
26.1: The Genetic Code
- Page ID
- 15201


Overview of Translation
Within this chapter, we will cover the details of prokaryotic and eukaryotic translation. Translation is the process of converting the information housed in mRNA into the protein sequence. Essentially, you are translating the language of nucleotides into the language of amino acids. Recall that prokaryotic and eukaryotic transcription and translation systems differ in large part due to the compartmentalization of larger eukaryotic cells. Due to this compartmentalization, transcription and translation are separated spatially and temporally within the cell. Transcription occurs within the nucleus of eukaryotes and translation occurs within the cytoplasm. Prokaryotes do not have compartmentalization and have, thus, evolved a coupled transcription/translation system where both processes occur simultaneously. Both are illustrated in Figure \(\PageIndex{1}\).
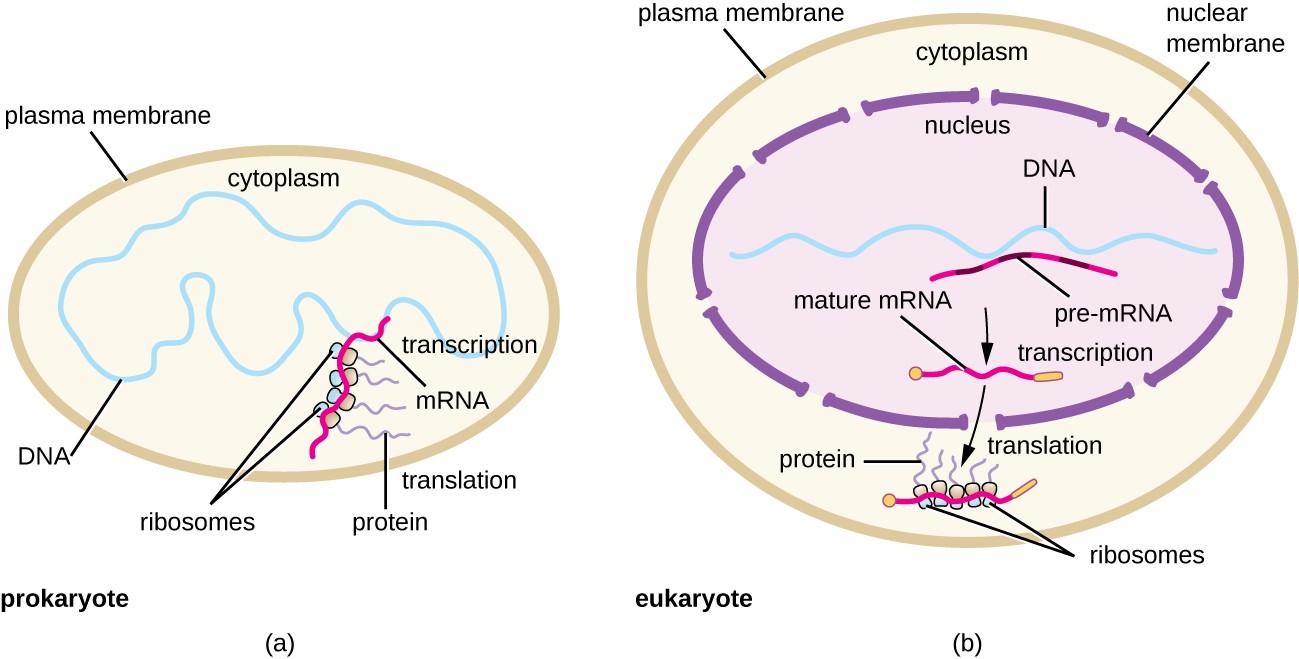
Panel (a) shows that prokaryotes lack cellular compartmentalization and show coupled transcription-translation processing;
Panel (b) shows that eukaryotes have a high degree of compartmentalization and separate the processes of transcription, which is in the nucleus of the cell, from the processes of translation, which is localized in the cytoplasm.
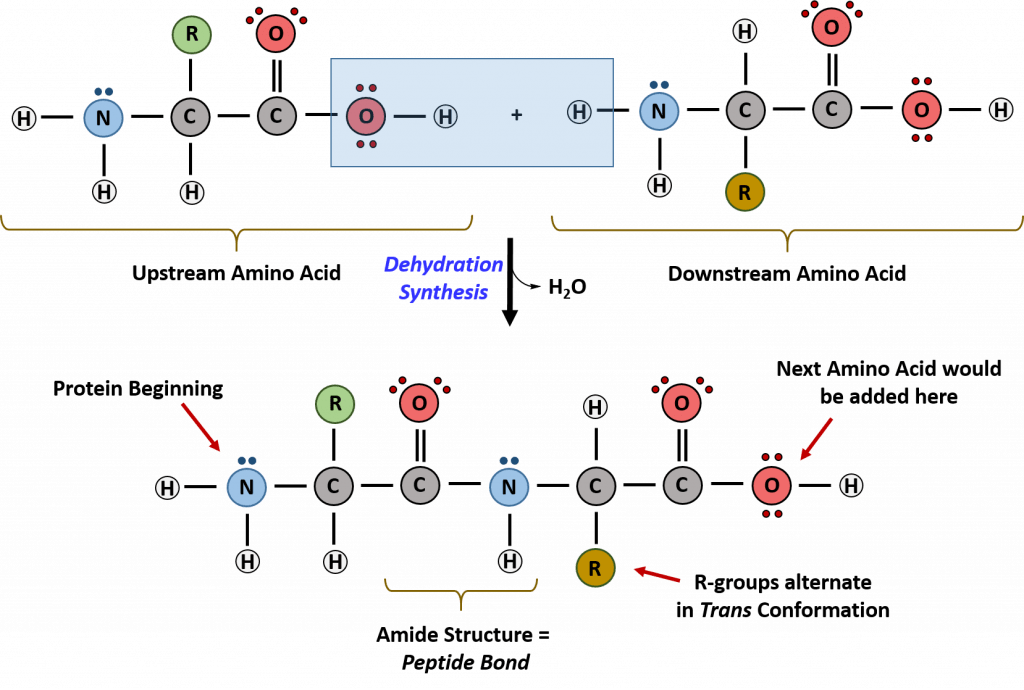
Recall that peptide formation is a dehydration reaction that combines the carboxylic acid of the upstream amino acid with the amine functional group of the downstream amino acid to form an amide linkage as shown in Figure \(\PageIndex{2}\). Water is the by-product. The ribosome (a large complex of peptides and rRNA molecules) serves as the enzyme that mediates this reaction. It requires a mature mRNA to serve as the template and directionally performs peptide bond synthesis from the N to the C-terminal of the growing peptide/protein. This is known as N- to C-synthesis. Note that the overall protonation state shown is very unlikely since under conditions when the carboxyl groups are protonated, so would the amines. This representation makes it easier to highlight the departing water
To maintain proper protein function, the error rate of translation is approximately 10-4 or 1 error in every 10,000 amino acids encoded. The fidelity of protein synthesis is maintained by the ribosome's ability to match the code from the template mRNA stand with the appropriate amino acid. Template mRNA is read by the ribosome in groups of three nucleotides, called a codon, as shown in Figure \(\PageIndex{3}\).
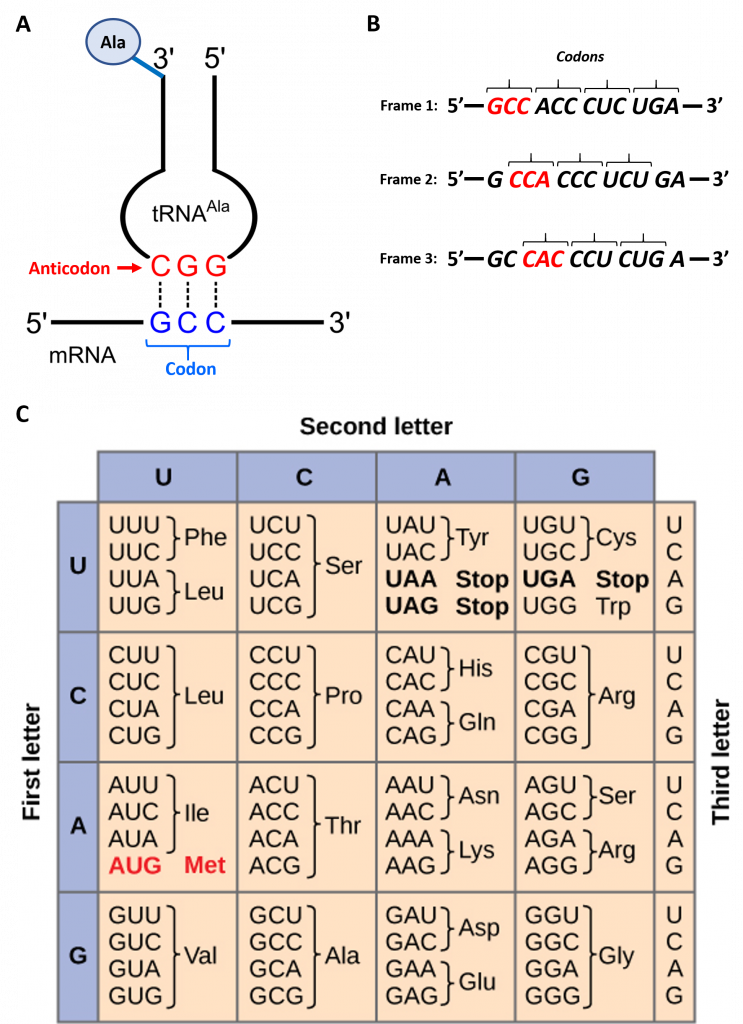
The template is non-overlapping and reads in discrete groups of three. This is known as the reading frame of the mRNA, and it is always read from the 5′ to 3′ direction. Thus, for each mRNA, there are three potential reading frames (panel B). Only one reading frame will be the correct one for protein synthesis. The ribosome must recognize and align the correct reading frame of the mRNA such that the correct codon sequences can be read. Small distinct tRNA molecules are tethered with specific amino acids and contain specific anticodons that complement mRNA codon sequences. The tRNA molecules can cycle on and off of the ribosome structure to hybridize with the correct codon sequences and chaperone the correct amino acid for peptide bond formation. The ribosome then serves as a ribozyme and mediates the peptidyl transferase activity to form the peptide bond. The mRNA is then shifted to reveal the next codon within the sequence and the process is repeated until the entire protein has formed. Panel C shows the codon chart for all of the possible combinations of three nucleotides. 64 possible codon combinations are possible using the 4 nucleotide possibilities, but only 20 amino acids are encoded during protein synthesis. Each codon is specific for a single amino acid. There is very little ambiguity within the code.
