
13.3: Eukaryotic Regulation of Translation
- Page ID
- 16494

A. The basics of Eukaryotic mRNA Translation
The basic features of translation initiation in eukaryotes are shown below.
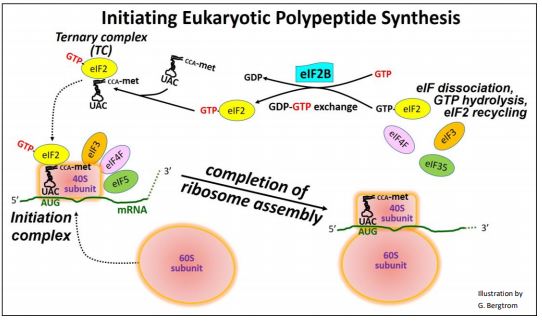
In many respects, the overall process is similar to prokaryotic translation initiation described elsewhere. The 40S ribosomal subunit itself can bind to and scan an mRNA, seeking the start site of an ORF (open reading frame) encoding a polypeptide. When GTP-bound eukaryotic initiation factor 2 (GTP-eIF2) binds met-tRNAf, it forms a ternary complex (TC). The TC can associate with the scanning 40S subunit. When a TC-associated scanning subunit encounters the start site of the ORF, scanning stalls. Additional eIFs enable formation of the initiation complex, positioning the initiator tRNA anticodon over the start site AUG in the mRNA. The initiation complex then recruits the large (60S) ribosomal subunit. Binding of the 60S ribosomal subunit to the initiation complex causes the release of all the eIFs and hydrolysis of the GTP on eIF2. The GDP remains bound to eIF2. For protein syntheses to continue, new GTP must replace GDP on eIF2. Another initiation factor, eIF2B, facilitates this GTP/GDP swap, recycling GTP-eIF2 for use in initiation. The regulation of translation is superimposed on these basic processes.
B. Translation Regulation
Since mRNAs are made to be translated, it is likely that by default, they are! We know that CAP and poly(A) tails on mRNAs are required for efficient translation because mRNAs engineered to lack one and/or the other are poorly translated. Also, there is little evidence to that cells modify the process of capping or polyadenylation, or the structures themselves.
Translation regulation typically targets initiation. It may be global, affecting the synthesis of many polypeptides at once, or specific, affecting a single polypeptide. Global regulation involves changes in the activity of eukaryotic initiation factors (eIFs) that would typically affect all cellular protein synthesis. Specific regulation involves binding sequences or regions on one or a few mRNAs that recognize and bind specific regulatory proteins and/or other molecules. That binding controls translation of only those mRNAs, without affecting general protein biosynthesis. mRNA structural features involved in translation and in translation regulation are illustrated below.
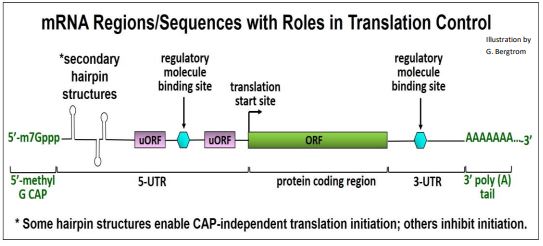
We will consider three examples of translational control of gene expression.
1. Specific Translation Control by mRNA Binding Proteins
Ferritin is a cellular iron-storage protein made up of heavy and light chain polypeptides. Translation of ferritin in iron-deficient cells is inhibited. In the absence of ferritin production, ferritin-iron complexes release iron for metabolic use. The 5’-UTR of mRNAs for both chains contain stem-loop binding sites that specifically recognize iron regulatory proteins (IRP1, IRP2). When ferritin mRNAs are bound to IRPs, translation initiation is blocked. The inhibition of ferritin translation by IRPs is illustrated below.
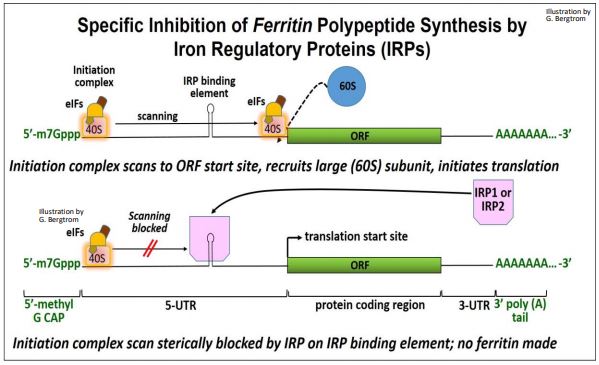
Normally, the initiation complex scans the 5’-UTR of an mRNA. When it finds the normal translation start site, it can bind the large subunit and begin translating the polypeptide. In iron-deficient cells, scanning by the initiation complex is thought to be physically blocked by steric hindrance.
