
3.2: The Structure of Proteins- An Overview
- Page ID
- 14930


Peptide Bond Formation and Primary Protein Structure
Proteins are polymers of amino acids that fold into shapes that confer function on the proteins. In biological systems, the amino acids are linked together by a large ribonucleic acid/protein nanoparticle called the ribosome. Thus, as the amino acids are linked together to form a specific protein, they are placed within a very specific order that is dictated by the genetic information contained within a specific type of RNA called messenger RNA (mRNA). The mRNA sequences are encoded in the genomic DNA sequence. The specific ordering of amino acids is known as the protein's primary sequence. The translation mechanism used by the ribosome to synthesize proteins will be discussed in detail in Chapter 26.
The amino acids are linked together using dehydration synthesis (loss of water) reaction that connects the carboxylic acid of the upstream amino acid with the amine functional group of the downstream amino acid to form an amide linkage (Figure 2.10). You will remember from other chemistry courses that the formation of an amide from a carboxylic acid (thermodynamically stable) and an amine requires activation of the carboxylic acid end to form a derivative with a better leaving group. This carbonyl of the modified end serves as an electrophile in the attack of the amine nitrogen, a nucleophile) in a nucleophilic substitution reaction. The activation reaction, which we will discuss in subsequent chapters involves the transfer of a phosphate from a phosphoanhydride, ATP, to the carboxylic acid group to form a mixed anhydride with the phosphate serving as a leaving group. Note that the reverse reaction is hydrolysis and requires the incorporation of a water molecule to separate two amino acids and break the amide bond. Notably, the ribosome serves as the enzyme that mediates the dehydration synthesis reactions required to build protein molecules, whereas a class of enzymes called proteases is required for protein hydrolysis.
Within protein structures, the amide linkage between amino acids is known as the peptide bond. Subsequent amino acids will be added onto the carboxylic acid terminal of the growing structure. Proteins are always synthesized in a directional manner starting with the amine and ending with the carboxylic acid tail. New amino acids are always added onto the carboxylic acid tail, never onto the amine of the first amino acid in the chain. The directionality of protein synthesis is dictated by the ribosome. Figure \(\PageIndex{1}\) below shows an overly simplistic version of the reaction that produces the amide bond.
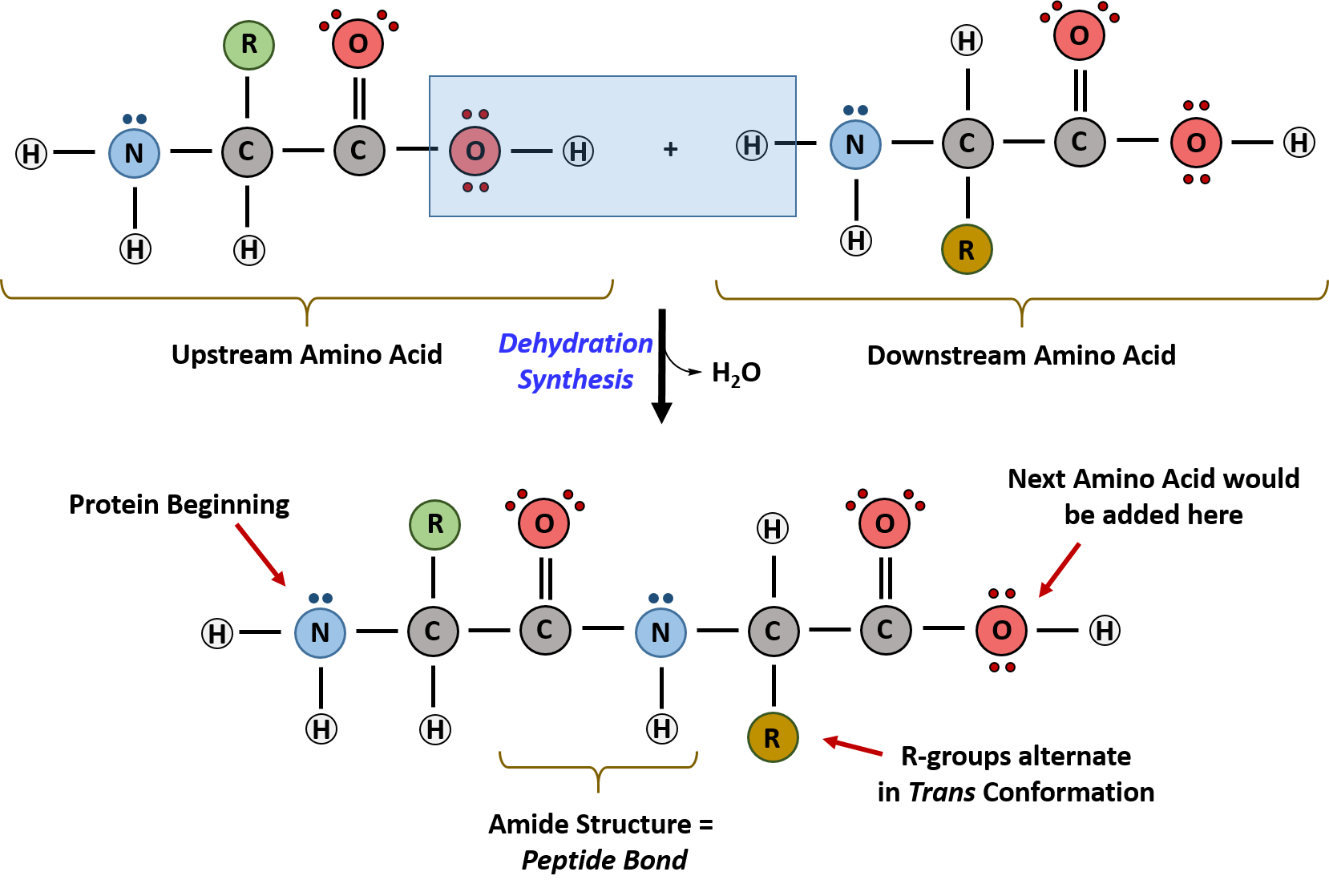
Please note two features of the reaction as shown in the diagram:
- The activation step (phosphorylation of the carboxylic acid end of the amino acid by ATP) is not shown.