However, there is redundancy within the code; i.e. many amino acids have more than one codon that encodes for that specific amino acid. To account for this redundancy, many tRNA molecules can recognize more than one codon using a single anticodon. This is known as degeneracy. Degeneracy usually occurs at the third position of the codon and is known as the wobble base position. Degeneracy helps to minimize the effects of mutations within the coding sequence, as mutations in the wobble base position will often lead to silent mutation– ie the mutation will still encode for the same amino acid.
In addition, if comparing the polarity of amino acids encoded by the different codons, neighboring codons typically encode for amino acids with similar polarity, as shown in Figure \(\PageIndex{4}\). This also helps to minimize the effects of mutations, by converting one amino acid within the sequence to one that has similar polarity. This type of mutation is more likely to cause less disturbance to the 3-dimensional structure of the resulting protein and retain biological function.

Degeneracy within the genetic code also allows for differential A/T & G/C concentrations within species. For example, the G/C content of bacteria can range from as low as 30% to as high as 70%. Organisms living at high temperatures or extreme environments often have higher G/C content. This effectively increases the hydrogen bond strength between the strands of the DNA (G/C pairs have 3 H-bonds, whereas A/T pairs only have 2) and causes an increase in the melting temperature of the chromosome. Thus, the DNA is stable at a higher temperature or under more extreme ionic conditions, such as high salt. A more detailed discussion of how a single tRNA can function to recognize more than one codon is the topic of the next section.
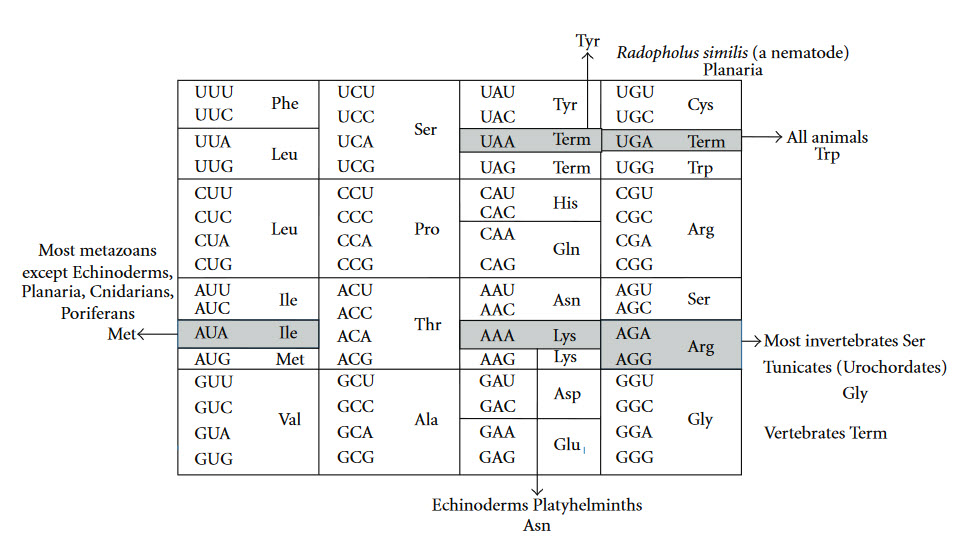
The Genetic Code is universal for almost all species alive on the planet, providing support for a single origin of life. Most deviations in the code occur within the mitochondria of eukaryotic species, as shown in Figure \(\PageIndex{5}\).
Transfer RNA (tRNA) Structure
Transfer RNAs (tRNAs) are central players in translation, functioning as adapter molecules between the informational level of nucleic acids and the functional level of proteins. Typically, tRNA molecules are between 76 – 90 nucleotides long and show a highly conserved secondary and tertiary structure. They also show the highest amount of nucleotide modification of all types of RNA with modifications concentrated in two hotspots—the anticodon loop and the tRNA core region, where the D- and T-loop interact with each other, stabilizing the overall structure of the molecule, as shown in Figure \(\PageIndex{6}\). These modifications can cause large rearrangements as well as local fine-tuning in the 3D structure of a tRNA.
The life of a transfer RNA (tRNA) molecule starts with a series of important maturation steps that can vary in their sequential order from case to case. Leader and trailer sequences are removed by a set of endo- and exonucleases, and in several tRNA precursors, splicing reactions excise intronic sequences. Furthermore, in many organisms, the sequence CCA, which represents the site of amino acid attachment, is not encoded but has to be added post-transcriptionally by CCA-adding enzymes. While all primary tRNA transcripts are composed of the four standard RNA bases A, C, G, and U, many of these nucleotides are modified, altering their properties in very different ways. Currently, 93 post-transcriptional modifications are known, and the variety of their functions is at least similarly diverse and not fully understood. The complexity of such modifications ranges from simple methylations at the bases or the ribose to rather complex and large base hypermodifications, whose synthesis often requires a whole cascade of enzymatic reactions. Modifications can alter a tRNA’s shape in subtle ways, but can also lead to massive structural rearrangements. In addition, they ensure efficient translation by maintaining the anticodon loop structure and promoting correct codon-anticodon interactions.
After maturation, tRNAs have multiple interaction partners in their life cycle, ranging from aminoacyl-tRNA-synthetases that are responsible for amino acid attachment, to translation factors, ribosomes, and mRNAs. Apart from synthetases, these interaction partners do not specifically act on one individual tRNA transcript or isoacceptor, but on all tRNAs, similar to the above-mentioned CCA-adding enzyme. Thus, despite a high sequence variation, a cell’s tRNAs show a well-conserved cloverleaf-like secondary structure that was originally discovered in 1965. The similar structure of all tRNA molecules allows them to bind to common protein synthesis machinery, such as the ribosome and CCA-adding enzymes. The cloverleaf consists of five parts: the acceptor stem (containing the tRNA’s 5′- and 3′-ends), the D-arm, the anticodon arm, the variable loop, and the TΨC-arm (T-arm). At the 3′-terminus, the tRNA carries the CCA sequence, required for aminoacylation, tRNA positioning in the ribosome, and translation termination. In a conserved network of tertiary interactions, mostly between D- and T-loop, tRNAs fold into an L-shaped three-dimensional structure, which was first solved by Kim et al. in 1974, as shown in Figure \(\PageIndex{6}\) (Panel B). The anticodon and the amino acid-accepting CCA-ends are separated by the longest possible distance from each other. This conserved structure of a tRNA is essential for its recognition by the ribosome, other RNAs, and proteins and, consequently, for its functionality. For example, the CCA-adding enzyme uses the acceptor domain for substrate recognition, whereas aminoacyl-tRNA-synthetases use several recognition elements like anticodon, acceptor stem, or the discriminator position.
