much the sample mean would vary if you were to repeat a study using new samples from within a single population. The standard error is calculated by dividing the standard deviation by the square root of the sample size:
\[{SE}=\frac{s}{\sqrt{n}}\]
Visualizing the data: How are tables and graphs used?
After all desired descriptive statistics are calculated, they are typically visually summarized into either a table or graph.
Tables:
A table is a set of data values arranged into columns and rows. Typically the columns encompass a broad data category, and the rows encompass another. Within each broad category, there are subcategories that determine how many columns and rows the table consists of. Tables are used to both collect and summarize data. However, most of the time when tables are presented, they consist of summarized data, not raw data. Although tables allow summarized data to be presented in an orderly manner, most people prefer to translate tables into the more powerful data visualization tool, a graph.
Graphs:
A graph is a diagram showing the relation between variable quantities, typically of two variables, each measured along one of a pair of axes at right angles. Graphs can look like a chart or drawing. Most graphs use bars, lines, or parts of a circle to display data. However, there are sometimes when graphs are overlaid on top of maps to also display geographical location, or are even animated to be interactive.
Major graph type categories:
- Circle/Pie – A circular chart divided into slices to illustrate numerical proportion. In a pie chart, the arc length of each slice (and consequently its central angle and area), is proportional to the quantity it represents. While it is named for its resemblance to a pie that has been sliced, there are variations on the way it can be presented.
- Line – A type of chart which displays information as a series of data points called 'markers' connected by straight line segments. It is a basic type of chart common in many fields. It is similar to a scatter plot except that the measurement points are ordered in sequence (typically by their x-axis value) and joined with straight line segments. A line chart is often used to visualize a trend in data over intervals of time – a time series – thus the line is often drawn chronologically.
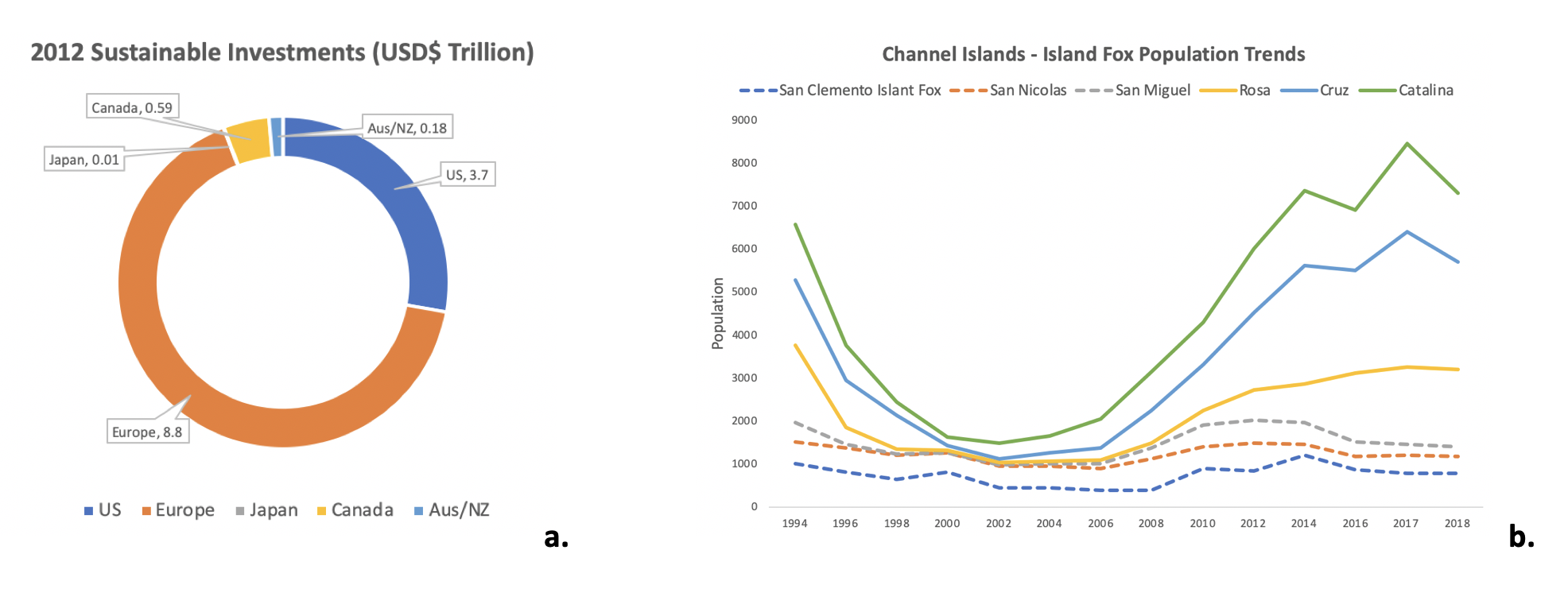
Figure \(\PageIndex{1}\): Examples of a circle/pie graph (a.) and a line graph (b.). Image created by Rachel Schleiger (CC-BY-NC).