- The reaction is shown with an unlikely protonation state. If the carboxyl group is protonated, which would occur at a low pH, the amine would also be protonated and should correctly be shown as RNH3+. The protonation state in the above figure was chosen to emphasize the loss of H2O (dehydration) in the reaction. Many textbooks that aren't rigorously based in chemistry show unlikely protonation states for this reaction. By discussing this now, we hope to highlight common mistakes and misconceptions found in many resources.
Figure \(\PageIndex{2}\) shows a generic structure from a longer peptide or protein.

Proteins range in size from around 50 amino acids in length to the largest known full protein, titin (aka called connectin), a muscle protein. The human version has over 34,000 amino acids and a molecular weight > 3.9 million! Even larger "giant" proteins, up to 85,804 amino acids, are encoded by some bacteria in the phylum Omnitrophota, which are found in waste water and hot pools, although only pieces of it have been encountered.
Some consider structures with fewer than 50 amino acids to be peptides (Figure 2.13). Others suggest that structures with 40-50 amino acids should be considered small proteins. One way to differentiate them is by how they are synthesized in vivo. Storz et al consider polypeptides to be small proteins if they are encoded in the genome by a continuous stretch of DNA base in an "open reading frame" (doi: 10.1146/annurev-biochem-070611-102400). Peptides, on the other hand, could be structures that are:
- "intrinsically disordered" with no definite fold,
- derived from proteins by proteolysis, and/or
- not synthesized by ribosomes
As genomes were sequences and annotated, some arbitrary parameters were set. For the yeast genome, annotated proteins were defined as those made from an open reading frame leading to a polypeptide of 100 amino acids (which on average has a molecular weight of 11,000). If no cutoff was used, the number of proteins encoded by the genome would be huge. Submissions of DNA sequences to the NIH GenBank must encode proteins no smaller than about 66 amino acids (MW about 7250). Even this ignores small proteins that have been isolated and characterized from cells. So the cutoff of 50 amino acids (MW about 5500) derived from open reading frames seems like the best arbitrary cutoff going from peptides to proteins.
Due to the large pool of amino acids that can be incorporated at each position within the protein, there are billions of different possible protein combinations that can be used to create novel protein structures! For example, think about a tripeptide made from this amino acid pool. At each position, there are 20 different options that can be incorporated. Thus, the total number of resulting tripeptides possible would be 20 X 20 X 20 or 203, or 8,000 different tripeptide sequences! Now think about how many options there would be for a small peptide containing 40 amino acids. There would be 2040 options, or a mind-boggling 1.09 X 1052 potential sequence options! Each of these options would vary in the overall protein shape, as the nature of the amino acid side chains helps to determine the interaction of the protein with the other residues in the protein itself and with its surrounding environment.