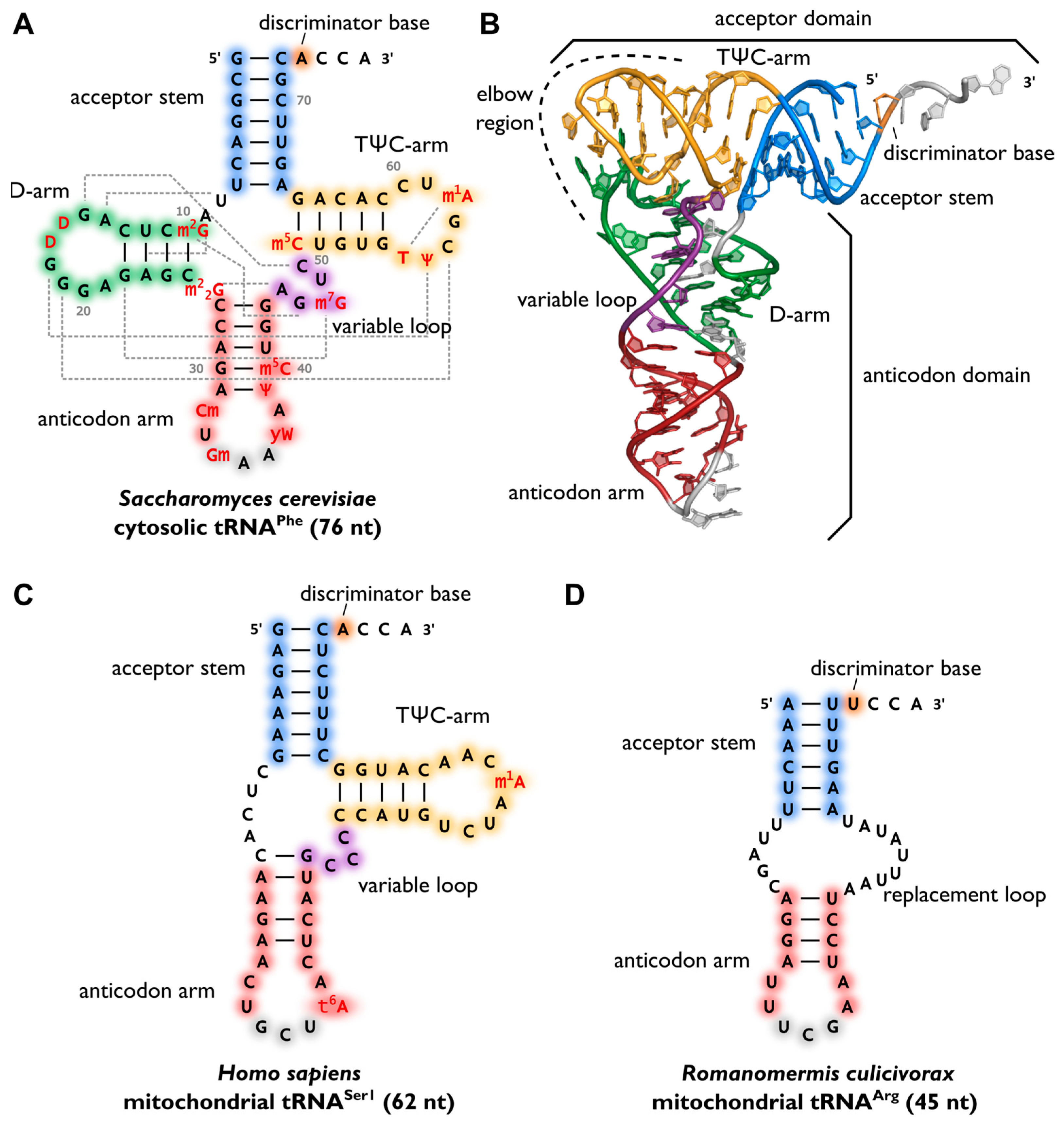
Panel (A) shows the canonical cloverleaf secondary structure of cytosolic tRNAPhe from S. cerevisiae is shown with acceptor stem (blue), D-arm (green), anticodon arm (red), variable loop (purple) and TΨC-arm (yellow). The anticodon is labeled in grey, the discriminator base in orange and post-transcriptional modifications in red. Grey dashed lines indicate tertiary interactions based on structural data and the length of the RNA is indicated in parenthesis;
Panel (B) shows the L-shaped tertiary structure of the cytosolic tRNAPhe from S. cerevisiae. Protein Data Bank entry (PDB): 1EHZ. The acceptor domain is composed of a stacked T-arm and acceptor stem, whereas D- and anticodon arm form the anticodon domain. The region where both domains come together and interact with each other via tertiary base pairing is also called the elbow region;
Panel(C) shows the secondary structure of human mitochondrial tRNASer1, which lacks the whole D-arm;
Panel (D) shows the secondary structure of the mitochondrial tRNAArg from the nematode Romanomermis culicivorax, which lacks both D- and T-arm. Instead, we find a so-called replacement loop. It represents the shortest tRNA found in vivo.
Surprisingly, not all tRNAs fold into the canonical cloverleaf structure. Especially many mitochondrial tRNAs are reduced in length and sometimes completely lack the D- or T-arm as shown in Figure \(\PageIndex{6}\), Panel C. In the mitochondria of nematodes, this situation is carried to an extreme, as tRNAs lacking one or even both arms seem to be the rule (Panel D).
Figure \(\PageIndex{7}\) shows an interactive iCn3D model of the yeast phenylalanine tRNA (1EHZ).
.png?revision=1&size=bestfit&width=329&height=334)
The coloring, which matches those in Figure 6 above, is shown below:
- Acceptor Stem - blue
- D Arm - green
- Anticodon= magenta
- Variable Loop - pink
- Tω C - yellow
Post-transcriptional enzyme-catalyzed modification of tRNA occurs at many base and sugar positions and influence specific anticodon–codon interactions and regulates translation, its efficiency, and fidelity. This phenomenon of nucleoside modification is most remarkable and results in a rich structural diversity of tRNA of which over 93 modifications have been characterized.
The variety of post-transcriptional modifications can be classified into two groups according to their complexity. The first group comprises the majority of modified bases, which have simple methylations at the ribose or base moiety that are usually introduced by a single enzymatic reaction. Simple modifications can be found at almost every position of the tRNA molecule with a high density in the tRNA core region, where tertiary interactions between D- and T-arm stabilize the three-dimensional fold, as shown in Figure \(\PageIndex{8}\). The second group includes complex modifications, whose synthesis requires the sequential activity of several enzymes. Most often these hypermodified nucleosides are found in the anticodon of tRNAs, where they play a direct role in codon recognition and create what is known as the wobble base or wobble position.
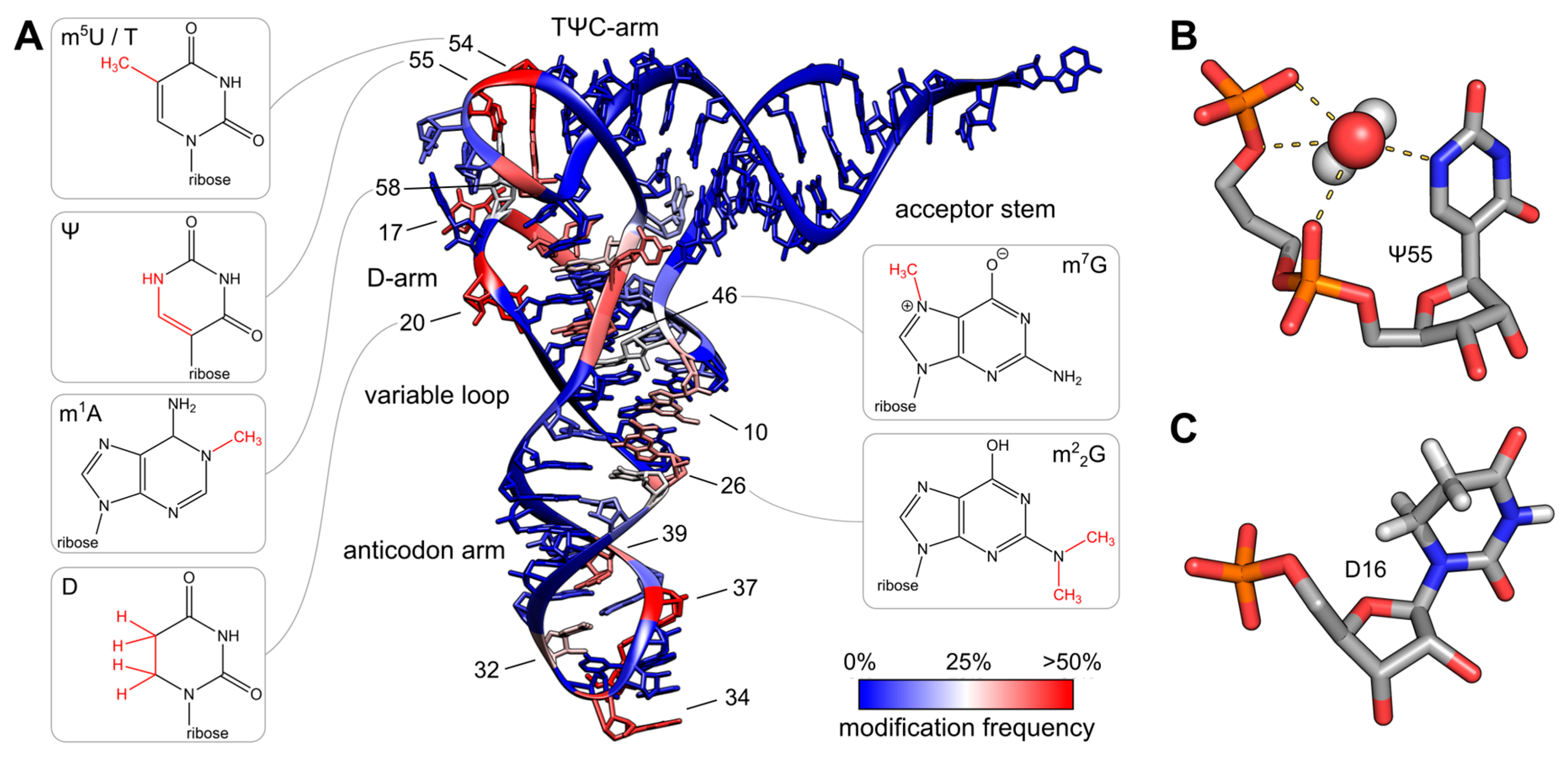
Panel (A) shows the colored tRNA structure shows the modification frequency of each base. The modification data were taken from the tRNAmodviz database and plotted on the crystal structure of tRNAPhe from S. cerevisiae. Blue-colored bases are rarely modified; red-colored bases are modification hotspots. tRNAs possess two regions with high modification levels—the anticodon loop (especially positions 34 and 37) and the core or elbow region, where D- and T-loop bases interact with each other and stabilize the tertiary fold. For some important positions, the chemical structure of the most frequent modification at this position is shown;
Panel (B) shows the three-dimensional structure of pseudouridine at position 55 of tRNAPhe from S. cerevisiae. The additional H-bond donor at N1 interacts with the 5′-adjacent phosphates via a coordinated water molecule. The hydrogen bound to N1 was not resolved in the crystal structure. The ribose shows a stabilizing C3′-endo conformation. PDB: 1EHZ-
Panel (C) shows the three-dimensional structure of D16 in the D-arm of tRNAiMet from Schizosaccharomyces pombe. The C5-C6 bond of dihydrouridine is reduced, which leads to a non-planar structure of the base. The ribose takes the less stable C2′ -endo conformation. PDB: 2MN0.
A wobble base pair is a pairing between two nucleotides in RNA molecules that does not follow Watson-Crick base pair rules. The four main wobble base pairs are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C), as shown in Figure \(\PageIndex{9}\). To maintain the consistency of nucleic acid nomenclature, “I” is used for hypoxanthine because hypoxanthine is the nucleobase of the inosine nucleotide; nomenclature otherwise follows the names of nucleobases and their corresponding nucleosides (e.g., “G” for both guanine and guanosine – as well as for deoxyguanosine). The thermodynamic stability of a wobble base pair is comparable to that of a Watson-Crick base pair. Wobble base pairs are fundamental in RNA secondary structure and are critical for the proper translation of the genetic code.