- Scatter plot – Is a graph in which the values of two variables are plotted along the horizontal and vertical axes, the pattern of the resulting points revealing any correlation preset. The data are displayed as a collection of points, each having the value of one variable determining the position on the horizontal axis and the value of the other variable determining the position on the vertical axis.
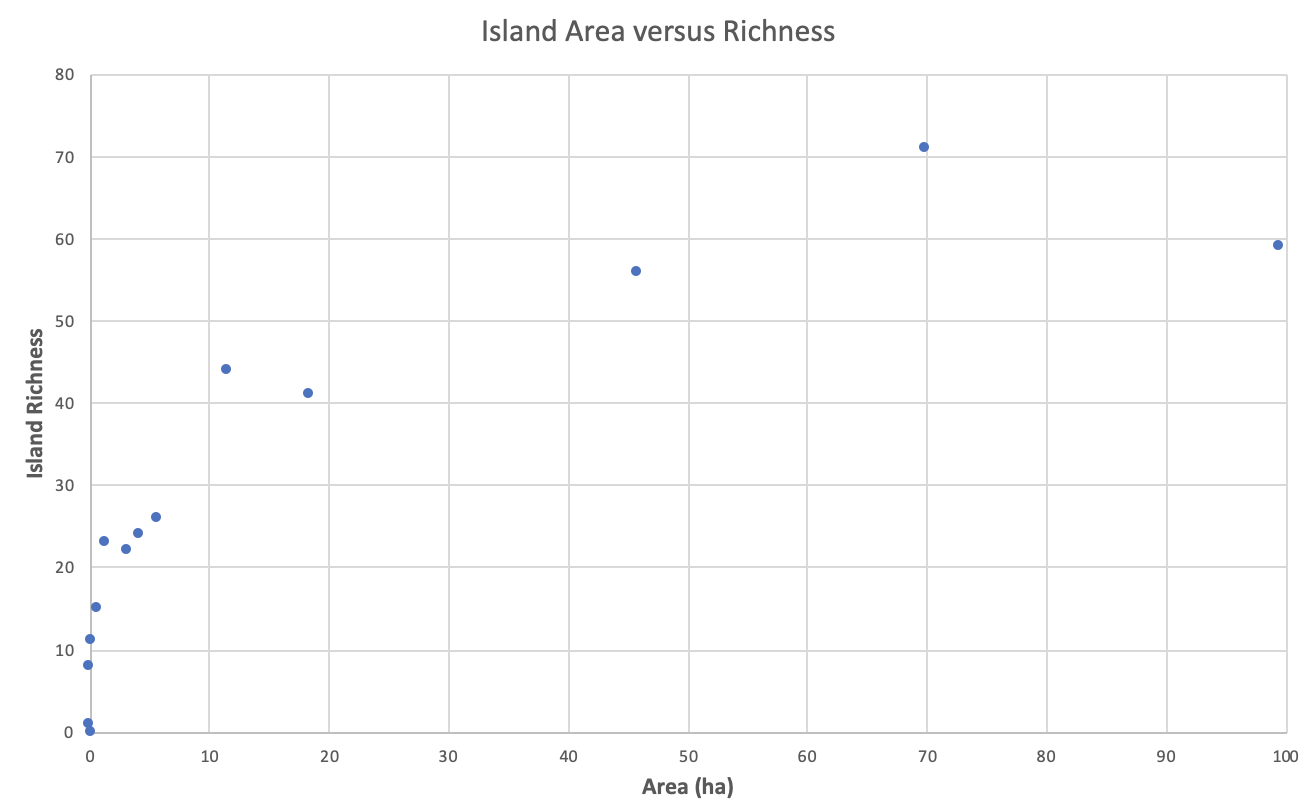
Figure \(\PageIndex{2}\): Example of a scatter plot. Image created by Rachel Schleiger (CC-BY-NC).
- Bar – A chart or graph that presents categorical data with rectangular bars with heights or lengths proportional to the values that they represent. The bars can be plotted vertically or horizontally.
- Histogram – Is an approximate representation of the distribution of numerical data. To construct a histogram, the first step is to "bin" (or "bucket") the range of values—that is, divide the entire range of values into a series of intervals—and then count how many values fall into each interval. The bins are usually specified as consecutive, non-overlapping intervals of a variable. The bins (intervals) must be adjacent (meaning there are not spaces between them like there are in bar graphs), and are often (but not required to be) of equal size. If the bins are of equal size, a rectangle is erected over the bin with height proportional to the frequency—the number of cases in each bin.