Nearly 200,000 3D structures of biomacromolecules are known and over a million have been determined using artificial intelligence computer programs. How can we simplify our understanding of the diversity of protein structures? Is each structure completely unique? What do they have in common?
To simplify and inform our understanding of the diversity of biological organisms, we place them into groups (from domains and kingdoms to genuses and species), based on common characteristics. Likewise, proteins are divided into a hierarchy of structures with increasing information content. This overview describes the four basic levels of protein structure, primary (10), secondary (20), tertiary (30) and quaternary (40). Each will be probed in greater deal in the next chapter. These classes of structures will be illustrated below with a protein named hydroxynitrile lyase (5Y02). (This protein has been simplified to illustrate key features of structure as will be described at the end).
Primary (10) Structure: the amino acid sequence of a protein.
The primary (10) structure of a protein is simply the amino acid sequence of a protein written from N- to C-terminal. It does not require visualization to describe it. Consider two different short continuous sequences from the hydroxynitrile lyase:
- Gln-Lys-Gln-Ile-Asp-Gln-Ile or in single letter code QKQIDQI. This is the sequence for amino acids 20-26 in the protein. This stretch of 10 structure has multiple repeated amino acids.
- Asp-Leu-Gly-Pro-Ala-Val or in single letter code DLGPAV. This is the sequence for amino acids 48-53 in the protein. This stretch of 10 structure does not contain repetitive amino acids.
A 2-D line drawing of the sequence offers more information about the sequence but does not provide information about the actual conformation of these sections of 10 structure within a given protein. These can be shown in Figure \(\PageIndex{3}\) in which the overall structure of the protein is shown in grey sticks with short stretches of primary structure shown in colored spacefill and 2D line drawings.

Figure \(\PageIndex{3}\): Alternative renderings of a "primary" sequence within a protein
Secondary (20) and Tertiary (30) Structures
Secondary (20) structures are repetitive structures within a protein held together by hydrogen bonds between amide Hs and carbonyl Os in the backbone main chain atoms. It's most easily examined through the specific rendering of the overall tertiary (30) or 3-D structure of the protein. Five different renderings showing the 3D (the tertiary structure of the protein are shown in Figure \(\PageIndex{4}\).

Representation A shows a stick drawing of the protein with red indicating bonds to oxygen and blue bonds to nitrogen. No bonds to hydrogen are shown as these are too small to be detected using common techniques used to determine structures of such large molecules. It looks like a complicated mess of bonds so understanding unique features with the 30 structure of the protein are difficult. Representation B shows just the backbone of the protein. The outline of how the protein twists and turns in space becomes more evident. The N- and C-terminal ends are more clearly seen.
Representation C shows just the bonds connecting the alpha C atoms of each amino acid. The protein's overall topology is now clearly evident. If you follow the chain from the N- to C-terminal ends, it should be evident that there are regularities in the conformations of the protein chain. The individual yellow zig-zags are called beta strands. These strands appear elongated and aligned with other beta strands to form a larger beta-sheet. The sheet is held together through hydrogen bonds between backbone amide Hs and carbonyl Os on adjacent strands. Beta strands are a type of secondary structure.
The red zig-zag lines represent another type of secondary structure called the alpha-helix. The helix is again held together by hydrogen bonds between amide Hs and carbonyl Os within a single continuous strand. The backbone of the alpha helix appears less elongated than in a beta-strand as it is wound into a coil (the alpha helix) along a central axis. If you took tweezers (using atomic force microscopy) and pulled on the helix, it could stretch and become more elongated like the beta strands.
The rest of the protein alpha carbon chain shown in blue is less regular. However, it is still ordered as it propagates through space in what is termed a random coil. In the protein, it adopts mostly a fixed conformation but it has more conformational flexibility than alpha helices and beta sheets. The alpha helices and beta strands (sheets) are examples of secondary structures.
Representations D and E are cartoon drawings clearly showing the alpha helices (red) and beta stands and sheets (yellow). It would be extremely difficult to discern alpha or beta secondary structures with stick representations showing all the bonds in a protein. Some of the atoms must be visually (not literally) removed to see the repetitive propagation of the protein backbone through the overall structure. If your goal was to understand the disposition of side chains in a small part of a protein, a cartoon view by itself would not be useful. Modeling programs allow mixed rending of a protein to include both cartoon and stick representations together.
Secondary structures, held together by hydrogen bonds between backbone atoms are characterized by repetitive changes in the angle of propagation of the chain between connected amino acids in an alpha helix and strand. In a given beta-strand, the relative change in the angle of propagation is nearly 00 compared to a much large angular change required to bend the amino acid backbone into an alpha helix. Here is the IUPAC definition of secondary structure. We added the word "repetitive" to clearly show that random coils are not an example of secondary structures.