The wobble base position is usually the first position of the anticodon (read in the 5′ – 3′ direction), which aligns with the 3rd position of the mRNA codon. This helps to explain the degeneracy found within the genetic code as shown in Figure 3 above and Figure \(\PageIndex{10}\). Degeneracy means that a single tRNA can recognize multiple different codons within mRNA.
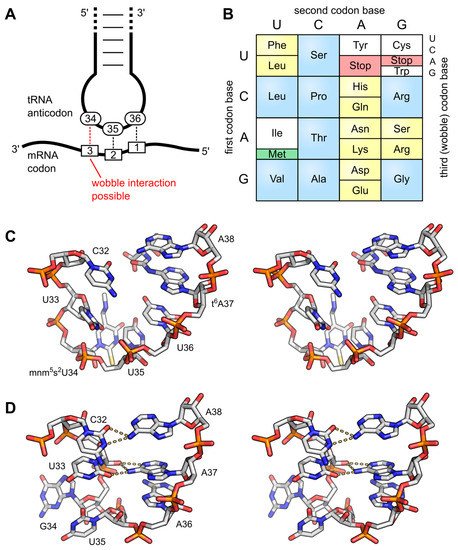
Panel (A) shows the interaction of the anticodon bases (34–36) of a tRNA with the corresponding bases of the mRNA codons (3, 2, 1). A wobble interaction is possible between codon base 3 and anticodon base 34. The latter is frequently modified and directs the wobble interactions with the third codon base;
Panel (B) shows the standard genetic code is illustrated as a simple decoding table, 2-fold degenerate codon boxes are colored yellow, and 4-fold degenerate boxes are blue. Start and stop codons are colored green and red, respectively;
Panel (C) shows a stereo image of the well-structured anticodon loop of tRNALys from E. coli. Modifications mnm5s2U34 and t6A37 prevent wrong base pairing inside the 7-nucleotide loop and promote the formation of the conserved U-turn motif. The stacked anticodon bases are located on the same side of the loop. PDB: 1FL8;
Panel (D) shows a stereo image of a collapsed and unmodified anticodon loop of tRNATyr from Bacillus subtilis. Here, bases 32 and 38 as well as 33 and 37 interact with each other and the U-turn motif is missing. The anticodon bases are not ordered and are on opposite sides of the loop. PDB: 2LAC.
A prominent example is tRNAIle carrying the anticodon UAU. In principle, this anticodon can read codons AUA (for isoleucine) and AUG (for methionine). Yet, it was shown in some instances that tRNAIle with unmodified UAU anticodon exists, but has a strong preference for its cognate AUA codon, while it rarely misreads AUG. In most organisms, however, tRNAIle carries the anticodon CUA. To avoid misreading of the methionine codon by this tRNA, C34 (position 1 of the anticodon) is modified to lysidine (k2C34, with the chemical structure shown in Figure 27.1.10, which restricts codon recognition to only AUA and thereby changes the amino acid identity of the tRNA from methionine to isoleucine. In the archaeal species, Haloarcula marismortui, Methanococcus maripaludis, and Sulfolobus solfataricus, this tRNAIle carries a different modification at C34, fulfilling the same purpose of restricting the interaction to AUA codons. Here, the original cytosine is modified at the C2-oxo position, which is replaced by agmatine (decarboxy-arginine), resulting in agmatidine (C+ or agm2C), as shown in Figure \(\PageIndex{11}\). A complimentary modification is that of N4-acetylcytosine (ac4C34, whose chemical structure is shown in Figure 27.1.8) in the elongator-tRNAMet of E. coli, which prevents the recognition of the AUA isoleucine codon. In non-plant mitochondria, however, both AUG and AUA codons are read as methionine. Hence, mitochondrial tRNAMet (carrying the anticodon CAU) has to recognize both codon forms. This is achieved by the introduction of 5-formylcytidine (f5C, Figure 11, at position 34, a modification that pairs with both A and U residues at the corresponding codon position 3.
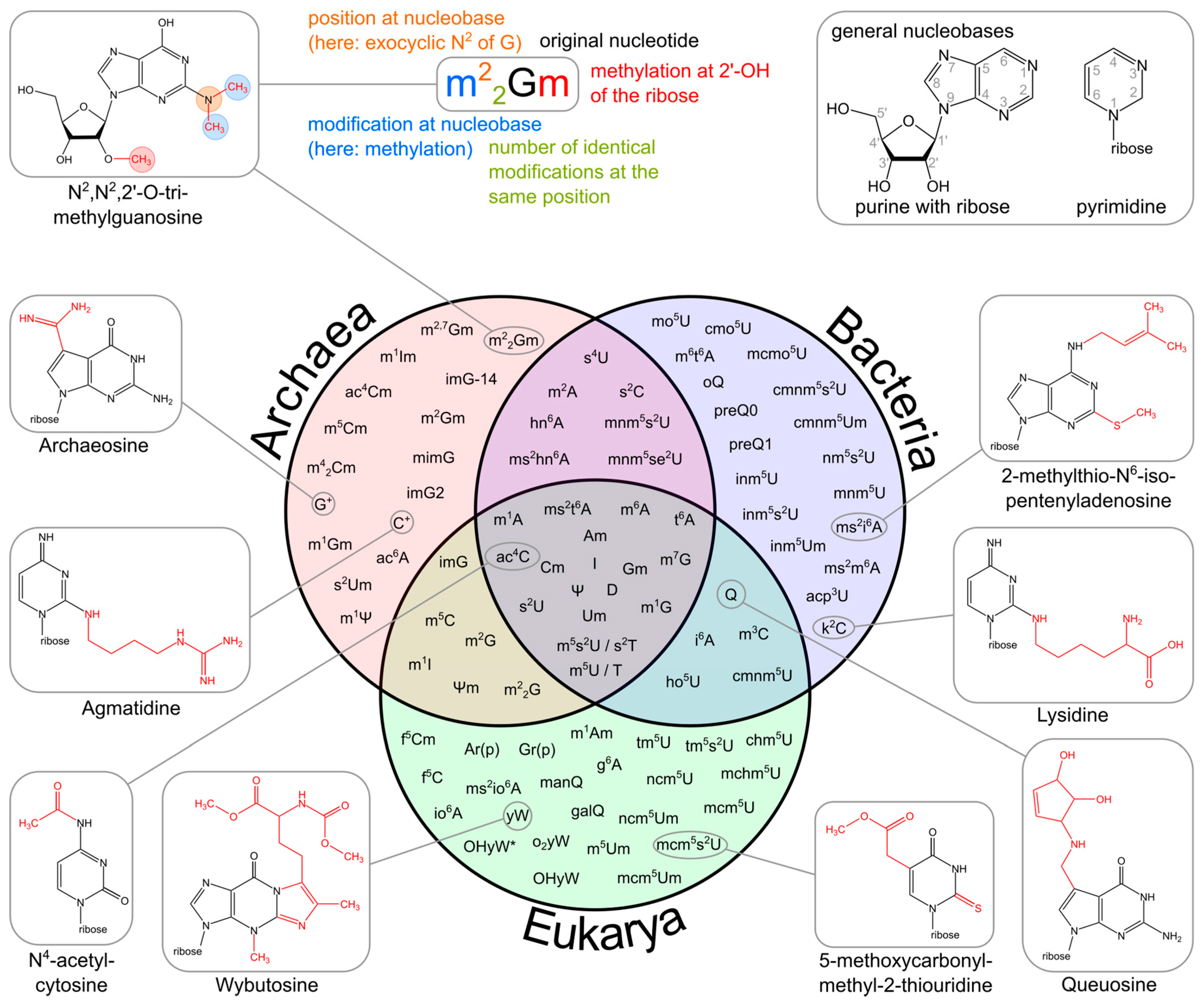
The upper part of the image illustrates the systematic abbreviation of RNA modifications with N2,N2,2′-O-trimethylguanosine (m22Gm) as an example and also shows the atom numbering in the purine and pyrimidine rings as well as in the ribose. An abbreviation in front of the base letter describes a base modification, whereas letters after the base stand for ribose alterations. Superscripted numbers specify the position at the base and subscripted numbers indicate the frequency of identical modification at the same position. Abbreviations are as follows: ac—acetyl, acp—aminocarboxypropyl, chm—carboxyhydroxymethyl, cmo—oxyacetic acid, cmnm—carboxymethylaminomethyl, f—formyl, g—glycinyl, gal—galactosyl, hn—hydroxynorvalylcarbamoyl, ho—hydroxy, i—isopentenyl, inm—isopentenylaminomethyl, io—cis-hydroxyisopentenyl, m—methyl, man—mannosyl, mchm—carboxyhydroxymethyl methyl ester, mcm—methoxycarbonylmethyl, mcmo—oxyacetic acid methyl ester, mnm—methylaminomethyl, mo—methoxy, ncm—carbamoylmethyl, nm—aminomethyl, r(p) —5-O-phosphono-b-d-ribofuranosyl, s—thio, se—seleno, t—threonylcarbamoyl, tm—taurinomethyl. The Venn diagram summarizes data collected from the RNA modification database and contains the 93 post-transcriptional modifications that are found in tRNAs. Some examples mentioned throughout the text are shown with their chemical structure.
Organisms vary in the number of tRNA genes in their genome. For example, the nematode worm C. elegans, a commonly used model organism in genetics studies, has 29,647 genes in its nuclear genome, of which 620 code for tRNA.The budding yeast Saccharomyces cerevisiae has 275 tRNA genes in its genome.