2. Coordinating Heme & Globin Synthesis
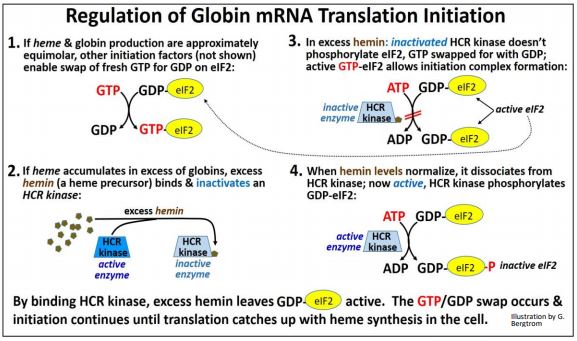
Consider that reticulocytes (the precursors to erythrocytes, the red blood cells in mammals) synthesize globin proteins. They also synthesize heme, an iron-bound porphyrin-ring molecule. Each globin must bind to a single heme to make a hemoglobin protein subunit. Clearly, it would not do for a reticulocyte to make too much globin protein and not enough heme, or vice versa. It turns out that hemin (a precursor to heme) regulates the initiation of translation of both \(\alpha \) and \(\beta \) globin mRNAs. Recall that, to sustain globin mRNA translation, the GDP-eIF2 generated after each cycle of translation elongation must be exchanged for fresh GTP. This is facilitated by the eIF2B initiation factor. eIF2B can exist in phosphorylated (inactive) or un-phosphorylated (active) states. Making sure that globin is not under- or overproduced relative to heme biosynthesis involves controlling levels of active vs. inactive eIF2B by hemin. Hemin accumulates when there is not enough globin polypeptide to combine with heme in the cell. Excess hemin binds and inactivates an HCR kinase, preventing phosphorylation of eIF2B. Since unphosphorylated eIF2B is active, it facilitates the GTP/GDP swap needed to allow continued translation. Thus, ongoing initiation ensures that globin mRNA translation can keep up with heme levels. In other words, if hemin production gets ahead of globin, it will promote more globin translation.
When globin and heme levels become approximately equimolar, hemin is no longer in excess. It then dissociates from the active HCR kinase. The now- active kinase catalyzes eIF2B phosphorylation. Phospho-eIF2B is inactive, and cannot facilitate the GTP/GDP swap on eIF2. Globin mRNA translation initiation, thus blocked, allows a lower rate of globin polypeptide translation to keep pace with heme synthesis. The regulation of globin mRNA translation initiation by hemin is shown below.
3. Translational Regulation of Yeast GCN4
Like the coordination of heme and globin production, the regulation of the GCN4 protein is based on controlling the ability of the cells to swap GTP for GDP on eIF2. However, this regulation is quite a bit more complex, despite the fact that yeast is a more primitive eukaryote! GCN4 is a global transcription factor that controls the transcription of as many as 30 genes in pathways for the synthesis of 19 out of the 20 amino acids! The discovery that amino acid starvation caused yeast cells to increase their production of amino acids in the cells led to the discovery the General Amino Acid Control (GAAC) mechanism involving GCN4. GCN is short for General Control Nondepressible, referring to its global, positive regulatory effects. It turns out that the GCN4 protein is also involved in stress gene expression, glycogen homeostasis, purine biosynthesis…, in fact in the action of up to 10% of all yeast genes! Here we focus on the GAAC mechanism.
Yeast cells provided with ample amino acids do not need to synthesize them. Under these conditions, GCN4 is present at basal (i.e., low) levels. When the cells are starved of amino acids, GCN4 levels increase as much as ten-fold within two hours, resulting in an increase in general amino acid synthesis. This rapid response occurs because amino acid starvation signals an increase in the activity of GCN2, a protein kinase. The GCN2 kinase catalyzes phosphorylation of GDPeIF2. As we have already seen, phosphorylated eIF2B cannot exchange GTP for GDP on the eIF2, in this case with the results shown below.

There is a paradox here. You would expect a slowdown in GTP-eIF2 regeneration to inhibit overall protein synthesis, and it does. However, the reduced levels of GTP-eIF2 somehow also stimulate translation of the GCN4 mRNA, leading to increased transcription of the amino acid synthesis genes. In other words, amino acid starvation leads yeast cells to use available substrates to make their own amino acids in order that protein synthesis can continue… at the same time as initiation complex formation is disabled!
Let’s accept that paradox for now, and look at how amino acid starvation leads to increased translation of the GCN4 protein and the up-regulation of amino acid biosynthesis pathways. To begin with, we are going to need to understand the structure of GCN4 mRNA. In the illustration below, note the 4 short uORFs in the 5’UTR of the RNA; these play a key role in GCN4 translation regulation.