The [repetitive] conformational arrangement (α-helix, β-pleated sheet, etc.) of the backbone segments of a macromolecule such as a polypeptide chain of a protein without regard to the conformation of the side chains or the relationship to other segments.
Quaternary Structure
Separate protein chains often interact through noncovalent interactions and sometimes through disulfide bond formation between free cysteine side chains on different chains to form dimers, trimers, tetramers, octamers, etc. Dimers can be homodimers (if the two chains are identical) or heterodimers (if they are different). The example we used in the section, hydroxynitrile lyase, forms a homodimer, as shown in Figure \(\PageIndex{5}\). The left images shows a cartoon version, with one monomer in orange and the other identical monomer in green. The images to the right shows a translucent surface representation of the dimer, with the car

The mixed-rendered image on the right shows a translucent surface image of each monomer and underneath the cartoon image
- primary structure: the linear amino acid sequence of a protein
- secondary structure: regular repeating structures arising when hydrogen bonds between the peptide backbone amide hydrogens and carbonyl oxygens occur at regular intervals within a given linear sequence (strand) of a protein or between two adjacent strands
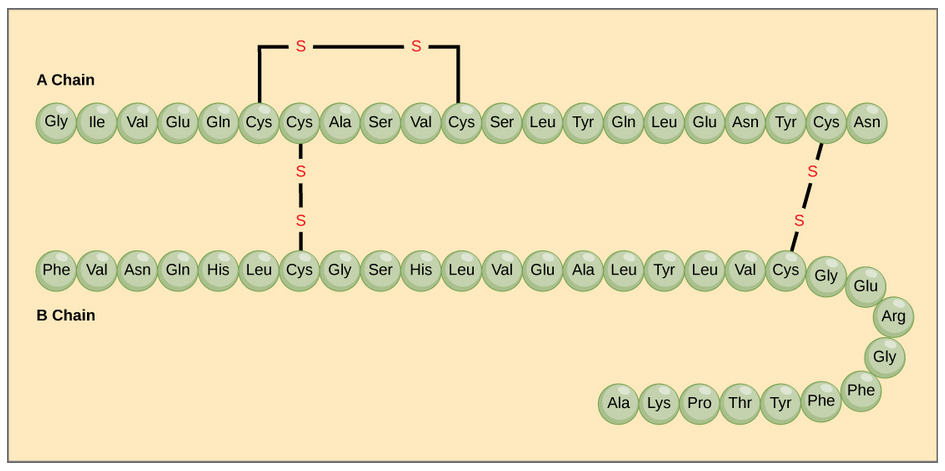
Disulfide bonds within individual chains and between them stabilize both tertiary and quaternary structures of both peptides and proteins. These are illustrated in Figure \(\PageIndex{6}\).
Protein Shape and Function
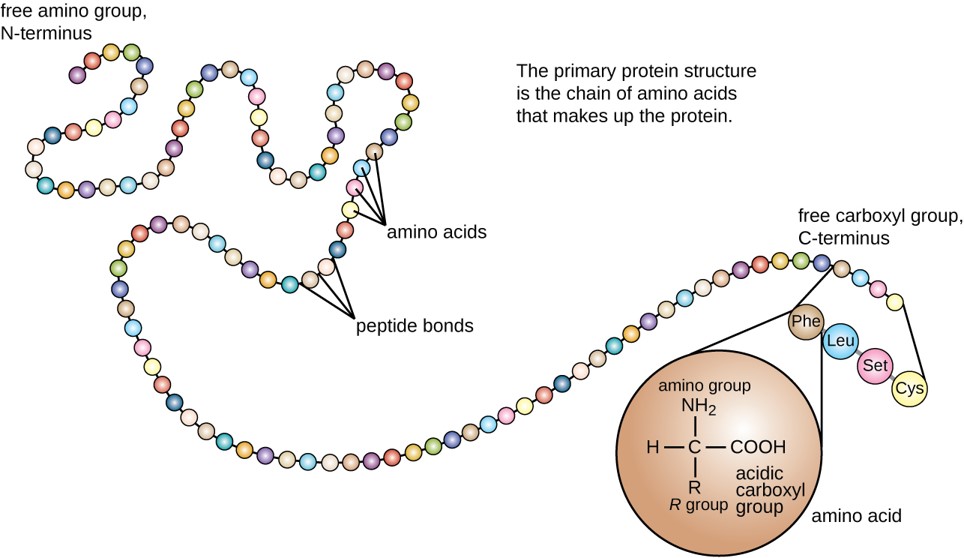
The primary structure of each protein leads to the unique folding pattern that is characteristic of that specific protein. In summary, the primary sequence is the linear order of the amino acids as they are linked together in the protein chain as shown in Figure \(\PageIndex{7}\). In the next section, we will discuss protein folding that gives rise to secondary, tertiary, and sometimes quaternary protein structures.