The human genome has approximately 20,848 protein-coding genes, of which there are 497 nuclear genes encoding cytoplasmic tRNA molecules, and 324 tRNA-derived pseudogenes (tRNA genes thought to be no longer functional). Regions in nuclear chromosomes, very similar in sequence to mitochondrial tRNA genes, have also been identified (tRNA-lookalikes). These tRNA-lookalikes are also considered part of the nuclear mitochondrial DNA (genes transferred from the mitochondria to the nucleus).
As with all eukaryotes, there are 22 mitochondrial tRNA genes in humans. Mutations in some of these genes have been associated with severe diseases like the MELAS syndrome.
Cytoplasmic tRNA genes can be grouped into 49 families according to their anticodon features. These genes are found on all chromosomes, except the 22 and the Y chromosomes. High clustering on 6p is observed (140 tRNA genes), as well as on chromosome 1. Currently, it is unclear why there is so much redundancy within the genome to decode 61 of the 64 possible codons (the other three are stop codons used to terminate translation).
Aminoacyl tRNA Synthetases
Aminoacyl-tRNA synthetases (aaRSs) are universally distributed enzymes that catalyze the esterification of a tRNA to its cognate amino acid (i.e., the amino acid corresponding to the anticodon triplet of the tRNA according to the genetic code). The product of this reaction, an aminoacyl-tRNA (aa-tRNA), is delivered by elongation factors to the ribosome to take part in protein synthesis.
Aminoacyl-tRNA synthetases are named after the aminoacyl-tRNA product generated, as such, methionyl-tRNA synthetase (abbreviated as MetRS) charges tRNAMet with methionine. In eukaryotes, an alternative nomenclature is often employed using the one-letter code of the amino acid (MARS), and a number is added to refer to the cytosolic (MARS1) or the mitochondrial (MARS2) variants. A total of 23 aaRSs have been described so far, one for each of the 20 proteinogenic amino acids (except for lysine, for which there are two) plus pyrrolysyl-tRNA synthetase (PylRS) and phosphoseryl-tRNA synthetase (SepRS), enzymes with a more restricted distribution that are only found in some bacterial and archaeal genomes. It is also worth noting that in eukaryotes the protein synthesis machinery of mitochondria and chloroplasts generally utilize their own, bacterial-like sets of synthetases and tRNAs that are distinct from their cytosolic counterparts.
The aminoacyl-tRNA synthetases catalyze a two-step reaction that leads to the esterification of an amino acid to the 3’ end of a tRNA along with the hydrolysis of one molecule of ATP, yielding aminoacyl-tRNA, AMP, and PPi. In the first step, termed amino acid activation, both the amino acid and ATP bind to the catalytic site of the enzyme, triggering a nucleophilic attack of the α-carboxylate oxygen of the amino acid to the α-phosphate group of the ATP, condensing into aminoacyl-adenylate (aa-AMP), which remains bound to the enzyme, and PPi, which is expelled from the active site, as shown in Figure \(\PageIndex{12}\).
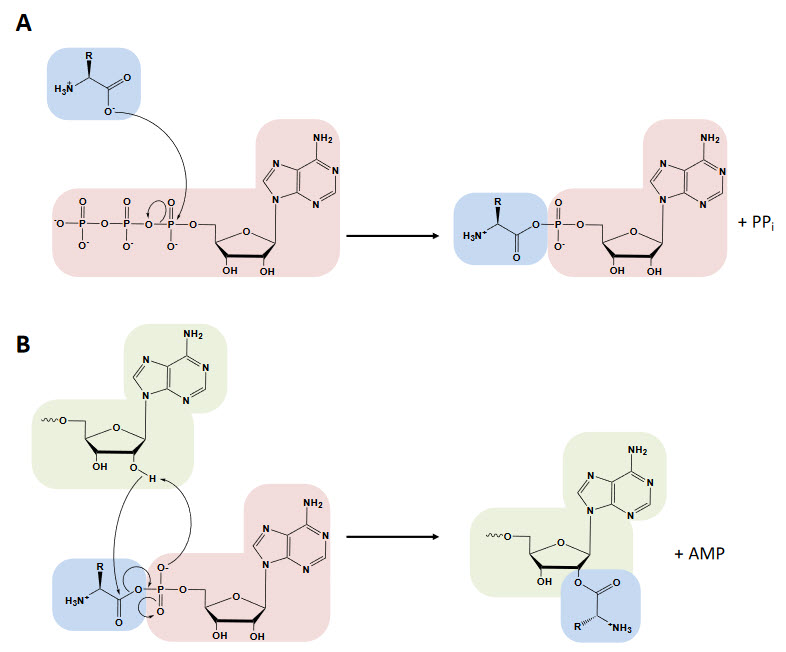
Although tRNA is usually not required for this first step, certain synthetases do require the tRNA species for productive amino acid activation. In the second part of the reaction, either the 2′- or 3′-hydroxyl group of the terminal adenine nucleotide attacks the carbonyl carbon of the adenylate, forming aminoacyl-tRNA and AMP (Figure 27.1.12 B). While the two-step aminoacylation reaction is universally conserved, the aaRSs that catalyze it show extensive structural, and in some instances functional, diversity.
The 23 known aaRSs can be divided into two major classes based on the architecture of their active sites (Class I and Class II). In class I synthetases, the catalytic domain bears a dinucleotide or Rossman fold (RF) featuring a five-stranded parallel β-sheet connected by α-helices and is usually located at or near the N-terminus of the protein. This RF contains the highly conserved motifs HIGH and KMSKS, separated by a connecting domain termed connective peptide 1 (CP1), as shown in Figure \(\PageIndex{13}\) (panel A). Class II active site architecture is organized as seven-stranded β-sheets flanked by α-helices and features three motifs that show a lesser degree of conservation than those in class I (panel B). Both classes also exhibit pronounced differences in their modes of substrate binding. Class I aaRSs bind the minor groove of the tRNA acceptor stem (with the exceptions of TrpRS and TyrRS) and aminoacylate the 2’-OH of the ribose of the terminal adenosine, while class II approach tRNA from the major groove and transfer amino acid to the 3’-OH (except PheRS). The mode of ATP binding is also different between both classes, being bound in an extended configuration in class I, while class II binds a bent configuration with the γ-phosphate folding back over the adenine ring. The kinetics of the aminoacylation reaction can also be used as a distinctive mechanistic signature, as aminoacyl-tRNA release is the rate-limiting step for class I enzymes (except for IleRS and some GluRS) while for class II it is the amino acid activation rate instead.
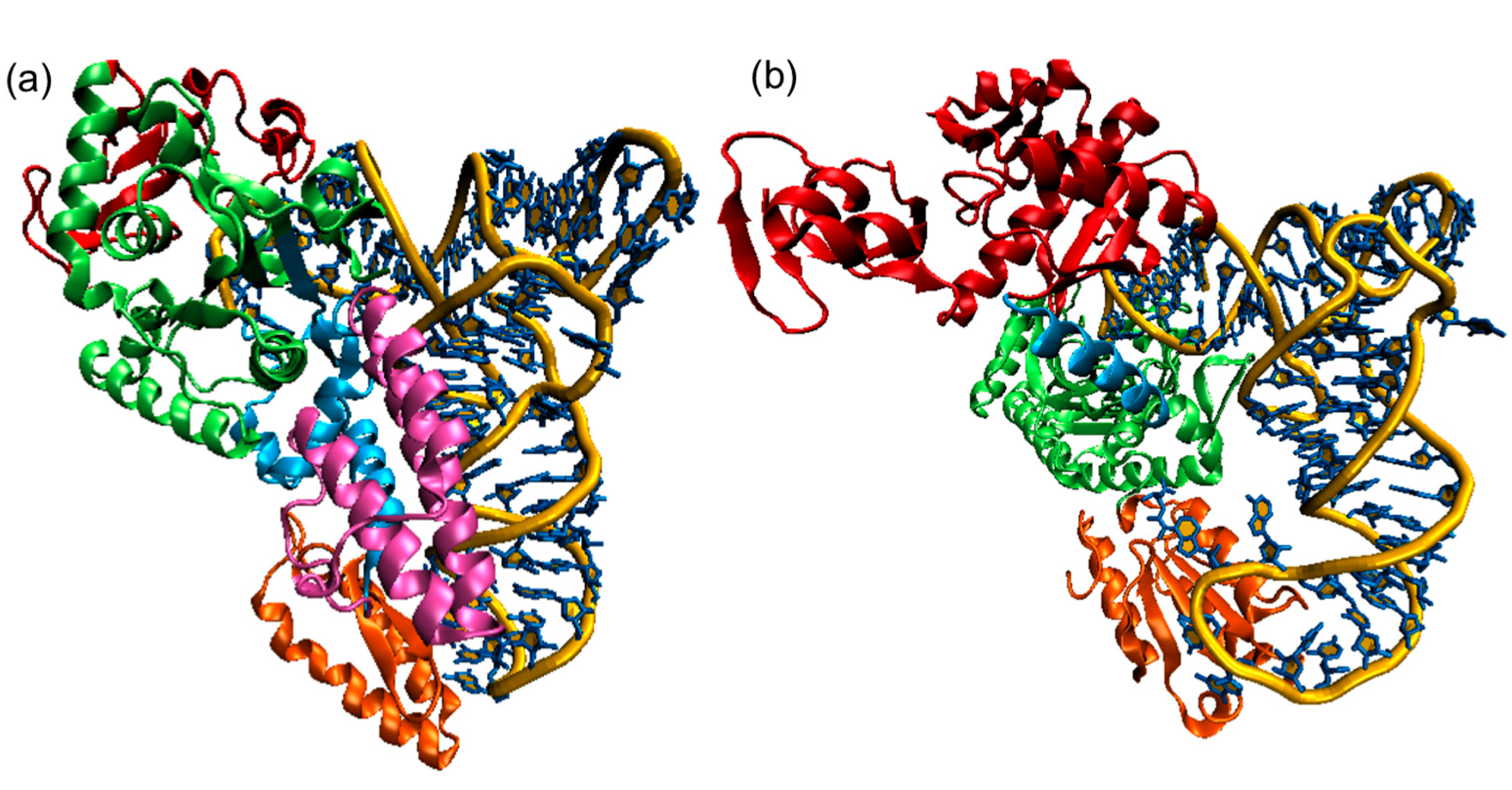
Panel (a) shows the E. coliCysRS:tRNACys complex. The CP domain (red) and Rossmann fold catalytic domain (green), stem contact fold (cyan), helical bundle domain (magenta), and anticodon binding domain (orange) of CysRS are shown in a ribbon diagram;
Panel (b) A single monomer of the homodimeric E. coli ThrRS:tRNAThr complex. The two N-terminal domains (red), catalytic domain (green), linker (cyan), and anticodon binding domain (orange) of ThrRS are shown in a ribbon diagram. For both structures, the tRNAs are shown in a stick diagram (blue) with a trace of their backbone (yellow).