We noted earlier that when a Ternary Complex (TC)-associated 40S ribosomal subunit scans an mRNAs and find the ORF start sites for its polypeptide, initiation complexes form, 60S ribosomal subunits bind and translation starts. GCN4 mRNA has four uORFs in its 5’ UTR. While uORFs encode only a few amino acids before encountering a stop codon, they can also be recognized during scanning. When TCs and 40S subunits are plentiful, they seem to engage uORFs in preference to the GCN4 coding region ORF, as illustrated below.
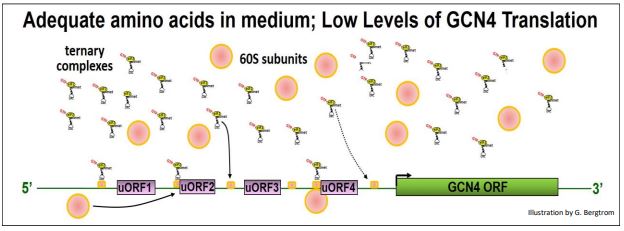
Under these conditions, active eIF2B allows the GTP/GDP swap on GDP-eIF2, leading to efficient GTP-eIF2 recycling and high TC levels. TCs bind small subunits during scanning and/or at the start sites of uORFs, forming initiation complexes that then bind 60S ribosomal subunits and begin uORF translation. The effect is to slow down scanning past the uORFs, thereby inhibiting initiation complex formation at the actual GCN4 ORF.
What happens in amino acid-starved cultures of yeast cells, when GTP-eIF2 cannot be efficiently regenerated and TCs are in short supply? To review, amino acid starvation signals an increase in GCN2 kinase activity resulting in phosphorylation and inactivation of eIF2B. Inactive phospho-eIF2 will not facilitate the GTP/GDP swap at GDP-eIF2, inhibiting overall protein synthesis. The resulting reduction in GTP-eIF2 also lowers the levels of TC and TC-associated 40S subunits. The illustration below shows how this phenomenon up-regulates GCN4 translation, even as the translation of other mRNAs has declined.

C. Regulating Protein Turnover (Half-Life)
We have already seen that organelles have a finite life span, or half-life. Recall that lysosomes participate in destroying worn out mitochondria and their molecular components. We also saw the role of small RNAs (especially miRNA) in destroying old, damaged or otherwise unwanted RNAs from cells. All cell structures and molecules have a finite half-life, defined as the time it takes for half of them to disappear in the absence of new synthesis of the structure or molecule. As we already know, the steady-state level of any cellular structure or molecule exists when the rate of its manufacture or synthesis is balanced by the rate of its turnover. Of course, steady state levels of things can change. For example, the level of gene expression (the amount of a final RNA or protein gene product in a cell) can change if rates of transcription, processing or turnover change. We should also expect the same for the steady-state levels of cellular proteins. Here we consider the factors that govern the half-life of cellular proteins.
The half-life of different proteins seems to be inherent in their structure. Thus, some amino acid side chains are more exposed at the surface of the protein and are thus more susceptible to change or damage over time than others. Proteins with fewer ‘vulnerable’ amino acids should have a longer half-life than those with more of them. Proteins damaged by errors of translation, folding, processing gone awry or just worn out from use or ‘old age’ will be targeted for destruction. All molecules have a half-life!
The mechanism for detecting and destroying unwanted old, damaged or misbegotten proteins involves a 76-amino acid polypeptide called ubiquitin that targets the protein for destruction, delivering it to a large complex of polypeptides called the proteasome. Here is what happens:
- The first step is to activate an ubiquitin. This starts when ATP hydrolysis fuels the binding of ubiquitin to an ubiquitin-activating enzyme.
- An ubiquitin-conjugating enzyme then replaces the ubiquitin-activation enzyme.
- The protein destined for destruction replaces the ubiquitin-conjugating enzyme.
- Several more ubiquitins then bind to this complex.
- The poly-ubiquinated protein delivers its protein to one of the 19S ‘CAP’ structures of a proteasome.
- After binding to one of the CAP structures of a proteasome, the poly-ubiquinated target proteins dissociate and the ubiquitins are released and recycled as the target protein unfolds (powered by ATP hydrolysis). The unfolded protein then enters a 20S core proteasome.
The target protein is digested to short peptide fragments by proteolytic enzymes in the interior of the proteasome core. The fragments are release from the CAP complex at the other end of the proteasome and digested down to free amino acids in the cytoplasm. There is a mind-boggling variety of proteins in a cell…, and there are as many as 600 different ubiquitin proteins, encoded by as many genes! Presumably, each ubiquitin handles a subclass of proteins based on common features of their structure.
With its complex quaternary structure, the 26S proteasome is smaller than a eukaryotic small ribosomal subunit (40S), but is still one of the largest cytoplasmic particles… and without the benefit of any RNA in its structure! The illustration on the next page details the role of ubiquitin in the degradation of a worn out protein by a proteasome. Click on Proteasome in Action to see an animated version of the illustration.