References
OpenStax, Proteins. OpenStax CNX. Sep 30, 2016 http://cnx.org/contents/bf17f4df-605c-4388-88c2-25b0f000b0ed@2.
File:Chirality with hands.jpg. (2017, September 16). Wikimedia Commons, the free media repository. Retrieved 17:34, July 10, 2019 from commons.wikimedia.org/w/index.php?title=File:Chirality_with_hands.jpg&oldid=258750003.
Wikipedia contributors. (2019, July 6). Zwitterion. In Wikipedia, The Free Encyclopedia. Retrieved 21:48, July 10, 2019, from en.Wikipedia.org/w/index.php?title=Zwitterion&oldid=905089721
Wikipedia contributors. (2019, July 8). Absolute configuration. In Wikipedia, The Free Encyclopedia. Retrieved 15:28, July 14, 2019, from en.Wikipedia.org/w/index.php?title=Absolute_configuration&oldid=905412423
Structural Biochemistry/Enzyme/Active Site. (2019, July 1). Wikibooks, The Free Textbook Project. Retrieved 16:55, July 16, 2019 from en.wikibooks.org/w/index.php?title=Structural_Biochemistry/Enzyme/Active_Site&oldid=3555410.
Structural Biochemistry/Proteins. (2019, March 24). Wikibooks, The Free Textbook Project. Retrieved 19:16, July 18, 2019 from en.wikibooks.org/w/index.php?title=Structural_Biochemistry/Proteins&oldid=3529061.
Fujiwara, K., Toda, H., and Ikeguchi, M. (2012) Dependence of a α-helical and β-sheet amino acid propensities on teh overall protein fold type. BMC Structural Biology 12:18. Available at: https://bmcstructbiol.biomedcentral.com/track/pdf/10.1186/1472-6807-12-18
Wikipedia contributors. (2019, July 16). Keratin. In Wikipedia, The Free Encyclopedia. Retrieved 17:50, July 19, 2019, from en.Wikipedia.org/w/index.php?title=Keratin&oldid=906578340
Wikipedia contributors. (2019, July 13). Alpha-keratin. In Wikipedia, The Free Encyclopedia. Retrieved 18:17, July 19, 2019, from en.Wikipedia.org/w/index.php?title=Alpha-keratin&oldid=906117410
Open Learning Initiative. (2019) Integumentary Levels of Organization. Carnegie Mellon University. In Anatomy & Physiology. Available at: https://oli.cmu.edu/jcourse/webui/syllabus/module.do?context=4348901580020ca6010f804da8baf7ba.
Wikipedia contributors. (2019, July 16). Collagen. In Wikipedia, The Free Encyclopedia. Retrieved 03:42, July 20, 2019, from en.Wikipedia.org/w/index.php?title=Collagen&oldid=906509954
Wikipedia contributors. (2019, July 2). Rossmann fold. In Wikipedia, The Free Encyclopedia. Retrieved 16:01, July 20, 2019, from en.Wikipedia.org/w/index.php?title=Rossmann_fold&oldid=904468788
Wikipedia contributors. (2019, May 30). TIM barrel. In Wikipedia, The Free Encyclopedia. Retrieved 16:46, July 20, 2019, from en.Wikipedia.org/w/index.php?title=TIM_barrel&oldid=899459569
Wikipedia contributors. (2019, July 16). Protein folding. In Wikipedia, The Free Encyclopedia. Retrieved 18:30, July 20, 2019, from en.Wikipedia.org/w/index.php?title=Protein_folding&oldid=906604145
Wikipedia contributors. (2019, June 11). Globular protein. In Wikipedia, The Free Encyclopedia. Retrieved 18:49, July 20, 2019, from en.Wikipedia.org/w/index.php?title=Globular_protein&oldid=901360467
Wikipedia contributors. (2019, July 11). Intrinsically disordered proteins. In Wikipedia, The Free Encyclopedia. Retrieved 19:52, July 20, 2019, from en.Wikipedia.org/w/index.php?title=Intrinsically_disordered_proteins&oldid=905782287