Figure \(\PageIndex{14}\) shows an interactive iCn3D model of the Class I and II aminoacyl-tRNA synthetases
| Class I E. Coli Cysteinyl-tRNA synthetase -tRNA(Cys) (1U0B) | class II E. coli threonyl-tRNA synthase - tRNA(Thr) (1QF6) |
|
(Copyright; author via source). Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...P4oRWxKvJHFDL6 |
(Copyright; author via source). Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...6aXwfqXGCpD7c6 |
.png?revision=1&size=bestfit&width=366&height=403)
_(1QF6)%25C2%25A0%25C2%25A0%25C2%25A0.png?revision=1&size=bestfit&width=381&height=408)
The color coding is analogous to Figure \(\PageIndex{13}\) with the tRNA shown in gray.
For the Class II E. coli threonyl-tRNA synthase - tRNA(Thr), key conserved amino acids in the active site are shown in CPK-colored sticks and labeled. The anticodon in the tRNA is shown in colored sticks as well. Note the large conformational change in the anticodon loop.
The E. coli threonyl-tRNA synthetase is interesting in that it represses the translation of its own mRNA. A Zn2+ ion is involved in binding specificity for the amino acid. It is coordinated by H385, H511, and a water molecule (not shown). R363 interacts with the alpha phosphate, while F379 and R520 align on both sides of the adenine rig. D383 interacts with the amine group of the substrate threonine.
To ensure the faithful translation of the genetic message, synthetases must identify and pair particular tRNAs with their cognate amino acid which relies on the proper recognition of both substrates. This can prove extremely challenging for the synthetases as not only have they to discriminate the correct tRNA isoacceptor amongst a set of other tRNAs very similar in structure and chemical composition but also be able to select the cognate amino acid amidst an extremely large pool of similar amino acids, both proteinogenic and non-proteinogenic. The evolutionary pressure to maintain fidelity has driven aaRSs to develop an elevated specificity for their substrates, both the tRNA and the amino acid.
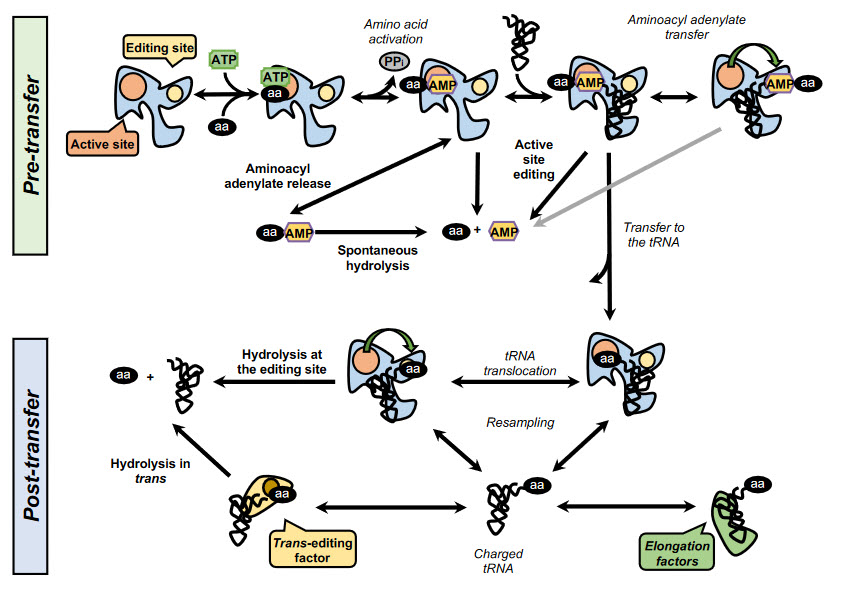
In addition, some synthetases have evolved editing activities that specifically target and hydrolyze misactivated amino acids and/or misacylated tRNAs. To date, editing activity has been described in 10 out of the 23 aaRSs. In class I synthetases, this activity is located in the highly conserved CP1 domain, although in some enzymes such as MetRS and LysRS the editing activity resides in the catalytic site. In class II synthetases, however, the editing domains are more idiosyncratic. Editing mechanisms can be divided into two categories, pre- or post-transfer editing, with regard to the editing taking place before or after the transfer of the amino acid to the tRNA, as shown in Figure \(\PageIndex{15}\).
Pre-transfer editing has been described in both class I and class II aaRSs and takes place after aa-AMP synthesis but before the aminoacyl moiety is transferred to the tRNA. Although the tRNA does not participate in the reaction itself, it has been reported that tRNA binding promotes editing activity in some aaRSs and is a requirement in IleRS and LeuRS. Pre-transfer editing can follow two main pathways. The first one is the selective release of the aa-AMP to the cytosol, where the labile phosphoester bond is spontaneously hydrolyzed. The second route involves the enzymatic breakdown of the product and may happen either in the active site or in an independent editing site.
Post-transfer editing takes place after the transfer of the amino acid to the tRNA and involves the hydrolysis of the ester bond, in a domain separated from the active site. The specific mechanism of editing is idiosyncratic to each synthetase but in general, once formed the aa-tRNA triggers a conformational change, and the 3’ terminus containing the aa is translocated from the active site to the editing site, sometimes traversing distances as large as 40 Å. As the core of the tRNA remains bound to the enzyme, this translocation often involves a rearrangement of the 3’ terminus to relocate to the editing site.
Ribosome Structure
The ribosome is a highly conserved molecular machine. In all organisms, it is composed of two unequal subunits, which consist of a distinct set of ribosomal RNA (rRNA) and ribosomal proteins (RPs) that combine to form a large nucleoprotein complex. The ribosome structures in all living organisms harbor three different tRNA binding sites: The A-site, where decoding occurs and the correct aminoacyl-tRNA (aa-tRNA) is selected based on the mRNA codon displayed, the P-site, which carries the peptidyl-tRNA, and the E-site, which binds exclusively deacetylated tRNAs that are exiting the ribosome. Thus, during translation the tRNA moves from the A-site through the P- and E-site, where it leaves the ribosome, as shown in Figure \(\PageIndex{16}\).
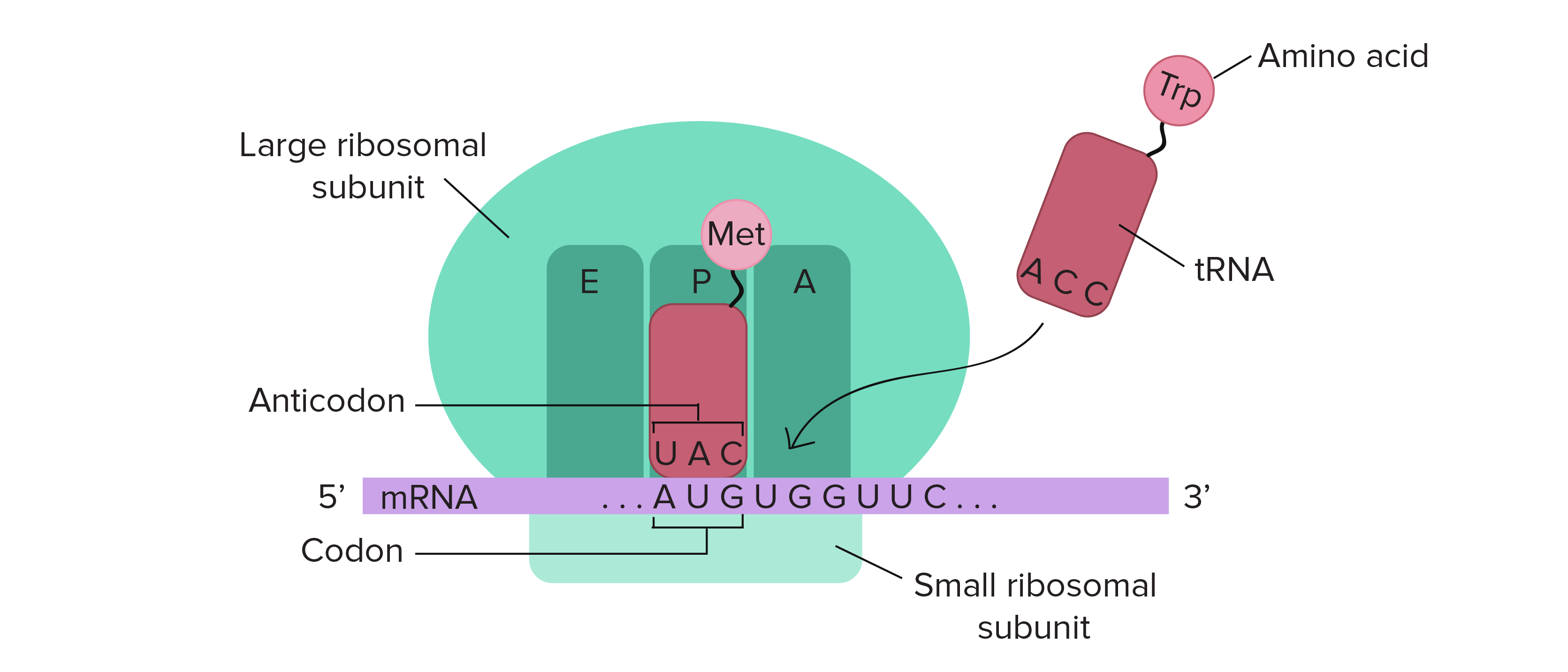
The mRNA (shown in purple) is assembled between the small subunit and the large subunit of the ribosome (shown in green). tRNA molecules (shown in red) that are loaded with their cognate amino acid (shown in pink) are transitioned through the A-P-E sites of the ribosome during the elongation phase of translation. Movement of the tRNA molecules also shifts the position of the mRNA causing the next three codon bases to line up in the A-site of the ribosome.