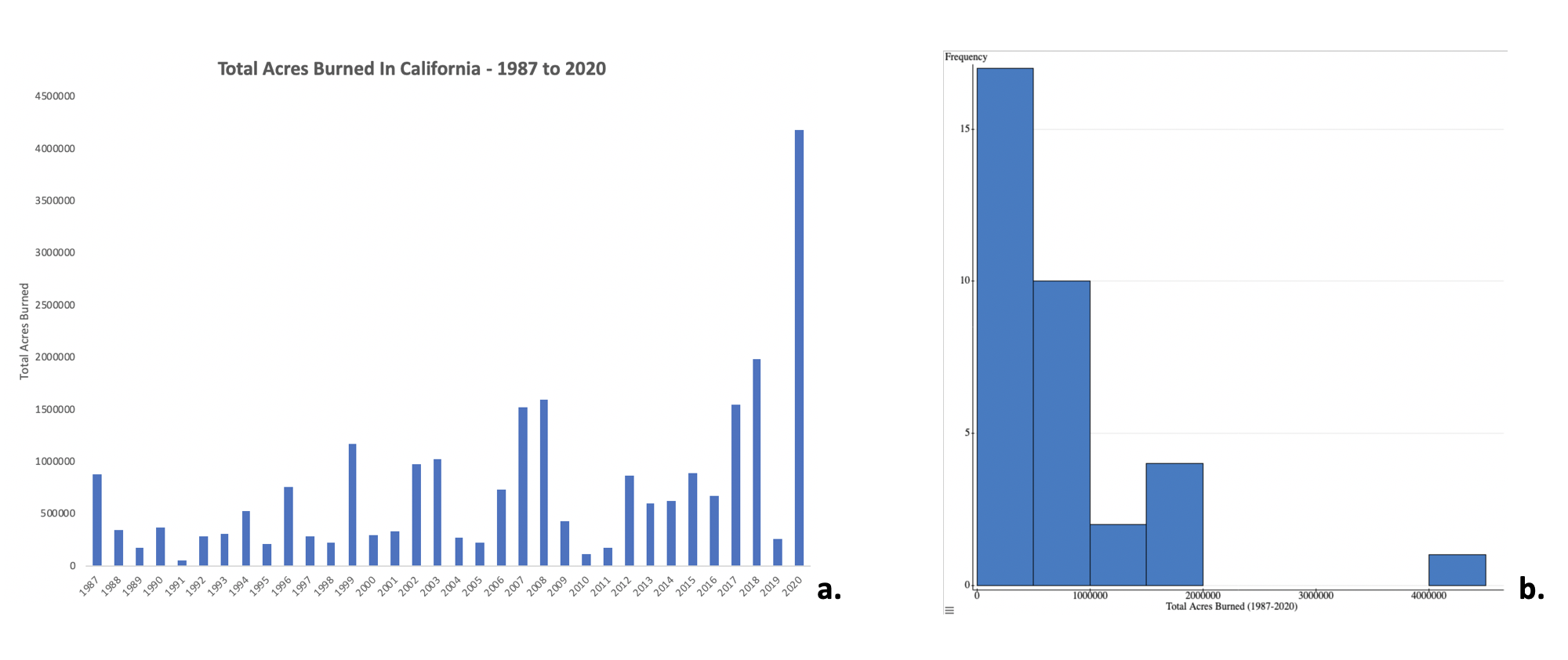
Figure \(\PageIndex{3}\): Examples of a bar graph (a.) and a histogram (b.) using the same dataset. Image created by Rachel Schleiger (CC-BY-NC).
Characteristics of effective graphical displays
The greatest value of a picture is when it forces us to notice what we never expected to see.
Professor Edward Tufte explained that users of information displays are executing particular analytical tasks such as making comparisons. The design principle of the information graphic should support the analytical task.[1] As William Cleveland and Robert McGill show, different graphical elements accomplish this more or less effectively. For example, dot plots and bar charts outperform pie charts.[12]
In his 1983 book The Visual Display of Quantitative Information, Edward Tufte defines 'graphical displays' and principles for effective graphical display in the following passage: "Excellence in statistical graphics consists of complex ideas communicated with clarity, precision, and efficiency. Graphical displays should:
- show the data
- induce the viewer to think about the substance rather than about methodology, graphic design, the technology of graphic production, or something else
- avoid distorting what the data has to say
- present many numbers in a small space
- make large data sets coherent
- encourage the eye to compare different pieces of data
- reveal the data at several levels of detail, from a broad overview to the fine structure
- serve a reasonably clear purpose: description, exploration, tabulation, or decoration
- be closely integrated with the statistical and verbal descriptions of a data set.
Graphics reveal data. Indeed graphics can be more precise and revealing than conventional statistical computations."[3]
- techatstate (7 August 2013). "Tech@State: Data Visualization - Keynote by Dr Edward Tufte". Archived from the original on 29 March 2017. Retrieved 29 November 2016 – via YouTube.
- leveland, W. S.; McGill, R. (1985). "Graphical perception and graphical methods for analyzing scientific data". Science. 229 (4716): 828–33. Bibcode:1985Sci...229..828C. doi:10.1126/science.229.4716.828. PMID 17777913. S2CID 16342041.
- Tufte, Edward (1983). The Visual Display of Quantitative Information. Cheshire, Connecticut: Graphics Press. ISBN 0-9613921-4-2. Archived from the original on 2013-01-14. Retrieved 2019-08-10.
Explore data visualizations at from data to viz.
Attribution
Rachel Schleiger (CC-BY-NC) and Data Visualization From Wikipedia, the free encyclopedia, modified by Andy Wilson.