The catalytic peptidyl transferase activity occurs when the tRNA molecules are bound in the A- and P-sites, transferring the nascent peptide to the incoming tRNA molecule (Fig. 27.1.15). Ribosomes are ribozymes because the catalytic peptidyl transferase activity that links amino acids together is performed by the rRNA.the complexity of the ribosome structure is reflected in the process of protein synthesis, which can be intersected into three major steps: initiation, elongation, and termination/recycling.
Ribosomes are either free-floating in the cytoplasm or they can be associated with the intracellular membranes that make up the rough endoplasmic reticulum (rER). Proteins translated into the rER will often be transported out of the cell or embedded into the plasma membrane. These processes are illustrated in Figure \(\PageIndex{17}\).
Figure \(\PageIndex{17}\): A ribosome translating a protein that is secreted into the endoplasmic reticulum. Figure from: Bensaccount
Ribosomes from bacteria, archaea, and eukaryotes in the three-domain system resemble each other to a remarkable degree. They differ in their size, much of the rRNA sequence, and the ratio of protein to RNA. Figure \(\PageIndex{18}\) shows the eukaryotic rRNA from the large subunit of the ribosome with highly conserved nucleotide elements (>90% sequence identity) within all of the domains of life, termed universal CNEs or uCNEs indicated. The differences in sequence and structure between eukaryotes and prokaryotes allow some antibiotics to kill bacteria by inhibiting their ribosomes while leaving human ribosomes unaffected.

In all species, more than one ribosome may move along a single mRNA chain at one time (as a polysome), each “reading” its sequence and producing a corresponding protein molecule. In this way, many proteins can be translated from a single mRNA molecule. Within bacteria, translation is also coupled with transcription, as the two processes are not physically separated from one another. This is illustrated in Figure \(\PageIndex{19}\). In eukaryotic organisms, polysomes form during translation. However, transcription and translation are not coupled, as the processes are separated into the nucleus and cytoplasm, respectively.
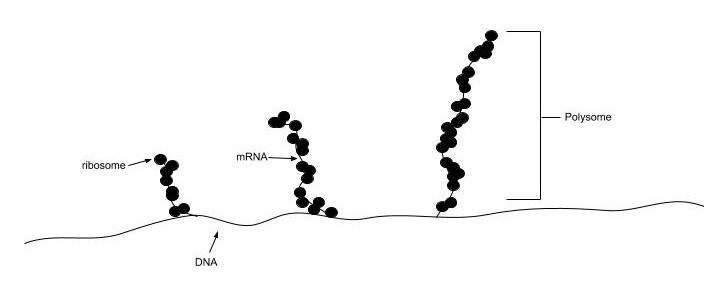
The mitochondrial ribosomes of eukaryotic cells functionally resemble many features of those in bacteria, reflecting the likely evolutionary origin of mitochondria.
Prokaryotic Ribosome Structure
Prokaryotic ribosomes have a mass of about 2500 kDa and a size of 70S (or Svedberg units: A Svedberg unit is a measure of the sedimentation rate in a centrifuge and thus is representative of size). A complete ribosome (70S) can be dissociated into a large subunit (50S) and a small subunit (30S), as shown in Figure \(\PageIndex{20}\). The small subunit is formed by the interactions of 21 different proteins and a 16S RNA molecule, whereas the large subunit contains 34 different proteins and two RNA molecules, a 23S, and a 5S species.
The rate-limiting step in protein synthesis is the formation of the 70S initiation complex which will be discussed in detail in the next section.
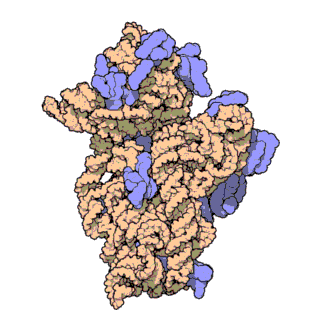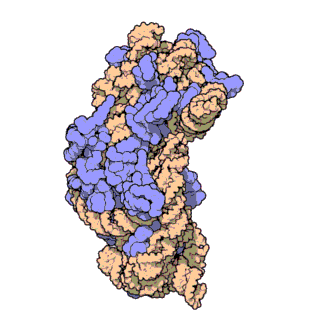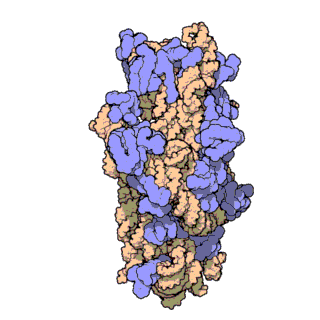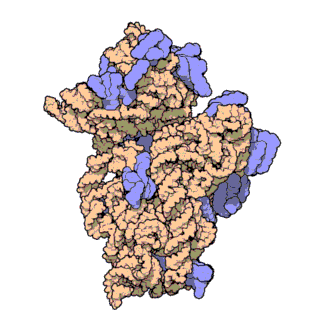
Figure \(\PageIndex{21}\) shows an interactive iCn3D model of the E. Coli ribosome (7K00).
.png?revision=1&size=bestfit&width=421&height=529)
The RNA is shown in a faint trace backbone. The proteins are shown as cartoons with different colors. Note the large number of Mg2+ ions.
The structure was determined using cryo-EM at high resolution. Some ribosomal proteins have isopeptide bonds (using side chain amine and carboxyl groups) as well as some thioamide backbone replacements for the usual amide links.
Eukaryotic Ribosome Structure
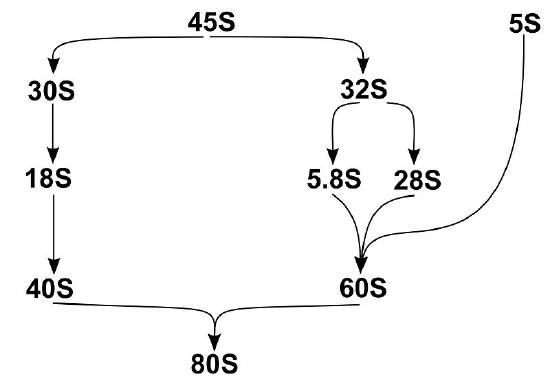
Eukaryotic ribosomes are larger than their prokaryotic counterparts at approximately 80S (although there is some modest variation between eukaryotic species). Human cytosolic ribosomes are composed of a large subunit (60S) that contains the 28S, 5.8S, and 5S rRNAs and 47 ribosomal proteins (RPs), and a small subunit (40S) that contains the 18S rRNA and 33 RPs.
The assembly of eukaryotic ribosomal subunits starts in the nucleolus, where RNA polymerase I transcribes the major rRNA precursor (a 45S pre-RNA), from which, after processing and removal of the external and internal transcribed spacers (ETS and ITS), the mature rRNAs are generated, as shown in Figure \(\PageIndex{22}\). The pre-RNA is modified during transcription by small nucleolar ribonucleoproteins (snoRNPs), processed by RNA nucleases, and assembled with numerous RPs. After processing the rRNA precursor, the pre-40S and pre-60S subunits follow separate biogenesis routes. Here we will describe the assembly of the 60S subunit in more detail.
Although the exact assembly of the 60S subunit is not currently known, a model has been postulated that suggests that in the nucleolus, after circularization of rRNA domains, early 60S assembly is carried out sequentially, as shown in Figure \(\PageIndex{23}\). As the transcription of the pre-rRNA proceeds, the rRNA quickly develops a core secondary structure that promotes the interaction of key Assembly Factors (AFs) and RPs before transcriptional termination. Specifically, during this time, the 5.8S portion, ITS2, domains I and II, and partially domain VI are folded in the earliest observed intermediate (state A in Fig. 23). Thus, it appears that the solvent-exposed back side of the large subunit forms like an exoskeleton and construction proceeds by formation of the exit tunnel. This model agrees with a previously suggested model of hierarchical folding based on RP depletion phenotypes. The peptidyl transferase center (PET) is predicted to be one of the later folding steps in the process (state F in Fig. Fig 23) Although the very late-folding peptidyl transferase center is the evolutionarily oldest part of the ribosome, it is likely that folding the solvent side first brings the advantage of providing a stable scaffold for the developing 60S subunit. The folding and assembly of the 40S subunit follow a similar pattern. The two subunits remain unattached until activated in the cytoplasm through the binding of a mRNA transcript with the small subunit. This begins the formation of the initiation complex that will mark the start of the transcriptional process.
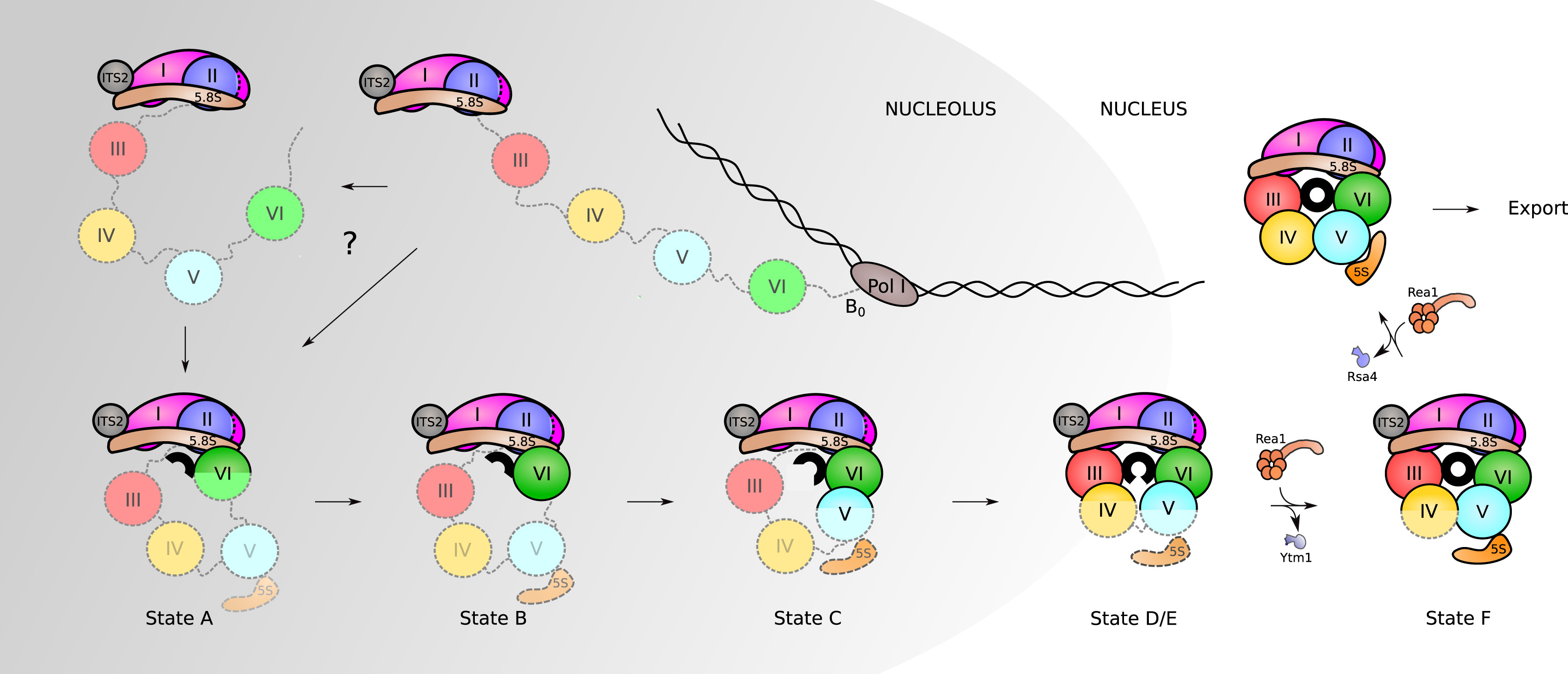
Assembly of RPs and AFs to the nascent 35S rRNA precursor starts co-transcriptionally. Very early, the pre-rRNA is circularized as domain VI binds to domains I and II and the 5.8S portion of the precursor rRNA. The formation of the PET (displayed here as a black circle) starts with this circularization. Its maturation progresses as rRNA domains fold following this order: VI, V, III, and IV. Full assembly of the PET is only achieved when domain V is completely folded as observed in state F. After that, only a few additional steps need to occur before the particles are exported to the cytoplasm, where they undergo final maturation.
References
This chapter was remixed and adapted from the following resources under creative commons licensing:
- Wikipedia contributors. (2020, June 27). Wobble base pair. In Wikipedia, The Free Encyclopedia. Retrieved 16:47, August 12, 2020, from https://en.Wikipedia.org/w/index.php?title=Wobble_base_pair&oldid=964760055
- Lorenz, C., Lünse, C., and Mörl, M. (2017) tRNA modifications: Impact on the structure and thermal adaptation. Biomolecules 7(2)35. Available at: https://www.mdpi.com/2218-273X/7/2/35/htm
- Pan, T. (2018) Modifications and functional genomics of human transfer RNA. Cell Research 28:395-404. Available at: https://www.nature.com/articles/s41422-018-0013-y#Sec3
- Bednárová, A., Hanna, M., Durham, I., Van Cleave, T., England, A., Chaudhuri, A., and Krishnan, N. (2017) Lost in translation: Defects in transfer RNA modifications and neurological disorders. Front. Mol Neurosci. 10:135. Available at: https://www.researchgate.net/publication/316440980_Lost_in_Translation_Defects_in_Transfer_RNA_Modifications_and_Neurological_Disorders
- Wikipedia contributors. (2020, May 17). Transfer RNA. In Wikipedia, The Free Encyclopedia. Retrieved 23:03, August 15, 2020, from https://en.Wikipedia.org/w/index.php?title=Transfer_RNA&oldid=957227343
- Gomez, M.A.R., and Ibba M. (2020) Aminoacyl-tRNA Synthetases. RNA, doi: 10.1261/rna.071720.119 Available at: https://rnajournal.cshlp.org/content/early/2020/04/17/rna.071720.119.abstract
- Li, R., Macnamara, L.M., Leuchter, J.D., Alexander, R.W., and Cho, S.S. (2015) MD Simulations of tRNA and Aminoacyl-tRNA Syntetases: Dynamics, Folding, Binding, and Allostery. Int. J. Mol Sci. 16(7):15872-15902. Available at: https://www.mdpi.com/1422-0067/16/7/15872
- Wikipedia contributors. (2020, August 15). Ribosome. In Wikipedia, The Free Encyclopedia. Retrieved 05:22, August 16, 2020, from https://en.Wikipedia.org/w/index.php?title=Ribosome&oldid=973144885
- Kater, L., Thoms, M., Barrio-Garcia, C., Cheng, J., Ismail, S., Ahmed, Y.L., Bange, G., Kressler, D., Berninghausen, O., Sinning, I., Hurt, E., and Beckmann, R. (2017) Visualizing the assembly pathway of nucleolar Pre-60S Ribosomes. Cell 171(7):1599-1610. Available at: https://www.sciencedirect.com/science/article/pii/S0092867417314290
- Bock, L.V., Kolár, M.H., Grubmüller, H. (2018) Molecular simulations of the ribosome and associated translation factors. Cur. Op. Struc. Bio. 49:27-35. Available at: https://www.sciencedirect.com/science/article/pii/S0959440X1730132X
- Doris, S.M., Smith, D.R., Beamesderfer, J.N., Raphael, B.J., Nathanson, J.A., and Gerbi, S.A. (2015) Universal and domain-specific sequences in 23S-28S ribosomal RNA identified by computational phylogenetics. RNA 21:1719-1730. Available at: https://www.researchgate.net/publication/281141702_Universal_and_domain-specific_sequences_in_23S-28S_ribosomal_RNA_identified_by_computational_phylogenetics
- Aleksashin, M.A., Leppik, M., Hochenberry, A.J., Klepacki, D., Vázquez-Laslop, N., Jewett, M.C., Remme, J., and Mankin A.S. (2019) Assembly and functionality of the ribosome with tethered subunits. Nature Communications 10:930. Available at: https://www.nature.com/articles/s41467-019-08892-w#rightslink
- Wikipedia contributors. (2020, July 3). Formylation. In Wikipedia, The Free Encyclopedia. Retrieved 22:03, August 16, 2020, from https://en.Wikipedia.org/w/index.php?title=Formylation&oldid=965827476
- Gualerzi, C.O., and Pon C.L. (2015) Initiation of mRNA translation in bacteria: structural and dynamic aspects. Cell Mol Life Sci. 72:4341-4367. Available at: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4611024/
- Wikipedia contributors. (2020, June 14). Kozak consensus sequence. In Wikipedia, The Free Encyclopedia. Retrieved 06:03, August 18, 2020, from https://en.Wikipedia.org/w/index.php?title=Kozak_consensus_sequence&oldid=962444929
- Knight, J.R.P., Garland, G., Pöyry, T., Mead, E. Vlahov, N., Sfakianos, A., Frosso, S., De-Lima-Hedayioglu, F., Mallucci, G.R., von der Haar, T., Smales, C.M., Sansom, O.J., and Willis, A.E. (2020) Control of translation elongation in health and disease. Dis. Mod. and Mech. 13: dmm043208. Available at: https://dmm.biologists.org/content/13/3/dmm043208
- Adio, S., Sharma, H., Senyushkina, T., Karki, P., Maracci, C., Wohlgemuth, I., Holtkamp, W., Peske, R., and Rodina, M.V. (2018) Dynamics of ribosomes and release factors during translation termination in E. coli. eLife 7:e34253. Available at: https://elifesciences.org/articles/34252
- Ge, X., Oliveira, A., Hjort, K., Bergfors, T., Guitiérrez-de-Terán, H., Andersson, D.I., Sanyal, S., and Åqvist, J. (2019) Inhibition of translation termination by small molecules targeting ribosomal release factors. Scientific Reports 9: 15424. Available at: https://www.nature.com/articles/s41598-019-51977-1#rightslink
- Svidritskiy, E., Demo G., Loveland A.B., Xu, C., and Korosteleve, A.A. (2019) Extensive ribosome and RF2 rearrangements during translation termination. eLife 8:e46850. Available at: https://elifesciences.org/articles/46850
- Sauert, M., Temmel, H., and Moll, I. (2015) Heterogeneity of the translational machinery: Variations on a common theme. Biochimie 114:39-47. Available at: https://www.sciencedirect.com/science/article/pii/S0300908414003952